







摘要
线性预测模型的近期热潮质疑了对Transformer基础架构进行修改的持续热情。这些预测器利用Transformer来建模时间序列的全局依赖性,每个时间序列标记由相同时间戳的多个变量组成。然而,Transformer在预测具有较大回溯窗口的时间序列时面临性能下降和计算爆炸的问题。此外,为每个时间序列标记嵌入的每个变量融合了多个表示潜在延迟事件和不同物理测量值的变量,这可能导致学习基于变量的表示并最终导致注意力图无意义。在这项工作中,我们反思了Transformer组件的职责,并在不修改基本组件的情况下重新利用Transformer架构。我们提出了iTransformer,它简单地在反转维度上应用了注意力和前馈网络。具体来说,各个序列的时间点被嵌入到变量标记中,注意力机制利用这些标记来捕捉多变量相关性;同时,前馈网络被应用于每个变量标记以学习非线性表示。iTransformer模型在具有挑战性的真实数据集上实现了最新的表现,这进一步提升了Transformer家族的性能,在不同的变量上具有推广能力,并且更好地利用了任意回溯窗口,使其成为时间序列预测的基本骨干替代方案。代码可在以下仓库中获得:https://github.com/thuml/iTransformer。
1. 介绍
Transformer(Vaswani et al., 2017)在自然语言处理(Brown et al., 2020)和计算机视觉(Dosovitskiy et al., 2021)方面取得了巨大的成功,成为遵循规模法则(Kaplan et al., 2020)的基础模型。受各个领域巨大成功的启发,Transformer凭借其强大的成对依赖关系描述能力和多层次表示提取能力在时间序列预测中正在崭露头角(Wu et al., 2021;Nie et al., 2023)。
然而,研究人员最近开始质疑基于Transformer的预测器的有效性,这些预测器通常将同一时间戳的多个变量嵌入到不可区分的通道中,并应用注意力机制来捕捉时间依赖关系。考虑到时间点之间的数值但较少语义关系,研究人员发现简单的线性层可以追溯到统计预测器(Box & Jenkins, 1968),其性能和效率超越了复杂的Transformers(Zeng et al., 2023;Das et al., 2023)。同时,确保变量的独立性和利用互信息在最新研究中被强调,用于显式建模多变量相关性以实现准确预测(Zhang & Yan, 2023;Ekambaram et al., 2023),但这在不颠覆传统Transformer架构的情况下很难实现。
考虑到对基于Transformer预测器的争议,我们反思为什么Transformers在时间序列预测中表现甚至不如线性模型。我们注意到,现有的基于Transformer的预测器架构可能不适合多变量时间序列预测。正如图2顶部所示,同一时间步的点基本上代表完全不同的物理意义,由于不一致的测量结果被嵌入到一个标记中,导致多变量相关性消失。而由单一时间步形成的标记由于过于局部的感受野和时间不对齐事件同时表示的原因,难以揭示有益信息。此外,虽然序列变化可以受序列顺序影响很大,但在时间维度上不变的注意力机制被错误采用(Zeng et al., 2023)。因此,Transformer在捕捉基本的系列表示和描绘多变量相关性方面变得薄弱,限制了其在各种时间序列数据上的容量和泛化能力。
