







参考B站教学视频: 深度学习网络缝合模块,模块缝模块
1. 准备主干网络论文和代码
举例:我找的论文是sparsercnn,一个可以用来做目标检测的CNN网络。
缝合位置
在模型文件中进行缝合。
在代码文件中,模型文件为detector.py,位置如下图所示。
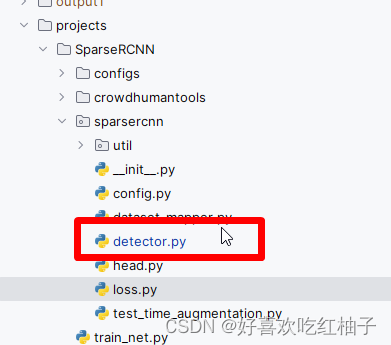
sparsercnn模型文件如下所示:
#
# Modified by Peize Sun, Rufeng Zhang
# Contact: {sunpeize, cxrfzhang}@foxmail.com
#
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
import logging
import math
from typing import List
import numpy as np
import torch
import torch.distributed as dist
import torch.nn.functional as F
from torch import nn
from detectron2.layers import ShapeSpec
from detectron2.modeling import META_ARCH_REGISTRY, build_backbone, detector_postprocess
from detectron2.modeling.roi_heads import build_roi_heads
from detectron2.structures import Boxes, ImageList, Instances
from detectron2.utils.logger import log_first_n
from fvcore.nn import giou_loss, smooth_l1_loss
from .loss import SetCriterion, HungarianMatcher
from .head import DynamicHead
from .util.box_ops import box_cxcywh_to_xyxy, box_xyxy_to_cxcywh
from .util.misc import (NestedTensor, nested_tensor_from_tensor_list,
accuracy, get_world_size, interpolate,
is_dist_avail_and_initialized)
__all__ = ["SparseRCNN"]
@META_ARCH_REGISTRY.register()
class SparseRCNN(nn.Module):
"""
Implement SparseRCNN
"""
def __init__(self, cfg):
super().__init__()
self.device = torch.device(cfg.MODEL.DEVICE)
self.in_features = cfg.MODEL.ROI_HEADS.IN_FEATURES
self.num_classes = cfg.MODEL.SparseRCNN.NUM_CLASSES
self.num_proposals = cfg.MODEL.SparseRCNN.NUM_PROPOSALS
self.hidden_dim = cfg.MODEL.SparseRCNN.HIDDEN_DIM
self.num_heads = cfg.MODEL.SparseRCNN.NUM_HEADS
# Build Backbone.
self.backbone = build_backbone(cfg)
self.size_divisibility = self.backbone.size_divisibility
# Build Proposals.
self.init_proposal_features = nn.Embedding(self.num_proposals, self.hidden_dim)
self.init_proposal_boxes = nn.Embedding(self.num_proposals, 4)
nn.init.constant_(self.init_proposal_boxes.weight[:, :2], 0.5)
nn.init.constant_(self.init_proposal_boxes.weight[:, 2:], 1.0)
# Build Dynamic Head.
self.head = DynamicHead(cfg=cfg, roi_input_shape=self.backbone.output_shape())
# Loss parameters: 损失函数的参数
class_weight = cfg.MODEL.SparseRCNN.CLASS_WEIGHT
giou_weight = cfg.MODEL.SparseRCNN.GIOU_WEIGHT
l1_weight = cfg.MODEL.SparseRCNN.L1_WEIGHT
no_object_weight = cfg.MODEL.SparseRCNN.NO_OBJECT_WEIGHT
self.deep_supervision = cfg.MODEL.SparseRCNN.DEEP_SUPERVISION
self.use_focal = cfg.MODEL.SparseRCNN.USE_FOCAL
# Build Criterion. 构建损失函数
matcher = HungarianMatcher(cfg=cfg,
cost_class=class_weight,
cost_bbox=l1_weight,
cost_giou=giou_weight,
use_focal=self.use_focal)
weight_dict = {"loss_ce": class_weight, "loss_bbox": l1_weight, "loss_giou": giou_weight}
if self.deep_supervision:
aux_weight_dict = {}
for i in range(self.num_heads - 1):
aux_weight_dict.update({k + f"_{i}": v for k, v in weight_dict.items()})
weight_dict.update(aux_weight_dict)
losses = ["labels", "boxes"]
self.criterion = SetCriterion(cfg=cfg,
num_classes=self.num_classes,
matcher=matcher,
weight_dict=weight_dict,
eos_coef=no_object_weight,
losses=losses,
use_focal=self.use_focal)
pixel_mean = torch.Tensor(cfg.MODEL.PIXEL_MEAN).to(self.device).view(3, 1, 1)
pixel_std = torch.Tensor(cfg.MODEL.PIXEL_STD).to(self.device).view(3, 1, 1)
self.normalizer = lambda x: (x - pixel_mean) / pixel_std
self.to(self.device)
def forward(self, batched_inputs, do_postprocess=True):
"""
Args:
batched_inputs: a list, batched outputs of :class:`DatasetMapper` .
