







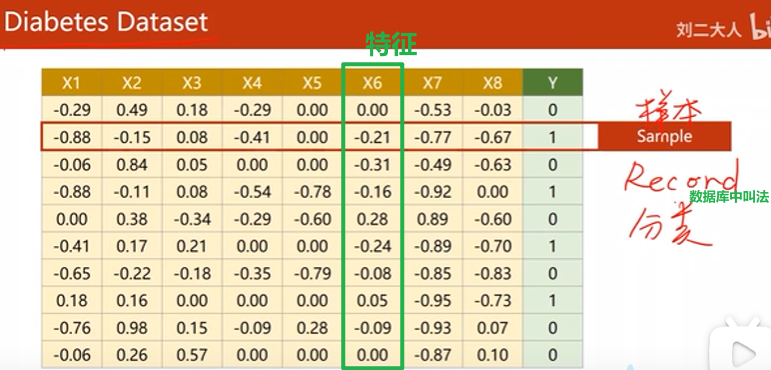
Diabetes数据集
X1~X8是八个指标,Y代表未来一年病情是否会加重。

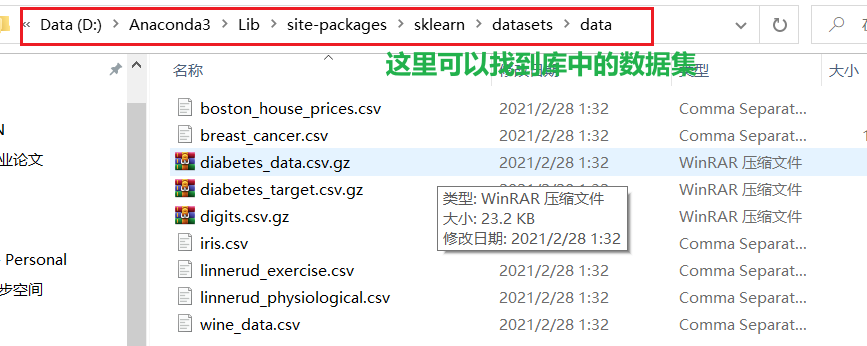
这个地址可以找到库中的数据集文件。D:\Anaconda3\Lib\site-packages\sklearn\datasets\data
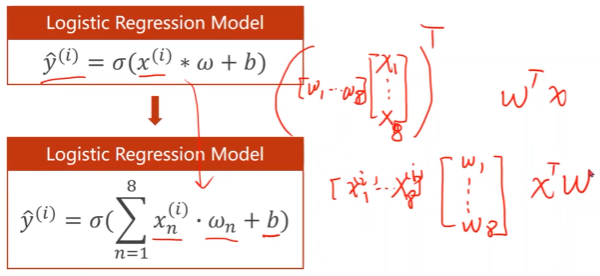
多维逻辑回归模型
相乘后是标量,将其转置表示不改变计算结果
上标表示样本,下标表示特征
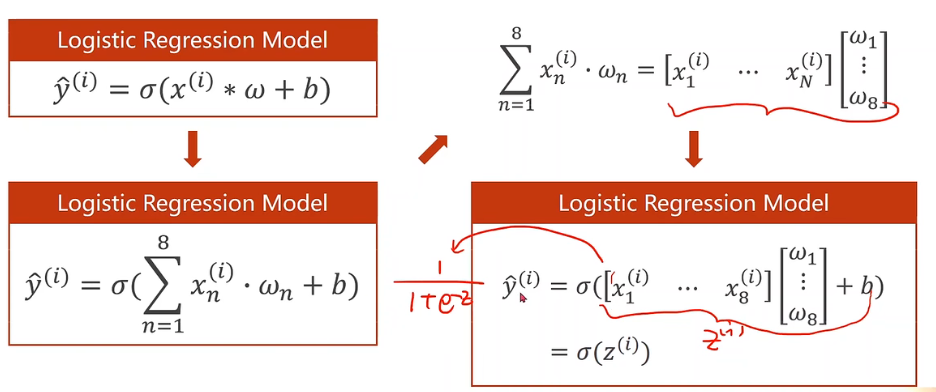
公式的改变:
对于Mini-batch
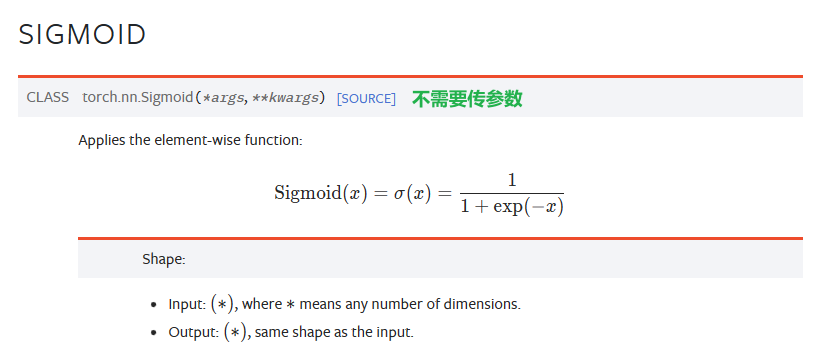
Sigmoid函数是按向量元素进行计算的
转成矩阵来计算是为了利用GPU并行计算的能力,提高运算速度
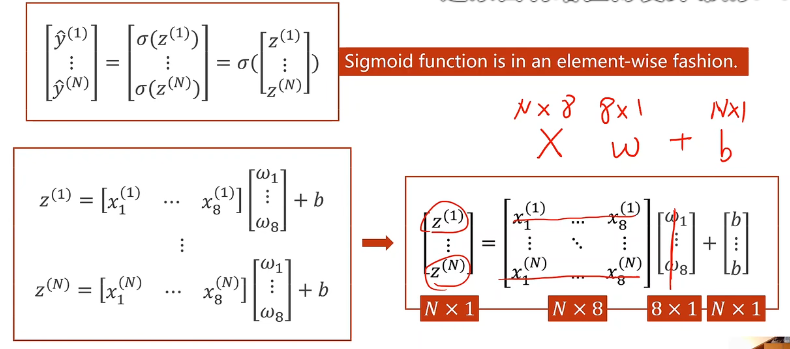
代码变化:

