





系列文章目录
基于非线性向量自回归延迟嵌入的时间序列核 NeurIPS 2023
文章目录
摘要
核设计是时间序列分析的一个关键但具有挑战性的方面,特别是在小数据集的背景下。 近年来,油藏计算(RC)已成为一种强大的工具,可以根据生成过程的基本动态而不是观测数据来比较时间序列。 然而,RC 的性能高度依赖于超参数设置,由于 RC 的循环性质,超参数设置难以解释且优化成本高昂。 在这里,我们基于最近建立的油藏动力学和非线性向量自回归(NVAR)过程之间的等价性,提出了一个新的时间序列内核。 内核是非循环的,并且依赖于一小组有意义的超参数,为此我们建议采用有效的启发式方法。 我们在各种现实世界的分类任务中展示了出色的性能,无论是在准确性还是速度方面。 这进一步加深了对 RC 表示学习模型的理解,并将 NVAR 框架的典型用途扩展到内核设计和现实世界时间序列数据的表示。
一、引言
时间序列可以说是现代最重要的数据类型之一(Hamilton,2020),并且在科学研究(Strogatz,2018)和实际应用中无处不在(Zhang 等,2018;Zeroual 等,2020) 。 大多数时间序列机器学习协议设计的一个关键要素是相似性的量化(Ding 等人,2008 年;Abanda 等人,2019 年;Echihabi 等人,2020 年)。 对于核方法尤其如此(Schölkopf 等,2001),核方法将数据投影到更高(可能是无限)维空间后搜索线性解决方案,并代表非线性模型的有效替代方案。 核方法的性能很大程度上受到当前数据类型(即核)的正半定(PSD)相似函数的定义的影响。 然而,他们的设计对于单变量(UTS)和多变量时间序列(MTS)等结构化数据具有挑战性,这些数据表现出时间自相关、属性间(或维度)依赖性以及可能的各种时间扭曲和错位(Paparrizos 等,2017)。 ,2020)。
为了克服这个问题,一种有前途的方法是识别和比较潜在的动态而不是原始的观察数据。 值得注意的是,基于储层计算(RC)的内核在这种情况下脱颖而出(Chen 等人,2013 年;Bianchi 等人,2020 年)。 基于 RC 的内核使用随机且未经训练的循环连接节点(存储层)层将每个时间序列映射到丰富的动态特征空间。 然后通过比较捕获动态的各个读数来获得相似性。 在实践中,RC 对大量可解释性极低的超参数高度敏感,其优化对于全面的值范围具有挑战性。
最近,Bollt (2021) 的一项理论工作证明,简单的 RC 可以正式重写为非线性向量自回归 (NVAR) 模型。 在 NVAR 框架中,存储库被输入序列与延时副本和非线性泛函(例如乘积)的简单串联所取代(Gauthier 等人,2021)。 这减少了超参数的数量,并已被证明在混沌系统预测中非常有效(Shahi et al., 2022),足以赢得“下一代油藏计算”的称号。 然而,它对于现实世界数据以及预测动力系统之外的适用性和性能在很大程度上尚未得到探索。
在这项工作中,我们研究 NVAR 过程是否可以替代内核设计的水库,以及提取的特征在比较现实世界时间序列数据时是否同样有效。 我们为 UTS 和 MTS 数据提出了一个非常高效且有效的 NVAR 内核。 主要思想如下(图1)。 首先,我们用自身的滞后副本和附加非线性项来丰富每个时间序列,形成高维 NVAR 嵌入。 然后,我们提取嵌入空间中时间演化的线性参数化,代表底层动态,类似于 RC 表示学习方法(Bianchi 等人,2020)。 最后,这些拟合参数用于计算时间序列之间的相似度。 我们的主要贡献涉及研究时间序列的不同社区,即内核设计、RC 和 NVAR,为每个社区带来特定的好处:
• 从内核设计的角度来看,我们为UTS 和MTS 提供了NVAR 内核以及基于简单启发式的通用参数设置。 根据我们对各种数据集的实验,所提出的方法在准确性方面与最先进的(SOTA)相匹配,并且比 SOTA 快得多,代表了准确性和效率之间的最佳折衷。
• 从RC 的角度来看,我们通过结合NVAR 制作的动态来推进其在TS 表示方面的成功。 所得模型更加准确、可解释且非循环,克服了超参数优化的困难,并揭示了潜在的 RC 性能。