Each item in the list contains the inputs for one image.
For now, each item in the list is a dict that contains:
* image: Tensor, image in (C, H, W) format.
* instances: Instances
Other information that's included in the original dicts, such as:
* "height", "width" (int): the output resolution of the model, used in inference.
See :meth:`postprocess` for details.
"""
images, images_whwh = self.preprocess_image(batched_inputs)
if isinstance(images, (list, torch.Tensor)):
images = nested_tensor_from_tensor_list(images)
# Feature Extraction.
src = self.backbone(images.tensor)
features = list()
for f in self.in_features:
feature = src[f]
features.append(feature)
# Prepare Proposals.
proposal_boxes = self.init_proposal_boxes.weight.clone()
proposal_boxes = box_cxcywh_to_xyxy(proposal_boxes)
proposal_boxes = proposal_boxes[None] * images_whwh[:, None, :]
# Prediction.
outputs_class, outputs_coord = self.head(features, proposal_boxes, self.init_proposal_features.weight)
output = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.training:
gt_instances = [x["instances"].to(self.device) for x in batched_inputs]
targets = self.prepare_targets(gt_instances)
if self.deep_supervision:
output['aux_outputs'] = [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
loss_dict = self.criterion(output, targets)
weight_dict = self.criterion.weight_dict
for k in loss_dict.keys():
if k in weight_dict:
loss_dict[k] *= weight_dict[k]
return loss_dict
else:
box_cls = output["pred_logits"]
box_pred = output["pred_boxes"]
results = self.inference(box_cls, box_pred, images.image_sizes)
if do_postprocess:
processed_results = []
for results_per_image, input_per_image, image_size in zip(results, batched_inputs, images.image_sizes):
height = input_per_image.get("height", image_size[0])
width = input_per_image.get("width", image_size[1])
r = detector_postprocess(results_per_image, height, width)
processed_results.append({"instances": r})
return processed_results
else:
return results
def prepare_targets(self, targets):
new_targets = []
for targets_per_image in targets:
target = {}
h, w = targets_per_image.image_size
image_size_xyxy = torch.as_tensor([w, h, w, h], dtype=torch.float, device=self.device)
gt_classes = targets_per_image.gt_classes
gt_boxes = targets_per_image.gt_boxes.tensor / image_size_xyxy
gt_boxes = box_xyxy_to_cxcywh(gt_boxes)
target["labels"] = gt_classes.to(self.device)
target["boxes"] = gt_boxes.to(self.device)
target["boxes_xyxy"] = targets_per_image.gt_boxes.tensor.to(self.device)
target["image_size_xyxy"] = image_size_xyxy.to(self.device)
image_size_xyxy_tgt = image_size_xyxy.unsqueeze(0).repeat(len(gt_boxes), 1)
target["image_size_xyxy_tgt"] = image_size_xyxy_tgt.to(self.device)
target["area"] = targets_per_image.gt_boxes.area().to(self.device)
new_targets.append(target)
return new_targets
def inference(self, box_cls, box_pred, image_sizes):
"""
Arguments:
box_cls (Tensor): tensor of shape (batch_size, num_proposals, K).
The tensor predicts the classification probability for each proposal.
box_pred (Tensor): tensors of shape (batch_size, num_proposals, 4).
