







目录
摘要
- 虽然基于 T r a n s f o r m e r Transformer Transformer的方法在长期时间序列预测中显著提高了最新的技术水平,但它们不仅计算开销高,而且更重要的是,它们无法捕捉时间序列的全局视图(例如,总体趋势)。为了解决这些问题,我们提出将 T r a n s f o r m e r Transformer Transformer与季节-趋势分解方法相结合,其中分解方法捕捉时间序列的全局特征,而Transformer捕捉更详细的结构。为了进一步提升 T r a n s f o r m e r Transformer Transformer在长期预测中的性能,我们利用大多数时间序列在诸如傅里叶变换等良好已知基底中具有稀疏表示的事实,并开发了一种频率增强 T r a n s f o r m e r Transformer Transformer。除了更有效外,所提出的方法,即频率增强分解 T r a n s f o r m e r ( F E D f o r m e r ) Transformer(FEDformer) Transformer(FEDformer),比标准 T r a n s f o r m e r Transformer Transformer在序列长度上的复杂性更为线性。我们的实证研究显示,在六个基准数据集上的实验表明,与最新的方法相比, F E D f o r m e r FEDformer FEDformer在多变量和单变量时间序列的预测误差上分别减少了 14.8 14.8% 14.8和 22.6 22.6% 22.6。代码可以在以下网址获得:https://github.com/MAZiqing/FEDformer。
1. 引言
尽管基于
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer的方法在时间序列预测方面取得了进展,但它们往往无法在某些情况下捕捉时间序列的整体特征/分布。在图1中,我们将真实世界
E
T
T
m
1
ETTm1
ETTm1数据集(
Z
h
o
u
Zhou
Zhou等,
2021
2021
2021)中基于
v
a
n
i
l
l
a
T
r
a
n
s
f
o
r
m
e
r
vanilla\ Transformer
vanilla Transformer方法(
V
a
s
w
a
n
i
Vaswani
Vaswani等,
2017
2017
2017)的预测时间序列与实际时间序列进行了比较。很明显,预测的时间序列与实际时间序列显示了不同的分布。实际和预测之间的差异可以通过
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer中的逐点注意力和预测来解释。由于每个时间步的预测是独立和单独进行的,很可能模型未能维护时间序列整体的全局属性和统计特性。为了解决这个问题,我们在这项工作中利用了两个想法。第一个想法是将时间序列分析中广泛使用的季节-趋势分解方法(
C
l
e
v
e
l
a
n
d
Cleveland
Cleveland等,
1990
1990
1990;
W
e
n
Wen
Wen等,
2019
2019
2019)引入到基于
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer的方法中。尽管这一想法之前已经被利用(
O
r
e
s
h
k
i
n
Oreshkin
Oreshkin等,
2019
2019
2019;
W
u
Wu
Wu等,
2021
2021
2021),我们提出了一种特殊的网络设计,该设计在将预测分布与实际分布接近方面有效,根据
K
o
l
m
o
g
o
r
o
v
−
S
m
i
r
n
o
v
Kolmogorov-Smirnov
Kolmogorov−Smirnov分布检验。我们的第二个想法是将傅里叶分析与T
r
a
n
s
f
o
r
m
e
r
ransformer
ransformer结合使用。与其将
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer应用于时间域,我们将其应用于频率域,从而帮助
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer更好地捕捉时间序列的全局特性。结合这两个想法,我们提出了一种频率增强分解
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer,简称
F
E
D
f
o
r
m
e
r
FEDformer
FEDformer,用于长期时间序列预测。
关于
F
E
D
f
o
r
m
e
r
FEDformer
