










在深度学习中,骨干网络(Backbone Network)是指模型的主干部分,负责从原始输入中提取特征。这些特征对于后续的任务(如分类、目标检测、语义分割等)至关重要。骨干网络通常是一个深层卷积神经网络(CNN)或其他类似架构的子网络。以下是关于深度学习骨干网络的一些详细介绍:
一、骨干网络的作用
骨干网络的主要作用是提取输入数据的特征。在图像识别、自然语言处理等任务中,骨干网络通过多层卷积、池化等操作,将输入数据(如图像、文本)转化为高维特征向量,为后续的任务模块提供有效的特征表示。
二、常见的骨干网络架构
2.1 LeNet:基础图像识别网络 (1998)
📃Paper : Gradient-Based Learning Applied to Document Recognition
💻Code: Deci-AI/super-gradients
提出背景:
LeNet由Yann LeCun等人在1998年提出,是深度学习领域早期的卷积神经网络(CNN)之一。在那个时代,深度学习还未引起广泛的关注,图像识别主要依赖于手工特征提取和传统的机器学习算法。然而,手工特征提取不仅耗时耗力,而且很难适应不同的图像变化。LeNet的出现,使得图像识别可以自动从原始像素中学习特征,大大提高了识别的准确性和效率。
主要贡献:
- LeNet是第一次将卷积神经网络应用于实际操作中,证明了CNN在图像识别任务中的有效性。
- LeNet奠定了卷积神经网络的基本结构,即卷积、非线性激活函数、池化、全连接。
网络结构:
LeNet模型包含了多个卷积层和池化层,以及最后的全连接层用于分类。其中,每个卷积层都包含了一个卷积操作和一个非线性激活函数(早期使用Sigmoid函数),用于提取输入图像的特征。池化层则用于缩小特征图的尺寸,减少模型参数和计算量。全连接层则将特征向量映射到类别概率上。
LeNet-5包含七层,不包括输入,每一层都包含可训练参数(权重),当时使用的输入数据是32*32像素的图像。下面逐层介绍LeNet-5的结构,并且,卷积层将用Cx表示,子采样层则被标记为Sx,完全连接层被标记为Fx,其中x是层索引。
LeNet-5结构:
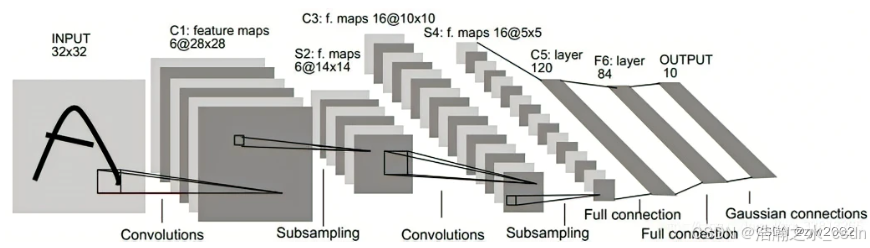
输入:32x32的灰度图像,也就是一个通道,那么一个图像就是一个2维的矩阵,没有RGB三个通道。
Layer1:6个大小为5x5的卷积核,步长为1。因此,到这里的输出变成了28x28x6。
Layer2:2x2大小的池化层,使用的是average pooling,步长为2。那么这一层的输出就是14x14x6。
Layer3:16个大小为5x5的卷积核,步长为1。但是,这一层16个卷积核中只有10个和前面的6层相连接。也就是说,这16个卷积核并不是扫描前一层所有的6个通道。如下图,0 1 2 3 4 5这 6个卷积核是扫描3个相邻,然后是6 7 8这3个卷积核是扫描4个相邻,9 10 11 12 13 14这6个是扫描4个非相邻,最后一个15扫描6个。实际上前面的6通道每个都只有10个卷积核扫描到。

这么做的原因是打破图像的对称性,并减少连接的数量。如果不这样做的话,每一个卷积核扫描一层之后是10x10,一个核大小是5x5,输入6个通道,输出16个,所以是10x10x5x5x6x16=240000个连接。但实际上只有156000连接。训练参数的数量从2400变成了1516个。
Layer4:和第二层一样,2x2大小的池化层,使用的是average pooling,步长为2。
Layer5:全连接卷积层,120个卷积核,大小为1x1。
第四层结束输出为16x5x5,相当于这里16x5x5展开为400个特征,然后使用120神经元去做全连接,如下图所示:
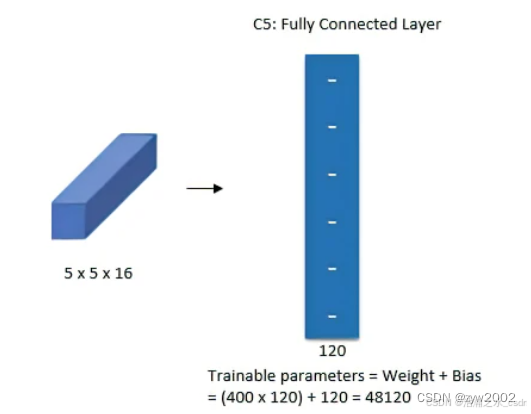
Layer6:全连接层,隐藏单元是84个。
Layer7:输出层,输出单元是10个,因为数字识别是0-9。
最终,LeNet-5的总结如下:
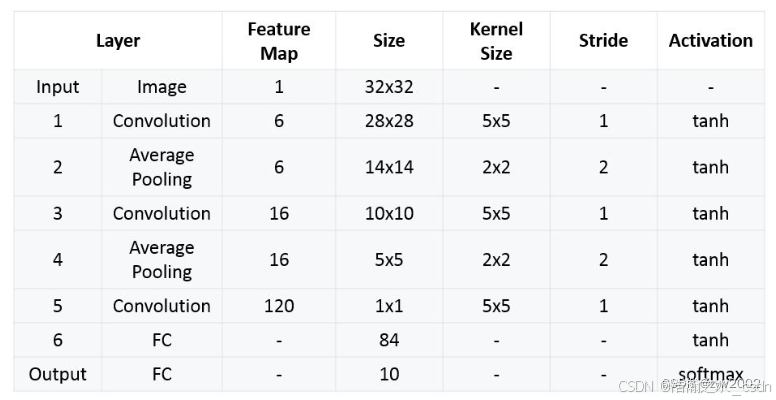
特点:
- 结构简单明了,易于理解和实现。
- 使用了局部感受野和权值共享技术,有效减少了模型的参数数量。
- 引入了池化层,提高了模型对图像变换的鲁棒性。
优缺点:
- 优点:计算量小,适合在硬件资源有限的情况下使用;网络结构清晰,易于理解和实现;在手写数字识别等简单任务上表现良好。
- 缺点:由于层数较少,特征表达能力有限,难以处理复杂的视觉任务;不适合大规模数据集;没有考虑到卷积核的重复利用,导致模型参数数量较多。
应用场景:
LeNet主要应用于手写数字识别任务,并在MNIST数据集上取得了很好的效果。此外,它也被广泛应用于教育和研究中作为入门示例。随着深度学习技术的发展,虽然LeNet在处理复杂任务上显得力不从心,但其设计理念和架构仍为后续许多CNN的发展提供了重要的启示。如今,在数字识别、图像分类等领域仍能看到LeNet的影子。
2.2 AlexNet:深度卷积网络 (2012)
📃Paper : 《ImageNet Classification with Deep Convolutional Neural Networks》
💻Code: alexnet-pytorch
提出背景
AlexNet的提出背景是深度学习在图像识别领域长期沉寂后的一次重大突破。尽管LeNet等早期卷积神经网络在图像分类中取得了一定成果,但由于计算资源的限制和模型设计的不足,深度学习并未引起广泛关注。直到2012年,AlexNet在ImageNet大赛上以远超第二名的成绩夺冠,才重新引起了人们对深度学习的兴趣。
主要贡献
- 首次在大型视觉数据集(如ImageNet)上取得显著成功,开创了现代深度学习的先河。
- 使用了ReLU激活函数,有效解决了Sigmoid在网络较深时的梯度弥散问题。
- 引入了Dropout技术来防止过拟合,提高了模型的泛化能力。
- 使用了多GPU加速训练,显著提高了模型的训练效率。
网络结构
AlexNet由输入层、5个卷积层、3个全连接层(包括输出层)组成。其中,前5层为卷积层,后3层为全连接层。网络分布在两块GPU上,部分层只跟同一个GPU中的上一层连接。每个卷积层后通常会跟一个ReLU激活函数和一个最大池化层。
AlexNet和LeNet的架构非常相似,如下图所示。左侧是LeNet, 右侧是AlexNet。

AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。 其次,AlexNet使用ReLU而不是sigmoid作为其激活函数。 下面,让我们深入研究AlexNet的细节。
- 模型设计
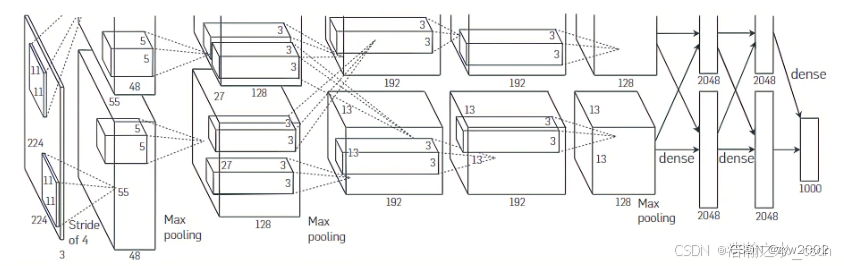
在AlexNet的第一层,卷积窗口的形状是11×11。 由于ImageNet中大多数图像的宽和高比MNIST图像的多10倍以上,因此,需要一个更大的卷积窗口来捕获目标。 第二层中的卷积窗口形状被缩减为5×5,然后是3×3。 此外,在第一层、第二层和第五层卷积层之后,加入窗口形状为3×3、步幅为2的最大汇聚层。 而且,AlexNet的卷积通道数目是LeNet的10倍。
在最后一个卷积层后有两个全连接层,分别有4096个输出。 这两个巨大的全连接层拥有将近1GB的模型参数。 由于早期GPU显存有限,原版的AlexNet采用了双数据流设计,使得每个GPU只负责存储和计算模型的一半参数。 幸运的是,现在GPU显存相对充裕,所以我们现在很少需要跨GPU分解模型(因此,我们的AlexNet模型在这方面与原始论文稍有不同)。
- 最大池化
在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避 免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间 会有重叠和覆盖,提升了特征的丰富性。
- 激活函数
此外,AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。 一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。 另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。 当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。 相反,ReLU激活函数在正区间的梯度总是1。 因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了
Sigmoid在网络较深时的梯度弥散问题,此外,加快了训练速度,因为训练网络使用梯度下降 法,非饱和的非线性函数训练速度快于饱和的非线性函数。虽然ReLU激活函数在很久之前就被 提出了,但是直到AlexNet的出现才将其发扬光大。
- Dropout
AlexNet通过暂退法(dropout)控制全连接层的模型复杂度,而LeNet只使用了权重衰减。
Dropout虽有单独的论文论述, 但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用 了Dropout。
- 数据增强
随机地从 256 × 256 256 \times 256256×256 的原始图像中截取 224 × 224 大小的区域(以及水平翻转的镜 像),相当于增加了 ( 256 × 224 ) 2 × 2 = 2048 倍的数据量。如果没有数据增强,仅靠原始的 数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能 力。进行预测时,则是取图片的四个角加中间共 5 个位置,并进行左右翻转,一共获得10张图 片,对他们进行预测并对10次结果求均值。
- 使用CUDA加速深度卷积网络的训练
利用GPU强大的并行计算能力,处理神经网络训练时大量 的矩阵运算。AlexNet使用了两块GTX580GPU进行训练,单个GTX580只有3GB显存,这限制了 可训练的网络的最大规模。因此作者将AlexNet分布在两个GPU上,在每个GPU的显存中储存一 半的神经元的参数。
特点
- 使用了ReLU激活函数,提高了模型的训练速度和非线性表达能力。
- 引入了Dropout技术,有效防止了过拟合。
- 使用了重叠池化(Overlapping Pooling),提高了特征的丰富性。
- 使用了局部响应归一化(LRN),虽然这一层在后续模型中逐渐被淘汰,但在当时有助于提高模型的泛化能力。
- 首次实现了多GPU加速训练,显著提高了模型的训练效率。
优缺点
- 优点:在大型视觉数据集上表现优异,引领了深度学习的发展潮流;使用了多种创新技术(如ReLU、Dropout、重叠池化等),提高了模型的性能和训练效率。
- 缺点:模型较大,训练和推理需要较强的计算资源;对输入图像的尺寸有限制;一些设计细节(如LRN层)在后续模型中已被淘汰。
应用场景
AlexNet主要被应用于图像分类任务,特别是在早期深度学习研究和发展中有重要作用。如今,它仍然可以用于较为简单的图像分类任务或作为学习深度学习的基础模型。此外,其设计思想和技术也被广泛应用于其他计算机视觉任务中。
2.3 ZFNet : 大型卷积网络 (2013)
📃Paper :《Visualizing and Understanding Convolutional Networks 》
💻Code: pytorch/captum
ZFNet提出背景与时间:
- 背景:ZFNet是在AlexNet之后提出的,旨在进一步优化卷积神经网络(CNN)的结构和性能。
- 时间:由Matthew D. Zeiler和Rob Fergus于2013年在论文《Visualizing and Understanding Convolutional Networks》中提出。
主要贡献:
- 通过可视化技术揭示了神经网络各层的功能和分类器的操作,为理解卷积神经网络提供了新视角。
- 在AlexNet基础上进行微调,通过减小第一层卷积核大小和步长,提高了模型性能。
- 提出了反池化(Unpooling)技术,使得最大池化操作近似可逆,有助于特征可视化。
网络结构:
- 类似于AlexNet,但进行了优化。例如,第一个卷积层的卷积核大小从11x11减小为7x7,步长从4减小为2。
- 后续卷积层、池化层和全连接层也根据需要进行了调整,以更好地捕捉图像特征。
ZFNet=( conv + relu + maxpooling )×2+( conv + relu )×3+fc×2+ softmax
ZFNet 仅仅是在 AlexNet 上做了一些调参:
改变了 AlexNet 的第一层,即将卷积核的尺寸大小 11x11 变成 7x7,并且将步长 4 变成了 2。
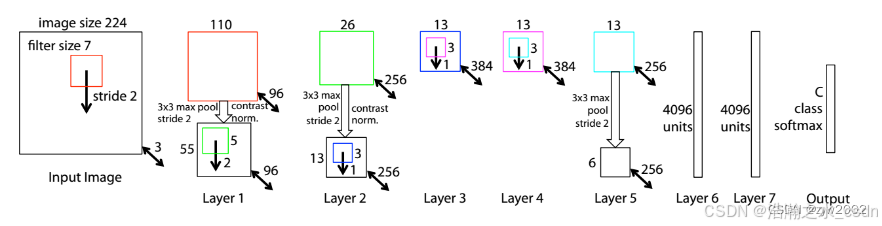
ZFNet实际上是微调(Fine-tuning)了AlexNet, 并通过反卷积(Deconvolution) 的方式可视化各层的输出特征图,进一步解释了卷积操作在大型网络中效果显著的原因。
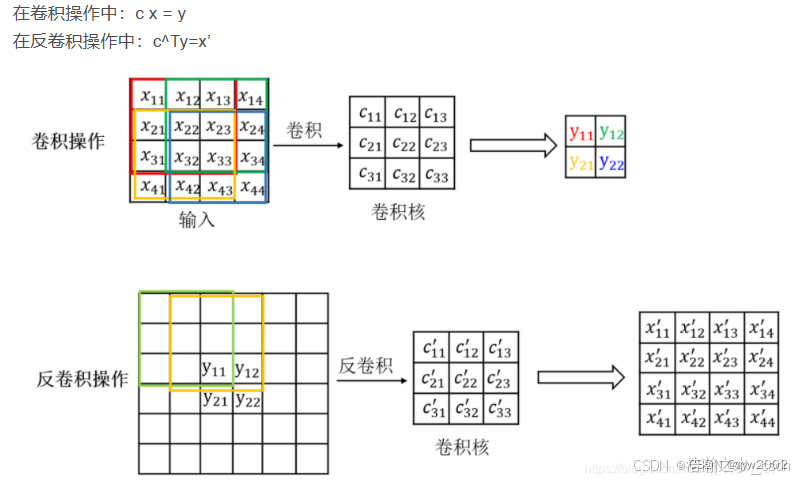
- 对卷积结果的可视化
作者将卷积核的计算结果(feature maps)映射回原始的像素空间(映射的方法为反卷积,反池化)并进行可视化。例如,下图Layer1区域最左上角的九宫格代表第一层卷积计算得到的前九张feature maps映射回原图像素空间后的可视化(称为f9)。第一层卷积使用96个卷积核,这意味着会得到96张feature maps,这里的前九张feature maps是指96个卷积核中值最大的9个卷积核对应生成的feature maps(这里称这9个卷积核为k9,即,第一层卷积最关注的前九种特征)。可以发现,这九种特征都是颜色和纹理特征,即蕴含语义信息少的结构性特征。
为了证明这个观点,作者又将数据集中的原始图像裁剪成小图,将所有的小图送进网络中,得到第一层卷积计算后的feature maps。统计能使k9中每个kernel输入计算结果最大的前9张输入小图,即9*9=81张,如下图红框中右下角所示。结果表明刚刚可视化的f9和这81张小图表征的特征是相似的,且一一对应的。由此证明卷积网络在第一层提取到的是一些颜色,纹理特征。

同理,观察Layer2和Layer3的可视化发现,第二次和第三次卷积提取到的特征蕴含的语义信息更丰富,不再是简单的颜色纹理信息,而是一些结构化的特征,例如蜂窝形状,圆形,矩形等等。那么网络的更深层呢?我们看下图:

在网络的深层,如第四层,第五层卷积提取到的是更高级的语义信息,如人脸特征,狗头特征,鸟腿鸟喙特征等等。
最后,越靠近输出端,能激活卷积核的输入图像相关性越少(尤其是空间相关性),例如Layer5中,最右上角的示例:feature map中表征的是一种绿色成片的特征,可是能激活这些特征的原图相关性却很低(原图是人,马,海边,公园等,语义上并不相干);其实这种绿色成片的特征是‘草地’,而这些语义不相干的图片里都有‘草地’。‘草地’是网络深层卷积核提取的是高级语义信息,不再是低级的像素信息,空间信息等等。
- 网络中对不同特征的学习速度
如下图所示,横轴表示训练轮数,纵轴表示不同层的feature maps映射回像素空间后的可视化结果:

由此可以看出,low-level的特征(颜色,纹理等)在网络训练的训练前期就可以学习到, 即更容易收敛;high-level的语义特征在网络训练的后期才会逐渐学到。 由此展示了不同特征的进化过程。这也是一个合理的过程,毕竟高级的语义特征,要在低级特征的基础上学习提取才能得到。
- 图像的平移、缩放、旋转对CNN的影响
下图是探究图片平移对卷积模型影响的实验,a1是五张不同的图片经过不同大小的左右平移后的结果。
a2是原始图片与经过平移后的图片分别送进卷积网络后,第一层卷积计算得到的feature maps之间的欧氏距离,可以看出当图片平移0个像素时(即图中横轴=0处),距离最小(等于0)。其他位置随着左右平移,得到的距离都会陡增或陡减。五条彩色曲线分别代表五张不同的原始图片。
a3是原始图片与经过平移后的图片分别送进卷积网络后,第七层卷积计算得到的feature maps之间的欧氏距离,可以看出趋势与a2类似;但是,增减的曲线变换更平缓,这一定程度上说明了网络的深层提取的是高级语义特征,而不是低级的颜色,纹理,空间特征。这种语义信息不会随着平移操作而轻易改变,例如狗的图片平移后还是狗。
这个性质叫做:卷积拥有良好的平移不变性。
最后,a4表示的是原始图片与经过平移后的图片分别送进卷积网络后,卷积网络最后的识别结果。可以看出识别准确率是相对平稳的,且在横轴x=0时,识别准确率较高(此时,图片不平移,识别物体基本在图片中心位置)。