矩阵:从N维空间映射到M维空间的一种线性变换。矩阵是空间变换的函数。
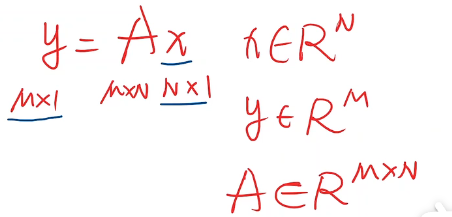
我们需要的空间变换中需要一些非线性的变换层。所以我们用多个线性变换层,通过找到最优的权重,把他们组合起来来模拟非线性的变换。
神经网络的本质是寻找一种非线性的空间变换函数,引入激活函数用线性层来拟合非线性的函数。
从8维到2维,就是在降维

神经网络的构造
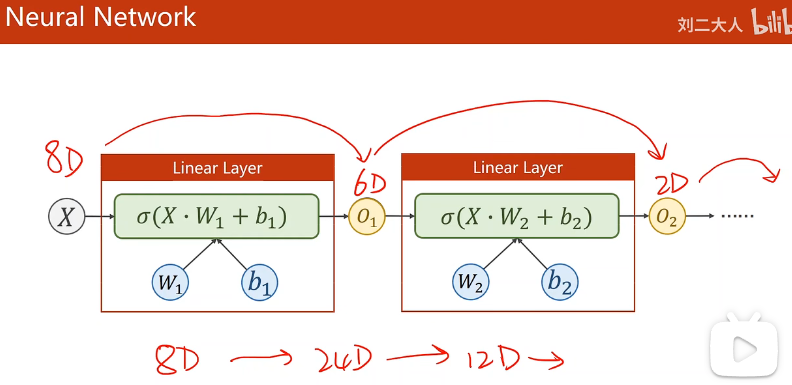
变换的维度和层数决定了网络的复杂程度,具体维度和层数取什么值,是典型的超参数搜索问题。一般来说,隐藏层越多,中间的神经元越多,将来的模型对非线性变化的学习能力越强。
但需要记得,学习能力不要太强!学习能力太强时会把输入样本里噪声的规律也学习到(这是不需要的)。我们要学的是数据真值本身的规律,模型必须要有泛化能力。
现阶段的学习也是如此。追求泛化能力。