FEDformer的一个关键问题是傅里叶分析应该使用哪些频率成分来表示时间序列。一种常见的智慧是保留低频成分,去除高频成分。这可能不适用于时间序列预测,因为一些趋势变化的时间序列与重要事件有关,如果我们简单地去除所有高频成分,这部分信息可能会丢失。我们通过有效利用时间序列在傅里叶基底上具有(未知)稀疏表示的事实来解决这个问题。根据我们的理论分析,随机选择的一组频率成分,包括高频和低频成分,将为时间序列提供更好的表示,这进一步通过广泛的实证研究得到了验证。除了在长期预测中更有效外,将
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer与频率分析相结合还允许我们将
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer的计算成本从二次复杂度降低到线性复杂度。我们注意到,这与之前的加速
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer的方法不同,这些方法往往导致性能下降。
简而言之,我们总结了这项工作的主要贡献如下:
- 我们提出了一种频率增强分解 T r a n s f o r m e r Transformer Transformer架构,结合了季节-趋势分解的专家,以更好地捕捉时间序列的全局特性。
- 我们在 T r a n s f o r m e r Transformer Transformer结构中提出了傅里叶增强块和小波增强块,使我们能够通过频率域映射捕捉时间序列中的重要结构。它们作为自注意力和交叉注意力块的替代品。
- 通过随机选择固定数量的傅里叶成分,所提出的模型实现了线性的计算复杂度和内存成本。该选择方法的有效性在理论和实证上都得到了验证。
- 我们在 6 6 6个基准数据集上进行了广泛的实验,这些数据集跨越多个领域(能源、交通、经济、天气和疾病)。我们的实证研究表明,所提出的模型在多变量和单变量预测中的性能比最新的方法分别提高了 14.8 14.8% 14.8和 22.6 22.6% 22.6。
2. 频域中时间序列的紧凑表示
众所周知,时间序列数据可以从时间域和频率域建模。我们的工作中一个关键的贡献是与其他长期预测算法区分开来的频率域操作结合神经网络。傅里叶分析是深入频率域的常用工具,但如何适当地表示时间序列中的信息是至关重要的。简单地保留所有频率成分可能会导致劣质表示,因为许多时间序列中的高频变化是由于噪声输入而导致的。另一方面,仅保留低频成分可能也不适用于序列预测,因为一些趋势变化的时间序列代表重要事件。相反,使用少量选定的傅里叶成分保持时间序列的紧凑表示将有助于
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer的高效计算,这对于长序列建模至关重要。我们建议通过随机选择一组傅里叶成分来表示时间序列,包括高频和低频。下面介绍了一种仅在理论上证明了随机选择方法的分析。实证验证将在实验部分进行。
假设我们有
m
m
m个时间序列,表示为
X
1
(
t
)
,
…
,
X
m
(
t
)
X_1(t), \ldots, X_m(t)
X1(t),…,Xm(t)。通过对每个时间序列应用傅里叶变换,我们将每个
X
i
(
t
)
X_i(t)
Xi(t)转换为一个向量
a
i
=
(
a
i
,
1
,
…
,
a
i
,
d
)
T
∈
R
d
a_i = (a_{i,1}, \ldots, a_{i,d})^T \in \mathbb{R}^d
ai=(ai,1,…,ai,d)T∈Rd。将所有傅里叶变换向量放入矩阵中,我们得到
A
=
(
a
1
,
a
2
,
…
,
a
m
)
T
∈
R
m
×
d
A = (a_1, a_2, \ldots, a_m)^T \in \mathbb{R}^{m \times d}
A=(a1,a2,…,am)T∈Rm×d,其中每一行对应一个不同的时间序列,每一列对应一个不同的傅里叶成分。尽管使用所有的傅里叶成分允许我们最好地保留时间序列中的历史信息,但这可能会导致历史数据的过拟合,从而导致对未来信号的预测较差。因此,我们需要选择一组傅里叶成分,一方面,这组成分应该足够小以避免过拟合问题;另一方面,应该能够保留大部分的历史信息。在这里,我们建议从
d
d
d个傅里叶成分中随机选择
s
s
s个成分(
s
<
d
s < d
s<d)。更具体地说,我们用
i
1
<
i
2
<
…
<
i
s
i_1 < i_2 < \ldots < i_s
i1<i2<…<is来表示随机选择的成分。我们构建矩阵
S
∈
{
0
,
1
}
s
×
d
S \in \{0, 1\}^{s \times d}
S∈{0,1}s×d,其中
S
i
,
k
=
1
S_{i,k} = 1
