









最近想要实现点云可视化的目标检测,故开始考虑使用点云在ros的rviz中进行实验。
最后实验效果(本文实现点云,图像发布,后续笔记更新边界框等信息发布):
数据准备:
kitti数据集在ros中可视化一(显示(发布)点云、图像信息,学习笔记)_kitti数据集可视化_ng_T的博客-CSDN博客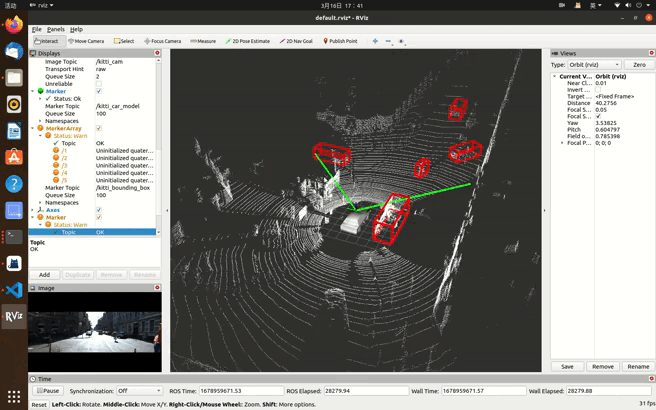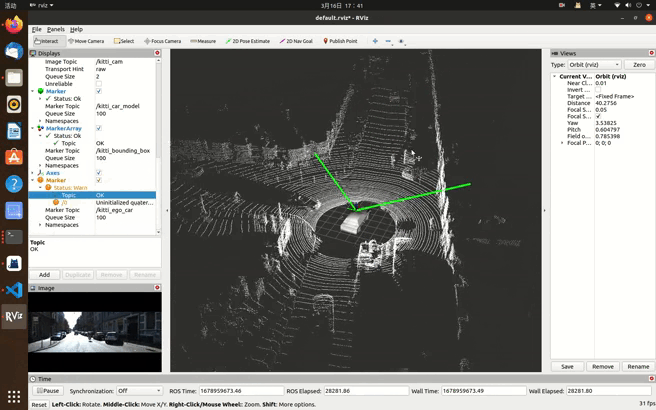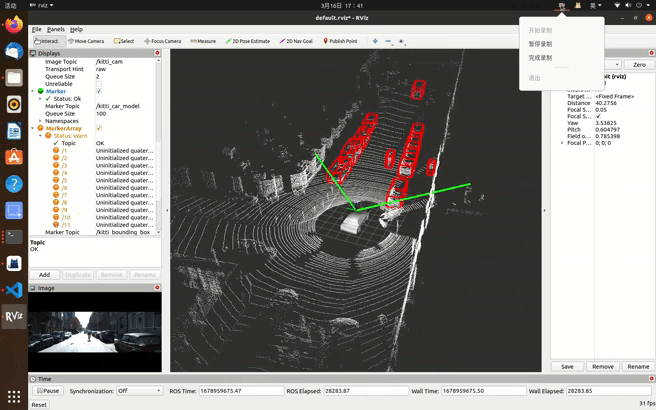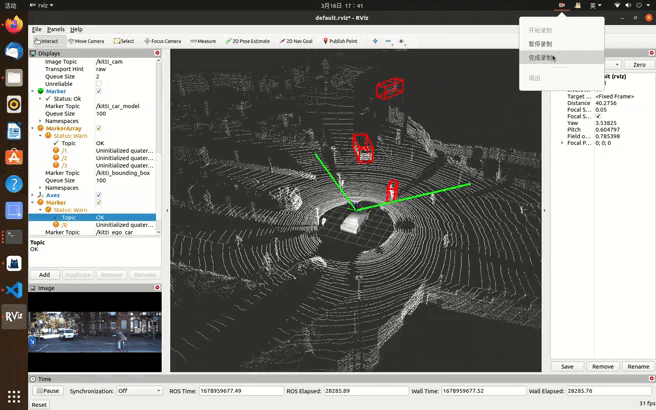
本机相关环境:ubutnu20.04 ros_neotic
准备小车模型:将解压后的car.dae存放在指定路径下
加载小车时注意rviz需要suorce一下(报错参考):rviz进行kitti数据集可视化时加载小车模型报错_ng_T的博客-CSDN博客
下载链接:下载地址
准备标注框相关信息可以参考:ROS1结合自动驾驶数据集Kitti开发教程(七)下载图像标注资料并读取显示 - 古月居
准备以下几个py文件:
input_ros_kitti.py文件为程序的人口创建发布话题(直接运行即可)等:
import rospy
from sensor_msgs.msg import Image,PointCloud2,Imu
from visualization_msgs.msg import Marker,MarkerArray
from cv_bridge import CvBridge
import numpy as np
import os
import cv2
from pub_publish import *
from read_data import *
# 保存解压后数据的地方
DATA_PATH='/home/t/t/Row_Data/2011_09_26/2011_09_26_drive_0005_sync/'
if __name__=='__main__':
rospy.init_node('kitti_node',anonymous=True)
cam_pub=rospy.Publisher('kitti_cam',Image,queue_size=10)
pcl_pub=rospy.Publisher('kitti_pcl',PointCloud2,queue_size=10)
ego_pub=rospy.Publisher('kitti_ego_car',Marker,queue_size=10)
model_pub=rospy.Publisher('kitti_car_model',Marker,queue_size=10)
imu_pub=rospy.Publisher('kitti_imu',Imu,queue_size=10)
bounding_box_pub=rospy.Publisher('kitti_bounding_box',MarkerArray,queue_size=10)
bridge=CvBridge()
rate=rospy.Rate(10)
frame=0
# 循环播放,通过frame控制帧数
while not rospy.is_shutdown():
img=cv2.imread(os.path.join(DATA_PATH,'image_02/data/%010d.png'%frame))
pcl=np.fromfile(os.path.join(DATA_PATH,'velodyne_points/data/%010d.bin'%frame),dtype=np.float32).reshape(-1,4)
# 获取标签信息
bounding_d = read_point_lable(frame)
# 发布图片信息
publish_camera(cam_pub,bridge,img)
# 发布点云话题
publish_pcl(pcl_pub,pcl)
# 发布车扫描角度的话题
publish_ego_car(ego_pub)
# 发布小车的模型
publish_car_model(model_pub)
# 发布imu话题
publish_imu(frame,imu_pub)
# 发布boundingbox的信息
publish_bounding_box(bounding_box_pub,bounding_d,frame)
rospy.loginfo('published')
rate.sleep()
frame+=1
frame%=154话题的具体实现代码pub_publish.py:
from std_msgs.msg import Header
import rospy
import sensor_msgs.point_cloud2 as pcl2
from geometry_msgs.msg import Point
from sensor_msgs.msg import Image,PointCloud2,Imu
from visualization_msgs.msg import Marker,MarkerArray
import tf_conversions
import numpy as np
import pandas as pd
import os
from boudingBOX import *
from kitti_util import *
FRAME_ID='map'
def publish_camera(cam_pub,bridge,image):