• 从 NVAR 的角度来看,我们将框架扩展到现实世界的时间序列表示和内核,远远超出了预测合成、无噪声和混沌动力系统的原始工作(Gauthier 等人,2021)。
• 我们建立了与 Takens 定理(Takens,1981)和状态空间重建领域(Sauer 等人,1991)的联系,这从理论上支撑了我们的方法,强调了在机器学习中使用动力系统理论的引人注目的途径 。
1.1 Notation
通过论文,我们将变量表示为小写(x); 常量为大写 (X); 向量和 UTS 为粗体小写 (x); 矩阵和 MTS 为粗体大写 X。方括号 x[n] 之间的索引表示集合中的第 n 个样本。 对于MTS X,对应的小写 x t x_t xt表示时间戳t处的所有维度,而 x d x^d xd表示所有时间戳处的维度d。
二、 Related methods
在本节中,我们提供了先前提出的时间序列数据内核的背景知识(按类别分组)。 尽管有大量的时间序列相似性度量(Yang & Shahabi,2004;Paparrizos & Gravano,2015;Janati 等人,2020),我们将讨论限制在 PSD 指标上。
Lock-step 锁步方法将时间序列视为静态向量并直接使用常见的距离度量(Cha,2007)。 PSD 属性通常通过叠加线性或径向核来获得(Schölkopf 等人,2002)。 这是非常有效的,但忽略了系列内的任何时间结构,并且不适用于不同的长度。
Elastic弹性测量考虑了时间扭曲(例如移位)或序列之间的不同长度。 卢等人。 (2008)提出对序列进行插值并将问题视为曲线之间的距离。 相反,全局对齐内核 (GAK) (Cuturi, 2011) 和 KDTW (Marteau & Gibet, 2014) 是基于著名的动态时间规整 (DTW) (Berndt & Clifford, 1994) 构建的,并根据以下成本计算相似度: 系列之间的一对多对齐。 平移不变核 (SINK) (Paparrizos & Franklin, 2019) 计算傅里叶域中的互相关相似度。 然而,对于上述方法,成对相似度的计算在计算上是昂贵的并且没有考虑多变量情况下不同属性之间的关系。
Model-based 基于模型的内核使用概率或确定性模型处理该序列,并根据提取的信息确定相似性。 这样的模型可以是单个生成模型,如 Fisher 核(Jaakkola et al., 1999)或概率积核(Jebara et al., 2004),也可以是参数化的概率分布族,如自回归核 (Cuturi 和 Doucet,2011)。 与后者类似,时间聚类内核 (TCK)(Mikalsen 等人,2018)是从高斯混合后验集合中获得的,共享相同的参数形式,但在数据集的不同子集上进行训练。 在非概率方法中,学习模式相似度 (LPS)(Baydogan & Runger,2016)使用回归树集合从每个序列中提取局部模式。 所有这些方法的缺点都来自于特定的函数形式,这可能会限制所提取特征的通用性。 集成方法也不适合训练样本较少的数据集。
Reservoir-based 储层计算(RC)是一类循环神经网络,它保持循环连接未经训练,以克服随时间反向传播的高成本(Werbos,1990)以及梯度爆炸和消失的脆弱性(Pascanu 等人,2013) )。 其最简单的形式是回声状态网络(ESN)(Jaeger,2001),由三层组成:输入层、连接神经元的隐藏层(存储层)和读出层:
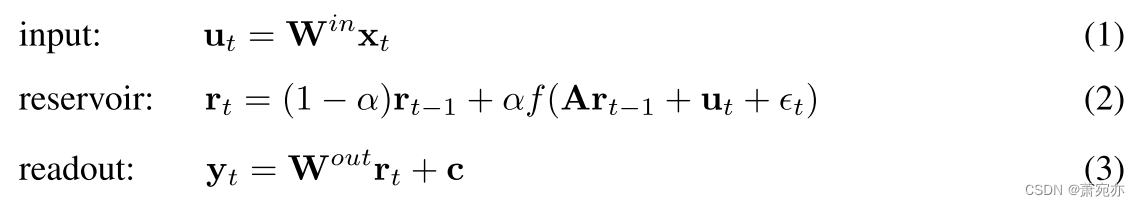
其中
x
t
∈
R
d
x
,
u
t
∈
R
d
r
and
r
t
∈
R
d
r
\begin{aligned}\mathbf{x}_t\in\mathbb{R}^{d_x},\mathbf{u}_t\in\mathbb{R}^{d_r}\text{ and }\mathbf{r}_t\in\mathbb{R}^{d_r}\end{aligned}