Si,k=1如果
i
=
i
k
i = i_k
i=ik,否则
S
i
,
k
=
0
S_{i,k} = 0
Si,k=0。然后,我们对多变量时间序列的表示变为
A
′
=
A
S
T
∈
R
m
×
s
A' = AS^T \in \mathbb{R}^{m \times s}
A′=AST∈Rm×s。下文将展示,尽管傅里叶基是随机选择的,在温和条件下,
A
′
A'
A′能够保留大部分来自
A
A
A的信息。
为了衡量
A
′
A'
A′在多大程度上能保留
A
A
A的信息,我们将
A
A
A的每个列向量投影到
A
′
A'
A′中的列向量所跨越的子空间中。我们用
P
A
′
(
A
)
P_{A'}(A)
PA′(A)表示投影后的矩阵,其中
P
A
′
(
⋅
)
P_{A'}(\cdot)
PA′(⋅)表示投影算子。如果
A
′
A'
A′保留了
A
A
A的大部分信息,我们期望
A
A
A和
P
A
′
(
A
)
P_{A'}(A)
PA′(A)之间的误差很小,即
∣
A
P
A
′
(
A
)
∣
|A P_{A'}(A)|
∣APA′(A)∣。令
A
k
A_k
Ak表示
A
A
A的前
k
k
k个最大奇异值分解的近似。下面的定理表明,如果随机采样的傅里叶成分数量
s
s
s在
k
2
k^2
k2的数量级上,则
∣
A
P
A
′
(
A
)
∣
|A P_{A'}(A)|
∣APA′(A)∣接近于
∣
A
−
A
k
∣
|A - A_k|
∣A−Ak∣。
定理1. 假设矩阵 A A A的相干性测度 μ ( A ) \mu(A) μ(A)是 Ω ( k / n ) \Omega(k/n) Ω(k/n)。那么,以高概率,有
∣
A
−
P
A
′
(
A
)
∣
≤
(
1
+
ϵ
)
∣
A
−
A
k
∣
|A - P_{A'}(A)| \leq (1 + \epsilon)|A - A_k|
∣A−PA′(A)∣≤(1+ϵ)∣A−Ak∣
如果
s
=
O
(
k
2
/
ϵ
2
)
s = O(k^2/\epsilon^2)
s=O(k2/ϵ2)。
对于真实世界的多变量时间序列,从傅里叶变换获得的相应矩阵
A
A
A通常表现出低秩属性,因为这些多变量时间序列不仅依赖于过去的值,还依赖于彼此之间的变化,以及共享相似频率分量。因此,如定理1所示,通过随机选择一组傅里叶成分,可以适当地表示傅里叶矩阵
A
A
A中的时间序列信息。
同样,小波正交多项式,例如勒让德多项式,遵循受限等距性质(
R
I
P
RIP
RIP),也可用于捕捉时间序列中的信息。与傅里叶基底相比,小波基底在捕捉时间序列的局部结构方面更有效,因此在某些预测任务中更为有效。我们将小波基底表示的讨论推迟到附录
B
B
B。在下一节中,我们将展示将傅里叶变换融入到
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer中的频率增强分解
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer架构的设计。
3 模型结构
在本节中,我们将介绍(
1
1
1)如图
2
2
2所示的
F
E
D
f
o
r
m
e
r
FEDformer
FEDformer的总体结构,(2)用于信号处理的两个子结构:一个使用傅里叶基,另一个使用小波基,(3)季节-趋势分解的专家机制混合,(4)提出模型的复杂性分析。
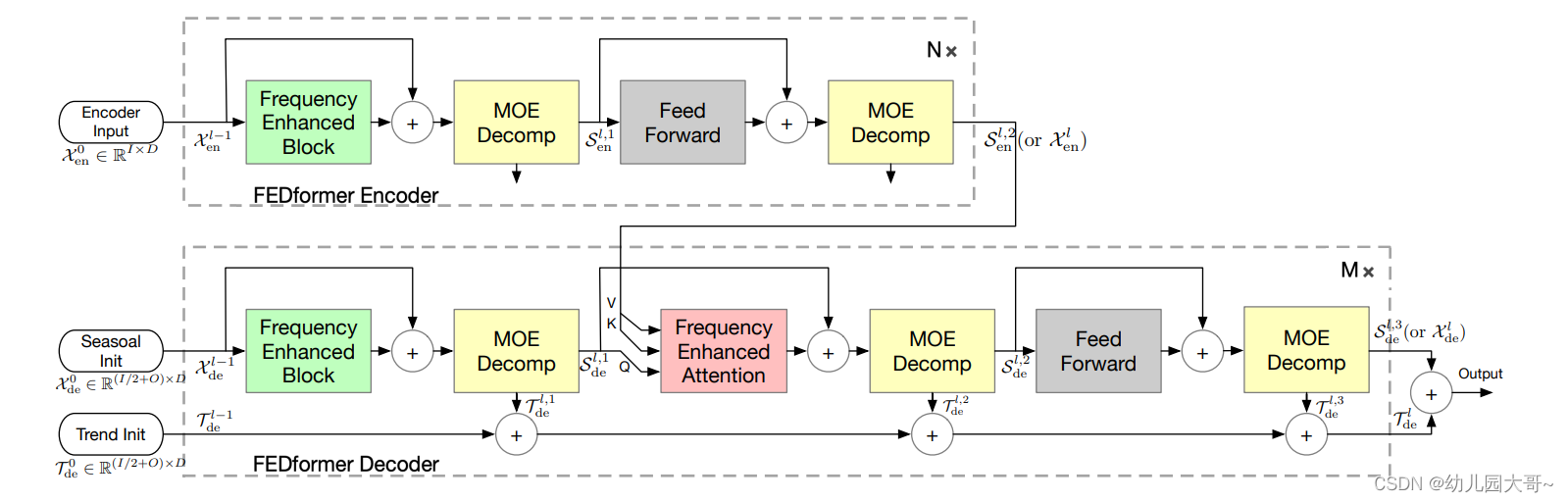
图2. FEDformer结构。
FEDformer由N个编码器和M个解码器组成。频域增强块(FEB,绿色块)和频域增强注意力(FEA,红色块)用于在频域中进行表示学习。FEB或FEA有两个子版本(FEB-f & FEB-w或FEA-f & FEA-w),其中“-f”表示使用傅里叶基底,“-w”表示使用小波基底。专家分解混合块(MOEDecomp,黄色块)用于从输入数据中提取季节趋势模式。
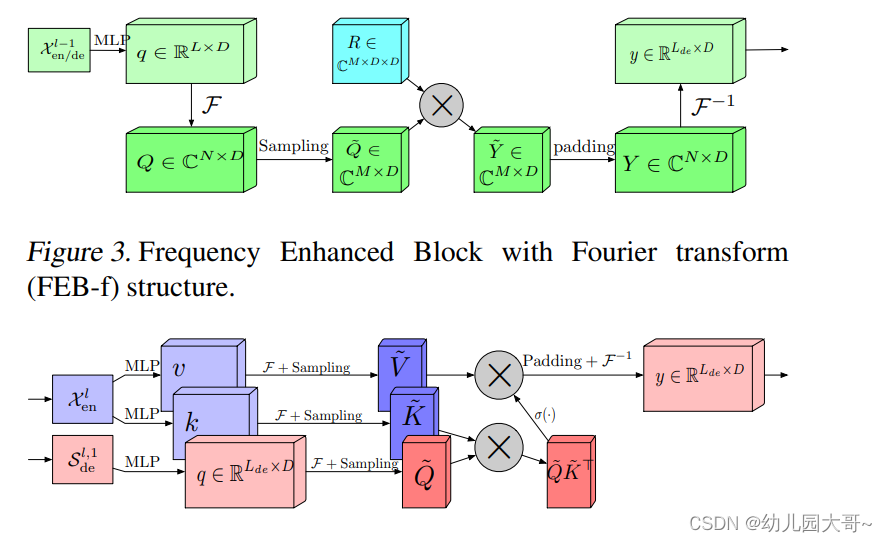
图3. 采用傅里叶变换的频域增强块(FEB-f)结构。
图4. 采用傅里叶变换的频域增强注意力(FEA-f)结构,σ(·)为激活函数。
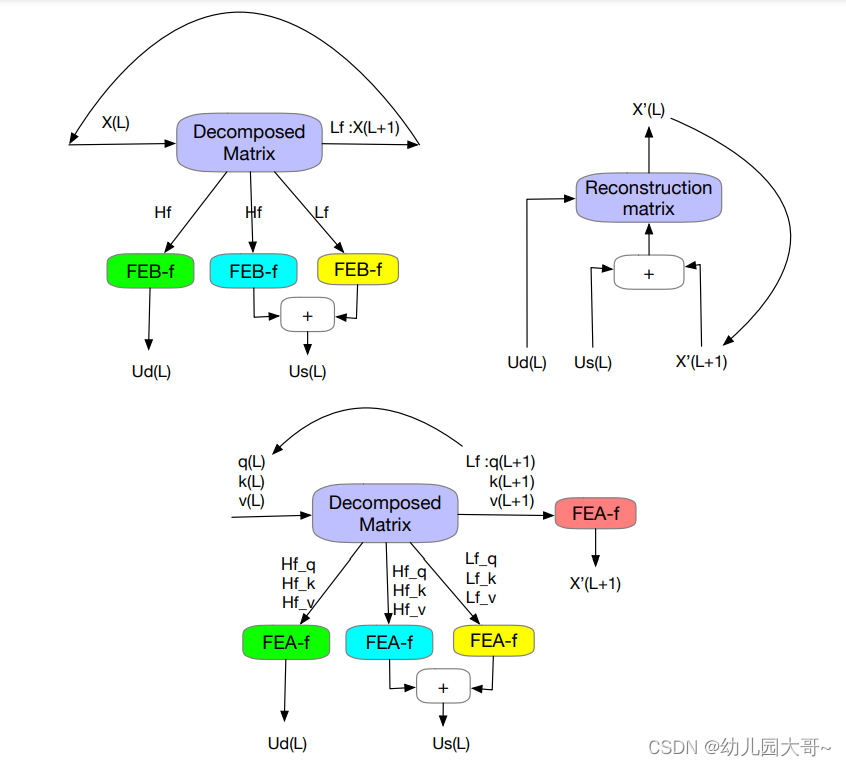
图5.左上:小波频域增强块分解阶段。右上:FEB-w和FEA-w共享的小波块重建阶段。底部:小波频域增强交叉注意力分解阶段。
3.1 FEDformer 框架
初步 长期时间序列预测是一个序列到序列的问题。我们将输入长度表示为 I I I,输出长度表示为 O O O。我们将 D D D表示为系列的隐藏状态。编码器的输入是 I × D I \times D I×D矩阵,解码器的输入是 ( I / 2 + O ) × D (I/2 + O) \times D (I/2+O)×D。
