










原文链接:
https://arxiv.org/pdf/2102.00240.pdf
源码地址:
https://github.com/wofmanaf/SA-Ne
摘要简介:
注意力机制让神经网络能够准确关注输入的所有相关元素,已成为提高深度神经网络性能的关键组件。在计算机视觉研究中,主要有两种广泛使用的注意力机制:空间注意力和通道注意力。它们分别旨在捕捉像素级的成对关系和通道依赖性。虽然将它们融合在一起可能比单独使用它们表现更好,但这会不可避免地增加计算开销。
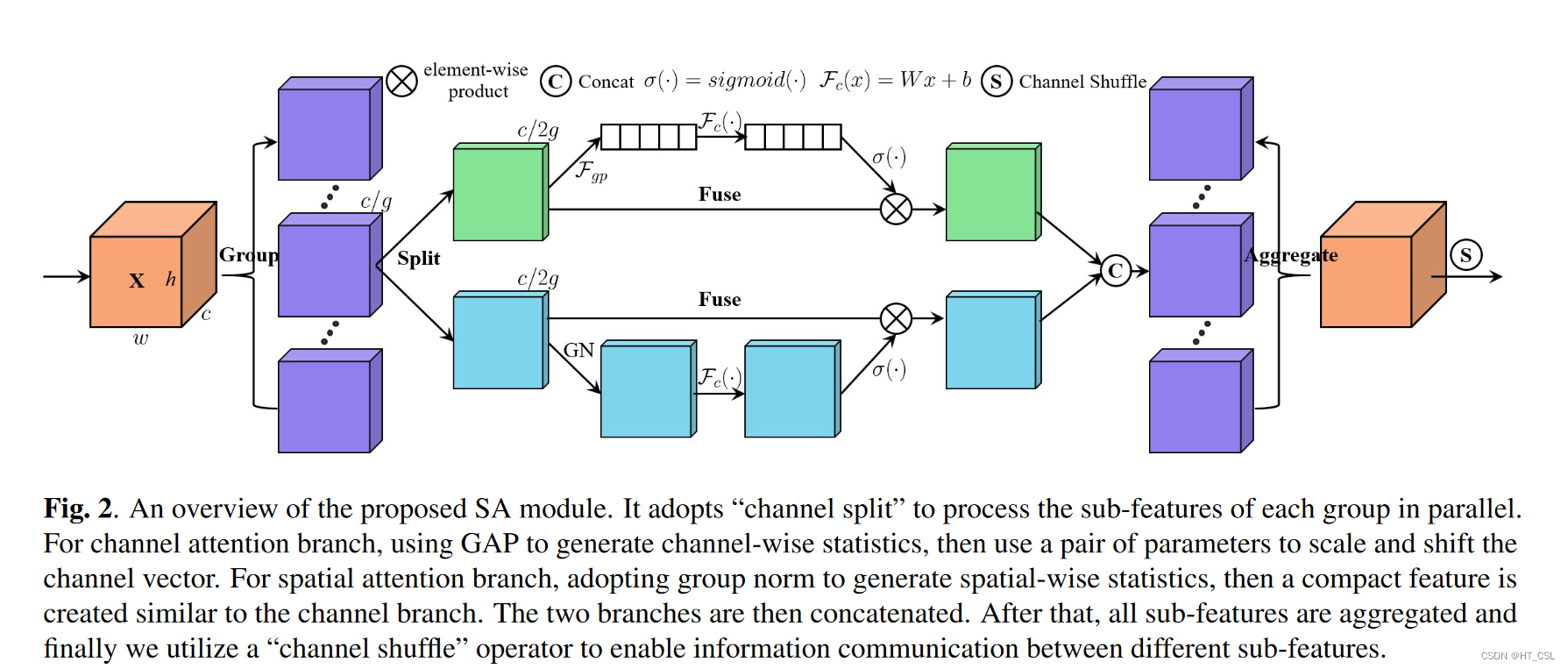
在本文中,我们提出了一个高效的Shuffle Attention(SA)模块来解决这个问题。该模块采用Shuffle单元有效地结合了两种注意力机制。具体来说,SA首先将通道维度分组为多个子特征,然后并行处理它们。接着,对于每个子特征,SA使用Shuffle单元来描绘空间和通道维度上的特征依赖性。之后,所有子特征被聚合,并采用“通道Shuffle”操作符来使不同子特征之间的信息得以交流。
提出的SA模块既高效又有效。例如,与骨干网络ResNet50相比,SA的参数和计算量分别为300与25.56M,以及2.76e-3 GFLOPs与4.12 GFLOPs,但Top-1准确率提高了1.34%以上。在ImageNet-1k分类、MS COCO目标检测和实例分割等常用基准测试上的大量实验结果表明,所提出的SA在保持较低模型复杂度的同时,显著优于当前的SOTA方法,实现了更高的精度。
模型结构图:
Pytorch版源码:
import torch
from torch import nn
from torch.nn import init
from torch.nn.parameter import Parameter
class ShuffleAttention(nn.Module):
def __init__(self, channel=512, G=8):
super().__init__()
self.G = G
self.channel = channel
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))
self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sigmoid = nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
@staticmethod
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
# 扁平化
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.size()
# 将通道分成子特征
x = x.view(b * self.G, -1, h, w) # bs*G,c//G,h,w
# 通道分割
x_0, x_1 = x.chunk(2, dim=1) # bs*G,c//(2*G),h,w
# 通道注意力
x_channel = self.avg_pool(x_0) # bs*G,c//(2*G),1,1
x_channel = self.cweight * x_channel + self.cbias # bs*G,c//(2*G),1,1
x_channel = x_0 * self.sigmoid(x_channel)
# 空间注意力
x_spatial = self.gn(x_1) # bs*G,c//(2*G),h,w
x_spatial = self.sweight * x_spatial + self.sbias # bs*G,c//(2*G),h,w
x_spatial = x_1 * self.sigmoid(x_spatial) # bs*G,c//(2*G),h,w
# 沿通道轴拼接
out = torch.cat([x_channel, x_spatial], dim=1) # bs*G,c//G,h,w
out = out.contiguous().view(b, -1, h, w)
# 通道混洗
out = self.channel_shuffle(out, 2)
return out
if __name__ == '__main__':
input = torch.randn(2, 32, 512, 512)
SA = ShuffleAttention(channel=input.size(1))
output = SA(input)
print(output.shape)

















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