关于将时间戳的多变量点嵌入为(时间)标记的潜在风险,我们采用对时间序列的逆向视角,将每个变量的整个时间序列独立地嵌入为一个(变量)标记,这是Patching的极端情况(Nie et al., 2023),扩大了局部感受野。通过逆向,嵌入的标记聚合了系列的全局表示,可以更加变量中心并通过多变量相关的蓬勃注意力机制更好地利用。同时,前馈网络可以有效捕捉任意回溯系列中编码的不同变量的可泛化表示,并解码以预测未来系列。
基于上述动机,我们认为Transformer并非对时间序列预测无效,而是被错误地使用了。在本文中,我们重新审视了Transformer的结构,并倡导iTransformer作为时间序列预测的基础骨干。技术上,我们将每个时间序列嵌入为变量标记(variate tokens),采用注意力机制来捕捉多变量相关性,并使用前馈网络进行序列表示。实验结果表明,提出的iTransformer在图1所示的真实世界预测基准上达到了最先进的性能,出人意料地解决了基于Transformer的预测器的痛点。我们的贡献在三个方面:
- 我们反思了Transformer的架构,并改进了原生Transformer组件在多变量时间序列上的能力,这一领域尚未充分探索。
- 我们提出了iTransformer,将独立的时间序列视为标记,通过自注意力机制捕捉多变量相关性,并利用层归一化和前馈网络模块学习更好的序列全局表示,用于时间序列预测。
- 实验表明,iTransformer在真实世界的基准上实现了全面的最先进性能。我们广泛分析了逆向模块和架构选择,指出了未来改进基于Transformer的预测器的有前景的方向。
2 相关工作
随着自然语言处理和计算机视觉领域的逐步突破,精心设计的Transformer变体被提议用于解决普遍的时间序列预测应用。超越当代TCNs(Bai et al., 2018;Liu et al., 2022a)和基于RNN的预测器(Zhao et al., 2017;Rangapuram et al., 2018;Salinas et al., 2020),Transformer展现了强大的序列建模能力和有前景的模型可扩展性,导致对时间序列预测进行改进的热情趋势。
通过对基于Transformer的预测器进行系统性的回顾,我们总结出现有的修改可以分为四类,依据是否修改组件和架构。正如图3所示,第一类(Wu et al., 2021;Li et al., 2021;Zhou et al., 2022)是最常见的做法,主要关注组件适配,特别是时间依赖建模的注意力模块和长序列的复杂性优化。然而,随着线性预测器的快速出现(Oreshkin et al., 2019;Zeng et al., 2023;Das et al., 2023;Liu et al., 2023),优异的性能和效率不断挑战这一方向。随后,第二类尝试充分利用Transformer。这类方法更加关注时间序列的内在处理,如平稳化(Liu et al., 2022b)、通道独立性和补丁(Nie et al., 2023),这些方法带来了持续改进的性能。此外,面对多变量之间独立性和相互作用的重要性日益增加,第三类彻底改造了Transformer的组件和架构。代表性研究(Zhang & Yan, 2023)明确地捕捉了通过改进的注意力机制和架构获得的跨时间和跨变量依赖关系。
与以往的研究不同,iTransformer没有修改现有的Transformer组件。相反,我们采用了基于逆向设计的组件,作为唯一一个基于我们最佳知识的设计类别。我们相信这种方法是经过广泛测试的,通过引入全面的实验,展示了iTransformer在时间序列预测中的优越性能。