FEDformer 结构 受到第一节中讨论的季节-趋势分解和分布分析的启发,我们将
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer重新设计为一种深度分解架构,如图2所示,包括频率增强块(
F
E
B
FEB
FEB)、频率增强注意力
编码器采用多层结构,如下所示:
X
en
l
=
Encoder
(
X
en
l
−
1
)
,
\mathbf{X}_{\text{en}}^{l} = \text{Encoder}(\mathbf{X}_{\text{en}}^{l-1}),
Xenl=Encoder(Xenl−1),
其中
l
∈
{
1
,
⋯
,
N
}
l \in \{1, \cdots, N\}
l∈{1,⋯,N}表示第
l
l
l层编码器的输出,
X
en
∈
R
I
×
D
\mathbf{X}_{\text{en}} \in \mathbb{R}^{I \times D}
Xen∈RI×D是嵌入的历史序列。编码器的公式化如下:
S
en
1
,
i
=
MOEDecomp
(
FEB
(
X
en
l
−
1
+
X
en
l
−
1
)
)
,
S
en
2
,
i
=
MOEDecomp
(
FeedForward
(
S
en
1
,
i
+
S
en
1
,
i
)
)
,
X
en
l
=
S
en
2
,
i
,
\begin{aligned} \mathbf{S}_{\text{en}}^{1, i} &= \text{MOEDecomp}(\text{FEB}(\mathbf{X}_{\text{en}}^{l-1} + \mathbf{X}_{\text{en}}^{l-1})), \\ \mathbf{S}_{\text{en}}^{2, i} &= \text{MOEDecomp}(\text{FeedForward}(\mathbf{S}_{\text{en}}^{1, i} + \mathbf{S}_{\text{en}}^{1, i})), \\ \mathbf{X}_{\text{en}}^{l} &= \mathbf{S}_{\text{en}}^{2, i}, \end{aligned}
Sen1,iSen2,iXenl=MOEDecomp(FEB(Xenl−1+Xenl−1)),=MOEDecomp(FeedForward(Sen1,i+Sen1,i)),=Sen2,i,
其中
i
∈
{
1
,
2
}
i \in \{1, 2\}
i∈{1,2}分别表示第
l
l
l层的第
i
i
i个分解块后的季节性成分。对于FEB模块,它有两种不同版本(
F
E
B
−
F
FEB-F
FEB−F 和
F
E
B
−
W
FEB-W
FEB−W),分别通过离散傅里叶变换(
D
F
T
DFT
DFT)和离散小波变换(
D
W
T
DWT
DWT)机制实现,可以无缝替换自注意力模块。
解码器也采用多层结构,如下所示:
X
de
l
,
T
de
l
=
Decoder
(
X
de
l
−
1
,
T
de
l
−
1
)
,
\mathbf{X}_{\text{de}}^{l}, \mathbf{T}_{\text{de}}^{l} = \text{Decoder}(\mathbf{X}_{\text{de}}^{l-1}, \mathbf{T}_{\text{de}}^{l-1}),
Xdel,Tdel=Decoder(Xdel−1,Tdel−1),
其中
l
∈
{
1
,
⋯
,
M
}
l \in \{1, \cdots, M\}
l∈{1,⋯,M}表示第
l
l
l层解码器的输出。解码器的公式化如下:
S
de
1
,
i
,
T
de
1
,
i
=
MOEDecomp
(
FEB
(
X
de
l
−
1
+
X
en
l
)
)
,
S
de
2
,
i
,
T
de
2
,
i
=
MOEDecomp
(
FEA
(
S
de
1
,
i
+
S
en
1
,
i
)
)
,
S
de
3
,
i
,
T
de
3
,
i
=
MOEDecomp
(
FeedForward
(
S
de
2
,
i
+
S
de
2
,
i
)
)
,
X
de
l
=
S
de
3
,
i
+
T
de
1
,
i
⋅
W
1
,
i
+
T
de
2
,
i
⋅
W
2
,
i
+
T
de
3
,
i
⋅
W
3
,
i
,