xt∈Rdx,ut∈Rdr and rt∈Rdr分别是输入、其放大投影和时间 t 时的储层状态(其中 dr ≫ dx 且 r0 := 0); 0 ≤ α ≤ 1 为泄漏参数; ϵt 是加性噪声,f 是任何非线性激活函数。 储层 (
A
∈
R
d
r
×
d
r
\mathbf{A}\in\mathbb{R}^{d_{r}\times d_{r}}
A∈Rdr×dr) 和投影 (
W
i
n
∈
R
d
r
×
d
x
\mathbf{W}^{in}\in{\mathbb{R}}^{d_{r}\times d_{x}}
Win∈Rdr×dx ) 矩阵保持未训练状态,而读数 (
W
o
u
t
∈
R
d
y
×
d
r
\mathbf{W}^{out}\in\mathbb{R}^{d_{y}\times d_{r}}
Wout∈Rdy×dr) 和偏差项 © 通过将储层状态拟合到 通过岭回归输出 (
y
t
∈
R
d
y
\mathbf{y_t}\in\mathbb{R}^{d_y}
yt∈Rdy )。
尽管具有随机性,但储层状态构成了丰富的异质特征池,这些特征提供了生成观测时间序列的底层动力系统的完整知识(Løkse 等人,2017 年;Bianchi 等人,2020 年)。 事实上,与拟合特定的函数形式相反,坚实的理论基础可以确保储层特征的质量(Hart et al., 2020; Gonon et al., 2023; Gonon & Ortega, 2021; Hart et al., 2021) )。 然而,性能对控制储层初始化和更新的大量超参数的选择高度敏感(Lukoševiˇcius,2012)。 例如,输入缩放 (||Win||) 和谱半径 (ρ(A)) 确保稳定的储层动力学 (Gallicchio, 2019) 并控制注入的非线性程度。 这并不容易判断,需要对非线性动力学有丰富的洞察力。 一般来说,ESN参数的解释和设置是一项复杂的任务,并且迄今为止仍然是一个活跃的研究领域(Dong等人,2022;Steiner等人,2022;Zhang等人,2022)。 简单的监督优化,例如交叉验证(CV),通常是令人望而却步的,因为优化空间很大,并且存储库的递归性质迫使方程的计算。 2 在评估一个超参数设置的性能之前,该系列的整个长度。
关于基于 RC 的内核,Chatzis & Demiris (2011) 最初直接在储层状态顶部构建了一个径向内核。 在陈等人中。 (2013),所有序列均由共享存储库处理,并根据各自的读数进行比较,这些读数分别在一步预测任务 (
y
t
=
x
t
+
1
\mathbf{y}_t=\mathbf{x}_{t+1}
yt=xt+1) 上进行训练。 最后,比安奇等人。 (2020)观察到,使用
y
t
=
r
t
+
1
\mathbf{y}_t=\mathbf{r}_{t+1}
yt=rt+1可以保留更多信息,并且可以通过对所有读出权重的矢量化应用径向函数来获得有效的内核。
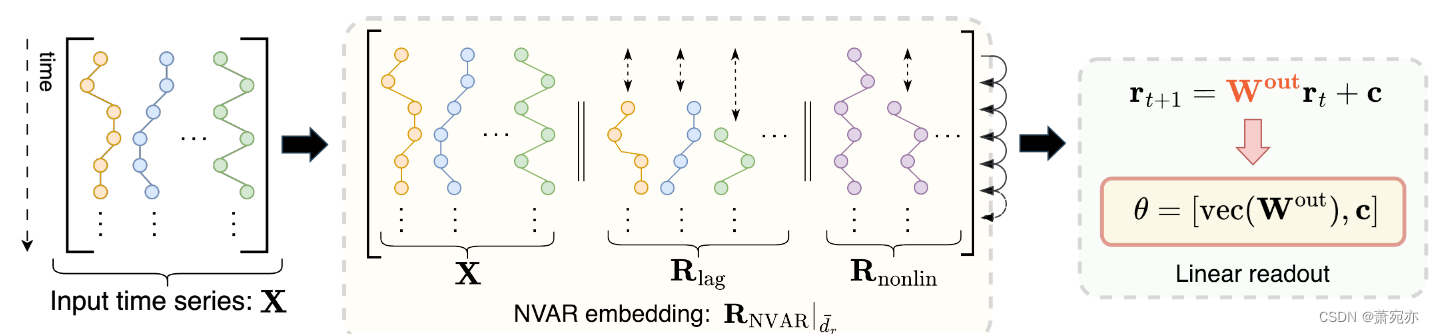
图 1:NVAR 内核中每个表示向量的构建。 输入序列 X 与
R
l
a
g
,
\mathbf{R}_{lag},
Rlag,(包含所有输入维度的 k 个滞后)和
R
n
o
n
l
i
n
,
\mathbf{R}_{nonlin},
Rnonlin,(包含 X 维度和
R
l
a
g
,
\mathbf{R}_{lag},
Rlag,维度之间的乘积)连接。 在所有可能的串联项中,仅考虑维度的随机子集。 然后,读出器通过沿时间维度执行岭回归拟合来提取嵌入状态的线性动态 (Wout) 和偏差项 ©。 这些拟合参数被矢量化以形成表示。
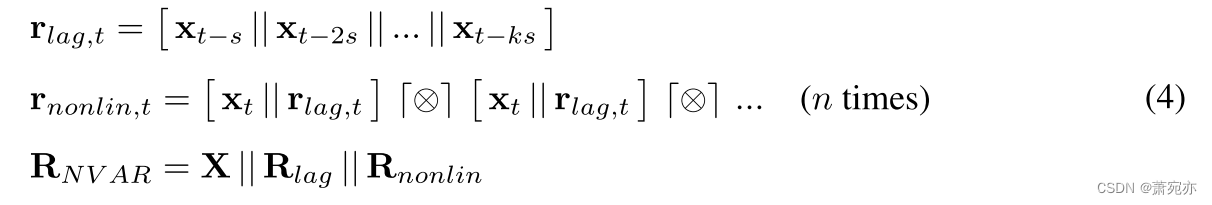
·|| · 是按列串联, · ⌈⊗⌉ · 执行外积并连接所有唯一的单项式。