3 iTransformer
在多变量时间序列预测中,给定历史观测值 X = { x 1 , … , x T } ∈ R T × N \mathbf{X} = \{\mathbf{x}_1, \ldots, \mathbf{x}_T\} \in \mathbb{R}^{T \times N} X={x1,…,xT}∈RT×N(有 T T T个时间步和 N N N个变量),我们预测未来的 S S S个时间步 Y = { x T + 1 , … , x T + S } ∈ R S × N \mathbf{Y} = \{\mathbf{x}_{T+1}, \ldots, \mathbf{x}_{T+S}\} \in \mathbb{R}^{S \times N} Y={xT+1,…,xT+S}∈RS×N。为了方便起见,我们将 X t , : \mathbf{X}_{t,:} Xt,:表示为时间步 t t t处同时记录的时间点,并将 X : , n \mathbf{X}_{:,n} X:,n表示为每个变量 n n n的整个时间序列。值得注意的是, X t , : \mathbf{X}_{t,:} Xt,:可能不包含本质上反映现实世界场景中相同事件的时间点,因为数据集中变量之间的系统性时间滞后。此外, X t , : \mathbf{X}_{t,:} Xt,:的元素在物理测量和统计分布中可以彼此不同,而变量 X : , n \mathbf{X}_{:,n} X:,n通常是共享的。
详细解释
符号定义
-
历史观测值 X \mathbf{X} X:
- 表示为 X = { x 1 , … , x T } ∈ R T × N \mathbf{X} = \{x_1, \ldots, x_T\} \in \mathbb{R}^{T \times N} X={x1,…,xT}∈RT×N,其中 T T T是时间步数, N N N是变量个数。也就是说,历史观测值矩阵包含了 T T T个时间步的观测数据,每个时间步有 N N N个变量。
-
未来时间步的预测值 Y \mathbf{Y} Y:
- 表示为 Y = { x T + 1 , … , x T + S } ∈ R S × N \mathbf{Y} = \{x_{T+1}, \ldots, x_{T+S}\} \in \mathbb{R}^{S \times N} Y={xT+1,…,xT+S}∈RS×N,其中 S S S是我们希望预测的未来时间步数。因此,预测值矩阵包含了 S S S个未来时间步的预测数据,每个时间步同样有 N N N个变量。
进一步的符号说明
-
时间步 t 处的观测值 X t \mathbf{X}_t Xt:
- 为了简化表示,我们用 X t \mathbf{X}_t Xt来表示时间步 t 处的观测数据。因此, X t \mathbf{X}_t Xt是一个向量,包含了时间步 t 处的 N N N个变量的观测值。
-
变量 n 的整条时间序列 X : , n \mathbf{X}_{:,n} X:,n:
- 用 X : , n \mathbf{X}_{:,n} X:,n来表示变量 n 的整个时间序列数据。即在所有时间步上,第 n 个变量的观测值。
注意事项
-
时间点对齐:
- 值得注意的是, X t \mathbf{X}_t Xt可能不包含反映真实世界场景中相同事件的时间点。这是因为数据集中变量之间的系统性时间滞后。
-
分布差异:
- X t \mathbf{X}_t Xt的元素在物理测量和统计分布中可以彼此不同。也就是说,不同时间步的观测值可能来源于不同的分布或有不同的测量尺度。
-
共享变量 X : , n \mathbf{X}_{:,n} X:,n:
- 变量 X : , n \mathbf{X}_{:,n} X:,n通常是共享的,这意味着变量 n 的时间序列数据在模型的不同部分中可以重复使用。
总结
通过这些符号和表示,我们可以系统地描述多变量时间序列预测问题。给定历史观测值 X \mathbf{X} X,我们希望构建一个模型来预测未来时间步的数值 Y \mathbf{Y} Y。在实际操作中,我们需要考虑时间点的对齐问题以及数据分布的差异,确保预测模型的准确性和可靠性。
3.1 结构概述
我们提出的 iTransformer 如图4所示,采用了Transformer(Vaswani et al., 2017)的仅编码器(encoder-only)架构,包括嵌入、投影和Transformer模块。
将整个系列嵌入为标记 大多数基于Transformer的预测器通常将同一时间的多个变量视为(时间)标记,并遵循生成式预测任务。然而,我们发现这种方法在数值模式上对学习注意力图的帮助较小,这一点得到了Patching(Dosovitskiy et al., 2021;Nie et al., 2023)应用增加的支持,这些应用扩展了各自的领域。同时,线性预测器的成功也挑战了采用重编码器-解码器Transformer生成标记的必要性。相反,我们提出的仅编码器iTransformer专注于表示学习和多变量序列的自适应相关。每个时间序列由潜在复杂过程驱动,首先被标记化以描述变量的属性,通过自注意力用于相互作用,并分别由前馈网络处理以进行系列表示。值得注意的是,生成预测序列的任务本质上交由线性层,这在之前的工作(Das et al., 2023)中被证明是有效的,我们将在下一节提供详细分析。
基于上述考虑,在iTransformer中,根据回溯系列 X : , n \mathbf{X}_{:,n} X:,n预测每个特定变量 Y ^ : , n \hat{\mathbf{Y}}_{:,n} Y^:,n的未来系列的过程简单地表示如下:
h
n
0
=
Embedding
(
X
:
,
n
)
,
h^0_n = \text{Embedding}(\mathbf{X}_{:,n}),
hn0=Embedding(X:,n),
H
l
+
1
=
TrmBlock
(
H
l
)
,
l
=
0
,
…
,
L
−
1
,
\mathbf{H}^{l+1} = \text{TrmBlock}(\mathbf{H}^l), \quad l = 0, \ldots, L-1,
Hl+1=TrmBlock(Hl),l=0,…,L−1,
Y
^
:
,
n
=
Projection
(
h
n
L
)
,
\hat{\mathbf{Y}}_{:,n} = \text{Projection}(h^L_n),
Y^:,n=Projection(hnL),
其中 H = { h 1 , … , h N } ∈ R N × D \mathbf{H} = \{h_1, \ldots, h_N\} \in \mathbb{R}^{N \times D} H={h1,…,hN}∈RN×D包含了 D D D维度的 N N N个嵌入标记,角标表示层的索引。嵌入: R T ↦ R D \mathbb{R}^T \mapsto \mathbb{R}^D RT↦RD和投影: R D ↦ R S \mathbb{R}^D \mapsto \mathbb{R}^S RD↦RS都由多层感知机(MLP)实现。获得的变量标记通过自注意力相互作用,并由每个TrmBlock中的共享前馈网络独立处理。具体而言,由于序列顺序信息已存储在神经元排列中,因此在传统Transformer中不再需要位置嵌入。