\begin{aligned} \mathbf{S}_{\text{de}}^{1, i}, \mathbf{T}_{\text{de}}^{1, i} &= \text{MOEDecomp}(\text{FEB}(\mathbf{X}_{\text{de}}^{l-1} + \mathbf{X}_{\text{en}}^{l})), \\ \mathbf{S}_{\text{de}}^{2, i}, \mathbf{T}_{\text{de}}^{2, i} &= \text{MOEDecomp}(\text{FEA}(\mathbf{S}_{\text{de}}^{1, i} + \mathbf{S}_{\text{en}}^{1, i})), \\ \mathbf{S}_{\text{de}}^{3, i}, \mathbf{T}_{\text{de}}^{3, i} &= \text{MOEDecomp}(\text{FeedForward}(\mathbf{S}_{\text{de}}^{2, i} + \mathbf{S}_{\text{de}}^{2, i})), \\ \mathbf{X}_{\text{de}}^{l} &= \mathbf{S}_{\text{de}}^{3, i} + \mathbf{T}_{\text{de}}^{1, i} \cdot \mathbf{W}_{1, i} + \mathbf{T}_{\text{de}}^{2, i} \cdot \mathbf{W}_{2, i} + \mathbf{T}_{\text{de}}^{3, i} \cdot \mathbf{W}_{3, i}, \end{aligned}
Sde1,i,Tde1,iSde2,i,Tde2,iSde3,i,Tde3,iXdel=MOEDecomp(FEB(Xdel−1+Xenl)),=MOEDecomp(FEA(Sde1,i+Sen1,i)),=MOEDecomp(FeedForward(Sde2,i+Sde2,i)),=Sde3,i+Tde1,i⋅W1,i+Tde2,i⋅W2,i+Tde3,i⋅W3,i,
其中
i
∈
{
1
,
2
,
3
}
i \in \{1, 2, 3\}
i∈{1,2,3}分别表示第
l
l
l层分解块后的季节性和趋势成分。
W
i
,
i
\mathbf{W}_{i, i}
Wi,i表示第
i
i
i个提取的趋势
T
de
l
,
i
\mathbf{T}_{\text{de}}^{l, i}
Tdel,i的投影。类似于FEB,FEA有两种不同版本(
F
E
A
−
F
FEA-F
FEA−F 和
F
E
A
−
W
FEA-W
FEA−W),分别通过
D
F
T
DFT
DFT和
D
W
T
DWT
DWT机制实现,可以替换交叉注意力块。
F
E
A
FEA
FEA的详细描述将在第
3.3
3.3
3.3节中给出。
最终预测是两个精细分解成分的总和,即
W
s
⋅
X
de
M
+
T
de
M
W_s \cdot \mathbf{X}_{\text{de}}^{M} + \mathbf{T}_{\text{de}}^{M}
Ws⋅XdeM+TdeM,其中
W
s
W_s
Ws是将深度变换后的季节性成分
X
de
M
\mathbf{X}_{\text{de}}^{M}
XdeM投影到目标维度。
3.2 傅里叶增强结构
离散傅里叶变换 (DFT) 提出的傅里叶增强结构使用离散傅里叶变换( D F T DFT DFT)。设 F \mathcal{F} F表示傅里叶变换, F − 1 \mathcal{F}^{-1} F−1表示逆傅里叶变换。给定一系列时间域中的实数 x n x_n xn,其中 n = 1 , 2 , … , N n = 1, 2, \ldots, N n=1,2,…,N。 D F T DFT DFT定义为
X l = ∑ n = 0 N − 1 x n e − i ω l n , X_l = \sum_{n=0}^{N-1} x_n e^{-i\omega l n}, Xl=∑n=0N−1xne−iωln,其中 i i i是虚数单位, X l X_l Xl表示频域中的复数序列, l = 1 , 2 , … , L l = 1, 2, \ldots, L l=1,2,…,L。
类似地,逆 D F T DFT DFT定义为
x n = 1 L ∑ l = 0 L − 1 X l e i ω l n 。 x_n = \frac{1}{L} \sum_{l=0}^{L-1} X_l e^{i\omega l n}。 xn=L1∑l=0L−1Xleiωln。
DFT的复杂度是 O ( N 2 ) O(N^2) O(N2)。使用快速傅里叶变换( F F T FFT FFT),计算复杂度可以降低到 O ( N log N ) O(N \log N) O(NlogN)。这里,通过选择 D F T DFT DFT和逆 D F T DFT DFT操作之前的傅里叶基的随机子集,并使子集的规模由标量界定,计算复杂度可以进一步降低到 O ( N ) O(N) O(N)。