cam_pub.publish(bridge.cv2_to_imgmsg(image,'bgr8'))
def publish_pcl(pcl_pub,point_cloud):
header=Header()
header.stamp=rospy.Time.now()
header.frame_id=FRAME_ID
pcl_pub.publish(pcl2.create_cloud_xyz32(header,point_cloud[:,:3]))
def publish_ego_car(ego_car_pub):
marker=Marker()
marker.header.frame_id=FRAME_ID
marker.header.stamp=rospy.Time.now()
marker.id=0
marker.action=Marker.ADD
marker.lifetime=rospy.Duration()
marker.type=Marker.LINE_STRIP
marker.color.r=0.0
marker.color.g=1.0
marker.color.b=0.0
marker.color.a=1.0
marker.scale.x=0.2
marker.points=[]
marker.points.append(Point(10,10,0))
marker.points.append(Point(0,0,0))
marker.points.append(Point(10,-10,0))
ego_car_pub.publish(marker)
def publish_car_model(model_pub):
mesh_marker=Marker()
mesh_marker.header.frame_id=FRAME_ID
mesh_marker.header.stamp=rospy.Time.now()
mesh_marker.id=-1
mesh_marker.lifetime=rospy.Duration()
mesh_marker.type=Marker.MESH_RESOURCE
# mesh_marker.mesh_resource="package://kitti_tutorial/Audi R8/Models/Audi R8.dae"
mesh_marker.mesh_resource="package://kitti_tutorials/meshes/Car.dae"
mesh_marker.pose.position.x=0
mesh_marker.pose.position.y=0
mesh_marker.pose.position.z=-1.73
q = tf_conversions.transformations.quaternion_from_euler(0,0,np.pi/2)
mesh_marker.pose.orientation.x=q[0]
mesh_marker.pose.orientation.y=q[1]
mesh_marker.pose.orientation.z=q[2]
mesh_marker.pose.orientation.w=q[3]
mesh_marker.color.r=1.0
mesh_marker.color.g=1.0
mesh_marker.color.b=1.0
mesh_marker.color.a=1.0
mesh_marker.scale.x=0.9
mesh_marker.scale.y=0.9
mesh_marker.scale.z=0.9
model_pub.publish(mesh_marker)
# 给每一帧的数据集的每列加上列名
IMU_NAME = ["lat", "lon", "alt", "roll", "pitch", "yaw", "vn", "ve", "vf", "vl", "vu", "ax", "ay", "az", "af", "al", "au", "wx", "wy", "wz", "wf", "wl", "wu", "posacc", "velacc", "navstat", "numsats", "posmode", "velmode", "orimode"]
def publish_imu(num,imu_pub):
# 使用pandas数据处理模块载入txt文件
BASE_PATH = "/home/t/t/Row_Data/2011_09_26/2011_09_26_drive_0005_sync/"
imu_data = pd.read_csv(os.path.join(BASE_PATH, "oxts/data/%010d.txt"%num), header=None, sep=" ")
imu_data.columns = IMU_NAME
imu = Imu()
imu.header.frame_id = "map"
imu.header.stamp = rospy.Time.now()
# 从imu获取四元数
q = tf_conversions.transformations.quaternion_from_euler(float(imu_data.roll), float(imu_data.pitch), float(imu_data.yaw))
imu.orientation.x = q[0]
imu.orientation.y = q[1]
imu.orientation.z = q[2]
imu.orientation.w = q[3]
# 线速度
imu.linear_acceleration.x = imu_data.af