下图探究图片缩放对卷积模型影响的实验,实验方法和表述与上面探讨平移时的设置类似。结果表明,网络的浅层相较于网络的深层对缩放操作更敏感;且最终的识别准确率较平稳。这个趋势跟探究平移操作对卷积模型影响的趋势类似,即:卷积操作也具有良好的缩放不变性。

下图是探究图片旋转对卷积模型影响的实验,可以看出旋转操作对卷积的影响正好与平移和缩放相反:卷积第一层对旋转的敏感程度较低,第七层对旋转的敏感程度高。这是因为颜色,纹理这些低级特征旋转前后还是相似的特征;但是目标级别的高级语义特征却不行,例如“特征9”旋转180°后变成了“特征6”. 看最终的识别准确率曲线也能发现旋转0°和350°时模型的识别准确率最高,因为此时旋转后模型最接近原始图片。对于某些存在对称性质的特征,例如原图中的电视,在旋转90°,180°,270°时都有不错的识别准确率。因此,卷积操作不具有良好的旋转不变性。

总结:
卷积的平移不变性是从滑动遍历这个操作带来的,不管一个特征出现在图中的什么位置,卷积核都可以通过滑动的方式,滑动到特征上面做识别。
卷积的缩放不变性则是从网络的层级结构中获得,不同层的卷积操作拥有不同尺寸的计算感受野 。至于旋转不变性缺失找不到对应的操作。
那么,为什么现在的一些成熟项目,例如人脸识别,图像分类等依然可以对旋转的图片做识别呢? 这是因为我们用大量的训练数据,旋转不变性可以从大量的训练数据中得到。其实,不仅是旋转不变性,卷积本身计算方法带来的平移不变性和缩放不变性也是脆弱的,大部分也是从数据集中学习到的。深度学习是一种基于数据驱动的算法。
- 改变卷积核的大小
ZFNet通过对AelxNet可视化发现,由于第一层的卷积核尺寸过大导致某些特征图失效(失效指的是一些值太大或太小的情况,容易引起网络的数值不稳定性,进而导致梯度消失或爆炸。图中的体现是(a)中的黑白像素块)。

