





系列文章目录
重新思考多元时间序列预测的渠道依赖性:从领先指标中学习 ICLR2024
文章目录
摘要
最近,与通道无关的方法在多元时间序列(MTS)预测中取得了最先进的性能。 尽管降低了过度拟合的风险,但这些方法错过了利用通道依赖性进行准确预测的潜在机会。 我们认为变量之间存在局部固定的超前滞后关系,即一些滞后变量可能在短时间内跟随领先指标。 利用这种通道依赖性是有益的,因为领先指标提供了可用于降低滞后变量的预测难度的预先信息。 在本文中,我们提出了一种名为 LIFT 的新方法,该方法首先有效地估计领先指标及其在每个时间步的领先步骤,然后明智地允许滞后变量利用领先指标的先进信息。 LIFT 作为一个插件,可以与任意时间序列预测方法无缝协作。 对六个真实世界数据集的大量实验表明,LIFT 将最先进方法的平均预测性能提高了 5.4%。 我们的代码可在 https://github.com/SJTU-Quant/LIFT 获取。
一、引言
多元时间序列(MTS)预测是最热门的研究主题之一,是天气、交通和金融等各个领域的一项基本任务。 MTS 由多个通道(也称为变量 1)组成,其中每个通道都是单变量时间序列。 许多 MTS 预测研究认为每个渠道都依赖于其他渠道。 因此,许多方法采用通道依赖(CD)策略,并通过先进的神经架构(包括 GNN)联合建模多个变量(Wu 等人,2020;Cao 等人,2020;Huang 等人,2023;Yi 等人,2023)。 ,2023a)、MLP(Chen 等人,2023;Ekambaram 等人,2023;Wang 等人,2024a;Yi 等人,2023b)、CNN(Wu 等人,2023)、Transformers(Zhou 等人) ., 2021; Ni 等人, 2023; Wang 等人, 2024b; Liu 等人, 2023a) 等(Shen 等人, 2024; Jia 等人, 2023; Fan 等人, 2024) 。
出乎意料的是,CD 方法被最近提出的通道无关(CI)方法击败(Nie 等人,2023;Lee 等人,2024;Zhou 等人,2023;Jin 等人,2024;Cao 等人,2024)。 ,2024;Chen 等人,2024;Dai 等人,2024),甚至是一个简单的线性模型(Zeng 等人,2023;Li 等人,2023a;Xu 等人,2023)。 这些 CI 方法根据每个单变量时间序列自身的历史值单独预测,而不是参考其他变量。 虽然仅建模跨时间依赖性,但 CI Transformers(Nie 等人,2023;Zhou 等人,2023)令人惊讶地优于联合建模跨时间和跨变量依赖性的 CD Transformers(Grigsby 等人,2021;Zhang 和 严,2023)。 原因之一是现有的 CD 方法缺乏有关通道依赖性的先验知识,可能会遇到过拟合问题(Han et al., 2023)。 这就提出了一个有趣的问题:是否存在对 MTS 预测有效的显式通道依赖?
在这项工作中,我们将焦点转向变量之间的局部固定超前滞后关系。 许多 MTS 的一个有趣但被低估的特征是变量的演变可能落后于其他一些变量,称为领先指标。 领先指标可能会直接影响其他变量的波动,而这种影响需要一定的时间延迟才能传播和生效。 例如,血液中退烧药浓度的增加可能会在一小时后导致体温下降,但不会立即下降。 除此之外,另一个常见的情况是领先指标和滞后变量都取决于一些潜在因素,而领先指标最先受到影响。 例如,台风首先使沿海城市降温,几天后又使内陆城市降温。
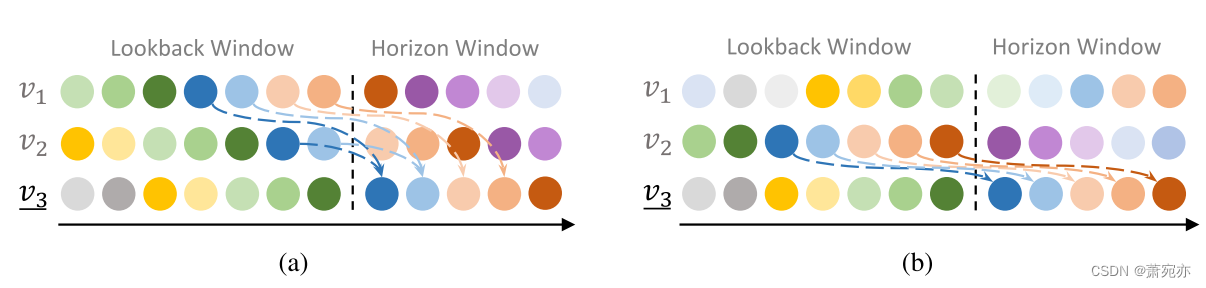
图 1:局部固定超前-滞后关系的图示。 (a) 在训练数据上,三个变量 v1、v2 和 v3 在回溯窗口和水平窗口上共享相似的时间模式(参见颜色),而 v1 和 v2 分别领先 v3 四步和两步。 然而,领先指标和领先步伐只能在短时间内保持不变。 (b) 在测试数据上,v1不再是领先指标,v2也将领先步数改为5。