The tensor predicts 4-vector (x,y,w,h) box
regression values for every proposal
image_sizes (List[torch.Size]): the input image sizes
Returns:
results (List[Instances]): a list of #images elements.
"""
assert len(box_cls) == len(image_sizes)
results = []
if self.use_focal:
scores = torch.sigmoid(box_cls)
labels = torch.arange(self.num_classes, device=self.device).\
unsqueeze(0).repeat(self.num_proposals, 1).flatten(0, 1)
for i, (scores_per_image, box_pred_per_image, image_size) in enumerate(zip(
scores, box_pred, image_sizes
)):
result = Instances(image_size)
scores_per_image, topk_indices = scores_per_image.flatten(0, 1).topk(self.num_proposals, sorted=False)
labels_per_image = labels[topk_indices]
box_pred_per_image = box_pred_per_image.view(-1, 1, 4).repeat(1, self.num_classes, 1).view(-1, 4)
box_pred_per_image = box_pred_per_image[topk_indices]
result.pred_boxes = Boxes(box_pred_per_image)
result.scores = scores_per_image
result.pred_classes = labels_per_image
results.append(result)
else:
# For each box we assign the best class or the second best if the best on is `no_object`.
scores, labels = F.softmax(box_cls, dim=-1)[:, :, :-1].max(-1)
for i, (scores_per_image, labels_per_image, box_pred_per_image, image_size) in enumerate(zip(
scores, labels, box_pred, image_sizes
)):
result = Instances(image_size)
result.pred_boxes = Boxes(box_pred_per_image)
result.scores = scores_per_image
result.pred_classes = labels_per_image
results.append(result)
return results
def preprocess_image(self, batched_inputs):
"""
Normalize, pad and batch the input images.
"""
images = [self.normalizer(x["image"].to(self.device)) for x in batched_inputs]
images = ImageList.from_tensors(images, self.size_divisibility)
images_whwh = list()
for bi in batched_inputs:
h, w = bi["image"].shape[-2:]
images_whwh.append(torch.tensor([w, h, w, h], dtype=torch.float32, device=self.device))
images_whwh = torch.stack(images_whwh)
return images, images_whwh
2. 找要缝合的模块
使用SEAttention模块进行缝合,模块代码如下所示:
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SEAttention(nn.Module):
def __init__(self,channel=512,reduction=16):
super().__init__()
self.ave_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel,channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction,channel, bias=False),
nn.Sigmoid()
)
def init_weights(self):
for m in self.modules():
if isinstance(m,nn.Conv2d):
init.kaiming_normal_(m.weight,mode='fan_out')
if m.bias is not None:
init.constant_(m.bias,0)
elif isinstance(m,nn.BatchNorm2d):
init.constant_(m.weight,1)
init.constant_(m.weight, 0)
elif isinstance(m,nn.Linear):
init.normal_(m.weight,std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self,x):
b,c,_,_ = x.size()
y = self.ave_pool(x).view(b,c)
y = self.fc(y).view(b,c,1,1)
return x*y.expand_as(x)
# 测试
if __name__ == '__main__':
input = torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output = se(input)
print(output.shape)
测试输出:

在测试用例中,输入的通道数是512,所以se模块的通道数channel也需要是512才能成功运行,因此需要保证主干网络的输出通道数和模块的输入通道数相同。
3. 把模块文件复制进主干网络的模型文件中
复制的位置随意,可以复制到模型文件类的上面。
复制过模块文件后的sparsercnn模型文件如下所示:
#
# Modified by Peize Sun, Rufeng Zhang
# Contact: {sunpeize, cxrfzhang}@foxmail.com
#
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
import logging
import math
from typing import List
import numpy as np
import torch
import torch.distributed as dist
import torch.nn.functional as F
from torch import nn
from detectron2.layers import ShapeSpec
from detectron2.modeling import META_ARCH_REGISTRY, build_backbone, detector_postprocess
from detectron2.modeling.roi_heads import build_roi_heads