频率增强块( F E B FEB FEB)与傅里叶变换( F E B − f FEB-f FEB−f)
F E B − f FEB-f FEB−f在编码器和解码器中使用,如图2所示。 F E B − f FEB-f FEB−f块的输入 x ∈ R N × D x \in \mathbb{R}^{N \times D} x∈RN×D首先通过权重 w ∈ R D × D w \in \mathbb{R}^{D \times D} w∈RD×D线性投影为 q = x ⋅ w q = x \cdot w q=x⋅w。然后 q q q从时间域转换到频率域。 q q q的傅里叶变换定义为 Q ∈ C N × D Q \in \mathbb{C}^{N \times D} Q∈CN×D。在频率域中,仅保留随机选择的 M M M个模式,因此我们使用选择算子将其定义为
Q ~ = Select ( Q ) = Select ( F ( q ) ) , \tilde{Q} = \text{Select}(Q) = \text{Select}(\mathcal{F}(q)), Q~=Select(Q)=Select(F(q)),其中 Q ~ ∈ C M × D \tilde{Q} \in \mathbb{C}^{M \times D} Q~∈CM×D且 M ≪ N M \ll N M≪N。然后, F E B − f FEB-f FEB−f 定义为 FEB-f ( q ) = F − 1 ( Padding ( Q ~ ⊙ R ) ) , \text{FEB-f}(q) = \mathcal{F}^{-1}(\text{Padding}(\tilde{Q} \odot R)), FEB-f(q)=F−1(Padding(Q~⊙R)),其中 R ∈ C D × D × M R \in \mathbb{C}^{D \times D \times M} R∈CD×D×M是一个参数化的随机初始化核。令 Y = Q ⊙ C Y = Q \odot C Y=Q⊙C,其中 Y ∈ C M × D Y \in \mathbb{C}^{M \times D} Y∈CM×D。生产算子定义为: Y m , d o = ∑ d i = 1 D Q m , d i ⋅ R d i , d o , m , Y_{m, d_o} = \sum_{d_i=1}^{D} Q_{m, d_i} \cdot R_{d_i, d_o, m}, Ym,do=∑di=1DQm,di⋅Rdi,do,m,
其中 d i = 1 , 2 , … , D d_i = 1, 2, \ldots, D di=1,2,…,D是输入通道, d o = 1 , 2 , … , D d_o = 1, 2, \ldots, D do=1,2,…,D是输出通道。 Q ⊙ R Q \odot R Q⊙R的结果在执行逆傅里叶变换回到时间域之前被零填充到 C N × D \mathbb{C}^{N \times D} CN×D。结构如图 3 3 3所示。
使用傅里叶变换的频率增强注意力(FEA-f)
我们使用经典 T r a n s f o r m e r Transformer Transformer的表达。输入的查询、键和值分别表示为 q ∈ R L × D q \in \mathbb{R}^{L \times D} q∈RL×D、 k ∈ R L × D k \in \mathbb{R}^{L \times D} k∈RL×D和 v ∈ R L × D v \in \mathbb{R}^{L \times D} v∈RL×D。在交叉注意力中,查询来自解码器,可以通过 q = x en ⋅ w q q = x_{\text{en}} \cdot w_q q=xen⋅wq获得,其中 w q ∈ R D × D w_q \in \mathbb{R}^{D \times D} wq∈RD×D。键和值来自编码器,可以通过 k = x de ⋅ w k k = x_{\text{de}} \cdot w_k k=xde⋅wk和 v = x de ⋅ w v v = x_{\text{de}} \cdot w_v v=xde⋅wv获得,其中 w k , w v ∈ R D × D w_k, w_v \in \mathbb{R}^{D \times D} wk,wv∈RD×D。形式上,经典注意力可以表示为:
Atten ( q , k , v ) = Softmax ( q k ⊤ d q ) v . \text{Atten}(q, k, v) = \text{Softmax}\left(\frac{q k^\top}{\sqrt{d_q}}\right)v. Atten(q,k,v)=Softmax(dqqk⊤)v.