该过程非常有效,因为它是非重复性的,并且 R N V A R \mathbf{R}_{NVAR} RNVAR 的大小通常小于典型水库的大小。 最重要的是,它由一小组整数超参数决定:k、s 和 n。 原则上,为了维持与 RC 的等价性,应考虑无限量的滞后 (k → ∞)。 尽管如此,据观察,n = 2 的小 k 在典型的动力系统预测任务中仍然可以表现得非常好(Gauthier et al., 2021; Shahi et al., 2022; Gauthier et al., 2022)。 然而,NVAR 模型在预测之外的适用性和性能在很大程度上尚未得到探索,特别是在表示和比较现实世界时间序列数据的背景下。 在这方面,他们提出了一种有前途的解决方案,可以显着增强 RC 表示和内核。
3.2 NVAR kernel
我们在此介绍 NVAR 内核 (NVARk),它将 NVAR 框架与基于 RC 的内核架构集成在一起。 给定一对时间序列 X[i]、X[j](维度 dx 的长度可能不同),NVARk 分三个步骤进行操作,我们将在以下段落中介绍。 图 1 描述了图形参考,而算法 1 明确了算法过程。

NVAR 嵌入 总体思路是使用等式定义的 NVAR 图来转换时间序列。 4,其中 n = 2。然而,对于给定的滞后数 k 的选择,所得到的附加维度数与 O(d2 xk2) 成比例。 对于中等高的
d
x
d_{x}
dx,这可能会导致高共线性并增加后续读出中的维数灾难,使其缓慢且不准确。 它还限制了 k 的可能选择,以及捕获长期记忆效应的能力。 事实上,这种方法似乎只在动力系统的背景下才显得容易处理,其中
d
x
d_{x}
dx 通常非常受限制。 为了解决这个问题并使该方法适用于更高维度的数据集,我们建议仅连接所有可能维度的随机子样本:
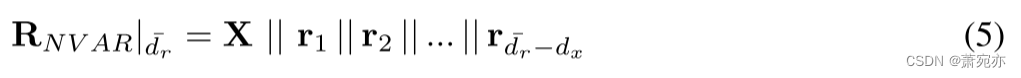
其中
{
r
a
}
a
=
1
d
ˉ
r
−
d
x
\{\mathbf{r}_{a}\}_{a=1}^{\bar{d}_{r}-d_{x}}
{ra}a=1dˉr−dx 在 [Rlag ||Rnonlin] 中随机采样的列,具有均匀概率和
d
ˉ
r
\bar{d}_{r}
dˉr 阈值超参数(所有项均省略符号 [i],并且相同的操作应用于时间序列 [j])。 这会将确定性 NVAR 图转换为随机特征图。 我们在下文中支持这一选择,指出 NVAR 模型与状态空间重构 (SSR) 理论之间未经探索的联系(Kantz & Schreiber,2004;Strogatz,2018)。
一般来说,我们可以将观测到的数据解释为更复杂的底层动力学 ( ϕ ∗ \phi^{*} ϕ∗) 的实现,作用于一些未知状态 ( x ∗ ) : x t + 1 ∗ = ϕ ∗ ( x t ∗ ) (\mathbf{x}^{*})\colon\mathbf{x}_{t+1}^{*}=\phi^{*}(\mathbf{x}_{t}^{*}) (x∗):xt+1∗=ϕ∗(xt∗)。 SSR 专注于使用观测到的数据 (x) 构建嵌入状态 (st),其动力学在拓扑上等效于 ϕ ∗ \phi^{*} ϕ∗,从而更好地表示底层系统(Casdagli 等人,1991)。 在这方面,著名的 Takens 定理(Takens,1981)声称,有效的嵌入,称为延迟嵌入(Packard 等人,1980),可以通过将输入与其滞后相连接来形成,最重要的是,保证不 所有滞后都是需要的,但只需要足够数量的 ℓ:\mathbf{s}{t}=[x{t},x_{t-s},x_{t-2s},…,x_{t-\ell s}].。 最近,Deyle 和 Sugihara (2011) 的工作提出了 Takens 定理对多元输入的推广,其中为了匹配 ℓ,可以将滞后分布在不同的观察维度上,并且还可以考虑输入的替代函数。 NVAR 表示中的所有项(即滞后项和非线性项)都让人想起这个公式,因此我们选择不考虑所有项,而是对串联项的数量设置上限(等式 5)。
