







2022 Neurips
1 intro
- 无监督与训练在NLP和CV领域的应用越来越多
- 他们大多基于合适的,在所有数据上都一致的先验假设
- 例如在NLP中,一个先验假设是不管是什么领域的文本,或者什么语种的文本,都遵循相同的语法规律
- 在时间序列中,之前并没有找到一个在不同数据集上都一致的先验假设
-
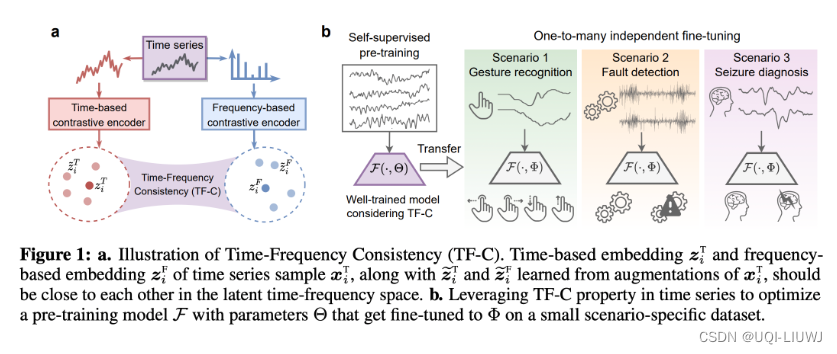
——>本文找到了一种不论在什么样的时间序列数据集中都存在的规律,那就是一个时间序列的频域表示和时域表示应该相似
-
——>提出了Time-Frequency Consistency (TF-C)的核心架构,以对比学习为基础,让时域和频域的序列表示尽可能接近
-
2 方法

- 利用多种时间序列数据增强手段,生成每个时间序列的不同增强版本
- 在时域上,使用的数据增强手段包括jittering、scaling、time-shifts、neighborhood segments等时间序列对比学习中的经典操作
- 在频域上,本文是首次研究了如何进行频域中的时间序列数据增强
- 通过随机抹除或增加frequency components实现频域上的数据增强
- 为了避免频域上的增强对原始序列过大的变化,导致增强后的序列和原始序列不相似,会对增删的components和增删幅度做限制
- 删除操作——会随机选择不超过E个频率进行删除
- 增加操作——会选择那些振幅小于一定阈值的频率,并提升其振幅
- 将时间序列输入到Time Encoder和Frequency Encoder,分别得到时间序列在时域和频域的表示
- 训练的损失函数由三部分组成:
- 时域对比学习loss
- 频域对比学习loss
- 时域和频域的表式对齐loss

- 前面两个loss只是分别在时域和频域内利用对比学习拉近表示,还没有引入时域和频域表示的对齐
- 为了实现时域和频域的一致性,本文设计了一种一致性loss拉近同一个样本在时域和频域的表示
- 借鉴了triplet loss的思想
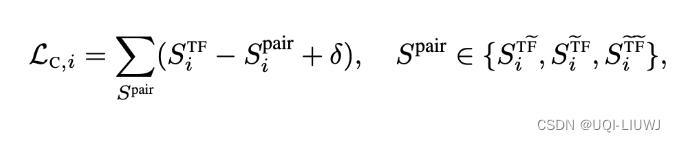
- 不带波浪线的T/F:原始时间序列时域表征&原始时间序列频域表征
- 带波浪线的T/F:增强时间序列时域表征&原始时间序列频域表征
- ——>这个loss的目的是:原始时间序列时域&频域表征的距离,小于时域&频域任何一个/两个增强之后表征的距离
- 时域对比学习loss
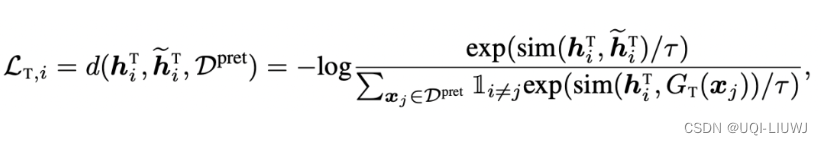
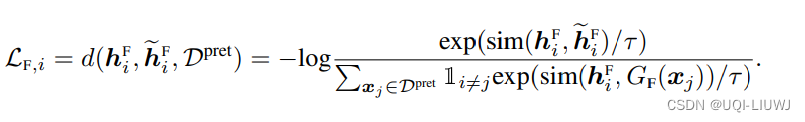
3 实验
3.1 one-to-one pretraining
- one-to-one——在一个数据集上使用不同的方法预训练,对比在另一个数据集上finetune后的效果

3.2 one-to-many pretraining
- One-to-many——在一个数据集上预训练,在多个数据集上finetune的效果

3.3 是否加入一致性
- 可视化了是否加入一致性loss对时域、频域表示学习的影响
- 不加一致性loss,时域和频域表示被学成两个簇,同一个样本两个表示距离比较远。
- 而引入一致性loss后,拉近了同一个样本时域和频域的表示

















 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











