






CBAM(Convolutional Block Attention Module)是轻量级的卷积注意力模块,它结合了通道和空间的注意力机制模块。
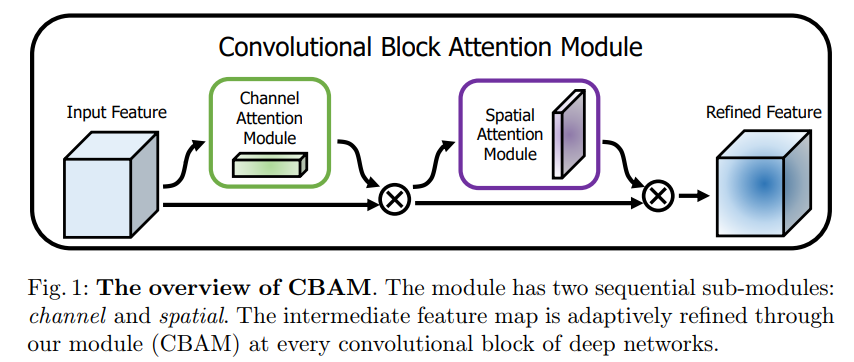
上图可以看到,CBAM包含CAM(Channel Attention Module)和SAM(Spartial Attention Module)两个子模块,分别进行通道和空间上的Attention。这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
(1)Channel attention module(CAM)
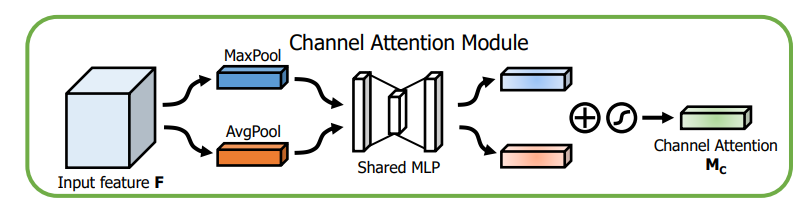
通道注意力模块:通道维度不变,压缩空间维度。
(2)Spatial attention module(SAM)
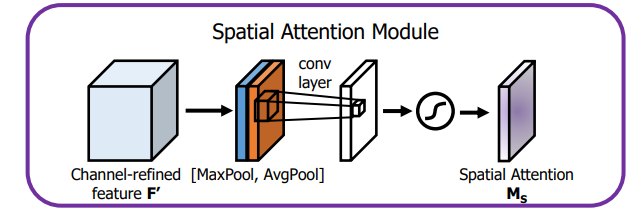
空间注意力模块:空间维度不变,压缩通道维度。该模块关注的是目标的位置信息。
代码实现:
import torch
import torch.nn as nn
class CBAMLayer(nn.Module):
def __init__(self, channel, reduction=16, spatial_kernel=7):
super(CBAMLayer, self).__init__()
# channel attention 压缩H,W为1
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# shared MLP
self.mlp = nn.Sequential(
# Conv2d比Linear方便操作
# nn.Linear(channel, channel // reduction, bias=False)
nn.Conv2d(channel, channel // reduction, 1, bias=False),
# inplace=True直接替换,节省内存
nn.ReLU(inplace=True),
# nn.Linear(channel // reduction, channel,bias=False)
nn.Conv2d(channel // reduction, channel, 1, bias=False)
)
# spatial attention
self.conv = nn.Conv2d(2, 1, kernel_size=spatial_kernel,
padding=spatial_kernel // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
max_out = self.mlp(self.max_pool(x))
avg_out = self.mlp(self.avg_pool(x))
channel_out = self.sigmoid(max_out + avg_out)
x = channel_out * x
max_out, _ = torch.max(x, dim=1, keepdim=True)
avg_out = torch.mean(x, dim=1, keepdim=True)
spatial_out = self.sigmoid(self.conv(torch.cat([max_out, avg_out], dim=1)))
x = spatial_out * x
return x
SENet
class SE_Block(nn.Module): # Squeeze-and-Excitation block
def __init__(self, in_planes):
super(SE_Block, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.conv1 = nn.Conv2d(in_planes, in_planes // 16, kernel_size=1)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_planes // 16, in_planes, kernel_size=1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.avgpool(x)
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
out = self.sigmoid(x)
return out*x
Spatial_Attention
class spatialAttention(nn.Module):
def __init__(self , kernel_size = 7):
super(spatialAttention, self).__init__()
assert kernel_size in (3 , 7 ), " kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
# avg 和 max 两个描述,叠加 共两个通道。
self.conv1 = nn.Conv2d(2 , 1 , kernel_size , padding = padding , bias = False)#保持卷积前后H、W不变
self.sigmoid = nn.Sigmoid()
def forward(self , x):
# egg:input: 1 , 3 * 2 * 2 avg_out :
avg_out = torch.mean(x , dim = 1 , keepdim = True)#通道维度的平均池化
# 注意 torch.max(x ,dim = 1) 返回最大值和所在索引,是两个值 keepdim = True 保持维度不变(求max的这个维度变为1),不然这个维度没有了
max_out ,_ = torch.max(x , dim =1 ,keepdim=True)#通道维度的最大池化
# print(avg_out.shape)
# print(max_out.shape)
x = torch.cat([avg_out , max_out] , dim =1)
# print(x.shape)
x = self.conv1(x)
out = self.sigmoid(x)
return out * x















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