此外,由于第一层的步长过大,导致第二层卷积结果出现棋盘状的伪影(例如(d)中第二小图和倒数第三小图)。因此ZFNet做了对应的改进。即将第一层 11X11步长为4的卷积操作变成 7X7步长为2的卷积。
- 遮挡对卷积模型的影响
ZFNet通过对原始图像进行矩形遮挡来探究其影响,如下图所示:
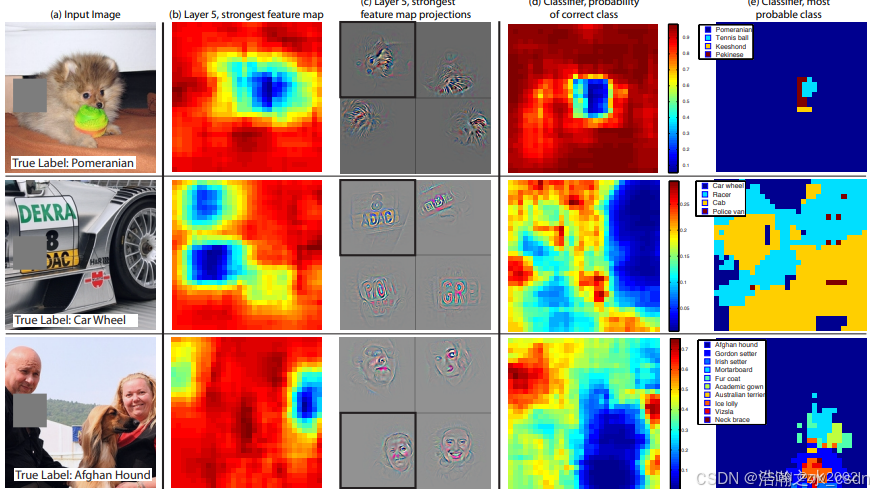
b表示计算遮挡后的图像经过第五个卷积层后得到的feature map 值的总和。红色代表更大的值。 由此可以看出来卷积计算后的特征图也是保留了原始数据中不同类别对象在图像中的空间信息。
c左上角的小图是经过第五个卷积后值最大的特征图的deconv可视化结果。由此实例2(可视化结果为英文字母或汉字,但原图的标签是“车轮”)可以看出卷积后值最大的特征图不一定是对分类最有作用的。c中的其他小图是统计数据集中其他图像可以使该卷积核输出最大特征图的deconv可视化结果。
d表示灰色滑块所遮挡的位置对图像正确分类的影响,红色代表分类成功的可能性大。例如博美犬的图像,当灰色滑块遮挡到博美犬的面部时,模型对博美犬的识别准确率大幅度下降。
e表示模型对遮挡后的图像的分类结果是什么。还拿博美犬的例子,灰色遮挡在图片中非狗脸的位置时,都不影响模型将其正确分类为博美犬(大部分都是蓝色标签,除了遮挡滑动到狗脸位置时)。
这个遮挡实验证明,深层的网络提取的是语义信息(例如狗的类属),而不是low-level的空间特征。因此对随机遮挡可以不敏感
特点:
- 结构简洁,易于理解和实现。
- 通过可视化技术,能够直观地展示网络各层的学习过程和特征提取效果。
- 使用了ReLU激活函数和交叉熵损失函数,提高了模型的训练效率和性能。
优缺点:
- 优点:性能较AlexNet有所提升,特征可视化技术有助于模型理解和调试。
- 缺点:相对于后续更复杂的网络结构,ZFNet的表达能力可能有限。
应用场景:
- 主要应用于图像分类任务,在ILSVRC-2013图像分类挑战中获得了冠军。
- 也可用于其他计算机视觉任务,如目标检测、图像分割等,但需要根据具体任务进行相应调整和优化。
2.4 VGGNet:使用块的网络 (2014)
📃Paper : 《Very Deep Convolutional Networks for Large-Scale Image Recognition》
💻Code: pytorch/vision
VGGNet全部使用3*3的卷积核和2*2的池化核,通过不断加深网络结构来提升性能。网络层数的增长并不会带来参数量上的爆炸,因为参数量主要集中在最后三个全连接层中。同时,两个3*3卷积层的串联相当于1个5*5的卷积层,3个3*3的卷积层串联相当于1个7*7的卷积层,即3个3*3卷积层的感受野大小相当于1个7*7的卷积层。但是3个3*3的卷积层参数量只有7*7的一半左右,同时前者可以有3个非线性操作,而后者只有1个非线性操作,这样使得前者对于特征的学习能力更强。
VGGNet作者总结出LRN层作用不大,越深的网络效果越好,1*1的卷积也是很有效的,但是没有3*3的卷积效果好,因为3*3的网络可以学习到更大的空间特征。
提出背景:
- VGGNet由牛津大学计算机视觉组(Visual Geometry Group)于2014年提出。
- 当时深度学习领域正在探索卷积神经网络的深度与其性能之间的关系。
主要贡献:
- 证明了使用3x3小卷积核增加网络深度可以有效提升模型性能。
- 在ILSVRC竞赛中取得了分类任务第二名和定位任务第一名的成绩。
- 提供了多种网络结构,如VGG-11、VGG-13、VGG-16和VGG-19等。
网络结构:
- 主要由卷积层和全连接层构成,深度可达16或19层。
- 卷积层使用3x3的卷积核,池化层使用2x2的最大池化。
- 全连接层包含几个较大的隐藏层,最后连接一个softmax输出层。
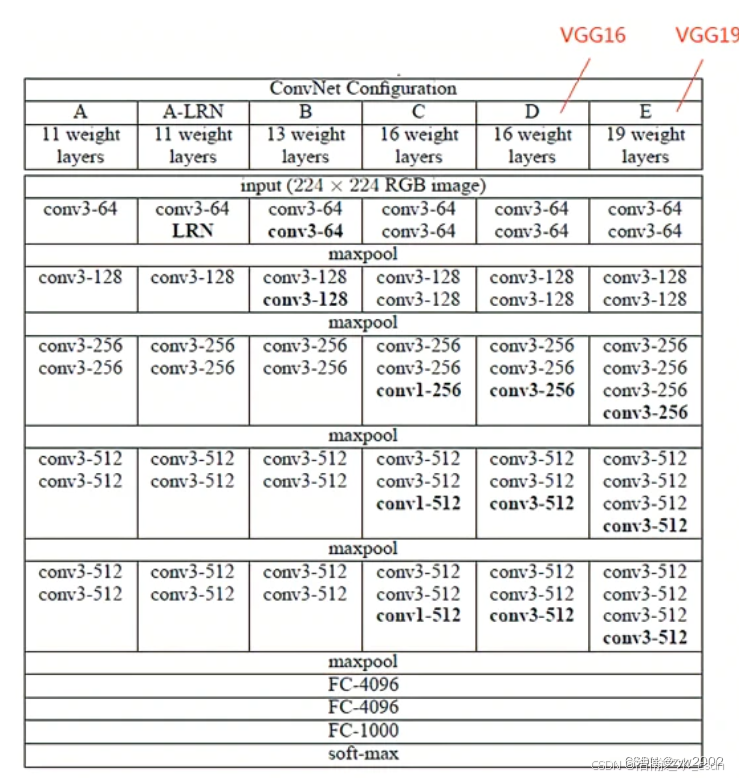
VGGNet一共有六种不同的网络结构A(VGG11)、A-LRN(VGG11-LRN)、B(VGG13)、C(VGG16-1)、D(VGG16-3)、E(VGG-19),这6种网络结构相似,都是由5层卷积层、3层全连接层组成,其中区别在于每个卷积层的子层数量不同,从A至E依次增加(子层数量从1到4),总的网络深度从11层到19层(添加的层以粗体显示)。
VGG11-LRN表示在第一层中采用了LRN的VGG-11;VGG16-1表示后三组卷积块中最后一层卷积采用卷积核尺寸为1x1, 相应的VGG16-3表示卷积核尺寸为3x3。
表格中的卷积层参数表示为“conv〈感受野大小〉-通道数〉”,例如con3-128,表示使用3x3的卷积核,通道数为128。为了简洁起见,在表格中不显示ReLU激活功能。
以VGG-16为例,架构图如下:
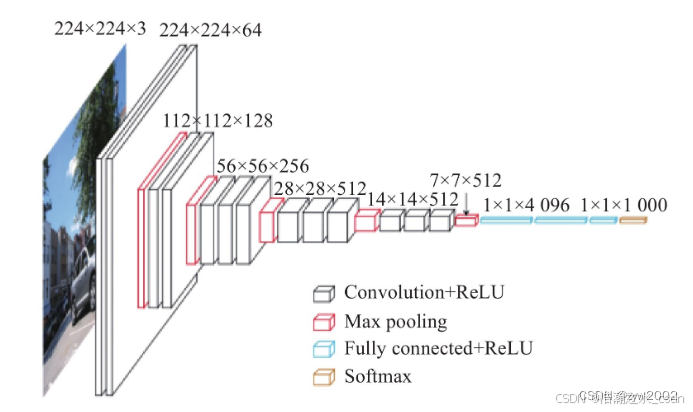
VGG-16架构:13个卷积层+3个全连接层,前5段卷积网络(标号1-5),最后一段全连接网络(标号6-8),网络总共参数数量大约138M左右。。
(1) 输入层(Input):图像大小为224×224×3
(2) 卷积层1+ReLU:conv3 - 64(卷积核的数量):kernel size:3 stride:1 pad:1
像素:(224-3+2×1)/1+1=224 输出为224×224×64 64个feature maps
参数: (3×3×3)×64+64=1792
(3) 卷积层2+ReLU:conv3 - 64:kernel size:3 stride:1 pad:1
像素: (224-3+1×2)/1+1=224 输出为224×224×64 64个feature maps
参数: (3×3×64×64)+64=36928
(4) 最大池化层: pool2: kernel size:2 stride:2 pad:0
像素: (224-2)/2 = 112 输出为112×112×64,64个feature maps
参数: 0
(5) 卷积层3+ReLU:.conv3-128:kernel size:3 stride:1 pad:1
像素: (112-3+2×1)/1+1 = 112 输出为112×112×128,128个feature maps
参数: (3×3×64×128)+128=73856
(6) 卷积层4+ReLU:conv3-128:kernel size:3 stride:1 pad:1
像素: (112-3+2×1)/1+1 = 112 输出为112×112×128,128个feature maps
参数: (3×3×128×128)+128=147584
(7) 最大池化层:pool2: kernel size:2 stride:2 pad:0
像素: (112-2)/2+1=56 输出为56×56×128,128个feature maps。
参数: 0
(8) 卷积层5+ReLU:conv3-256: kernel size:3 stride:1 pad:1
像素: (56-3+2×1)/1+1=56 输出为56×56×256,256个feature maps
参数: (3×3×128×256)+256=295168
(9) 卷积层6+ReLU:conv3-256: kernel size:3 stride:1 pad:1
像素: (56-3+2×1)/1+1=56 输出为56×56×256,256个feature maps,
参数: (3×3×256×256)+256=590080
(10) 卷积层7+ReLU:conv3-256: kernel size:3 stride:1 pad:1
像素: (56-3+2×1)/1+1=56 输出为56×56×256,256个feature maps
参数: (3×3×256×256)+256=590080
(11) 最大池化层:pool2: kernel size:2 stride:2 pad:0
像素:(56 - 2)/2+1=28 输出为28×28×256,256个feature maps
参数: 0
(12) 卷积层8+ReLU:conv3-512:kernel size:3 stride:1 pad:1
像素:(28-3+2×1)/1+1=28 输出为28×28×512,512个feature maps
参数: (3×3×256×512)+512=1180160