imu.linear_acceleration.y = imu_data.al
imu.linear_acceleration.z = imu_data.au
# 角速度
imu.angular_velocity.x = imu_data.wx
imu.angular_velocity.y = imu_data.wy
imu.angular_velocity.z = imu_data.wz
imu_pub.publish(imu)
def publish_bounding_box(bounding_box_pub,Bouding_Data,idx):
# 接受传递过来的标注信息
pred_boxes = np.array(Bouding_Data)
# 用于添加后续计算得到的box
boxes = []
for h,w,l,x,y,z,heading in pred_boxes:
corners_3d_cam2 = compute_3d_box_cam2(h,w,l,x,y,z,heading)
calib = Calibration("/home/t/t/Row_Data/2011_09_26/", from_video=True)
corners_3d_velo = calib.project_rect_to_velo(corners_3d_cam2.T).T
# 如何利用八个定点画图
# box = detector.get_3d_box((x,y,z),(l,w,h),heading)
# box=box.transpose(1,0).ravel()
box = corners_3d_velo.ravel()
boxes.append(box)
# 创建
marker_arry = MarkerArray()
for obid in range(len(boxes)):
ob = boxes[obid]
tid = 0
detect_points_set = []
for i in range(0, 8):
detect_points_set.append(Point(ob[i], ob[i+8], ob[i+16]))
marker = Marker()
marker.header.frame_id = 'map'
marker.header.stamp = rospy.Time.now()
marker.id = obid+1
marker.action = Marker.ADD
marker.type = Marker.LINE_LIST
marker.lifetime = rospy.Duration(0.1)
marker.color.r = 1
marker.color.g = 0
marker.color.b = 0
marker.color.a = 1
marker.scale.x = 0.2
marker.points = []
for line in lines:
marker.points.append(detect_points_set[line[0]])
marker.points.append(detect_points_set[line[1]])
marker_arry.markers.append(marker)
bounding_box_pub.publish(marker_arry)读取数据的代码read_data:
# 用于读取数据
import cv2
import numpy as np
# 加载点云数据
import os
import pandas as pd
BASE_PATH = "/home/t/t/Row_Data/2011_09_26/2011_09_26_drive_0005_sync/"
# 读取label
def read_point_lable(idx):
# 整个测试的数据集在同一个txt中
df = pd.read_csv(os.path.join(BASE_PATH, "label_02/0000.txt"), header=None, sep=" ")
res = df[df[0]==idx]
res = np.array(res)
res = res[res[:,2]!="DontCare"]
return res[:,10:17]画boundingbox需要用到的函数boudingBOX.py
import rospy
import time
import numpy as np
from geometry_msgs.msg import Point
from visualization_msgs.msg import Marker, MarkerArray
lines = [[0, 1], [1, 2], [2, 3], [3, 0], [4, 5], [5, 6],
[6, 7], [7, 4], [0, 4], [1, 5], [2, 6], [3, 7]]
def compute_3d_box_cam2(h, w, l, x, y, z, yaw):
# 计算旋转矩阵
R = np.array([[np.cos(yaw), 0, np.sin(yaw)], [0, 1, 0], [-np.sin(yaw), 0, np.cos(yaw)]])
# 8个顶点的xyz
x_corners = [l/2,l/2,-l/2,-l/2,l/2,l/2,-l/2,-l/2]
y_corners = [0,0,0,0,-h,-h,-h,-h]
z_corners = [w/2,-w/2,-w/2,w/2,w/2,-w/2,-w/2,w/2]