from detectron2.structures import Boxes, ImageList, Instances
from detectron2.utils.logger import log_first_n
from fvcore.nn import giou_loss, smooth_l1_loss
from .loss import SetCriterion, HungarianMatcher
from .head import DynamicHead
from .util.box_ops import box_cxcywh_to_xyxy, box_xyxy_to_cxcywh
from .util.misc import (NestedTensor, nested_tensor_from_tensor_list,
accuracy, get_world_size, interpolate,
is_dist_avail_and_initialized)
__all__ = ["SparseRCNN"]
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SEAttention(nn.Module):
def __init__(self,channel=512,reduction=16):
super().__init__()
self.ave_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel,channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction,channel, bias=False),
nn.Sigmoid()
)
def init_weights(self):
for m in self.modules():
if isinstance(m,nn.Conv2d):
init.kaiming_normal_(m.weight,mode='fan_out')
if m.bias is not None:
init.constant_(m.bias,0)
elif isinstance(m,nn.BatchNorm2d):
init.constant_(m.weight,1)
init.constant_(m.weight, 0)
elif isinstance(m,nn.Linear):
init.normal_(m.weight,std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self,x):
b,c,_,_ = x.size()
y = self.ave_pool(x).view(b,c)
y = self.fc(y).view(b,c,1,1)
return x*y.expand_as(x)
@META_ARCH_REGISTRY.register()
class SparseRCNN(nn.Module):
"""
Implement SparseRCNN
"""
def __init__(self, cfg):
super().__init__()
self.device = torch.device(cfg.MODEL.DEVICE)
self.in_features = cfg.MODEL.ROI_HEADS.IN_FEATURES
self.num_classes = cfg.MODEL.SparseRCNN.NUM_CLASSES
self.num_proposals = cfg.MODEL.SparseRCNN.NUM_PROPOSALS
self.hidden_dim = cfg.MODEL.SparseRCNN.HIDDEN_DIM
self.num_heads = cfg.MODEL.SparseRCNN.NUM_HEADS
# Build Backbone.
self.backbone = build_backbone(cfg)
self.size_divisibility = self.backbone.size_divisibility
# Build Proposals.
self.init_proposal_features = nn.Embedding(self.num_proposals, self.hidden_dim)
self.init_proposal_boxes = nn.Embedding(self.num_proposals, 4)
nn.init.constant_(self.init_proposal_boxes.weight[:, :2], 0.5)
nn.init.constant_(self.init_proposal_boxes.weight[:, 2:], 1.0)
# Build Dynamic Head.
self.head = DynamicHead(cfg=cfg, roi_input_shape=self.backbone.output_shape())
# Loss parameters: 损失函数的参数
class_weight = cfg.MODEL.SparseRCNN.CLASS_WEIGHT
giou_weight = cfg.MODEL.SparseRCNN.GIOU_WEIGHT
l1_weight = cfg.MODEL.SparseRCNN.L1_WEIGHT
no_object_weight = cfg.MODEL.SparseRCNN.NO_OBJECT_WEIGHT
self.deep_supervision = cfg.MODEL.SparseRCNN.DEEP_SUPERVISION
self.use_focal = cfg.MODEL.SparseRCNN.USE_FOCAL
# Build Criterion. 构建损失函数
matcher = HungarianMatcher(cfg=cfg,
cost_class=class_weight,
cost_bbox=l1_weight,
cost_giou=giou_weight,
use_focal=self.use_focal)
weight_dict = {"loss_ce": class_weight, "loss_bbox": l1_weight, "loss_giou": giou_weight}
if self.deep_supervision:
aux_weight_dict = {}
for i in range(self.num_heads - 1):
aux_weight_dict.update({k + f"_{i}": v for k, v in weight_dict.items()})
weight_dict.update(aux_weight_dict)
losses = ["labels", "boxes"]
self.criterion = SetCriterion(cfg=cfg,
num_classes=self.num_classes,
matcher=matcher,
weight_dict=weight_dict,
eos_coef=no_object_weight,
losses=losses,
use_focal=self.use_focal)
pixel_mean = torch.Tensor(cfg.MODEL.PIXEL_MEAN).to(self.device).view(3, 1, 1)
pixel_std = torch.Tensor(cfg.MODEL.PIXEL_STD).to(self.device).view(3, 1, 1)
self.normalizer = lambda x: (x - pixel_mean) / pixel_std
self.to(self.device)
def forward(self, batched_inputs, do_postprocess=True):
"""
Args:
batched_inputs: a list, batched outputs of :class:`DatasetMapper` .