iTransformers架构本质上不对Transformer变体提出更多具体要求,除了注意力机制适用于多变量相关性。因此,一系列有效的注意力机制(Li et al., 2021;Wu et al., 2022;Dao et al., 2022)可以作为插件,在变量数量增大时减少复杂性。此外,由于具有输入的灵活性,标记数量可以从训练到推理过程中变化,模型允许在任意数量的变量上进行训练。命名为iTransformers的反向Transformer在第4.2节的实验中进行了广泛评估,并在时间序列预测中展示了优势。
3.2 反向Transformer组件
我们组织了由层归一化、前馈网络和自注意力模块组成的 L L L个块堆栈。但它们在反向维度上的职责进行了仔细的重新考虑。
层归一化 层归一化(Ba et al., 2016)最初是为了提高深度网络的收敛性和训练稳定性。在典型的基于Transformer的预测器中,该模块对同一时间戳的多变量表示进行归一化,逐渐融合变量之间的关系。一旦收集的时间点不代表同一事件,操作还会引入非因果或延迟过程之间的交互噪声。在我们的反向版本中,归一化应用于单个变量的序列表示,如公式2所示,这在研究和实践中被证明对处理非平稳问题有效(Kim et al., 2021;Liu et al., 2022b)。此外,由于所有序列作为(变量)标记归一化为高斯分布,不一致测量导致的差异可以减少。相比之下,在之前的架构中,不同时间步的标记将被归一化,导致时间序列过度平滑。
LayerNorm ( H ) = { h n − Mean ( h n ) Var ( h n ) ∣ n = 1 , … , N } \text{LayerNorm}(\mathbf{H}) = \left\{ \frac{h_n - \text{Mean}(h_n)}{\sqrt{\text{Var}(h_n)}} \Bigg| n = 1, \ldots, N \right\} LayerNorm(H)={Var(hn)hn−Mean(hn) n=1,…,N}
前馈网络 Transformer采用前馈网络(FFN)作为编码标记表示的基本构建块,并同样应用于每个标记。如前所述,在传统的Transformer中,形成标记的同一时间戳的多个变量可以定位不当且过于局部化,无法揭示足够的信息用于预测。在反向版本中,FFN被用在每个变量标记的序列表示上。通过通用逼近定理(Hornik, 1991),它们可以提取复杂的表示来描述时间序列。通过反向块的堆叠,它们致力于使用稠密的非线性连接编码观察到的时间序列并解码未来系列的表示,这在最近完全基于MLP的工作中有效(Tolstikhin et al., 2021;Das et al., 2023)。
更有趣的是,对独立时间序列的相同线性操作作为最近线性预测器(Zeng et al., 2023)和通道独立性(Nie et al., 2023)的结合,可以帮助我们理解系列表示。最近对线性预测器的重新审视(Li et al., 2023)强调MLP提取的时间特征应在不同的时间序列中共享。我们提出了一种合理的解释,认为MLP的神经元被教导描绘任何时间序列的固有属性,如幅度、周期性,甚至频谱(神经元作为滤波器),作为比应用于时间点的自注意力更有优势的预测表示。通过实验验证,我们验证了在第4.3节中将线性层的分工进行细分的好处,例如改进回溯系列和层次结构,以及在未见变量上的推广能力。