在
F
E
A
−
f
FEA-f
FEA−f中,我们将查询、键和值转换为傅里叶变换,并在频率域中通过随机选择M个模式来执行类似的注意力机制。傅里叶变换后的选择版本分别表示为
Q
~
∈
C
M
×
D
\tilde{Q} \in \mathbb{C}^{M \times D}
Q~∈CM×D、
K
~
∈
C
M
×
D
\tilde{K} \in \mathbb{C}^{M \times D}
K~∈CM×D和
V
~
∈
C
M
×
D
\tilde{V} \in \mathbb{C}^{M \times D}
V~∈CM×D。
F
E
A
−
f
FEA-f
FEA−f 定义为:
Q
~
=
Select
(
F
(
q
)
)
,
K
~
=
Select
(
F
(
k
)
)
,
V
~
=
Select
(
F
(
v
)
)
,
FEA-f
(
q
,
k
,
v
)
=
F
−
1
(
Padding
(
σ
(
Q
~
⋅
K
~
⊤
)
⋅
V
~
)
)
,
\tilde{Q} = \text{Select}(\mathcal{F}(q)),\\ \tilde{K} = \text{Select}(\mathcal{F}(k)),\\ \tilde{V} = \text{Select}(\mathcal{F}(v)),\\ \text{FEA-f}(q, k, v) = \mathcal{F}^{-1}\left(\text{Padding}\left(\sigma(\tilde{Q} \cdot \tilde{K}^\top) \cdot \tilde{V}\right)\right),
Q~=Select(F(q)),K~=Select(F(k)),V~=Select(F(v)),FEA-f(q,k,v)=F−1(Padding(σ(Q~⋅K~⊤)⋅V~)),
其中
σ
\sigma
σ是激活函数。我们使用
s
o
f
t
m
a
x
softmax
softmax或
t
a
n
h
tanh
tanh作为激活函数,因为它们在不同数据集上的收敛性能有所不同。令
Y
=
σ
(
Q
~
⋅
K
~
⊤
)
⋅
V
~
Y = \sigma(\tilde{Q} \cdot \tilde{K}^\top) \cdot \tilde{V}
Y=σ(Q~⋅K~⊤)⋅V~,并在执行逆傅里叶变换之前,将
Y
∈
C
M
×
D
Y \in \mathbb{C}^{M \times D}
Y∈CM×D零填充到
C
N
×
D
\mathbb{C}^{N \times D}
CN×D。FEA-f结构如图4所示。
3.3 小波增强结构
离散小波变换(DWT) 虽然傅里叶变换在频率域中创建信号的表示,小波变换在频率和时间域中创建表示,允许高效访问信号的局部信息。多小波变换结合了正交多项式和小波的优点。对于给定的 f ( x ) f(x) f(x),在尺度 n n n上的多小波系数可以分别定义为:
s i n = ⟨ f , φ i μ n ⟩ μ n = 0 k − 1 , d i n = ⟨ f , ψ i μ n ⟩ μ n = 0 k − 1 , s_i^n = \left\langle f, \varphi_i^{\mu_n} \right\rangle_{\mu_n=0}^{k-1}, \quad d_i^n = \left\langle f, \psi_i^{\mu_n} \right\rangle_{\mu_n=0}^{k-1}, sin=⟨f,φiμn⟩μn=0k−1,din=⟨f,ψiμn⟩μn=0k−1,
其中 φ i μ n , ψ i μ n ∈ R k × 2 n \varphi_i^{\mu_n}, \psi_i^{\mu_n} \in \mathbb{R}^{k \times 2^n} φiμn,ψiμn∈Rk×2n分别是分段多项式的正交小波基。跨尺度的分解/重构过程定义为:
s i n = H ( 0 ) s 2 i n + 1 + H ( 1 ) s 2 i + 1 n + 1 , s 2 i n + 1 = ∑ H ( 0 ) s i n + G ( 0 ) d i n , d i n = G ( 0 ) s 2 i n + 1 + G ( 1 ) s 2 i + 1 n + 1 , d 2 i n + 1 = ∑ G ( 1 ) s i n + G ( 1 ) d i n , \begin{aligned} s_i^n &= H^{(0)} s_{2i}^{n+1} + H^{(1)} s_{2i+1}^{n+1}, \\ s_{2i}^{n+1} &= \sum H^{(0)} s_i^n + G^{(0)} d_i^n, \\ d_i^n &= G^{(0)} s_{2i}^{n+1} + G^{(1)} s_{2i+1}^{n+1}, \\ d_{2i}^{n+1} &= \sum G^{(1)} s_i^n + G^{(1)} d_i^n, \end{aligned} sins2in+1dind2in+1=H(0)s2in+1+H(1)s2i+1n+1,=∑H(0)sin+G(0)din,=G(0)s2in+1+G(1)s2i+1n+1,=∑G(1)sin+G(1)din,
其中 H ( 0 ) , H ( 1 ) , G ( 0 ) , G ( 1 ) H^{(0)}, H^{(1)}, G^{(0)}, G^{(1)} H(0),H(1),G(0),G(1)是用于多小波分解滤波器的线性系数。它们是用于小波分解的固定矩阵。
多小波表示可以通过多尺度和多小波基的张量积获得。注意,不同尺度的基是通过张量积耦合的,所以我们需要解耦它们。受到( G u p t a Gupta Gupta等人, 2021 2021 2021)的启发,我们采用了一种非标准的小波表示来减少模型复杂度。对于映射函数 F ( x ) = x ′ F(x) = x' F(x)=x′,在多小波域下的映射可以写为:
U s l n = A n d s l n + B n s s l n , U s l n = C n d l n , U s l L = F s l L , \begin{aligned} U_{sl}^n &= A_n d_{sl}^n + B_n s_{sl}^n, \\ U_{sl}^n &= C_n d_l^n, \\ U_{sl}^L &= \mathcal{F} s_l^L, \end{aligned} UslnUslnUslL=Andsln+Bnssln,=Cndln,=FslL,