# 旋转矩阵点乘(3,8)顶点矩阵
corners_3d_cam2 = np.dot(R, np.vstack([x_corners,y_corners,z_corners]))
# 加上location中心点,得出8个顶点旋转后的坐标
corners_3d_cam2 += np.vstack([x,y,z])
return corners_3d_cam2kitti_util.py
""" Helper methods for loading and parsing KITTI data.
Author: Charles R. Qi
Date: September 2017
"""
from __future__ import print_function
import numpy as np
import cv2
import os
class Object3d(object):
''' 3d object label '''
def __init__(self, label_file_line):
data = label_file_line.split(' ')
data[1:] = [float(x) for x in data[1:]]
# extract label, truncation, occlusion
self.type = data[0] # 'Car', 'Pedestrian', ...
self.truncation = data[1] # truncated pixel ratio [0..1]
self.occlusion = int(data[2]) # 0=visible, 1=partly occluded, 2=fully occluded, 3=unknown
self.alpha = data[3] # object observation angle [-pi..pi]
# extract 2d bounding box in 0-based coordinates
self.xmin = data[4] # left
self.ymin = data[5] # top
self.xmax = data[6] # right
self.ymax = data[7] # bottom
self.box2d = np.array([self.xmin,self.ymin,self.xmax,self.ymax])
# extract 3d bounding box information
self.h = data[8] # box height
self.w = data[9] # box width
self.l = data[10] # box length (in meters)
self.t = (data[11],data[12],data[13]) # location (x,y,z) in camera coord.
self.ry = data[14] # yaw angle (around Y-axis in camera coordinates) [-pi..pi]
def print_object(self):
print('Type, truncation, occlusion, alpha: %s, %d, %d, %f' % \
(self.type, self.truncation, self.occlusion, self.alpha))
print('2d bbox (x0,y0,x1,y1): %f, %f, %f, %f' % \
(self.xmin, self.ymin, self.xmax, self.ymax))
print('3d bbox h,w,l: %f, %f, %f' % \
(self.h, self.w, self.l))
print('3d bbox location, ry: (%f, %f, %f), %f' % \
(self.t[0],self.t[1],self.t[2],self.ry))
class Calibration(object):
''' Calibration matrices and utils
3d XYZ in <label>.txt are in rect camera coord.
2d box xy are in image2 coord
Points in <lidar>.bin are in Velodyne coord.
y_image2 = P^2_rect * x_rect
y_image2 = P^2_rect * R0_rect * Tr_velo_to_cam * x_velo
x_ref = Tr_velo_to_cam * x_velo
x_rect = R0_rect * x_ref
P^2_rect = [f^2_u, 0, c^2_u, -f^2_u b^2_x;
0, f^2_v, c^2_v, -f^2_v b^2_y;
0, 0, 1, 0]
= K * [1|t]
image2 coord:
----> x-axis (u)
|
|
v y-axis (v)
velodyne coord:
front x, left y, up z
rect/ref camera coord:
right x, down y, front z
Ref (KITTI paper): http://www.cvlibs.net/publications/Geiger2013IJRR.pdf
TODO(rqi): do matrix multiplication only once for each projection.