这也让我们对我们的方法有不同的看法。 我们可以解释 R N V A R ∣ d r ˉ \mathbf{R}_{NVAR}|_{\bar{d_{r}}} RNVAR∣drˉ试图创建动态近似于生成数据的基础状态的状态。 由于生成过程中通常会丢失信息,因此基于这种状态的比较比直接使用观察到的数据更真实。 在实践中,噪声的存在使我们无法获得如此精确的状态(Casdagli 等人,1991),并将我们的方法置于嵌入学领域(Sauer 等人,1991),即用 特殊功能,克服了原始 Takens 公式中对噪声的敏感性。 附录 A 更广泛地讨论了这一理论框架。
方程的替代方案。 5 将生成完整的 NVAR 表示,然后是降维模块,如 Bianchi 等人中所示。 (2020)。 在我们的初步评估中,这被证明在计算上更加昂贵并且导致性能较差,可能是因为降维没有保留延迟嵌入结构。
线性读数通过岭回归训练各个线性读数(方程 3),以解决相同嵌入状态上的一步预测任务,即使用 y t = r t + 1 \mathbf{y}_t=\mathbf{r}_{t+1} yt=rt+1。 然后提取每个模型的参数并进行矢量化以获得表示 θ[i] 和 θ[j]。 这一步消除了对 TS 长度的依赖,这意味着内核可以比较不同长度的 TS。
由于读出对与其滞后和二次乘积连接的输入进行操作,因此这些表示向量可以被解释为封装与输入维度内的自互和互信息相关的统计数据。 相比之下,RC 方法的表示几乎涵盖了难以解释的储层动力学。
RBF聚合最后,使用径向函数来保证PSD属性并形成内核:
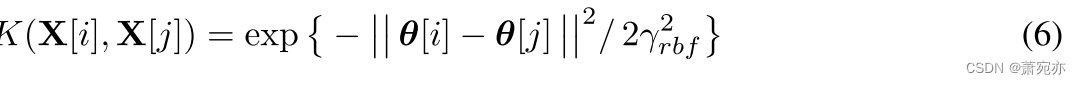
3.3 Hyperparameter setting
我们在这里显示构建 NVARk 并提出启发式表达式的超参数。
滞后数 (k) 和滞后大小 (s) 参数 k 和 s 在 NVAR 框架(方程 4)以及我们的方法中发挥着关键作用。 这些关键参数具有明确的解释:k 控制滞后数量并扩展内存容量,即捕获进一步延伸到过去的重要依赖关系; s 控制滞后之间的间距,从而管理探测这些依赖性的时间分辨率。 相比之下,关键的 RC 参数可能更难解释。
在 Takens 的公式中,在无限长、无噪声时间序列的情况下,对任何特定滞后 s 不存在重要性偏差,并且它们的数量 k 是唯一相关因素。 这通常是使用虚假最近邻算法来确定的(Kennel 等人,1992 年;Wallot 和 Mønster,2018 年)。 然而,当处理有限的噪声观测时,s 的选择变得同样重要,因为它与采样频率直接相关(Broomhead & King,1986)。 特别是,使用太高的值将强制对不相关点进行建模,而太低的值则会对噪声进行建模。 相反,正确选择 s 可以提取季节性或其他相关趋势以及潜在的动态。 在实践中,对于噪声系统,由于缺乏明确的理论指导,k 和 s 的选择本质上是一个难题(Tran & Hasekawa,2019)。 尽管如此,可以利用可解释性来提出依赖于任务的启发式算法(Small & Tse,2004),通常需要在冗余和级联特征的不相关性之间进行权衡。
在这项工作中,我们提出了两种设置。 第一条是经验法则,具体流程如下。 我们首先对时间序列应用趋势过滤方法,例如 ℓ1 趋势(Kim 等人,2009)(这允许选择捕获系统时间变化而不是叠加噪声的 s)。 然后我们将乘积 k · s 设置为峰与谷之间的平均距离 (dbp) (Kugiumtzis, 1996)。 最后,我们通过采用 s=k= d b p \sqrt{\mathrm{dbp}} dbp来平衡贡献。 或者,在监督设置中,这两个参数都通过 CV 进行优化。
多项式阶数 (n) 多项式阶数控制嵌入中的非线性量。 与之前的大多数工作一样,我们发现不需要比 n = 2 更复杂的值。
嵌入维数 ($
\bar{d}{r}$) 在 Takens 的公式中,嵌入大小是底层流形维数的两倍就足以重建系统动力学。 然而,在处理现实世界的数据时,这是未知的,必须在相关特征的省略和冗余之间进行权衡,这会增加共线性和计算时间。 根据我们的工作范围,我们选择优先与以前的 RC 方法(Bianchi 等人,2020)进行公平比较,该方法将 $