由于这种效应通常在一定时期内变化很小,因此超前-滞后关系一旦建立就局部稳定。 如图 1a 所示,滞后变量及其领先指标在回溯窗口和水平窗口中具有相似的时间模式。 如果领先指标领先于目标变量 δ 步,则其回溯窗口的最新 δ 步将与滞后变量的未来 δ 步共享相似的时间模式。 特别地,当滞后变量完全跟随其领先指标时,通过预览超前信息,可以将滞后变量预测H步的难度降低为预测H-δ步。 尽管出现了超前-滞后关系,但领先指标和领先步骤的动态变化对渠道依赖性建模提出了挑战。 如图 1 所示,具体的领先指标和相应的领先步骤可能会随着时间的推移而变化。
鉴于此,我们提出了一种名为 LIFT(MTS 预测领先指标学习的缩写)的方法,涉及三个关键步骤。 首先,我们开发了一种高效的互相关计算算法来动态估计每个时间步的领先指标和领先步骤。 其次,如图 2 所示,我们通过目标导向的转变技巧来调整每个变量及其领先指标。 第三,我们使用骨干网络进行初步预测,并引入 Lead-aware Refiner 来校准粗略的预测。 值得注意的是,许多 MTS 是异构的,其中变量是对象的不同维度(例如,风速、湿度和天气中的气温)。 在这些情况下,滞后变量可以通过仅共享时间模式的一部分来与领先指标相关。 为了解决这个问题,我们利用频域中的所需信号,并通过自适应混频器实现领先感知精炼器,自适应混频器自适应地滤除领先指标中不需要的频率成分,并吸收剩余的所需频率成分。 本文的主要贡献总结如下。
• 我们提出了一种称为LIFT 的新方法,该方法利用变量之间的局部平稳超前-滞后关系进行MTS 预测。 LIFT 作为即插即用模块工作,可以无缝合并任意时间序列预测主干。
• 我们引入了一种有效的算法来估计领先指标以及任意时间步长相应的领先步骤。 我们进一步设计了一个领先感知精炼器,它自适应地利用频域中领先指标的信息信号来精炼滞后变量的预测。
• 对六个真实世界数据集的广泛实验结果表明,LIFT 显着改进了短期和长期 MTS 预测的最先进方法。 具体来说,LIFT 比 CI 模型平均提高了 7.9%,比 CD 模型平均提高了 3.0%。 我们还引入了一种轻量级但强大的方法 LightMTS,它具有高参数效率,并在流行的天气和电力数据集上实现了最佳性能。
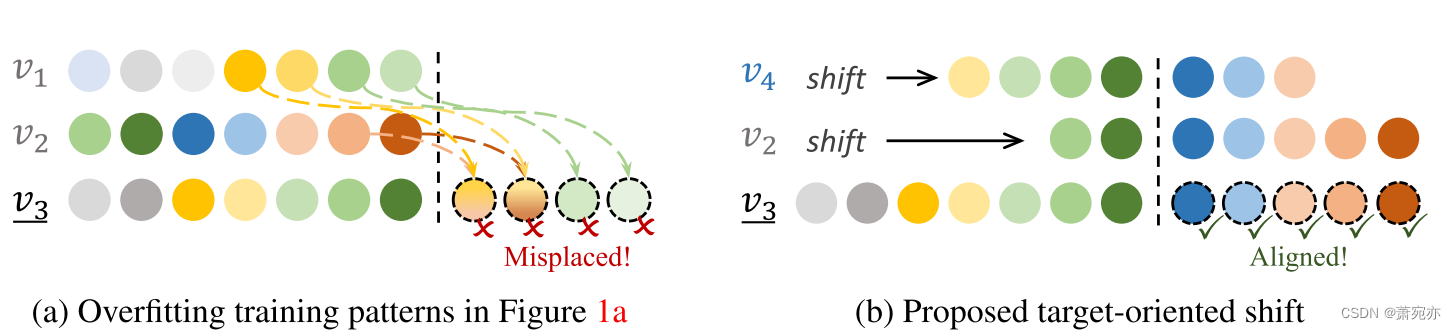
图 2:我们的关键想法的说明。 在一种测试数据中,v1 不再领先 v3。 相反,v3 的领先指标是 v2 和 v4,分别领先 5 步和 3 步。 一个直观的想法是,将 v2 和 v4 移动相应的前导步骤,以保持它们始终与 v3 对齐。
二、 PRELIMINARIES
多元时间序列 (MTS)2 表示为 X = { X ( 1 ) , ⋯ , X ( C ) } \mathcal{X}=\left\{\mathcal{X}^{(1)},\cdots,\mathcal{X}^{(C)}\right\} X={X(1),⋯,X(C)} ,其中 C 是变量(也称为通道)的数量, X ( j ) X^{(j)} X(j) 是 j 的时间序列 -th 变量。 给定一个L长度的回溯窗口 X t − L + 1 : t = { X t − L + 1 ( j ) , ⋯ , X t ( j ) } j = 1 C ∈ R C × L \mathcal{X}_{t-L+1:t}=\{\mathcal{X}_{t-L+1}^{(j)},\cdots,\mathcal{X}_{t}^{(j)}\}_{j=1}^{C}\in\mathbb{R}^{C\times L} Xt−L+1:t={Xt−L+1(j),⋯,Xt(j)}j=1C∈RC×L,此时的MTS预测任务 t 旨在预测水平窗口中 H 个连续的未来时间步,即 X t + 1 : t + H ∈ R C × H \mathcal{X}_{t+1:t+H}\in\mathbb{R}^{C\times H} Xt+1:t+H∈RC×H。