'''
def __init__(self, calib_filepath, from_video=False):
if from_video:
calibs = self.read_calib_from_video(calib_filepath)
else:
calibs = self.read_calib_file(calib_filepath)
# Projection matrix from rect camera coord to image2 coord
self.P = calibs['P2']
self.P = np.reshape(self.P, [3,4])
# Rigid transform from Velodyne coord to reference camera coord
self.V2C = calibs['Tr_velo_to_cam']
self.V2C = np.reshape(self.V2C, [3,4])
self.C2V = inverse_rigid_trans(self.V2C)
# Rotation from reference camera coord to rect camera coord
self.R0 = calibs['R0_rect']
self.R0 = np.reshape(self.R0,[3,3])
# Camera intrinsics and extrinsics
self.c_u = self.P[0,2]
self.c_v = self.P[1,2]
self.f_u = self.P[0,0]
self.f_v = self.P[1,1]
self.b_x = self.P[0,3]/(-self.f_u) # relative
self.b_y = self.P[1,3]/(-self.f_v)
def read_calib_file(self, filepath):
''' Read in a calibration file and parse into a dictionary.
Ref: https://github.com/utiasSTARS/pykitti/blob/master/pykitti/utils.py
'''
data = {}
with open(filepath, 'r') as f:
for line in f.readlines():
line = line.rstrip()
if len(line)==0: continue
key, value = line.split(':', 1)
# The only non-float values in these files are dates, which
# we don't care about anyway
try:
data[key] = np.array([float(x) for x in value.split()])
except ValueError:
pass
return data
def read_calib_from_video(self, calib_root_dir):
''' Read calibration for camera 2 from video calib files.
there are calib_cam_to_cam and calib_velo_to_cam under the calib_root_dir
'''
data = {}
cam2cam = self.read_calib_file(os.path.join(calib_root_dir, 'calib_cam_to_cam.txt'))
velo2cam = self.read_calib_file(os.path.join(calib_root_dir, 'calib_velo_to_cam.txt'))
Tr_velo_to_cam = np.zeros((3,4))
Tr_velo_to_cam[0:3,0:3] = np.reshape(velo2cam['R'], [3,3])
Tr_velo_to_cam[:,3] = velo2cam['T']
data['Tr_velo_to_cam'] = np.reshape(Tr_velo_to_cam, [12])
data['R0_rect'] = cam2cam['R_rect_00']
data['P2'] = cam2cam['P_rect_02']
return data
def cart2hom(self, pts_3d):
''' Input: nx3 points in Cartesian
Oupput: nx4 points in Homogeneous by pending 1
'''
n = pts_3d.shape[0]
pts_3d_hom = np.hstack((pts_3d, np.ones((n,1))))
return pts_3d_hom
# ===========================
# ------- 3d to 3d ----------
# ===========================
def project_velo_to_ref(self, pts_3d_velo):
pts_3d_velo = self.cart2hom(pts_3d_velo) # nx4
return np.dot(pts_3d_velo, np.transpose(self.V2C))
def project_ref_to_velo(self, pts_3d_ref):
pts_3d_ref = self.cart2hom(pts_3d_ref) # nx4
return np.dot(pts_3d_ref, np.transpose(self.C2V))
def project_rect_to_ref(self, pts_3d_rect):
''' Input and Output are nx3 points '''
return np.transpose(np.dot(np.linalg.inv(self.R0), np.transpose(pts_3d_rect)))
def project_ref_to_rect(self, pts_3d_ref):
''' Input and Output are nx3 points '''
return np.transpose(np.dot(self.R0, np.transpose(pts_3d_ref)))
def project_rect_to_velo(self, pts_3d_rect):
''' Input: nx3 points in rect camera coord.
Output: nx3 points in velodyne coord.