\bar{d}{r}$ = 75 确定为读出之前的最佳维度。 在附录 C.1 中,我们进行了简短的探索,以确定该值是否也是 NVAR 嵌入的合理选择。 虽然我们没有在单变量数据集中观察到任何冗余,但我们确实观察到某些多变量数据集在使用不同的
d
ˉ
r
\bar{d}_{r}
dˉr后性能下降。 研究建议 70 ≲ $
\bar{d}_{r}$ ≲ 100 为合适的范围。
线性读出正则化(λridge) 对于读出,我们采用 Cancelliere 等人提出的最优正则化(OCReP)。 (2015),即将 λridge 设置为 R N V A R ∣ d r ˉ \mathbf{R}_{NVAR}\Big|\bar{d_{r}} RNVAR drˉ的最小和最大奇异值之间的乘积 。
RBF 长度尺度 ( γ r b f \gamma_{rbf} γrbf) 我们在方程式中设置长度尺度。 6 到训练集中所有表示 θ[i] 之间的中值成对距离。
3.4 Asymptotic complexity
NVARk 基于时间序列的个体表示。 因此,计算密集型步骤每个时间序列仅执行一次,导致复杂度为 O(N)。 这也意味着计算可以沿着 N 并行化。与基于比较的内核相比,这提供了显着的计算优势,基于比较的内核必须对所有相关的系列对执行昂贵的计算,即 O(N2)。
就系列长度 (T) 的可扩展性而言,NVAR 相对于任何递归 RC 方法的优势在于隐藏状态创建方式的关键区别。 等式。 5 不是迭代的,仅执行固定数量的连接操作 d ˉ r − d x \bar{d}_r-d_x dˉr−dx,与时间序列的长度无关。 相比之下,基于储层的方法受到储层状态(方程 2)昂贵的递归更新的限制,其为 O(Td2 r),其中 dr 是储层的大小(通常很大)。 作为证据,提高水库更新的可扩展性是一个活跃的研究领域(Dong 等人,2020)。 NVARk的复杂度仅限于输出层的唯一岭回归。 这对应于求解具有 T 个训练样本和 D 个特征的线性系统,其中 D 至多为 ¯dr。 这样的系统通常可以有效地解决,例如 通过使用 LU(或 Cholesky)渐近 O(T ́d2 r) 分解。
至于输入序列维数的可扩展性,所有操作都受 d ˉ r 2 \bar{d}_{r}^{2} dˉr2限制,我们将其视为常数,并且不讨论与该参数相关的复杂性。 总体而言,NVARk 表现出最多 O(NT d ˉ r 2 \bar{d}_{r}^{2} dˉr2) 的渐近复杂度。
四、 Experimental evaluation
在本节中,我们将通过实验演示 NVARk 的性能。 根据已有文献(Cuturi,2011;Cuturi & Doucet,2011;Baydogan & Runger,2016;Paparrizos 等,2020),我们的主要评估包括时间序列分类。 特别是,我们将不同的预先计算的内核矩阵与支持向量机(SVM)分类器(Steinwart & Christmann,2008)配对,这是一种介于简单线性模型和更先进的深度学习架构之间的流行内核分类方法。 该评估基于 UCR 档案中的 130 多个 UTS 数据集和 UEA 档案中的 19 个 MTS 数据集(Bagnall A. & E.)(附录 B.1)进行,重点关注准确性、执行时间和可扩展性。 在附录 C.5 中,我们提供了用于降维和可视化的核主成分分析 (kPCA) 的快照。
在两种不同的超参数设置下研究了所提出方法的性能。 我们用 NVARk 表示 k 和 s 由一般建议的经验法则确定的设置。 3.3. 最大维数设置为 d¯ r = 75。至于其他超参数,我们遵循第 2 节中给出的设置。 3.3. 相反,我们用 NVARk* 表示配置,其中 k 和 s 在小网格上的 CV 循环中进行优化。 由于数据集涵盖了广泛的系列长度,因此 CV 网格略有调整(附录 B.2)。