这句话说得好:学习能力太强,就类似于背书了。我们需要的是泛化能力强的、能忽略噪声、抓住问题核心本质的模型。
ANN人工神经网络
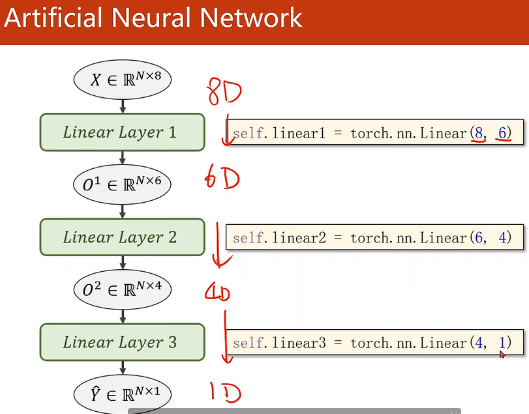
示例:糖尿病预测
数据集准备
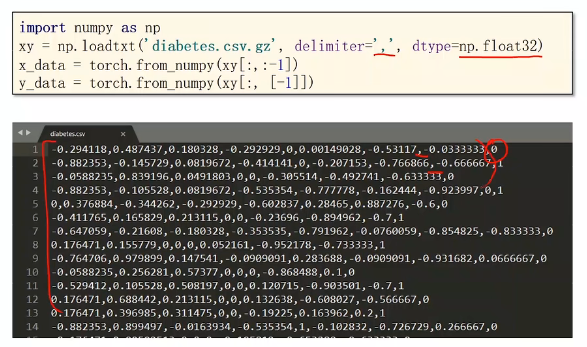
文件名可以是csv也可以是gz(linux下的压缩包),delimiter是分隔符,dtype指定数据类型。
不用double是因为常用的显卡只支持32位的浮点数。对于神经网络来说,32位浮点数已经够用。
torch.from_numpy()是从numpy创建两个tensor
[-1]表示最后拿出的是一个矩阵,如果不要[]拿出来的是一个向量。记得我们需要矩阵来运算
若用vscode ,这里传入的相对路径必须从项目根路径开始。详细可见(1条消息) 【Python】 numpy.loadtxt() OSError: xxx.txt not found文件找不到异常_np.load 找不到文件_莫莫绵的博客-CSDN博客
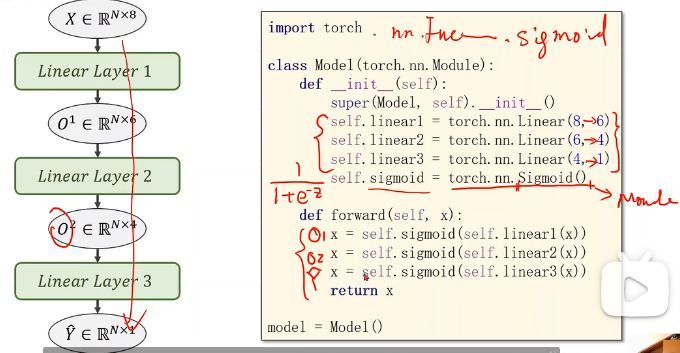
模型定义
nn.Sigmoid模块也是继承自nn.Module,模块中没有需要调整的参数,只定义一个,将来可以通用。
nn.Sigmoid,首字母S大写,是一个类。torch.sigmoid,首字母s小写,是一个类中的方法。
左边输出是O1,O2,但在函数中可以全写x避免出错。
构造损失和优化器
无变化