(13) 卷积层9+ReLU:conv3-512:kernel size:3 stride:1 pad:1
像素:(28-3+2×1)/1+1=28 输出为28×28×512,512个feature maps
参数: (3×3×512×512)+512=2359808
(14) 卷积层10+ReLU:conv3-512:kernel size:3 stride:1 pad:1
像素:(28-3+2×1)/1+1=28 输出为28×28×512,512个feature maps
参数: (3×3×512×512)+512=2359808
(15) 最大池化层:pool2: kernel size:2 stride:2 pad:0,输出为14×14×512,512个feature maps。
像素:(28-2)/2+1=14 输出为14×14×512
参数: 0
(16) 卷积层11+ReLU:conv3-512:kernel size:3 stride:1 pad:1
像素:(14-3+2×1)/1+1=14 输出为14×14×512,512个feature maps
参数: (3×3×512×512)+512=2359808
(17) 卷积层12+ReLU:conv3-512:kernel size:3 stride:1 pad:1
像素:(14-3+2×1)/1+1=14 输出为14×14×512,512个feature maps
参数: (3×3×512×512)+512=2359808
(18) 卷积层13+ReLU:conv3-512:kernel size:3 stride:1 pad:1
像素:(14-3+2×1)/1+1=14 输出为14×14×512,512个feature maps,
参数: (3×3×512×512)+512=2359808
(19) 最大池化层:pool2:kernel size:2 stride:2 pad:0
像素:(14-2)/2+1=7 输出为7×7×512,512个feature maps
参数: 0
(20) 全连接层1+ReLU+Dropout:有4096个神经元或4096个feature maps
像素:1×1×4096
参数:7×7×512×4096 = 102760448
(21) 全连接层2+ReLU+Dropout:有4096个神经元或4096个feature maps
像素:1×1×4096
参数:4096×4096 = 16777216
(22) 全连接层3:有1000个神经元或1000个feature maps
像素:1×1×1000
参数:4096×1000=4096000
(23) 输出层(Softmax):输出识别结果,看它究竟是1000个可能类别中的哪一个。
特点:
- 结构简洁直观,网络结构一致性高。
- 使用多个小尺寸卷积核代替大尺寸卷积核,减少参数量。
- 递增的通道数,有助于提取更加复杂的特征。
优缺点:
- 优点:结构简单,特征提取能力强,泛化性能好。
- 缺点:模型参数较多,计算资源消耗大,训练速度相对较慢。
应用场景:
- 广泛应用于图像分类任务。
- 也被用于人脸识别、目标检测等领域。
- 作为许多计算机视觉任务的backbone网络结构。
2.5 NiN: 网络中的网络 (2014)
NiN(Network in Network)是一种深度卷积神经网络架构,其提出背景、主要贡献、网络结构、特点、优缺点及应用场景可以详细阐述如下:
一、提出背景
NiN的提出主要基于对传统卷积神经网络(CNN)的改进需求。传统CNN在特征提取方面存在局限性,其假设潜在概念(latent concept)是线性的,但这在很多情况下并不成立。此外,全连接层作为CNN中的关键部分,存在参数过多、容易过拟合以及难以解释等问题。为了克服这些局限性,NiN被设计出来以提高模型的非线性能力和特征提取能力。
二、主要贡献
NiN的主要贡献包括以下几个方面:
- 引入MLPConv层:在卷积层中引入微型多层感知机(MLP)结构,通过MLP来增强卷积层的非线性能力,从而提取更复杂的特征。
- 使用1x1卷积:通过1x1卷积核来减少特征图的尺寸和通道数,从而减少计算量和参数数量。
- 全局平均池化层(GAP):用全局平均池化层代替传统的全连接层,减少参数数量,防止过拟合,并提高模型的泛化能力。
三、网络结构
NiN的网络结构主要包括以下几个部分:
- 输入层:接收输入图像,如224x224的RGB图像。
- 卷积层:包括多个MLPConv层和常规卷积层(如3x3卷积层)。MLPConv层使用多层感知机来代替传统的卷积核。
- 池化层:使用最大池化或全局平均池化来对特征图进行下采样。
- 随机失活层:用于防止过拟合。
- 全连接层:在某些NiN的实现中,可能会使用全连接层,但NiN的主要贡献之一是减少了全连接层的使用。
- 输出层:使用Softmax激活函数进行分类。
四、特点
NiN的特点主要包括:
- 高非线性能力:通过MLPConv层和1x1卷积核的引入,增强了模型的非线性能力,有助于提取更复杂的特征。
- 参数效率高:由于使用了1x1卷积和全局平均池化,NiN的参数数量和计算量相对较少。
- 泛化能力强:通过减少全连接层的使用和引入全局平均池化,NiN的泛化能力得到了提升。
- 易于解释:全局平均池化层的输出可以更容易地解释为分类映射,有助于理解模型的决策过程。
五、优缺点
优点:
- 提高了模型的非线性能力和特征提取能力。
- 减少了参数数量和计算量,降低了过拟合的风险。
- 提高了模型的泛化能力和解释性。
缺点:
- 全局平均池化层可能会丢失一些有用信息。
- 在某些复杂任务中,NiN的性能可能不如更复杂的网络结构。
六、应用场景
NiN主要应用于图像分类任务,如CIFAR-10、CIFAR-100、SVHN和MNIST等数据集上的分类任务。由于其具有较高的非线性能力和参数效率,NiN也适用于其他需要高效特征提取和分类的计算机视觉任务。此外,NiN的设计理念也影响了后续深度学习网络的发展,为更复杂的网络结构提供了有益的启示。
2.6 GoogLeNet : 含并行连接的网络 (2014)
📃Paper : 《Going Deeper with Convolutions》
💻Code:
pytorch/vision
GoogleNet 网络是14年由 Google 团队提出,斩获该年 ImageNet 竞赛中 Classification Task(分类任务)第一名。之所以名为“GoogLeNet”而非“GoogleNet”,文章说是为了向早期的LeNet致敬。
GoogLeNet吸收了NiN中串联网络的思想,并在此基础上做了改进。 这篇论文的一个重点是解决了什么样大小的卷积核最合适的问题。 毕竟,以前流行的网络使用小到1×1,大到11×11的卷积核。 本文的一个观点是,有时使用不同大小的卷积核组合是有利的。
大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,据此论文提出了名为Inception 的结构来实现此目的,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。
提出背景:
- GoogLeNet于2014年由Google团队提出,旨在解决深度学习中网络深度和宽度增加导致的参数过多、计算复杂度高及过拟合等问题。
主要贡献:
- 引入了Inception结构,通过并行使用不同尺度的卷积核和池化操作,有效减少了参数数量,提高了计算效率。
- 在网络顶部使用平均池化代替全连接层,进一步减少了参数数量,提高了模型性能。
网络结构:
- GoogLeNet采用模块化设计,包含多个Inception模块。
- 网络深度达到22层,通过堆叠Inception模块实现特征的深度提取。
Inception结构
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。
作者首先提出下图这样的基本结构:
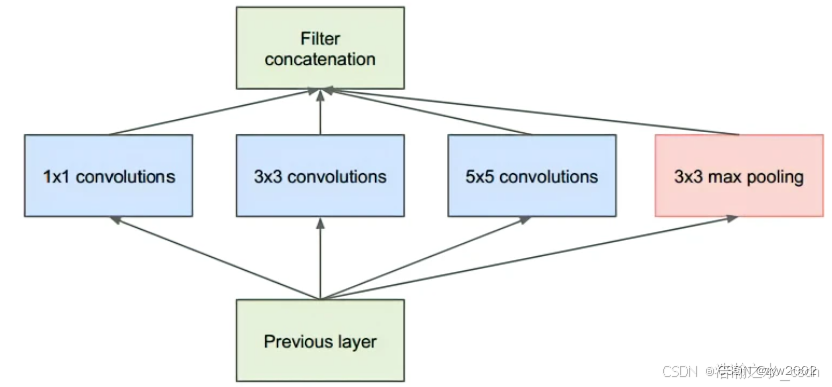
对上图做以下说明:
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
4 . 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
具体改进后的Inception Module如下图:

Inception块由四条并行路径组成。 前三条路径使用窗口大小为1×1、3×3和5×5的卷积层,从不同空间大小中提取信息。 中间的两条路径在输入上执行1×1卷积,以减少通道数,从而降低模型的复杂性。 第四条路径使用3×3最大汇聚层,然后使用1×1卷积层来改变通道数。 这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。

GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。 第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使用全连接层。

特点:
- 模块化设计,便于增添和修改网络结构。
- Inception结构能够捕捉不同尺度的特征信息,增强网络对尺度的适应性。
- 使用1x1卷积核进行降维,减少参数数量和计算量。
优缺点:
- 优点:参数少、计算效率高、特征提取能力强。
- 缺点:网络结构复杂,理解和实现难度较大。
应用场景:
- GoogLeNet广泛应用于图像分类、目标检测等计算机视觉任务。
- 在无人驾驶、医学影像分析、工业视觉检测等领域也有潜在的应用价值。
2.7 ResNet: 残差网络 (2015)
📃Paper : Deep Residual Learning for Image Recognition
💻Code: pytorch/vision/models/resnet.py
ResNet 网络是在 2015年 由微软实验室中的何凯明等几位大神提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得COCO数据集中目标检测第一名,图像分割第一名。
提出背景:
- ResNet(残差网络)由微软研究院的Kaiming He等人于2015年提出,旨在解决深度神经网络中梯度消失和退化问题。随着网络层数的增加,传统神经网络在训练时容易出现梯度消失,导致网络难以训练。
主要贡献:
- ResNet引入了残差连接(残差块),允许梯度直接穿过块,有效解决了深度神经网络的梯度消失问题。
- 通过学习输入与输出之间的残差,使得深层网络更容易优化和训练,从而能够构建更深层的网络结构,提升模型性能。
网络结构:
- ResNet由多个残差块组成,每个残差块包含卷积层、激活函数和残差连接。
- 输入数据通过卷积层处理后,与通过残差连接直接传递的输入相加,得到该残差块的输出。
- 通过堆叠多个残差块形成深层网络结构,并在最后通过全连接层输出分类结果。
Residual 的计算方式
residual结构使用了一种shortcut的连接方式,也可理解为捷径。让特征矩阵隔层相加,注意F(X)和X形状要相同,所谓相加是特征矩阵相同位置上的数字进行相加。

如上,左图是一个正常的块,右图是一个残差块。
让我们聚焦于神经网络局部:如图所示,假设我们的原始输入为x,而希望学出的理想映射为f(x)(作为上方激活函数的输入)。 左图虚线框中的部分需要直接拟合出该映射f(x),而右图虚线框中的部分则需要拟合出残差映射f(x)−x。 残差映射在现实中往往更容易优化。 以本节开头提到的恒等映射作为我们希望学出的理想映射f(x),我们只需将右图虚线框内上方的加权运算(如仿射)的权重和偏置参数设成0,那么f(x)即为恒等映射。 实际中,当理想映射f(x)极接近于恒等映射时,残差映射也易于捕捉恒等映射的细微波动。 右图是ResNet的基础架构–残差块(residual block)。 在残差块中,输入可通过跨层数据线路更快地向前传播。
残差块
ResNet沿用了VGG完整的3×3卷积层设计。 残差块里首先有2个有相同输出通道数的3×3卷积层。 每个卷积层后接一个批量规范化层和ReLU激活函数。 然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。 这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。 如果想改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后再做相加运算。

两种Residual
左侧残差结构称为 BasicBlock (上文刚介绍过),右侧残差结构称为 Bottleneck
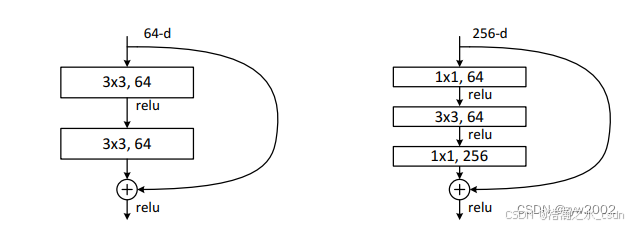
BottleNeck的结构:
(1)其中第一层的1× 1的卷积核的作用是对特征矩阵进行降维操作,将特征矩阵的深度由256降为64;
第三层的1× 1的卷积核是对特征矩阵进行升维操作,将特征矩阵的深度由64升成256。
降低特征矩阵的深度主要是为了减少参数的个数。
如果采用BasicBlock,参数的个数应该是:256×256×3×3×2=1179648
采用Bottleneck,参数的个数是:1×1×256×64+3×3×64×64+1×1×256×64=69632
(2)先降后升为了主分支上输出的特征矩阵和捷径分支上输出的特征矩阵形状相同,以便进行加法操作。
特点:
- 残差连接:允许梯度直接传递,解决梯度消失问题。
- 恒等映射:通过残差连接实现输入与输出的恒等映射,简化学习难度。
- 深度可拓展:可以构建非常深的网络结构,提高模型性能。
优缺点:
- 优点:
- 能够训练深层网络,避免梯度消失问题。
- 提高模型表达能力和性能。
- 使用残差连接保留原始特征,使网络学习更稳定。
缺点:
- 需要大量计算资源来训练和推理。
- 在某些情况下可能过拟合,需要通过正则化等方法处理。
应用场景:
- ResNet广泛应用于计算机视觉领域,如图像分类、目标检测、人脸识别等任务。
- 在自然语言处理领域也有应用,如文本分类、机器翻译等。
- 因其优异的性能,成为深度学习领域的基准模型之一。
2.8 Darknet-19 (2016)
📃Paper : 《YOLO9000: Better, Faster, Stronger》
💻Code: AlexeyAB/darknet
Darknet-19 是Joseph Redmon 于2016年提出的。
Darknet-19 是 YOLO v2 的 backbone。Darknet-19 总共有 19 层 conv 层, 5 个 maxpooling 层。Darknet-19 吸收了 VGG16, NIN 等网络的优点,网络结构小巧,但是性能强悍。
提出背景:
- Darknet19是YOLOv2目标检测算法中的骨干网络,由Joseph Redmon于2016年提出。它旨在通过紧凑的网络结构实现高效的目标检测性能。
主要贡献:
- Darknet19结合了VGG16和NIN的优点,设计了一个轻量级的卷积神经网络,用于目标检测任务。它在保持与ResNet相当分类精度的同时,提供了更快的计算速度。
网络结构:
- Darknet19包含19个卷积层,5个最大池化层,无全连接层,使用了Avgpool。卷积层主要使用3x3的卷积核,部分层使用1x1卷积核进行特征降维。
- 实际输入为416 ∗ 416 416*416416∗416
- 没有FC层,5次降采样(MaxPool),19个卷积层
- 使用Batch Normilazation来让训练更稳定,加速收敛,使model规范化。
- 使用Global Average Pooling

特点:
- 结构紧凑,参数少,计算效率高。
- 融合了多种网络结构的优点,如VGG的卷积核大小和NIN的1x1卷积核。
- 在计算速度和精度之间取得了良好的平衡。
优缺点:
- 优点:计算速度快,模型参数少,易于部署。
- 缺点:随着更复杂的网络结构出现,Darknet19的表达能力可能受限,特别是在处理更复杂场景或更高精度要求的任务时。
应用场景:
- Darknet19广泛应用于目标检测任务,特别是在实时性要求较高的场景,如自动驾驶、视频监控等领域。同时,它也可以用于图像分类等任务。
2.9 DenseNet: 稠密连接网络 (2017)
📃Paper : 《Densely Connected Convolutional Networks》
💻Code: densenet.py
提出背景:
DenseNet由何凯明等人于2016年提出,旨在解决深度神经网络训练过程中普遍存在的梯度消失和爆炸问题,以及过度参数化的问题。DenseNet通过密集连接机制,实现了特征的重用和梯度的有效传播。
主要贡献:
DenseNet的主要贡献在于其提出的密集连接(Dense Connectivity)机制,这一机制使得每一层都直接与其前所有层相连,从而形成一个密集的特征流,有效提高了信息在网络中的流动效率,并减少了参数数量。DenseNet在多个数据集上取得了优异的性能表现,成为深度学习领域的重要突破之一。
网络结构:
DenseNet的网络结构主要由DenseBlock和Transition层组成。DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。Transition层则用于连接两个相邻的DenseBlock,并通过池化操作降低特征图大小。DenseNet通过堆叠多个DenseBlock和Transition层来构建深层网络结构。