与之前提出的内核进行比较:储层模型回波状态网络(rmESN)(Bianchi 等人,2020)作为与我们的方法等效的储层。 我们将 D = 75 设置为线性读出之前的维数。 这使我们能够直接比较提取的动态特征的质量,无论是否有水库; 时间簇内核 (TCK)(Mikalsen 等人,2018)作为基于模型的内核和 MTS 的 SOTA 的代表; Shift-INvariant Kernel (SINK) (Paparrizos & Franklin, 2019) 作为基于傅里叶的方法和 UTS 的 SOTA 的代表。 附录 C.4 中介绍了与全局对齐内核 (GAK)(Cuturi,2011)的比较。 附录 B.2 中的指南包含超参数设置以及 NVARk 和所有上述基线的代码实现的链接。
尽管我们的基准测试中的一些数据集也可以使用深度学习(DL)方法进行研究(Ismail Fawaz 等人,2019),但内核方法的用例有很大不同,通常集中在小型数据集上,其中应用 深度学习并非无足轻重。 特别是,内核可以立即计算两个时间序列之间的相似度。 因此,在文献中,内核通常不会直接针对深度学习进行测试。 尽管如此,在我们的工作中,我们与基于 ESN 的表示进行了比较,众所周知,ESN 与各种深度学习架构具有竞争力(Bianchi 等人,2020;Shahi 等人,2022)。 因此,ESN 可以被视为更复杂架构的代理。
作为预处理,我们应用零填充将所有系列匹配到每个数据集中的最大长度(以允许与 TCK 进行比较),并遵循将所有系列标准化为零均值和单位方差的常见做法。 对于每个数据集-方法对,我们允许的最长执行时间为 20 小时。
4.1 SVM classification of UTS
我们在这里展示单变量数据集的 SVM 分类。 SVM 需要设置超平面正则化 C,我们在 CV 循环中根据 [10−3,103] 中的对数间隔值对其进行优化。 这是除 NVARk* 之外的所有方法中唯一的自由参数,其中它与 k 和 s 联合优化。 对于 CV 循环,我们采用 10 倍 CV,验证集的大小相当于训练集的 33%。 每个数据集的 SVM 准确度是通过使用不同种子进行 10 次重复的平均来获得的。 标签。 1 报告了所提出框架内所有内核的平均分类精度以及相对排名(附录 D 中报告了各个结果)。 全面的,
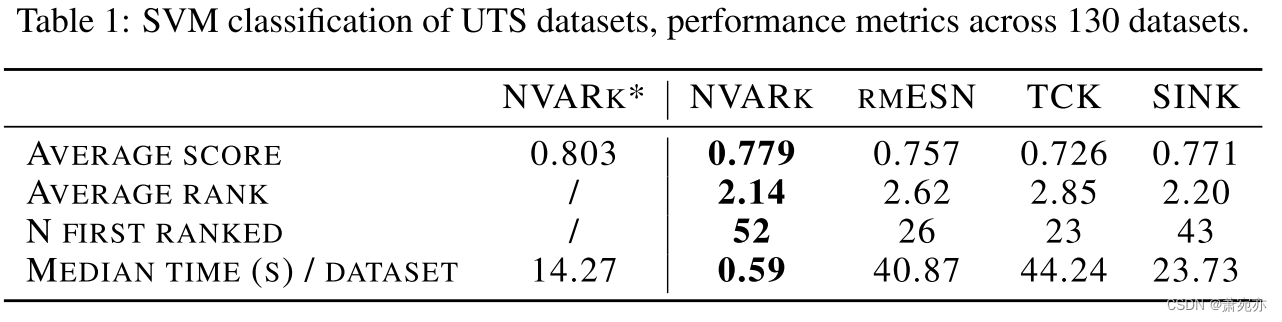
NVARk 获得了非常有竞争力的结果,具有最高的平均准确度和排名。 单变量数据集的情况对于 NVARk 来说是一个适合操作的场景,因为在大多数情况下,可以考虑 RNVAR 中所有可能的项而不超过 ́dr,并且共线性的影响最小化。 在 Friedman + Nemenyi 统计测试下,NVARk 和 SINK 似乎无法区分,这使得 NVARk 的准确度低于 SOTA。 有趣的是,NVARk 和 rmESN 之间的差异在 95% 水平上显着,p 值 NVARk−rmESN = 0.013。 NVARk* 的结果表明,仅通过两个整数嵌入超参数的 CV 优化就可以非常有效地提高 NVARk 的性能。
4.2 执行时间和可扩展性
就执行时间而言,NVARk(第 3.4 节)的可扩展性特性体现在卓越的性能上。 在图 2(左)和选项卡中。 如图 1(最后一行)所示,我们比较了计算训练训练和训练测试核矩阵的运行时间,并观察到 NVARk 的改进在数据集和基线上是一致的,在高 T 和高 T 中加速因子高达 ×103。 N 个政权。
相对于基于启发式的 NVARk,NVARk* 的结果可以通过 ∼ 25 的减速因子(并行网格搜索 + 1 次具有最佳参数的迭代)来实现。 有趣的是,对于 113/130 数据集,NVARk* 执行时间比 rmESN 的单次迭代更快。
为了研究缩放,在图 2(中、右)中,我们逐渐改变了 AbnormalHeartbeat 数据集的长度(通过插值)和 Crop 数据集中的训练样本数量(通过随机采样)。 结果表明,NVARk 在所有方案中都表现得非常好,而 rmESN 随序列长度的变化而变化,而 TCK 和 SINK 随训练样本大小的变化变化很差。 相反,NVARk 的优势在于其非递归结构和 N 中的线性复杂度。
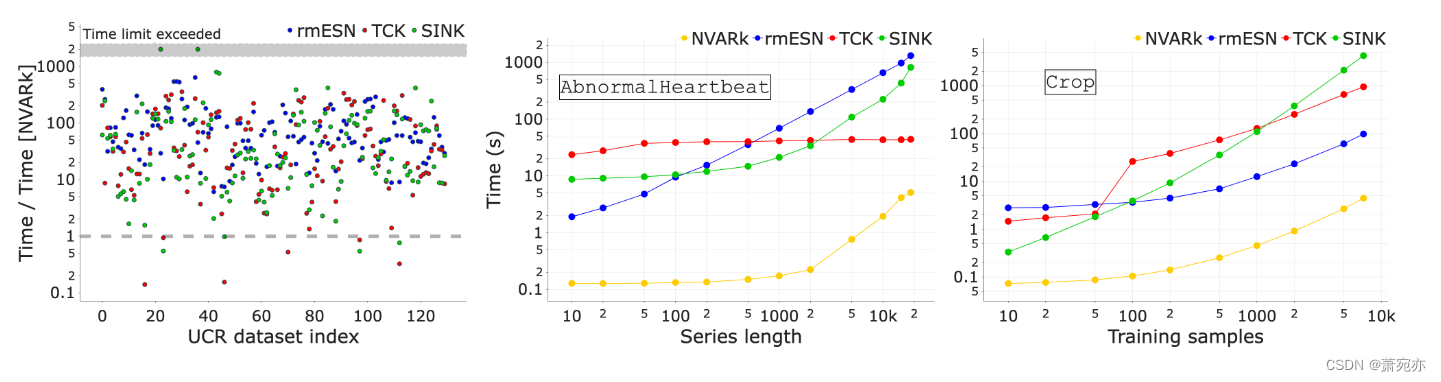