训练过程
此处仍然是采用Batch训练的,下节讲完DataLoader再改用mini-batch
前馈→反馈→更新

代码
import numpy as np
import torch
import matplotlib.pyplot as plt
# prepare dataset
xy = np.loadtxt('PyTorch_exercise\diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # 第一个‘:’是指读取所有行,第二个‘:’是指从第一列开始,最后一列不要
y_data = torch.from_numpy(xy[:, [-1]]) # [-1] 最后得到的是个矩阵
# design model using class
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6) # 输入数据x的特征是8维,x有8个特征
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid() # 一个类
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x)) # y hat
return x
model = Model()
# construct loss and optimizer
# criterion = torch.nn.BCELoss(size_average = True)
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epoch_list = []
loss_list = []
# training cycle forward, backward, update
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()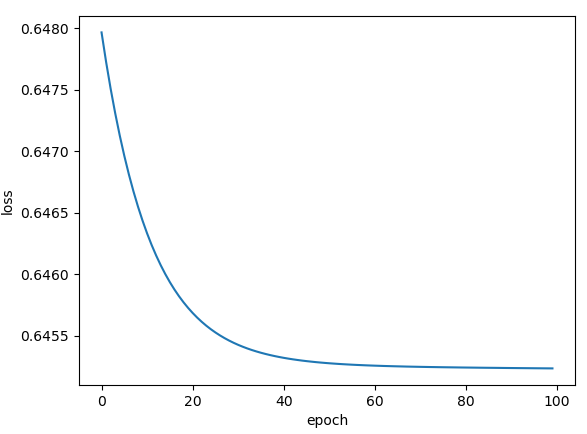
以下扩展参考自:(1条消息) PyTorch 深度学习实践 第7讲_错错莫的博客-CSDN博客
如果想查看某些层的参数,以神经网络的第一层参数为例,可按照以下方法进行。
# 参数说明
# 第一层的参数:
layer1_weight = model.linear1.weight.data
layer1_bias = model.linear1.bias.data
print("layer1_weight", layer1_weight)
print("layer1_weight.shape", layer1_weight.shape)
print("layer1_bias", layer1_bias)
print("layer1_bias.shape", layer1_bias.shape)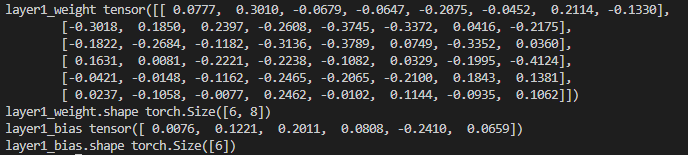
第一层的权重是6*8维的。。。
混淆矩阵:(1条消息) 机器学习常用评价指标:ACC、AUC、ROC曲线_auc和acc_追梦*小生的博客-CSDN博客
补充:准确率acc为评价指标的代码写法
torch.where torch.where — PyTorch 2.0 documentation
y_pred_label = torch.where(y_pred>=0.5,torch.tensor([1.0]),torch.tensor([0.0]))
acc = torch.eq(y_pred_label, y_data).sum().item()/y_data.size(0)
print("loss = ",loss.item(), "acc = ",acc)
————————————————
版权声明:本文为CSDN博主「错错莫」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/bit452/article/details/109682078练习:测试不同的激活单元对神经网络性能的影响
ReLU:不连续
softplus:连续的
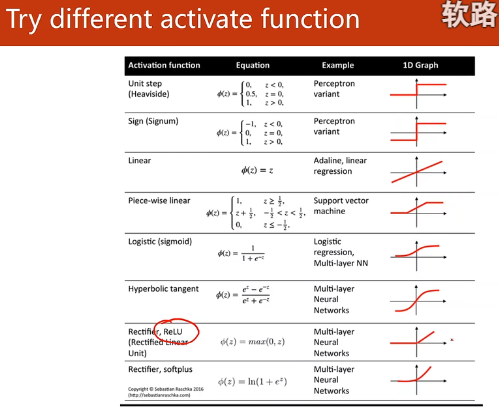
不同的激活函数: torch.nn — PyTorch 2.0 documentation
可以用在自己的网络中,其他结构一样,只换成不同的激活函数,观察他们的损失曲线并记录。可以画图表比较谁的训练速度比较快,谁能找到更优的收敛
记住:ReLU函数的取值是(0,1),如果前馈中最后的输入是<0的,最后y^会输出0,此时有风险,在loss中会计算lny^!所以在最后一个前馈建模时还是使用sigmoid函数,这样的话最后结果是在(0,1)之间较为光滑。

import numpy as np
import torch
import matplotlib.pyplot as plt
# prepare dataset
xy = np.loadtxt('PyTorch_exercise\diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # 第一个‘:’是指读取所有行,第二个‘:’是指从第一列开始,最后一列不要
y_data = torch.from_numpy(xy[:, [-1]]) # [-1] 最后得到的是个矩阵
# design model using class
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6) # 输入数据x的特征是8维,x有8个特征
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid() # 一个类
self.activate = torch.nn.ReLU()
def forward(self, x):
# x = self.sigmoid(self.linear1(x))
# x = self.sigmoid(self.linear2(x))
# x = self.sigmoid(self.linear3(x)) # y hat
x = self.activate(self.linear1(x))
x = self.activate(self.linear2(x))
x = self.sigmoid(self.linear3(x)) # y hat
return x
model = Model()
# construct loss and optimizer
# criterion = torch.nn.BCELoss(size_average = True)
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epoch_list = []
loss_list = []
# training cycle forward, backward, update
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()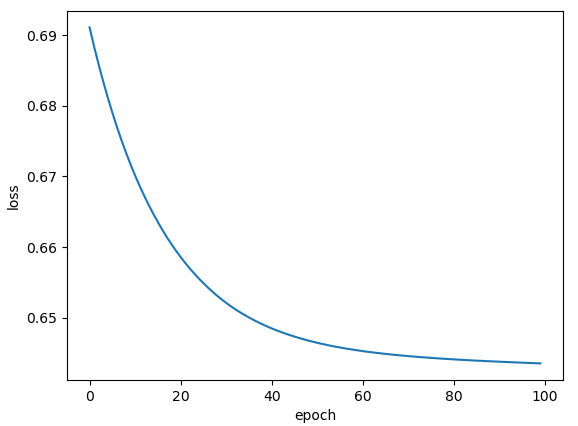
大致比较了一下两张图片,针对这种模型情况,三层激活函数都用sigmoid更好,损失函数下降更快。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