我们假设如果变量 i 在时间 t 领先变量 j δ 个步长,则 X t + 1 : t + H ( j ) \mathop{\mathcal{X}}_{t+1:t+H}^{(j)} Xt+1:t+H(j)类似于 X t + 1 − δ : t + H − δ ( i ) \mathcal{X}_{t+1-\delta:t+H-\delta}^{(i)} Xt+1−δ:t+H−δ(i)。 通过局部平稳超前-滞后关系的视角,我们可以使用最近的观察结果来估计领先指标和领先步骤。 具体来说,超前滞后关系可以通过 X t − L + 1 − δ : t − δ ( i ) and X t − L + 1 : t ( j ) \mathcal{X}_{t-L+1-\delta:t-\delta}^{(i)}\text{ and }\mathcal{X}_{t-L+1:t}^{(j)} Xt−L+1−δ:t−δ(i) and Xt−L+1:t(j)之间的互相关系数来量化,定义如下 。
定义 1(互相关系数)。 假设在 L 长度的回溯窗口中变量 i 比变量 j 领先 δ 步,则时间 t 时两个变量之间的互相关系数定义为:

其中 μ ( ⋅ ) ∈ R a n d σ ( ⋅ ) ∈ R \mu^{(\cdot)}\in\mathbb{R} and\sigma^{(\cdot)}\in\mathbb{R} μ(⋅)∈Randσ(⋅)∈R分别表示回溯窗口内单变量时间序列的均值和标准方差。
三、 THE LIFT APPROACH
在本节中,我们提出了 LIFT 方法,该方法动态识别领先指标并自适应地利用它们进行 MTS 预测。
3.1 OVERVIEW
图3描述了LIFT的概述,它涉及以下6个主要步骤。
(一)初步预测。 给定回溯窗口
X
t
−
L
+
1
:
t
\mathcal{X}_{t-L+1:t}
Xt−L+1:t,我们首先从黑盒主干获得粗略预测
X
^
t
+
1
:
t
+
H
\widehat{\mathcal{X}}_{t+1:t+H}
X
t+1:t+H,这可以通过任何现有的时间序列预测模型来实现。
(二)实例标准化。 给定
X
t
−
L
+
1
:
t
a
n
d
X
^
t
+
1
:
t
+
H
\mathcal{X}_{t-L+1:t}\mathrm{~and~}\widehat{\mathcal{X}}_{t+1:t+H}
Xt−L+1:t and X
t+1:t+H,我们应用实例归一化(Kim et al., 2022)而不使用仿射参数,以便统一变量的值范围。 具体来说,基于
X
t
−
L
+
1
:
t
X_{t-L+1:t}
Xt−L+1:t 中每个变量的均值和标准差,我们获得归一化回溯窗口
X
t
−
L
+
1
:
t
X_{t-L+1:t}
Xt−L+1:t和归一化预测
X
^
t
+
1
:
t
+
H
\widehat{X}_{t+1:t+H}
X
t+1:t+H。
(三) Lead estimation。 给定
X
t
−
L
+
1
:
t
\boldsymbol{X}_{t-L+1:t}
Xt−L+1:t,引导估计器计算成对变量的互相关系数。 对于每个变量 j,我们选择 K 个最可能的主导指标
I
t
(
j
)
∈
R
K
(
K
≪
C
)
\mathcal{I}_{t}^{(j)} \in \mathbb{R}^{K} (K\ll C)
It(j)∈RK(K≪C)以及相应的主导步骤
{
δ
i
,
t
(
j
)
∣
i
∈
I
t
(
j
)
}
\{\delta_{i,t}^{(j)} | i \in \mathcal{I}_{t}^{(j)}\}
{δi,t(j)∣i∈It(j)}和互相关系数
R
t
(
j
)
∈
R
K
\boldsymbol{R}_{t}^{(j)}\in\mathbb{R}^{K}