'''
pts_3d_ref = self.project_rect_to_ref(pts_3d_rect)
return self.project_ref_to_velo(pts_3d_ref)
def project_velo_to_rect(self, pts_3d_velo):
pts_3d_ref = self.project_velo_to_ref(pts_3d_velo)
return self.project_ref_to_rect(pts_3d_ref)
# ===========================
# ------- 3d to 2d ----------
# ===========================
def project_rect_to_image(self, pts_3d_rect):
''' Input: nx3 points in rect camera coord.
Output: nx2 points in image2 coord.
'''
pts_3d_rect = self.cart2hom(pts_3d_rect)
pts_2d = np.dot(pts_3d_rect, np.transpose(self.P)) # nx3
pts_2d[:,0] /= pts_2d[:,2]
pts_2d[:,1] /= pts_2d[:,2]
return pts_2d[:,0:2]
def project_velo_to_image(self, pts_3d_velo):
''' Input: nx3 points in velodyne coord.
Output: nx2 points in image2 coord.
'''
pts_3d_rect = self.project_velo_to_rect(pts_3d_velo)
return self.project_rect_to_image(pts_3d_rect)
# ===========================
# ------- 2d to 3d ----------
# ===========================
def project_image_to_rect(self, uv_depth):
''' Input: nx3 first two channels are uv, 3rd channel
is depth in rect camera coord.
Output: nx3 points in rect camera coord.
'''
n = uv_depth.shape[0]
x = ((uv_depth[:,0]-self.c_u)*uv_depth[:,2])/self.f_u + self.b_x
y = ((uv_depth[:,1]-self.c_v)*uv_depth[:,2])/self.f_v + self.b_y
pts_3d_rect = np.zeros((n,3))
pts_3d_rect[:,0] = x
pts_3d_rect[:,1] = y
pts_3d_rect[:,2] = uv_depth[:,2]
return pts_3d_rect
def project_image_to_velo(self, uv_depth):
pts_3d_rect = self.project_image_to_rect(uv_depth)
return self.project_rect_to_velo(pts_3d_rect)
def rotx(t):
''' 3D Rotation about the x-axis. '''
c = np.cos(t)
s = np.sin(t)
return np.array([[1, 0, 0],
[0, c, -s],
[0, s, c]])
def roty(t):
''' Rotation about the y-axis. '''
c = np.cos(t)
s = np.sin(t)
return np.array([[c, 0, s],
[0, 1, 0],
[-s, 0, c]])
def rotz(t):
''' Rotation about the z-axis. '''
c = np.cos(t)
s = np.sin(t)
return np.array([[c, -s, 0],
[s, c, 0],
[0, 0, 1]])
def transform_from_rot_trans(R, t):
''' Transforation matrix from rotation matrix and translation vector. '''
R = R.reshape(3, 3)
t = t.reshape(3, 1)
return np.vstack((np.hstack([R, t]), [0, 0, 0, 1]))
def inverse_rigid_trans(Tr):
''' Inverse a rigid body transform matrix (3x4 as [R|t])
[R'|-R't; 0|1]
'''
inv_Tr = np.zeros_like(Tr) # 3x4
inv_Tr[0:3,0:3] = np.transpose(Tr[0:3,0:3])
inv_Tr[0:3,3] = np.dot(-np.transpose(Tr[0:3,0:3]), Tr[0:3,3])
return inv_Tr
def read_label(label_filename):
lines = [line.rstrip() for line in open(label_filename)]
objects = [Object3d(line) for line in lines]
return objects
def load_image(img_filename):
return cv2.imread(img_filename)
def load_velo_scan(velo_filename):
scan = np.fromfile(velo_filename, dtype=np.float32)
scan = scan.reshape((-1, 4))
return scan
def project_to_image(pts_3d, P):
''' Project 3d points to image plane.