其中 ( U s l n , U s l n , d l n , s l n ) (U_{sl}^n, U_{sl}^n, d_l^n, s_l^n) (Usln,Usln,dln,sln)是多尺度、多小波系数, L L L是递归分解的最粗尺度, A n , B n , C n A_n, B_n, C_n An,Bn,Cn是用于不同信号在分解和重构过程中处理的三个独立的 F E B − f FEB-f FEB−f模块。这里 F \mathcal{F} F是一个单层感知器,用于在 L L L个分解步骤后处理剩余的最粗信号。更多的设计细节在附录 D D D中描述。
使用小波变换的频率增强块(FEB-w)
F E B − w FEB-w FEB−w的整体架构如图5所示。它在递归机制上与FEB-f有所不同:输入被递归地分解成 3 3 3部分并分别操作。对于小波分解部分,我们实现了固定的勒让德小波基分解矩阵。使用三个 F E B − f FEB-f FEB−f模块分别处理高频部分、低频部分和小波分解的剩余部分。对于每个循环 L L L,它生成一个处理后的高频张量 U d ( L ) U_d(L) Ud(L)、一个处理后的低频张量 U s ( L ) U_s(L) Us(L)和一个原始低频张量 X ( L + 1 ) X(L+1) X(L+1)。这是一种阶梯式下降方法,分解阶段将信号按1/2的比例缩减,最多运行 L L L个循环,其中 L < log 2 ( M ) L < \log_2(M) L<log2(M)对于给定的输入序列大小 M M M。在实践中, L L L被设置为一个固定参数。三个FEB-f模块集在不同的分解循环 L L L中共享。
对于小波重构部分,我们递归地构建输出张量。对于每个循环 L L L,我们结合从分解部分生成的 X ( L + 1 ) X(L+1) X(L+1)、 U s ( L ) U_s(L) Us(L)和 U d ( L ) U_d(L) Ud(L),并生成下一个重构循环的 X ( L ) X(L) X(L)。对于每个循环,信号张量的长度维度增加 2 2 2倍。
使用小波变换的频率增强注意力(FEA-w)
F E A − w FEA-w FEA−w 包含与 F E B − w FEB-w FEB−w 类似的分解阶段和重构阶段。我们在这里保持重构阶段不变。唯一的区别在于分解阶段。使用相同的分解矩阵分别分解 q q q、 k k k、 v v v信号,并且 q q q、 k k k、 v v v信号共享相同的模块集来处理。如上所述,一个包含小波分解块( F E B − w FEB-w FEB−w)的频率增强块包含三个 F E B − f FEB-f FEB−f 模块来处理信号过程。我们可以将 F E B − f FEB-f FEB−f 视为自注意力机制的替代。我们使用一种简单的方法来构建具有小波分解的频率增强交叉注意力,用 F E A − f FEA-f FEA−f 模块替代每个 F E B − f FEB-f FEB−f 模块。此外,还添加了另一个 F E A − f FEA-f FEA−f 模块来处理最粗的剩余信号 q ( L ) , k ( L ) , v ( L ) q(L), k(L), v(L) q(L),k(L),v(L)。
3.4 专家混合用于季节-趋势分解
由于在实际数据上常常观察到复杂的周期模式与趋势成分耦合,用固定窗口平均池提取趋势可能会很困难。为了克服这样的问题,我们设计了一个专家混合分解块( M O E D e c o m p MOEDecomp MOEDecomp)。它包含一组具有不同大小的平均滤波器,用于从输入信号中提取多个趋势成分,以及一组依赖于数据的权重,用于将它们组合为最终的趋势。形式上,我们有:
X trend = Softmax ( L ( x ) ) ∗ ( F ( x ) ) , \mathbf{X}_{\text{trend}} = \text{Softmax}(L(x)) \ast (F(x)), Xtrend=Softmax(L(x))∗(F(x)),
其中 F ( ⋅ ) F(\cdot) F(⋅)是一组平均池化滤波器, S o f t m a x ( L ( x ) ) Softmax(L(x)) Softmax(L(x)) 是用于混合这些提取的趋势的权重。
3.5 复杂性分析
对于 F E D f o r m e r − f FEDformer-f FEDformer−f,在 F E B FEB FEB和 F E A FEA FEA块中使用固定数量的随机选择模式时,时间和内存的计算复杂度为 O ( L ) O(L) O(L)。我们将模式数量 M = 64 M = 64 M=64设为默认值。虽然使用 F F T FFT FFT进行全 D F T DFT DFT变换的复杂度是 O ( L log ( L ) ) O(L \log(L)) O(Llog(L)),但我们的模型只需要 O ( L ) O(L) O(L)的成本和内存复杂度,预选的一组傅里叶基可以快速实现。
对于 F E D f o r m e r − w FEDformer-w FEDformer−w,当我们将递归分解步数设置为固定值 L L L,并使用与 F E D f o r m e r − f FEDformer-f FEDformer−f相同的随机选择模式数时,时间复杂度和内存使用量也是 O ( L ) O(L) O(L)。在实践中,我们选择 L = 3 L = 3 L=3和模式数量 M = 64 M = 64 M=64作为默认值。在表1中总结了训练和推理步骤中的时间复杂度和内存使用情况的比较。可以看出,所提出的 F E D f o r m e r FEDformer FEDformer在基于 T r a n s f o r m e r Transformer Transformer的预测模型中实现了最佳的总体复杂度。
















 3270
3270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