Rt(j)∈RK。

图 3:LIFT 概述。 灰色背景中的所有图层都是非参数的。 我们用实线描述回溯窗口的输入,用虚线描述水平窗口的预测。 作为说明,我们为每个目标变量选择两个最可能的先行指标,例如,橙色和黄色是时间 t 时红色的先行指标。
(四)目标导向转变。 在获得变量 j 的 I t ( j ) a n d { δ i , t ( j ) } i ∈ I t ( j ) \mathcal{I}_t^{(j)}\mathrm{~and~}\{\delta_{i,t}^{(j)}\}_{i\in\mathcal{I}_t^{(j)}} It(j) and {δi,t(j)}i∈It(j) 后,我们移动 X t − L + 1 : t ( i ) \boldsymbol{X}_{t-L+1:t}^{(i)} Xt−L+1:t(i)和 X ^ t + 1 : t + H ( i ) \widehat{\boldsymbol{X}}_{t+1:t+H}^{(i)} X t+1:t+H(i)通过 δ i , t ( j ) \delta_{i,t}^{(j)} δi,t(j)步骤,其中 i ∈ I t ( j ) i\in\mathcal{I}_t^{(j)} i∈It(j)。 由此,我们获得了一个面向 j 的 MTS 段 S t ( j ) ∈ R K × H \boldsymbol{S}_t^{(j)}\in\mathbb{R}^{K\times H} St(j)∈RK×H,其中 K 个领先指标与水平窗口中的变量 j 对齐。
(五) Lead-aware refnement。 Lead-aware Refiner 从 S t ( j ) S_t^{(j)} St(j)中提取信号,并将归一化初步预测 X ^ t + 1 : t + H ( j ) a s X ~ t + 1 : t + H ( j ) \widehat{\boldsymbol{X}}_{t+1:t+H}^{(j)}\mathrm{~as~}\widetilde{\boldsymbol{X}}_{t+1:t+H}^{(j)} X t+1:t+H(j) as X t+1:t+H(j)。
(六)实例反规范化。 最后,我们用原始均值和标准差对 X ~ t + 1 : t + H ( j ) \widetilde{\boldsymbol{X}}_{t+1:t+H}^{(j)} X t+1:t+H(j) 进行反规范化,得到最终预测 X ~ t + 1 : t + H ( j ) \widetilde{\mathcal{X}}_{t+1:t+H}^{(j)} X t+1:t+H(j)。
Training scheme 我们可以通过 X ~ t + 1 : t + H \widetilde{\boldsymbol{X}}_{t+1:t+H} X t+1:t+H 和地面实况 X t + 1 : t + H \mathcal{X}_{t+1:t+H} Xt+1:t+H之间的 MSE 联合训练主干和 Lead-aware Refiner。 或者,给定预训练和冻结的主干网,我们可以仅对训练数据预先计算一次初步预测,从而减少训练期间超参数调整的时间和 GPU 内存占用。
Technical challenges
值得注意的是,由于效率和噪声问题,利用超前滞后关系并非易事。 如方程。 (1) 需要 O(L),这是一种在 {1,···, L} 中搜索所有可能的 δ 的强力估计方法,需要 O(L2) 次计算。 此外,
S
t
(
j
)
S_t^{(j)}
St(j)可能包含一些来自领先变量的不相关模式,这些模式对滞后变量来说是噪音。
为了解决这些问题,我们通过复杂度为 O(L log L) 的高效算法来实现 Lead Estimator。 我们通过自适应频率混合器开发了 Lead-aware Refiner,该混合器自适应地生成频域滤波器并根据互相关和变量状态混合所需的频率分量。