自注意力 虽然注意力机制通常用于促进以前预测器中的时间依赖建模,但反向模型将一个变量的整个系列视为独立过程。具体来说,综合提取每个时间序列的表示 H = { h 0 , … , h N } ∈ R N × D \mathbf{H} = \{h_0, \ldots, h_N\} \in \mathbb{R}^{N \times D} H={h0,…,hN}∈RN×D,自注意力模块采用线性投影来获得查询、键和值 Q , K , V ∈ R N × d k \mathbf{Q}, \mathbf{K}, \mathbf{V} \in \mathbb{R}^{N \times d_k} Q,K,V∈RN×dk,其中 d k d_k dk是投影维度。
以 q i , k j ∈ R d k q_i, k_j \in \mathbb{R}^{d_k} qi,kj∈Rdk作为一个(变量)标记的特定查询和键,我们注意到预Softmax分数的每个条目公式为:
A
i
,
j
=
(
Q
K
⊤
)
i
,
j
d
k
∝
q
i
⊤
k
j
A_{i,j} = \frac{(QK^\top)_{i,j}}{\sqrt{d_k}} \propto q_i^\top k_j
Ai,j=dk(QK⊤)i,j∝qi⊤kj
由于每个标记在其特征维度上之前已经归一化,这些条目可以揭示变量间的相关性,并且整个分数图
A
∈
R
N
×
N
\mathbf{A} \in \mathbb{R}^{N \times N}
A∈RN×N展示了成对变量标记之间的多变量相关性。因此,高度相关的变量将在下一次表示交互中被赋予更多权重,其值来自
V
\mathbf{V}
V。基于这种直觉,所提出的机制被认为在多变量系列预测中更自然和具有解释性。我们进一步在第4.3节和附录E.1中提供了分数图的可视化分析。
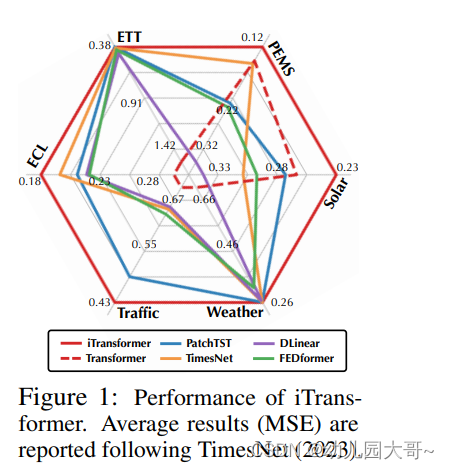
图1:iTransformer的性能。平均结果(MSE)按照TimesNet(2023)的标准报告。
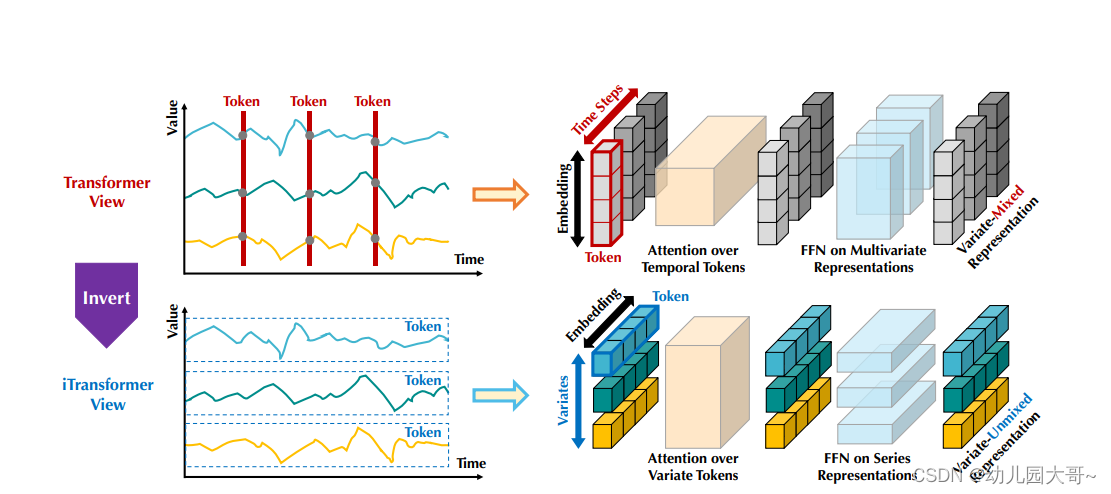
图2:对比传统的Transformer(顶部)和提出的iTransformer(底部)。Transformer嵌入了时间标记,该标记包含每个时间步的多变量表示。iTransformer则将每个序列独立地嵌入变量标记,从而注意力模块能够描述多变量相关性,并且前馈网络能够编码序列表示。
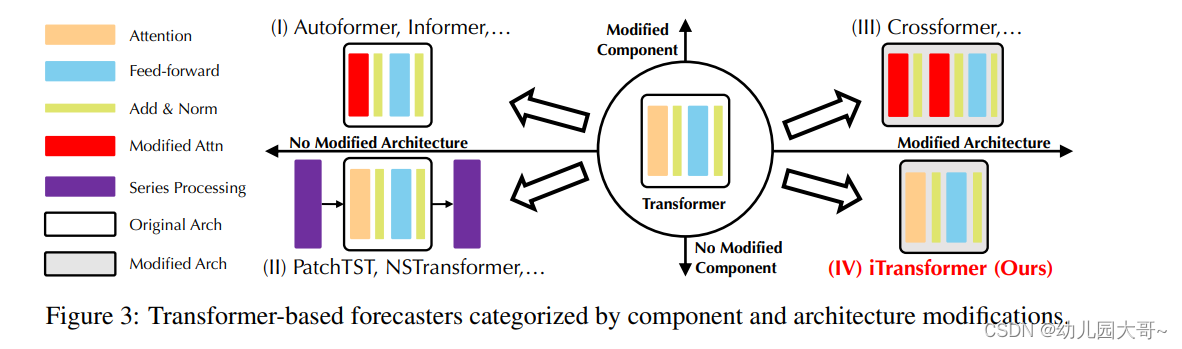
图3:基于Transformer的预测器按组件和架构修改分类。
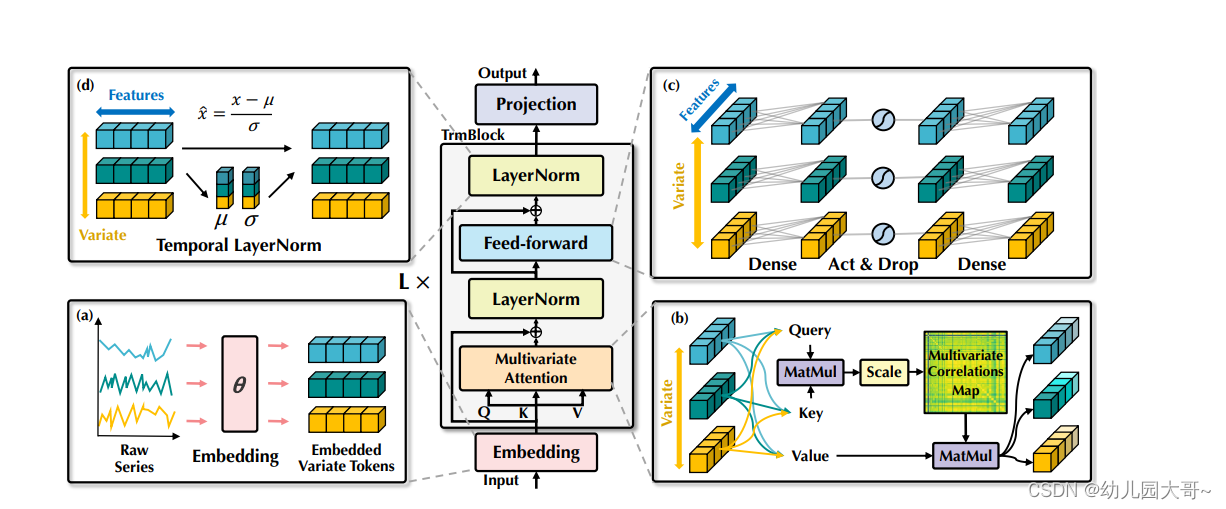
图4:iTransformer的总体结构,与Transformer的编码器共享相同的模块安排。
(a) 不同变量的原始序列独立嵌入为标记。
(b) 对嵌入的变量标记应用自注意力,增强解释性以揭示多变量相关性。
© 每个标记的序列表示通过共享的前馈网络提取。
(d) 采用层归一化以减少变量之间的差异。















 1661
1661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