Each item in the list contains the inputs for one image.
For now, each item in the list is a dict that contains:
* image: Tensor, image in (C, H, W) format.
* instances: Instances
Other information that's included in the original dicts, such as:
* "height", "width" (int): the output resolution of the model, used in inference.
See :meth:`postprocess` for details.
"""
images, images_whwh = self.preprocess_image(batched_inputs)
if isinstance(images, (list, torch.Tensor)):
images = nested_tensor_from_tensor_list(images)
# Feature Extraction.
src = self.backbone(images.tensor)
features = list()
for f in self.in_features:
feature = src[f]
features.append(feature)
# Prepare Proposals.
proposal_boxes = self.init_proposal_boxes.weight.clone()
proposal_boxes = box_cxcywh_to_xyxy(proposal_boxes)
proposal_boxes = proposal_boxes[None] * images_whwh[:, None, :]
# Prediction.
outputs_class, outputs_coord = self.head(features, proposal_boxes, self.init_proposal_features.weight)
output = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.training:
gt_instances = [x["instances"].to(self.device) for x in batched_inputs]
targets = self.prepare_targets(gt_instances)
if self.deep_supervision:
output['aux_outputs'] = [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
loss_dict = self.criterion(output, targets)
weight_dict = self.criterion.weight_dict
for k in loss_dict.keys():
if k in weight_dict:
loss_dict[k] *= weight_dict[k]
return loss_dict
else:
box_cls = output["pred_logits"]
box_pred = output["pred_boxes"]
results = self.inference(box_cls, box_pred, images.image_sizes)
if do_postprocess:
processed_results = []
for results_per_image, input_per_image, image_size in zip(results, batched_inputs, images.image_sizes):
height = input_per_image.get("height", image_size[0])
width = input_per_image.get("width", image_size[1])
r = detector_postprocess(results_per_image, height, width)
processed_results.append({"instances": r})
return processed_results
else:
return results
def prepare_targets(self, targets):
new_targets = []
for targets_per_image in targets:
target = {}
h, w = targets_per_image.image_size
image_size_xyxy = torch.as_tensor([w, h, w, h], dtype=torch.float, device=self.device)
gt_classes = targets_per_image.gt_classes
gt_boxes = targets_per_image.gt_boxes.tensor / image_size_xyxy
gt_boxes = box_xyxy_to_cxcywh(gt_boxes)
target["labels"] = gt_classes.to(self.device)
target["boxes"] = gt_boxes.to(self.device)
target["boxes_xyxy"] = targets_per_image.gt_boxes.tensor.to(self.device)
target["image_size_xyxy"] = image_size_xyxy.to(self.device)
image_size_xyxy_tgt = image_size_xyxy.unsqueeze(0).repeat(len(gt_boxes), 1)
target["image_size_xyxy_tgt"] = image_size_xyxy_tgt.to(self.device)
target["area"] = targets_per_image.gt_boxes.area().to(self.device)
new_targets.append(target)
return new_targets
def inference(self, box_cls, box_pred, image_sizes):
"""
Arguments:
box_cls (Tensor): tensor of shape (batch_size, num_proposals, K).
The tensor predicts the classification probability for each proposal.
box_pred (Tensor): tensors of shape (batch_size, num_proposals, 4).
The tensor predicts 4-vector (x,y,w,h) box
regression values for every proposal
image_sizes (List[torch.Size]): the input image sizes
Returns:
results (List[Instances]): a list of #images elements.
"""
assert len(box_cls) == len(image_sizes)
results = []
if self.use_focal:
scores = torch.sigmoid(box_cls)
labels = torch.arange(self.num_classes, device=self.device).\
unsqueeze(0).repeat(self.num_proposals, 1).flatten(0, 1)
for i, (scores_per_image, box_pred_per_image, image_size) in enumerate(zip(
scores, box_pred, image_sizes
)):
result = Instances(image_size)
scores_per_image, topk_indices = scores_per_image.flatten(0, 1).topk(self.num_proposals, sorted=False)
labels_per_image = labels[topk_indices]
box_pred_per_image = box_pred_per_image.view(-1, 1, 4).repeat(1, self.num_classes, 1).view(-1, 4)
box_pred_per_image = box_pred_per_image[topk_indices]
result.pred_boxes = Boxes(box_pred_per_image)
result.scores = scores_per_image
result.pred_classes = labels_per_image
results.append(result)
else:
# For each box we assign the best class or the second best if the best on is `no_object`.
scores, labels = F.softmax(box_cls, dim=-1)[:, :, :-1].max(-1)
for i, (scores_per_image, labels_per_image, box_pred_per_image, image_size) in enumerate(zip(
scores, labels, box_pred, image_sizes
)):
result = Instances(image_size)
result.pred_boxes = Boxes(box_pred_per_image)
result.scores = scores_per_image
result.pred_classes = labels_per_image
results.append(result)
return results
def preprocess_image(self, batched_inputs):
"""
Normalize, pad and batch the input images.
"""
images = [self.normalizer(x["image"].to(self.device)) for x in batched_inputs]
images = ImageList.from_tensors(images, self.size_divisibility)
images_whwh = list()
for bi in batched_inputs:
h, w = bi["image"].shape[-2:]
images_whwh.append(torch.tensor([w, h, w, h], dtype=torch.float32, device=self.device))
images_whwh = torch.stack(images_whwh)
return images, images_whwh
4. 开始缝合
4.1 查看主干网络的输出通道数
在模型的forward函数中,可以使用x.shape输出主干网络的输入特征。
例如我的代码中,我需要打印一下images.tensor的shape来查看一下他的通道数。
def forward(self, batched_inputs, do_postprocess=True):
images, images_whwh = self.preprocess_image(batched_inputs)
if isinstance(images, (list, torch.Tensor)):
images = nested_tensor_from_tensor_list(images)
print(images.tensor)
# Feature Extraction.
src = self.backbone(images.tensor)
4.1.1 执行训练命令查看
运行训练命令然后进行通道数的查看,print出来了shape后就可以停止训练了。
4.1.2 运行模型文件查看
在模型文件最后添加main方法来直接运行该文件输出通道数
if __name__ == '__main__':
sparsercnn = SparseRCNN()
print(sparsercnn)
我的代码运行出来的channel=3,因此后续就把SE模块的channel也改成3。
4.2 将模块添加进主干网络中
主干网络中需要添加的代码位置:
- init函数中
- forward函数中
4.2.1 init函数中
在初始化阶段定义一下se模块,可以加在所有的self.xxx的最后。
不要忘记把channel通道数改为3.
# 引入模块
self.SE = SEAttention(channel=3)

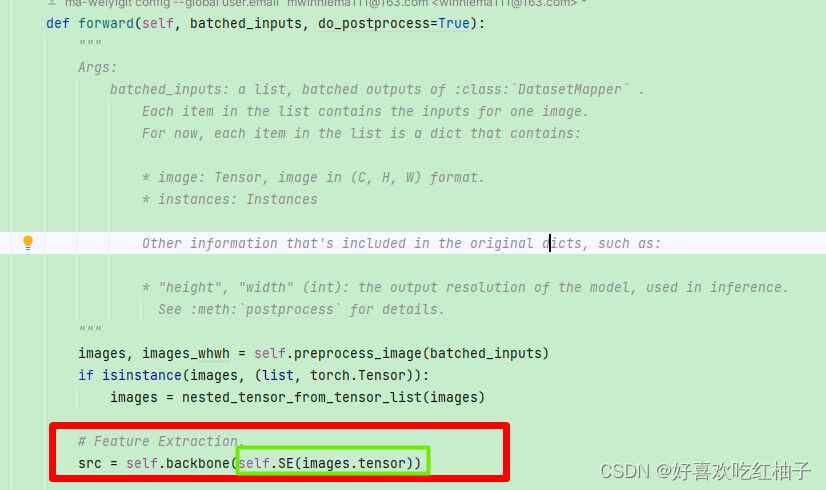
4.2.2 forward函数中
在forward函数中使用se模块。
5. 运行成果
执行训练命令即可,可以看一下准确率有没有提升,若提升则说明插入的模型有效果。

















 1551
1551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