3.2 LEAD ESTIMATOR
给定归一化回溯窗口 X t − L + 1 : t \boldsymbol{X}_{t-L+1:t} Xt−L+1:t,引导估计器首先根据 Wiener–Khinchin 定理(Wiener,1930)的扩展计算每对变量 i 和变量 j 之间的互相关系数(详细信息请参阅附录) A)。 形式上,我们通过以下等式一次性估计 {0, · · ·, L − 1} 中所有可能的前导步骤的系数:
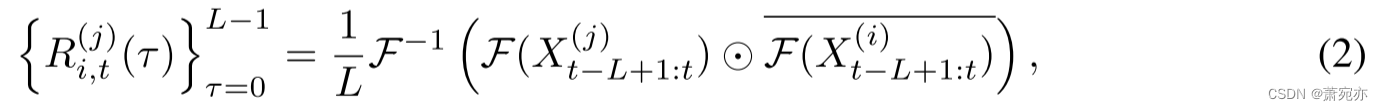
其中 F 是快速傅立叶变换,F−1 是其逆变换,⊙ 是逐元素乘积,条形表示共轭运算。 复杂度降低至 O(L log L)。
请注意,变量可以表现出正相关或负相关。 目标变量 j 与其先导指标 i 之间的前导步长
δ
i
,
t
(
j
)
\delta_{i,t}^{(j)}
δi,t(j)旨在达到最大绝对互相关系数,即
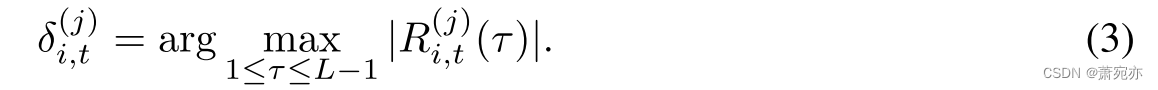
为简单起见,我们将最大绝对系数表示为
∣
R
i
,
t
(
j
)
(
δ
i
,
t
(
j
)
)
∣
为
∣
R
i
,
t
(
j
)
∗
∣
|R_{i,t}^{(j)}(\delta_{i,t}^{(j)})| \mathrm{为} |R_{i,t}^{(j)*}|
∣Ri,t(j)(δi,t(j))∣为∣Ri,t(j)∗∣。 然后,我们选择表现出最显着超前滞后关系的K个变量作为变量j的先行指标,其定义为:
 具体来说,将K个领先指标
I
t
(
j
)
\mathcal{I}_t^{(j)}
It(j)按照互相关性降序排序,即
I
t
(
j
)
\mathcal{I}_t^{(j)}
It(j)中的第k个指标具有第k最高的
∣
R
i
,
t
(
j
)
∗
∣
|R_{i,t}^{(j)*}|
∣Ri,t(j)∗∣ w.r.t. 变量 j. 此外,我们使用
R
t
(
j
)
∈
R
K
\boldsymbol{R}_t^{(j)}\in\mathbb{R}^K
Rt(j)∈RK 来表示
{
∣
R
i
,
t
(
j
)
∗
∣
}
i
∈
I
t
j
\left\{\left|R_{i,t}^{(j)*}\right|\right\}_{i\in\mathcal{I}_t^j}
{
Ri,t(j)∗
}i∈Itj的数组。
具体来说,将K个领先指标
I
t
(
j
)
\mathcal{I}_t^{(j)}
It(j)按照互相关性降序排序,即
I
t
(
j
)
\mathcal{I}_t^{(j)}
It(j)中的第k个指标具有第k最高的
∣
R
i
,
t
(
j
)
∗
∣
|R_{i,t}^{(j)*}|
∣Ri,t(j)∗∣ w.r.t. 变量 j. 此外,我们使用
R
t
(
j
)
∈
R
K
\boldsymbol{R}_t^{(j)}\in\mathbb{R}^K
Rt(j)∈RK 来表示
{
∣
R
i
,
t
(
j
)
∗
∣
}
i
∈
I
t
j
\left\{\left|R_{i,t}^{(j)*}\right|\right\}_{i\in\mathcal{I}_t^j}
{
Ri,t(j)∗
}i∈Itj的数组。
值得注意的是,我们的 Lead Estimator 是非参数的,我们只能在训练数据上预先计算一次估计,而不是在每个时期重复计算。
3.3 LEAD-AWARE REFINER
对于每个变量 j,Lead-aware Refiner 将通过其领先指标来细化 X ^ t + 1 : t + H ( j ) \widehat{\mathcal{X}}_{t+1:t+H}^{(j)} X t+1:t+H(j)。 我们将描述变量 j 的细化过程,其他 C − 1 变量并行细化。
面向目标的移位 对于每个领先指标
i
∈
I
t
(
j
)
i\in\mathcal{I}_t^{(j)}