特点:
- 密集连接:每一层都与其之前的所有层密集连接,增强了各层的关联性。
- 特征重用:每一层都可以访问其之前所有层的特征图,从而更有效地利用特征信息。
- 梯度流动:密集连接增强了梯度的反向传播,有助于解决梯度消失问题。
- 参数效率:DenseNet的参数效率更高,因为它不需要像传统CNN那样学习冗余的特征图。
优缺点:
- 优点:更强的梯度流动、特征重用、参数效率高、网络易于训练。
- 缺点:计算量大、推理速度较慢、资源消耗较高、批量处理有限制。
应用场景:
DenseNet被广泛应用于智能安防、智能交通、智慧医疗等领域。在智能安防领域,DenseNet可以用于人脸识别、行为分析等;在智能交通领域,DenseNet可以用于车辆检测、交通拥堵预测等;在智慧医疗领域,DenseNet可以用于医学影像分析、疾病预测等。DenseNet在图像分类、目标检测、语义分割等任务中表现出卓越的性能和效率,为各个领域的智能化发展提供了强有力的支持。
2.10 ResNeXt (2017)
ResNeXt作为一种深度学习模型,其提出背景、时间与作者、主要贡献、网络结构、特点、优缺点及应用场景可以归纳如下:
1. 提出背景
ResNeXt的提出背景主要源于对深度神经网络(DNN)性能提升的持续追求。随着深度学习在计算机视觉等领域的广泛应用,研究者们发现,增加网络的深度和宽度是提升模型性能的有效手段。然而,这种简单的扩展方式往往伴随着计算复杂度的急剧增加和过拟合风险的上升。此外,传统网络结构在设计上往往缺乏灵活性,难以在保持模型复杂度的同时,实现性能的最大化。因此,ResNeXt网络被提出,旨在通过引入新的网络架构思想,以更加高效和灵活的方式提升模型的性能。
2. 提出时间与作者
ResNeXt由Facebook AI Research团队在2016年首次提出,并在2017年的CVPR会议上详细阐述。其核心论文为《Aggregated Residual Transformations for Deep Neural Networks》,由何凯明等人撰写。
3. 主要贡献
ResNeXt的主要贡献包括:
- 引入Cardinality维度:在ResNet的基础上,引入了Cardinality(基数)这一新的维度,通过增加分组卷积中的组数(即Cardinality),在保持参数量不变的情况下,提高了网络的准确性。
- 分组卷积的应用:采用分组卷积策略,将输入特征图分成多个组,并在每个组内进行独立的卷积操作,降低了计算量并增加了网络的非线性能力。
- 模块化设计:网络结构由多个相同的ResNeXt block堆叠而成,每个block内部采用了分组卷积和残差连接相结合的方式,使得网络更加灵活和易于扩展。
4. 网络结构
ResNeXt的网络结构可以看作是ResNet的升级版。它采用了与ResNet相似的残差连接机制,但在每个残差块内部,ResNeXt使用了分组卷积来替代传统的卷积操作。具体来说,ResNeXt block由以下几个部分组成:
- 分组卷积层:输入特征图首先被分成多个组,每个组内的特征图分别进行卷积操作。
- 1x1卷积层:在分组卷积之前和之后,通常会使用1x1的卷积层进行降维和升维操作,以进一步减少计算量和参数数量。
- 残差连接:在每个ResNeXt block中都引入了残差连接机制,以解决深层网络中的梯度消失问题。
5. 特点
ResNeXt的特点主要包括:
- 高效性:通过引入分组卷积和Cardinality维度,ResNeXt在保持模型性能的同时,降低了计算复杂度和参数数量,提高了模型的推断速度。
- 灵活性:模块化设计使得网络结构更加灵活和易于扩展,可以根据具体任务的需求调整网络的深度、宽度和Cardinality等参数。
- 泛化能力强:能够处理复杂问题并保持良好的性能表现。
6. 优缺点
优点:
- 高效性:计算效率高,适用于大规模数据集和实时应用。
- 灵活性:模块化设计使得网络易于扩展和调整。
- 泛化能力强:能够处理复杂问题并保持良好的性能表现。
缺点:
- 模型复杂度较高:虽然ResNeXt在保持性能的同时降低了计算复杂度,但其整体模型复杂度仍然较高,需要较大的计算资源来支持。
- 参数调优困难:由于引入了新的维度(Cardinality)和分组卷积策略,ResNeXt的参数调优相对复杂,需要更多的实验和调试工作。
7. 应用场景
ResNeXt网络由于其高效性和灵活性,在多个领域都有广泛的应用场景,包括但不限于:
- 图像分类:在ImageNet等大型图像分类数据集上取得了优异的性能表现。
- 目标检测:可以作为特征提取网络,用于目标检测任务中的特征提取和识别。
- 语义分割:在语义分割任务中,ResNeXt可以作为编码器部分,用于提取图像中的语义信息。
- 视频处理:由于其高效性,ResNeXt也可以应用于视频处理领域,如视频分类、视频摘要等任务。
2.11 MobileNetV1(2017)
MobileNetV1的提出背景
MobileNetV1是在深度学习,特别是卷积神经网络(CNN)在计算机视觉领域取得显著进展的背景下提出的。自2012年AlexNet开始,深度CNN的准确率不断提高,网络结构也日益复杂,参数量和计算量显著增加。然而,这种趋势使得网络难以在资源受限的移动设备和边缘设备上部署。因此,研究人员开始探索轻量化网络结构,以在保持较高准确率的同时,减少模型的参数量和计算量,从而能够在移动端和边缘设备上进行实时计算和推理。
时间与作者
MobileNetV1由谷歌(Google)的Andrew G. Howard等人在2017年提出,但实际上该概念在2016年已经初步形成,只是直到2017年才在arXiv上正式发表。
主要贡献
MobileNetV1的主要贡献在于提出了一种深度可分离卷积(Depthwise Separable Convolutions)架构,该架构通过将标准卷积分解为深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两步,显著减少了计算量和参数量。这种架构不仅保证了模型的轻量化,还保持了较高的准确率。
网络结构
MobileNetV1的网络结构主要由深度可分离卷积层组成,前面几层为标准卷积层,后面接多个深度可分离卷积层,最后通过全局平均池化层和全连接层输出分类结果。这种结构使得MobileNetV1在保持较高准确率的同时,具有较低的参数量和计算量。
特点
- 轻量化:通过深度可分离卷积架构显著减少模型的参数量和计算量,适合在移动端和边缘设备上部署。
- 高效性:在保证较高准确率的同时,实现了快速推理和计算。
- 灵活性:通过引入宽度乘数(Width Multiplier)和分辨率乘数(Resolution Multiplier)两个超参数,可以根据不同需求调整模型大小,以适应不同计算能力的设备。
优缺点
优点:
- 轻量化:适合在移动端和边缘设备上部署。
- 高效率:在保证准确率的同时,实现了快速推理和计算。
- 灵活性:通过调整超参数可以适应不同计算能力的设备。
缺点:
- 虽然准确率较高,但相对于一些更复杂的网络结构,其准确率可能略有下降。
- 在某些特定任务上,可能需要更多的优化和调整才能达到最佳效果。
应用场景
MobileNetV1由于其轻量化和高效性的特点,广泛应用于各种需要实时处理和计算的场景,如:
- 移动设备上的图像分类、目标检测等计算机视觉任务。
- 自动驾驶系统中的实时推理和决策。
- 边缘计算中的实时数据处理和分析。
总之,MobileNetV1作为一种轻量级的卷积神经网络结构,为深度学习在移动端和边缘设备上的应用提供了有力支持。
2.12 MobileNetV2(2018)
提出背景:
MobileNet系列网络是由谷歌公司提出的轻量级网络结构,旨在解决移动和嵌入式设备上计算资源受限的问题。随着移动设备的普及和深度学习应用的不断增加,如何在保持模型性能的同时减少计算量和参数量成为了一个重要的研究方向。MobileNetV1虽然通过深度可分离卷积有效降低了计算量,但在特征提取和模型表征能力上仍有提升空间。
时间与作者:
MobileNetV2由谷歌团队在2018年提出,其原始论文为《MobileNetV2: Inverted Residuals and Linear Bottlenecks》。
主要贡献
MobileNetV2的主要贡献在于引入了以下两个创新点:
-
倒残差结构(Inverted Residuals):与传统的残差块结构不同,MobileNetV2的倒残差结构首先通过1×1的卷积操作增加特征通道数(即“扩张”),然后再通过一个轻量级的深度卷积(Depthwise Convolution)进行特征提取,最后通过1×1的卷积操作减少特征通道数(即“压缩”)。这种设计可以在保持模型轻量级的同时,提高特征的表征能力。
-
线性瓶颈层(Linear Bottlenecks):在残差块的最后一个1×1卷积之后,为了避免ReLU激活函数对特征的破坏,MobileNetV2使用了线性激活函数。这样可以更好地保留特征的信息,有助于提高模型的性能。
网络结构
MobileNetV2的网络结构主要由多个倒残差块(Inverted Residual Blocks)堆叠而成。每个倒残差块由以下几个部分组成:
- 1×1卷积(升维):通过1×1卷积增加特征通道数。
- 3×3深度卷积(Depthwise Convolution):在升维后的特征图上应用3×3的深度卷积进行特征提取。
- 1×1卷积(降维):通过1×1卷积将特征通道数减少到与输入相同或指定的输出维度。
此外,MobileNetV2还使用了ReLU6作为激活函数,以在移动端设备低精度浮点数时也能有很好的数值分辨率。
特点
- 轻量级:通过深度可分离卷积和倒残差结构,MobileNetV2在保持较高准确率的同时,大大减少了模型参数量和计算量。
- 高效的特征提取:倒残差结构和深度卷积的结合使得MobileNetV2能够高效地提取图像特征。
- 快速推理:由于模型较小,MobileNetV2在移动设备上的推理速度较快,适合实时应用。
优缺点
优点:
- 模型小,计算量低,适合在移动和嵌入式设备上部署。
- 准确率较高,能够满足大多数应用场景的需求。
- 推理速度快,适合实时应用。
缺点:
- 在某些极端复杂或高精度的应用场景下,可能无法达到与大型网络相当的准确率。
- 需要针对特定任务进行调优和训练,以达到最佳性能。
应用场景
MobileNetV2由于其轻量级和高效的特性,被广泛应用于以下场景:
- 移动和嵌入式视觉应用:如手机摄像头的人脸识别、物体检测等。
- 实时目标检测:在视频监控、自动驾驶等领域中,MobileNetV2可以作为目标检测任务的主干网络。
- 图像分类:在移动端应用中,MobileNetV2可以用于图像分类任务,提高应用的智能化水平。
- 其他计算机视觉任务:如语义分割、姿态估计等,也可以结合MobileNetV2进行实现。
2.13 Darknet-53 (2018)
Darknet53是一种深度神经网络架构,由Joseph Redmon等人在2018年提出,并首次在论文《YOLOv3: An Incremental Improvement》中详细阐述。以下是对Darknet53的提出背景、主要贡献、网络结构、特点、优缺点及应用场景的综合介绍:
1. 提出背景
随着深度学习在计算机视觉领域的快速发展,目标检测和图像分类等任务对模型性能的要求日益提高。传统的卷积神经网络(CNN)虽然取得了一定的成果,但在处理复杂场景和大规模数据集时仍面临计算量大、参数多、训练时间长等问题。为了克服这些挑战,研究人员不断探索新的网络架构,Darknet53便是在这一背景下提出的。
2. 主要贡献
Darknet53的主要贡献在于其创新的设计理念和优异的性能表现。它作为YOLOv3的核心网络模型,通过堆叠多个卷积层和残差连接层,显著提高了特征提取的效果和检测精度。同时,Darknet53还具备轻量高效的特点,能够在保持高性能的同时减少计算资源的消耗,提高模型的推理速度。
3. 网络结构
Darknet53的网络结构主要由以下几个部分组成:
- 前段:主要由卷积层和max-pooling层组成,用于提取图像的初步特征,并逐步降低特征图的尺寸。
- 中段:主要由残差块(Residual Block)组成,通过残差连接加速收敛、减少梯度消失问题,并提高精度。每个残差块包含多个卷积层和批归一化层,以及LeakyReLU激活函数。
- 后段:主要由全局平均池化层和全连接层组成,用于对特征图进行进一步的处理和分类。
Darknet53总共包含53个卷积层(也有说法认为其包含52个卷积层和1个输出层,共53层),这也是其命名的由来。
4. 特点
- 轻量高效:相比其他深度神经网络框架,Darknet53的参数量和计算量都较小,能够在保证高性能的同时降低计算资源消耗。
- 多尺度特征融合:通过残差连接和跳跃连接机制,Darknet53能够捕捉不同尺度和层级的特征信息,提高模型的泛化能力。
- 易于扩展:使用残差结构可以轻松增加更多的卷积层来提高网络性能。
- 高效推理:采用低精度计算和并行计算技术,使得模型的推理速度很快,适用于实时应用场景。
5. 优缺点
优点:
- 高效性:训练速度快,推理速度快。
- 高性能:在多个数据集上表现出色,具有较高的分类和检测精度。
- 灵活性:网络结构易于调整和优化,适用于不同的应用场景。
缺点:
- 复杂度较高:虽然相比其他深度神经网络框架有所简化,但Darknet53的网络结构仍然较为复杂,需要一定的计算资源支持。
- 对硬件要求较高:为了充分发挥Darknet53的性能优势,通常需要高性能的GPU等硬件设备支持。
6. 应用场景
Darknet53已被广泛应用于计算机视觉领域的各种任务中,包括但不限于:
- 图像分类:在ImageNet等数据集上表现出色,适用于大规模图像分类任务。
- 目标检测:作为YOLOv3的核心网络模型,在目标检测任务中取得了优异的性能。
- 人脸识别:能够高效提取人脸特征并进行识别。
- 智能监控:在安防领域用于实时监控和异常检测。
综上所述,Darknet53以其优异的性能和高效性在计算机视觉领域具有广泛的应用前景。
2.14 MobileNetV3(2019)
提出背景:
MobileNetV3的提出背景主要聚焦于减少计算量和内存占用,同时保持高性能,以优化在资源受限环境下的计算机视觉任务,如图像分类、目标检测和语义分割等。随着移动设备和嵌入式系统的普及,对高效、轻量级网络的需求日益增加。MobileNetV3在继承MobileNet系列优势的基础上,进一步通过自动化搜索技术和精心设计的网络结构,实现了性能与效率的平衡。
时间与作者:
MobileNetV3是由谷歌(Google)在2019年3月21日提出的网络架构。具体的作者信息可能涉及多个研究人员,但谷歌作为该项目的推动者,负责了整体的设计和实现。
主要贡献
MobileNetV3的主要贡献包括:
- 互补搜索技术:结合Platform-Aware NAS(平台感知神经架构搜索)和NetAdapt算法,自动搜索并优化网络结构,以适应不同硬件平台的需求。
- 新的激活函数:引入了h-swish激活函数,作为swish激活函数的改进版,旨在提高计算效率和量化性能。
- 网络结构优化:重新设计了耗时层结构,如将平均池化层提前,减少了不必要的计算量;同时,引入了Squeeze-and-Excitation(SE)模块,增强了网络对特征通道的注意力机制。
- 轻量级深度可分离卷积:继续使用了MobileNetV1引入的深度可分离卷积,显著减少了计算量和参数数量。
网络结构
MobileNetV3的网络结构可以分为起始部分、中间部分和最后部分:
- 起始部分:包括一个3x3的卷积层,用于提取特征。
- 中间部分:由多个MobileBlock(包含1x1卷积、深度可分离卷积、SE模块等)组成,不同版本的MobileNetV3(Large和Small)在中间部分的层数和参数上有所不同。
- 最后部分:通过两个1x1的卷积层代替全连接层,输出类别预测。
特点
- 高效性:通过自动化搜索和精心设计的网络结构,MobileNetV3在保持高性能的同时,显著减少了计算量和内存占用。
- 适应性:针对不同的硬件平台和应用场景进行了优化,具有广泛的适用性。
- 集成性:集成了MobileNet系列和其他轻量级网络的优势,如深度可分离卷积、SE模块等。
优缺点
优点:
- 高性能:在多个基准测试上实现了较高的精度。
- 低延迟:通过减少计算量和优化网络结构,降低了推理时间。
- 易部署:适合部署在移动设备、IoT设备等资源有限的平台上。
缺点:
- 计算复杂度:虽然相较于其他网络有所降低,但在某些极端资源受限的环境下仍可能面临挑战。
- 训练难度:由于引入了新的激活函数和网络结构,可能需要更多的训练技巧和优化策略。
应用场景
MobileNetV3因其高效、轻量级的特性,广泛应用于以下场景:
- 实时图像识别:如人脸识别、车辆识别等。
- 视频分析:如监控视频中的异常检测、行为识别等。
- 增强现实(AR):在移动设备上实现高效的AR效果。
- 移动应用中的图像处理:如照片编辑、滤镜效果等。
总之,MobileNetV3作为轻量化神经网络设计的一个重要里程碑,不仅推动了计算机视觉领域在移动设备上的应用,也为后续的轻量级模型设计提供了宝贵的经验和技术基础。
2.15 EfficientNet V1 (2019)
EfficientNetV1的提出背景、主要贡献、网络结构、特点、优缺点及应用场景可以详细阐述如下:
1. 提出背景
EfficientNetV1是由Google团队在2019年提出的一种高效的神经网络架构。在深度学习领域,之前的研究多集中在单一维度上对网络结构进行扩展,如增加网络深度(ResNet系列)、增加网络宽度或提高输入图像的分辨率。然而,这些单一维度的扩展方法往往无法同时达到最佳的性能和资源利用效率。因此,EfficientNetV1提出了一种新的模型缩放方法,旨在通过同时调整网络的深度、宽度和分辨率,实现更高效的网络扩展。
2. 主要贡献
- 复合缩放方法:EfficientNetV1引入了复合缩放方法(Compound Scaling Method),通过同时调整网络的深度、宽度和分辨率,以平衡计算资源和准确性。这种方法使用一个复合系数来统一地缩放所有维度,实现了更均衡的网络扩展。
- 高效的网络架构:通过Neural Architecture Search(NAS)技术,EfficientNetV1找到了一种高效的网络架构,能够在保持较小模型大小和较快推理速度的同时,实现较高的准确率。
- 多版本模型:EfficientNetV1提供了多个版本的模型,从EfficientNet-B0到EfficientNet-B7,这些模型在输入分辨率、网络深度和网络宽度上进行了不同程度的调整,以满足不同的应用需求。
3. 网络结构
EfficientNetV1的网络结构基于深度卷积神经网络(CNN),并采用了类似于MobileNetV2的倒置残差块(Inverted Residual Block)作为基本构建模块。该模块包含了分组卷积和线性瓶颈结构,以及Squeeze-and-Excitation(SE)注意力机制。通过复合缩放方法,EfficientNetV1能够动态地调整这些模块的宽度、深度和分辨率,以优化模型性能。
4. 特点
- 均衡扩展:通过同时调整网络的深度、宽度和分辨率,实现了更均衡的网络扩展,提高了模型的性能和资源利用效率。
- 高效性:EfficientNetV1在保持较小模型大小和较快推理速度的同时,实现了较高的准确率,特别适用于资源受限的环境。
- 灵活性:提供了多个版本的模型,可以根据具体的应用需求选择合适的模型大小。
5. 优缺点
- 优点:
- 高效性:在保持较小模型大小和较快推理速度的同时,实现了较高的准确率。
- 灵活性:提供了多个版本的模型,适用于不同的应用需求。
- 均衡扩展:通过复合缩放方法实现了更均衡的网络扩展。
- 缺点:
- 复杂度较高:复合缩放方法需要同时调整多个维度,增加了模型设计的复杂度。
- 对计算资源要求较高:虽然EfficientNetV1在资源利用效率上有所提升,但相对于一些轻量级网络而言,其计算资源需求仍然较高。
6. 应用场景
EfficientNetV1在多个领域都有广泛的应用场景,包括但不限于:
- 图像分类:作为一种高效的图像分类模型,EfficientNetV1在ImageNet等数据集上取得了优异的表现。
- 目标检测:EfficientNetV1可以作为目标检测模型的特征提取网络,提高目标检测的准确性,特别是在小目标检测方面。
- 图像分割:增强图像分割的语义理解能力,提高分割精度。
- 其他领域:如自然语言处理、语音识别等领域也可以借鉴EfficientNetV1的复合缩放方法和高效网络架构思想。
综上所述,EfficientNetV1是一种高效、灵活的神经网络架构,通过复合缩放方法和高效的网络结构设计,实现了在计算资源和准确性之间的良好平衡。其广泛的应用场景也证明了其在实际应用中的价值。
2.16 CSPNet:跨阶段局部网络(2020)
CSPNet的提出背景
CSPNet(Cross Stage Partial Network)的提出背景主要源自对现有计算机视觉模型的分析和挑战。随着深度学习的发展,虽然神经网络在图像分类、目标检测等任务上取得了显著进展,但这些进展往往依赖于大量的计算资源,这在计算资源受限的环境下(如嵌入式设备和边缘计算平台)是不切实际的。此外,现有的轻量级模型在追求轻量化的同时,往往牺牲了模型的准确性,且存在计算瓶颈和内存开销较大的问题。因此,CSPNet旨在解决这些问题,提出一种能够在保持模型准确性的前提下,提高计算效率和推断速度的轻量级网络结构。
主要贡献
CSPNet的主要贡献包括:
- 增强CNN的学习能力:通过跨阶段部分连接策略,CSPNet能够在轻量化的同时保持较高的准确性,从而增强CNN模型的学习能力。
- 降低计算瓶颈:通过优化网络结构和计算流程,CSPNet显著降低了计算瓶颈,提高了模型的推断速度。
- 减少内存成本:在特征金字塔生成特征图的过程中,CSPNet采用交叉通道池化压缩特征图,从而减少了内存占用。
- 通用性:CSPNet不仅适用于图像分类任务,还可以轻松地与ResNet、DenseNet等网络结构结合,应用于目标检测、语义分割等计算机视觉任务。
网络结构
CSPNet的核心在于其跨阶段部分连接(Cross Stage Partial Connections)的设计。具体来说,CSPNet将基础层的特征图划分成两部分:一部分经过密集连接模块(如Dense Block)进行特征提取和融合;另一部分则直接通过过渡层(Transition Layer)进行下采样或特征转换。最后,这两部分特征图通过拼接(Concatenation)操作进行合并,得到最终的特征表示。这种设计既保留了DenseNet等网络结构重用特征的特性,又通过截断梯度流防止了过多的梯度信息重复,从而提高了模型的学习能力和推断效率。
特点
CSPNet的特点主要包括:
- 轻量级:通过跨阶段部分连接策略,CSPNet在保持较高准确性的同时,实现了模型的轻量化。
- 高效性:优化后的网络结构和计算流程显著降低了计算瓶颈和内存开销,提高了模型的推断速度。
- 灵活性:CSPNet易于与不同的网络结构结合,适用于多种计算机视觉任务。
- 鲁棒性:通过增加梯度传播路径和平衡每一层的计算量,CSPNet提高了模型的鲁棒性和泛化能力。
优缺点
优点:
- 轻量级且高效:在保证模型准确性的同时,降低了计算复杂度和内存占用。
- 灵活性高:易于与不同的网络结构结合,适用于多种计算机视觉任务。
- 鲁棒性强:通过优化网络结构和计算流程,提高了模型的泛化能力和稳定性。
缺点:
- 需要针对具体任务进行调优:虽然CSPNet具有通用性,但在应用于具体任务时仍需要根据实际情况进行调优以达到最佳性能。
- 对硬件要求较高:虽然CSPNet在计算效率和内存占用方面有所优化,但在处理大规模数据集或复杂任务时仍需要较高的硬件配置。
应用场景
CSPNet适用于多种计算机视觉任务,包括但不限于:
- 图像分类:提高常规图像分类任务的准确性。
- 目标检测:在对象检测框架中作为基础网络以提高检测性能。
- 语义分割:对于需要理解像素级别的图像任务提供强大支持。
- 视频分析:由于其高效特性,可应用于实时视频理解等场景。
总之,CSPNet作为一种新型的轻量级网络结构,在保持模型准确性的同时提高了计算效率和推断速度,为计算机视觉领域的研究和应用提供了新的思路和方法。
2.15 EfficientNetV2 (2021)
EfficientNetV2是由Google研究人员Mingxing Tan和Quoc V. Le等人在2021年提出的一种深度学习模型,它是EfficientNet系列的最新迭代。以下是对EfficientNetV2的提出背景、主要贡献、网络结构、特点、优缺点及应用场景的详细解析:
提出背景
EfficientNetV1通过复合缩放(compound scaling)策略,在不显著增加计算负担的情况下,显著提升了模型性能。然而,随着模型复杂度的增加,训练时间和资源需求也相应增长。EfficientNetV2的提出正是为了解决这一问题,目标是在保证高效率的同时,进一步提升模型的训练速度和参数效率。
主要贡献
- Fused-MBConv结构:在EfficientNetV1中使用的MBConv(Mobile Inverted Residual Bottleneck)结构基础上,EfficientNetV2引入了Fused-MBConv。这种结构通过融合扩张卷积(expansion convolution)和深度可分离卷积(depthwise convolution),用一个标准的3x3卷积层替换,从而简化了网络结构,减少了计算成本,同时加速了训练过程。
- 训练感知的神经架构搜索(Training-aware NAS):EfficientNetV2采用了一种新的神经架构搜索方法,该方法在搜索过程中直接考虑了模型的训练速度,而不只是最终的评估性能。这意味着搜索出来的模型不仅准确率高,而且训练起来更快。
- 更高效的缩放策略:EfficientNetV2不仅沿用了复合缩放的思想,还进一步优化了缩放策略,以适应新的Fused-MBConv结构,使得模型在不同规模下都能达到最佳的效率和性能平衡。
- 渐进式学习策略:这一策略允许模型从较小的规模开始训练,逐步过渡到更大规模的模型,有助于加速收敛并可能提升最终模型的性能。同时,它还会根据训练图像的尺寸动态调整正则化方法(如Dropout、Rand Augment和Mixup),从而提高训练速度和准确性。
网络结构
EfficientNetV2的网络结构在EfficientNetV1的基础上进行了改进,主要包括以下几点:
- 使用Fused-MBConv模块:在网络浅层使用Fused-MBConv模块,以加速训练过程并减少计算成本。
- 较小的扩展因子(expansion ratio):使用较小的扩展因子,如4,而不是EfficientNetV1中的6,以减少内存访问开销。
- 更小的卷积核(kernel size):偏向使用更小的卷积核,如3x3,而不是EfficientNetV1中的5x5,以增加感受野但减少计算量。
- 移除最后一个步距为1的阶段:移除了EfficientNetV1中最后一个步距为1的阶段,以减少参数数量和内存访问开销。
特点
- 高效性:通过优化网络结构和缩放策略,EfficientNetV2在保持高性能的同时,显著提升了训练速度和参数效率。
- 适应性:采用渐进式学习策略,能够根据训练图像的尺寸动态调整正则化方法,提高模型的适应性。
- 易部署性:由于其较小的模型尺寸和较快的推理速度,EfficientNetV2更容易在资源受限的设备上部署。
优缺点
优点:
- 训练速度快:相比其他模型,EfficientNetV2的训练速度显著提升。
- 参数效率高:在保持高性能的同时,减少了模型参数数量。
- 易于部署:较小的模型尺寸和较快的推理速度使得EfficientNetV2更容易在多种设备上部署。
缺点:
- 依赖训练数据集:EfficientNetV2的有效性和泛化能力可能受到训练数据集的限制。
- 计算资源要求:尽管训练速度有所提升,但在大规模训练时仍需要一定的计算资源。
应用场景
EfficientNetV2由于其高效性和高性能,被广泛应用于图像分类、物体检测、语义分割等计算机视觉任务中。同时,它也在医疗影像分析、自动驾驶、无人机导航等领域得到了实际应用。在资源有限的场景下,如移动设备和嵌入式系统,EfficientNetV2的优势尤为明显。
三、骨干网络的应用场景
-
图像分类:在图像分类任务中,骨干网络的输出通常连接到一个全连接层或全局池化层,以便对提取的特征进行分类。
-
目标检测:在目标检测任务中,骨干网络通常与额外的头部网络结合,用于预测图像中物体的位置和类别。例如,在YOLOv7中,EfficientNet被用作骨干网络以提高目标检测的准确性和速度。
-
语义分割:在语义分割任务中,骨干网络的输出被送入解码器网络,以将特征映射回原始图像的像素级别,从而生成语义分割的结果。
-
自然语言处理:虽然自然语言处理(NLP)任务中更多使用循环神经网络(RNN)或Transformer等架构,但卷积神经网络也在一些NLP任务中作为骨干网络使用,特别是在处理文本分类、情感分析等任务时。
四、总结
骨干网络是深度学习模型中的重要组成部分,负责从原始输入中提取有效的特征表示。不同的骨干网络架构具有各自的特点和优势,适用于不同的任务和场景。在选择骨干网络时,需要根据具体任务的需求、数据的特性以及计算资源的限制进行综合考虑。



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