图 2:左图:对于所有单变量数据集,该图显示了计算不同方法和 NVARk 的训练-训练和训练-测试内核的执行时间之间的比率。 中:内核随系列长度的可扩展性。 右图:内核随训练大小的可扩展性。
4.3 SVM classification of MTS
我们在此介绍 19 个 MTS 数据集的 SVM 分类。 我们不包括 SINK,因为没有为 MTS 提供扩展或评估。 除此之外,评估的进行与单变量情况相同。 对于多元数据集,我们预计会偏离理想的操作NVARk 的场景。 特别是,所有可能的动态特征可能不会同样有效,并且通过随机选择一些,可能会错过重要的相关性或捕获虚假的相关性。 尽管如此,表中的实验。 图 2 显示了令人惊讶的良好结果,即使对于 d´ r 只是所有可能串联项的一小部分的数据集也是如此。 我们相信这一发现加强了与广义塔肯斯定理的联系。 值得注意的是,在不同的时间序列情况下都具有良好的性能,这些情况并不是立即由动态系统产生的。 探索这方面构成了有趣的未来工作,例如,时间序列表示学习和状态空间重建作为可能的基础。
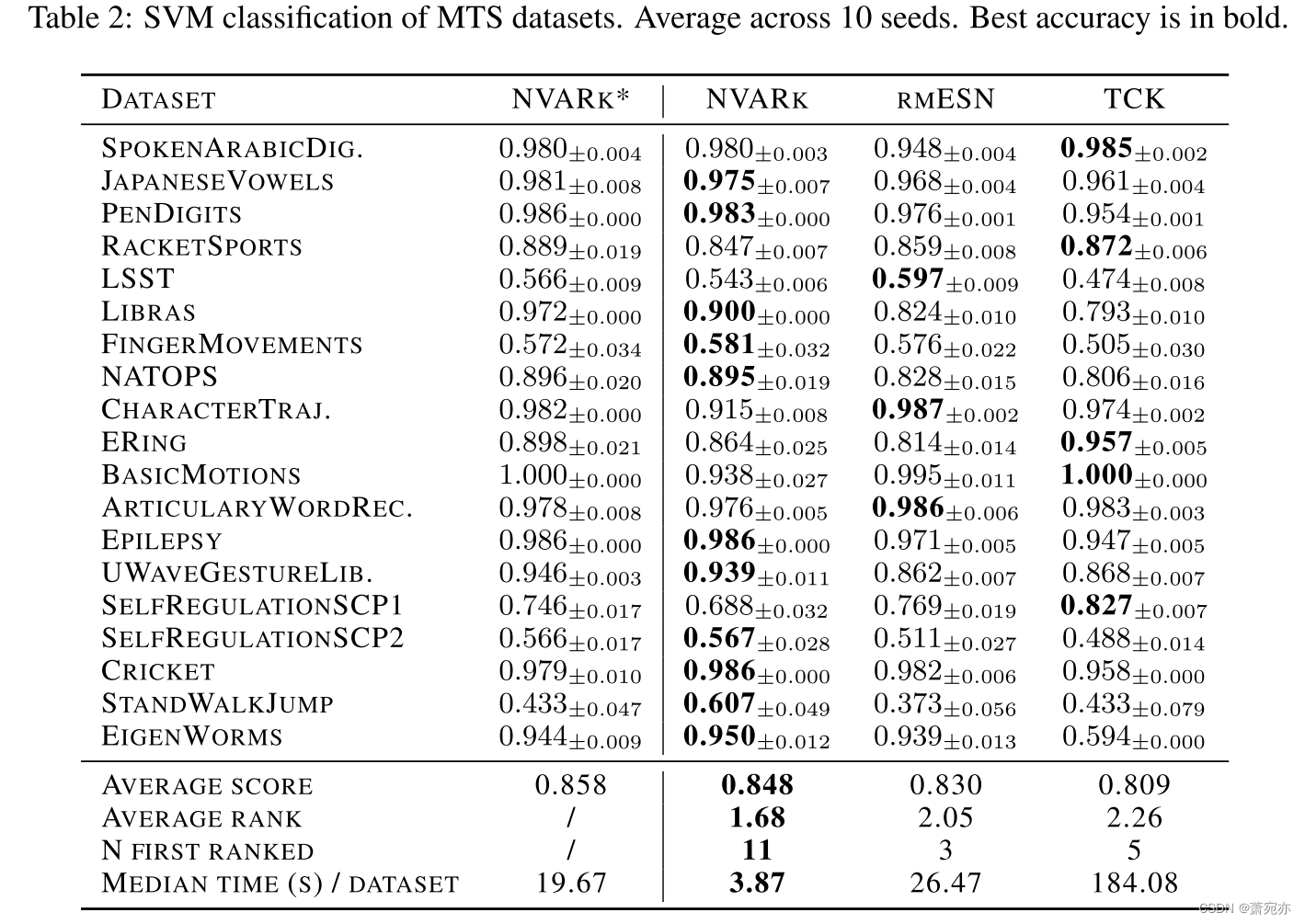
最后,我们观察到两个超参数配置 NVARk* 和 NVARk 往往排列在彼此旁边。 这支持了所提出的一般设置的质量,允许内核提取有意义的特征,同时保持较高的计算效率。
4.4 Ablation study
为了弄清楚哪个 NVARk 组件最重要,我们在这里提出了一项消融研究。 我们单独考虑将线性读数直接拟合在输入时间序列上(无串联),仅对方程中的线性项进行采样。 5、仅对非线性项进行采样。 据我们所知,这是一项有趣的消融研究,在之前的工作中尚未进行过研究。 结果显示在表中。 3.
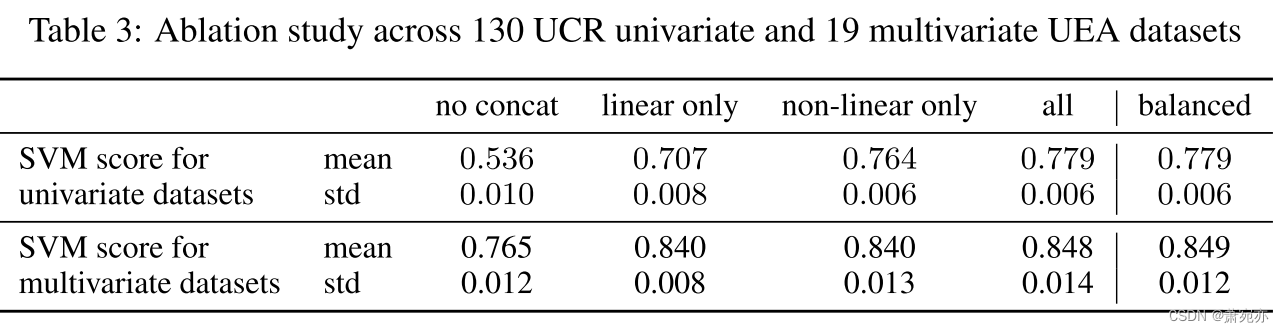
作为总体趋势,我们观察到使用所有项都会得到最佳结果,其次是仅非线性项、仅线性项以及直接拟合输入序列。 另请注意,结果与我们使用广义 Taken 定理的解释一致。 对于单变量数据集,线性往往表现不佳,因为连接维度的总数非常小(等于 k),并且可能不足以重建基础流形。 在多变量情况下,这两个变体的表现非常相似,因为所有属性的滞后可能已经构成了相当大的项池。 总之,我们考虑方程的另一个变体。 5,其中我们首先连接所有滞后项,然后通过采样非线性项来填充剩余维度,直到 ¯dr。 有趣的是,对于多变量数据集,这会带来稍微更好的性能并减少方差。 我们相信这最终可能会补偿所有可能的线性项和非线性项之间的不平衡,同时还减少从不相关维度添加噪声的机会。
五、 Conclusions
我们提出了一个时间序列内核,它将 NVAR 框架集成到基于水库的内核架构中。 NVARk 基于 NVAR 嵌入的线性动力学来比较时间序列,该嵌入是通过将滞后和非线性泛函连接到原始序列而构建的。 在精度方面,NVARk 优于相应的 RC 架构。 在计算上,它非常高效,并且基于一些整数超参数,这些超参数一起允许通过简单的基于监督的网格优化来进一步改进结果。 至于未来的工作方向,我们认为针对 NVARk 的具体弱点将是有效的。 特别是,当时间序列的输入维度接近最大嵌入维度( ́dr )时,所提出的方法发现连接更多滞后和非线性项的余量很小。 这种情况需要大幅增加 ́dr ,因此会对线性读数造成过度压力,而线性读数本质上具有有限的表达能力。 我们预计 NVARk 的有效性会降低。 为了克服这个问题,我们可以考虑用更精细的策略来取代维度的随机采样,这些策略优先选择有意义的术语。 或者,探索不同的线性层(例如)如何 套索,将在这种制度下执行。 除此之外,还可以考虑不同的无监督策略来学习嵌入参数的最佳值。 特别是,我们注意到与签名变换之间未经探索的亲和力(Chevyrev & Kormilitzin,2016),我们计划深化该亲和力以推断 NVAR 嵌入最大维度的最佳设置。

















 1934
1934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