i∈It(j),我们按领先步骤移动其序列,如下所示:

其中 ∥ 是串联。
对于与变量 j 负相关的领先指标 i,我们在每个时间步翻转其值以反映 R i , t ( j ) ∗ < 0 \begin{aligned}R_{i,t}^{(j)*}&<0\end{aligned} Ri,t(j)∗<0。形式上,对于每个 i ∈ I i ( j ) i\in\mathcal{I}_{i}^{(j)} i∈Ii(j),我们有:
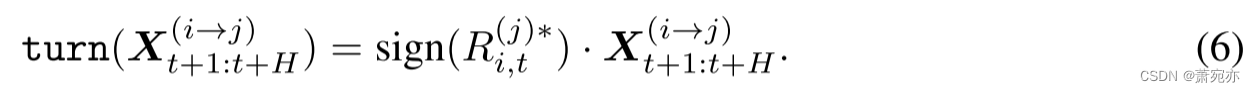
然后我们收集
{
t
u
r
n
(
X
t
+
1
:
t
+
H
(
i
→
j
)
)
∣
i
∈
I
t
(
j
)
}
\{\mathtt{turn}(\boldsymbol{X}_{t+1:t+H}^{(i\to j)})\mid i\in\mathcal{I}_t^{(j)}\}
{turn(Xt+1:t+H(i→j))∣i∈It(j)}作为面向目标的 MTS 片段
S
t
(
j
)
∈
R
K
×
H
\boldsymbol{S}_t^{(j)}\in\mathbb{R}^{K\times H}
St(j)∈RK×H。
状态估计 为了全面了解领先指标,值得注意的是超前-滞后模式也取决于变量状态。 不同的变量处于其特定的状态,具有一些内在的周期性(或趋势),例如,太阳照度在短期内受到降雨的影响,但保持其日常周期性。 变量的状态也可能随着时间的推移而变化,表现出与其他变量不同的相关强度,例如,两条相邻道路的交通速度之间的相关性在高峰时段很强,但在非高峰时段则弱得多。 因此,变量状态是信息信号,可以指导我们过滤掉不相关的模式。
假设总共有 N 个状态,我们通过以下方式估计变量 j 在时间 t 的状态概率:

其中
P
0
(
j
)
∈
R
N
P_0^{(j)}\in\mathbb{R}^N
P0(j)∈RN 表示变量 j 的内在状态分布,是一个可学习参数,
f
state
:
R
L
↦
R
N
f_\text{state }:\mathbb{R}^L \mapsto \mathbb{R}^N
fstate :RL↦RN 由线性层实现,并且
P
t
(
j
)
=
{
p
t
,
n
(
j
)
}
n
=
1
N
∈
R
N
P_t^{(j)} = \{p_{t,n}^{(j)}\}_{n=1}^N \in \mathbb{R}^N
Pt(j)={pt,n(j)}n=1N∈RN包括时间 t 时所有潜在状态的概率。 我们的自适应混频器将采用
P
t
(
j
)
P_t^{(j)}
Pt(j)来生成滤波器,以根据变量状态滤除噪声通道相关性。
自适应混频器为了从领先指标中提取有价值的信息,我们建议在频域中对跨变量依赖性进行建模。 给定变量 j 及其面向目标的 MTS 段 S t ( j ) S_t^{(j)} St(j) 的归一化预测,我们通过以下方式推导它们的傅里叶变换:

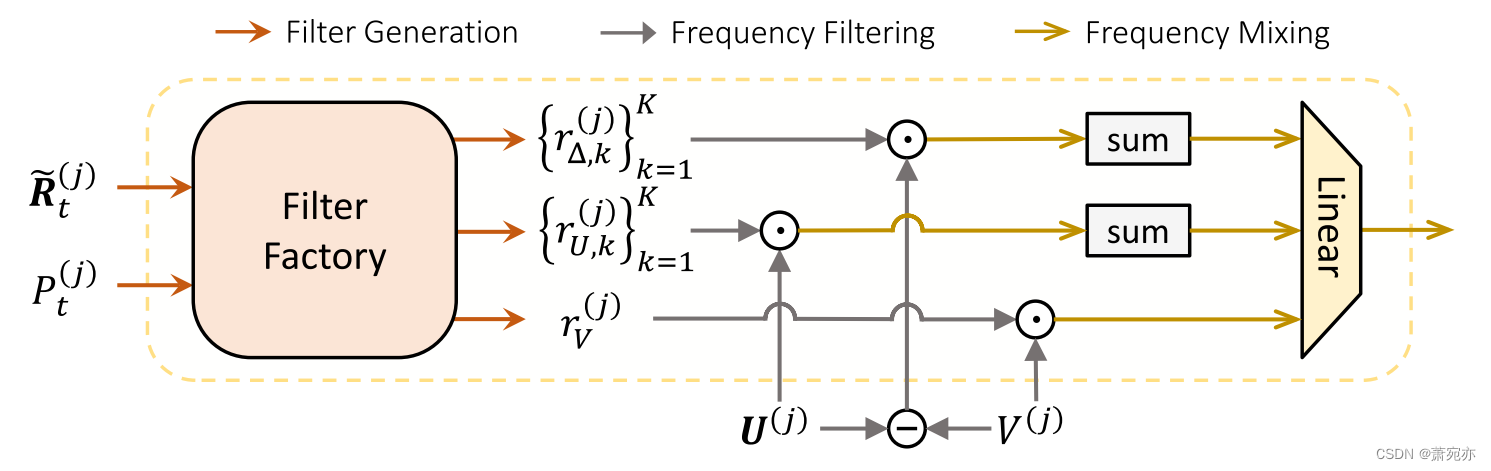
图 4:自适应混频器的架构。
其中 F 是快速傅里叶变换, V ( j ) ∈ C ⌊ H / 2 ⌋ + 1 , and U ( j ) ∈ C K × ( ⌊ H / 2 ⌋ + 1 ) V^{(j)}~\in~\mathbb{C}^{\lfloor H/2\rfloor+1},~\text{and}~\boldsymbol{U}^{(j)}~\in~\mathbb{C}^{K\times(\lfloor H/2\rfloor+1)} V(j) ∈ C⌊H/2⌋+1, and U(j) ∈ CK×(⌊H/2⌋+1)。 U ( j ) \boldsymbol{U}^{(j)} U(j)的每个元素表示为 U k ( j ) U_k^{(j)} Uk(j) ,是第 k 个先导指标的频率分量。 令 Δ k ( j ) = U k ( j ) − V ( j ) \begin{aligned}\Delta_k^{(j)}=U_k^{(j)}-V^{(j)}\end{aligned} Δk(j)=Uk(j)−V(j)表示变量 j 与第 k 个领先指标之间的差异。