Usage: pts_2d = projectToImage(pts_3d, P)
input: pts_3d: nx3 matrix
P: 3x4 projection matrix
output: pts_2d: nx2 matrix
P(3x4) dot pts_3d_extended(4xn) = projected_pts_2d(3xn)
=> normalize projected_pts_2d(2xn)
<=> pts_3d_extended(nx4) dot P'(4x3) = projected_pts_2d(nx3)
=> normalize projected_pts_2d(nx2)
'''
n = pts_3d.shape[0]
pts_3d_extend = np.hstack((pts_3d, np.ones((n,1))))
print(('pts_3d_extend shape: ', pts_3d_extend.shape))
pts_2d = np.dot(pts_3d_extend, np.transpose(P)) # nx3
pts_2d[:,0] /= pts_2d[:,2]
pts_2d[:,1] /= pts_2d[:,2]
return pts_2d[:,0:2]
def compute_box_3d(obj, P):
''' Takes an object and a projection matrix (P) and projects the 3d
bounding box into the image plane.
Returns:
corners_2d: (8,2) array in left image coord.
corners_3d: (8,3) array in in rect camera coord.
'''
# compute rotational matrix around yaw axis
R = roty(obj.ry)
# 3d bounding box dimensions
l = obj.l;
w = obj.w;
h = obj.h;
# 3d bounding box corners
x_corners = [l/2,l/2,-l/2,-l/2,l/2,l/2,-l/2,-l/2];
y_corners = [0,0,0,0,-h,-h,-h,-h];
z_corners = [w/2,-w/2,-w/2,w/2,w/2,-w/2,-w/2,w/2];
# rotate and translate 3d bounding box
corners_3d = np.dot(R, np.vstack([x_corners,y_corners,z_corners]))
#print corners_3d.shape
corners_3d[0,:] = corners_3d[0,:] + obj.t[0];
corners_3d[1,:] = corners_3d[1,:] + obj.t[1];
corners_3d[2,:] = corners_3d[2,:] + obj.t[2];
#print 'cornsers_3d: ', corners_3d
# only draw 3d bounding box for objs in front of the camera
if np.any(corners_3d[2,:]<0.1):
corners_2d = None
return corners_2d, np.transpose(corners_3d)
# project the 3d bounding box into the image plane
corners_2d = project_to_image(np.transpose(corners_3d), P);
#print 'corners_2d: ', corners_2d
return corners_2d, np.transpose(corners_3d)
def compute_orientation_3d(obj, P):
''' Takes an object and a projection matrix (P) and projects the 3d
object orientation vector into the image plane.
Returns:
orientation_2d: (2,2) array in left image coord.
orientation_3d: (2,3) array in in rect camera coord.
'''
# compute rotational matrix around yaw axis
R = roty(obj.ry)
# orientation in object coordinate system
orientation_3d = np.array([[0.0, obj.l],[0,0],[0,0]])
# rotate and translate in camera coordinate system, project in image
orientation_3d = np.dot(R, orientation_3d)
orientation_3d[0,:] = orientation_3d[0,:] + obj.t[0]
orientation_3d[1,:] = orientation_3d[1,:] + obj.t[1]
orientation_3d[2,:] = orientation_3d[2,:] + obj.t[2]
# vector behind image plane?
if np.any(orientation_3d[2,:]<0.1):
orientation_2d = None
return orientation_2d, np.transpose(orientation_3d)
# project orientation into the image plane
orientation_2d = project_to_image(np.transpose(orientation_3d), P);
return orientation_2d, np.transpose(orientation_3d)
def draw_projected_box3d(image, qs, color=(255,255,255), thickness=2):
''' Draw 3d bounding box in image
qs: (8,3) array of vertices for the 3d box in following order:
1 -------- 0
/| /|
2 -------- 3 .
| | | |
. 5 -------- 4
|/ |/
6 -------- 7
'''
qs = qs.astype(np.int32)
for k in range(0,4):
# Ref: http://docs.enthought.com/mayavi/mayavi/auto/mlab_helper_functions.html
i,j=k,(k+1)%4
# use LINE_AA for opencv3
cv2.line(image, (qs[i,0],qs[i,1]), (qs[j,0],qs[j,1]), color, thickness, cv2.CV_AA)
i,j=k+4,(k+1)%4 + 4
cv2.line(image, (qs[i,0],qs[i,1]), (qs[j,0],qs[j,1]), color, thickness, cv2.CV_AA)
i,j=k,k+4
cv2.line(image, (qs[i,0],qs[i,1]), (qs[j,0],qs[j,1]), color, thickness, cv2.CV_AA)
return image




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