直观上,当估计的相关性 R t ( j ) \boldsymbol{R}_t^{(j)} Rt(j) 很大时,初步预测值得从领先指标中进一步细化。 为了对 V ( j ) and U ( j ) V^{(j)}\text{ and }U^{(j)} V(j) and U(j)中的信号进行滤波,我们采用滤波器工厂来生成 2K + 1 个频域滤波器,定义如下:
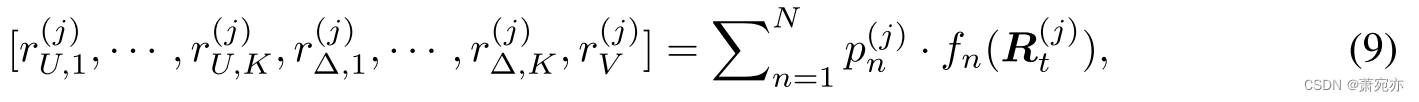
其中
f
n
:
R
K
↦
R
(
2
K
+
1
)
(
⌊
H
/
2
⌋
+
1
)
f_n:\mathbb{R}^K\mapsto\mathbb{R}^{(2K+1)(\lfloor H/2\rfloor+1)}
fn:RK↦R(2K+1)(⌊H/2⌋+1) 是一个线性层,其参数特定于第 n 个状态。 一方面,我们使用前 2K 个滤波器来建模两种超前滞后关系:(1)变量 j 直接受到第 k 个领导者的影响,并且真实值
V
t
r
u
e
(
j
)
V_{true}^{(j)}
Vtrue(j) 包含一定程度的
U
k
(
j
)
U_{k}^{(j)}
Uk(j),例如
V
t
r
u
e
(
j
)
≈
V
(
j
)
+
r
U
,
k
(
j
)
⊙
U
k
(
j
)
V_{true}^{(j)} \approx V^{(j)} + r_{U,k}^{(j)} \odot U_k^{(j)}
Vtrue(j)≈V(j)+rU,k(j)⊙Uk(j); (2) 当变量 j 与第 k 个领导者都受到潜在因素影响时,它们相似,并且真实值
V
t
r
u
e
(
j
)
V_{true}^{(j)}
Vtrue(j)是
V
(
j
)
a
n
d
U
k
(
j
)
V^{(j)}\mathrm{~and~}U_k^{(j)}
V(j) and Uk(j) 之间的插值,例如,
V
t
r
u
e
(
j
)
≈
(
1
−
r
Δ
,
k
(
j
)
)
⊙
V
(
j
)
+
r
Δ
,
k
(
j
)
⊙
U
=
V
(
j
)
+
r
Δ
,
k
(
j
)
⊙
Δ
k
(
j
)
V_{true}^{(j)} \approx (1 - r_{\Delta,k}^{(j)}) \odot V^{(j)}+r_{\Delta,k}^{(j)} \odot U = V^{(j)}+r_{\Delta,k}^{(j)} \odot \Delta_{k}^{(j)}
Vtrue(j)≈(1−rΔ,k(j))⊙V(j)+rΔ,k(j)⊙U=V(j)+rΔ,k(j)⊙Δk(j)。 另一方面,我们使用
r
V
(
j
)
∈
R
⌊
H
/
2
⌋
+
1
r_{V}^{(j)}\in\mathbb{R}^{\lfloor H/2\rfloor+1}
rV(j)∈R⌊H/2⌋+1 来消除
V
(
j
)
V^{(j)}
V(j) 的不可靠频率分量。 形式上,我们通过以下方式缩放频率分量:
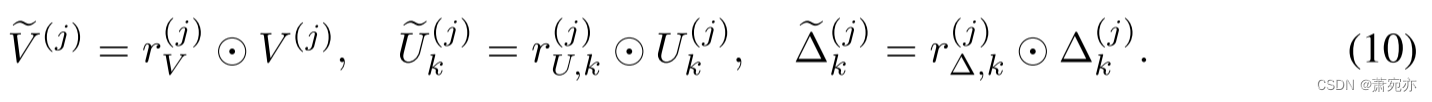
然后,我们从 K 个领先指标中收集信息,并通过以下方式混合频率分量:
 其中
g
:
C
3
(
⌊
H
/
2
⌋
+
1
)
↦
C
⌊
H
/
2
⌋
+
1
g:\mathbb C^{3(\lfloor H/2\rfloor+1)}\mapsto\mathbb C^{\lfloor H/2\rfloor+1}
g:C3(⌊H/2⌋+1)↦C⌊H/2⌋+1 是复值线性层。
其中
g
:
C
3
(
⌊
H
/
2
⌋
+
1
)
↦
C
⌊
H
/
2
⌋
+
1
g:\mathbb C^{3(\lfloor H/2\rfloor+1)}\mapsto\mathbb C^{\lfloor H/2\rfloor+1}
g:C3(⌊H/2⌋+1)↦C⌊H/2⌋+1 是复值线性层。
最后,我们应用快速傅里叶逆变换和反规范化来得出最终的精确预测,其公式为:

其中我们使用
X
t
−
L
+
1
:
t
(
j
)
\mathcal{X}_{t-L+1:t}^{(j)}
Xt−L+1:t(j) 的平均值和标准差进行非标准化。
3.4 DISCUSSION
推理 CD 型号性能较差的原因。 许多变量彼此不一致,而传统模型(例如,Informer(Zhou et al., 2021))只是在同一时间步长混合多变量信息。 因此,他们从滞后变量中引入了过时的信息,这些信息是噪音并干扰预测领导者。 尽管其他模型(例如,向量自回归(Giannone 等人,2010))通过静态权重记住不同时间步长的 CD,但由于领先指标和领先步数随时间变化,它们可能会遇到过度拟合问题。
LIFT 可以与任意时间序列预测主干合作。 当将 LIFT 与 CI 主干相结合时,我们将 MTS 预测分解为两个阶段,分别侧重于建模时间依赖性和通道依赖性。 该方案避免了在第一阶段引入噪声信道依赖性,并且与传统CD方法相比可以降低优化难度。 当将 LIFT 与 CD 主干相结合时,我们期望 LIFT 能够根据 S t ( j ) \boldsymbol{S}_{t}^{(j)} St(j)中领先指标的实际观察来细化粗略预测。
LIFT 通过动态选择和转移指标来缓解分布转移。 现有的基于归一化的方法(Kim 等人,2022;Fan 等人,2023;Liu 等人,2023b)处理回溯窗口和水平窗口中统计属性(例如均值和方差)的分布变化。 我们的工作与它们是正交的,因为我们对渠道依赖性的不同类型的分布变化进行了新颖的调查(参见附录 D.2 中的可视化)。
四、 LIGHTWEIGHT MTS FORECASTING WITH LIFT
由于 LIFT 的灵活性,我们引入了一种名为 LightMTS 的轻量级 MTS 预测方法,其中一个简单的线性层作为 CI 主干。 继李等人之后。 (2023a),我们在初步预测之前进行实例归一化,以减轻分布变化。
由于我们不学习高维潜在空间中的表示,LightMTS 比流行的 CD 模型更轻量级,包括 Transformer(Zhang & Yan,2023;Liu et al.,2023a)和 CNN(Wu et al.,2023)。 附录 D.1 提供了经验证据,其中 LightMTS 的参数效率与 DLinear Zeng 等人相似。 (2023)。
五、EXPERIMENTS
5.1 EXPERIMENTAL SETTINGS
数据集。 我们对六个广泛使用的 MTS 数据集进行了广泛的实验,包括天气(Zeng 等人,2023)、电力(Wu 等人,2020)、交通(Lai 等人,2018)、太阳能(Liu 等人,2020)。 2023a)、Wind(Liu 等人,2022)和 PeMSD8(Song 等人,2020)。 我们在附录 C.1 中提供了数据集详细信息,并在附录 D.3 中对更多数据集进行了实验。
比较方法。 由于 LIFT 可以合并任意时间序列预测主干,因此我们使用 (i) 两个最先进的 CI 模型验证 LIFT 的有效性:PatchTST(Nie 等人,2023)和 DLinear(Zeng 等人,2023) ; (ii) 最先进的 CD 模型:Crossformer(Zhang & Yan,2023); (iii) 经典 CD 模型:MTGNN(Wu et al., 2020)。 我们使用它们来实例化 LIFT 的主干,同时保留相同的模型超参数以进行公平比较。 我们还包括 PatchTST 的基线,例如 FEDformer (Zhou et al., 2022) 和 Autoformer (Wu et al., 2021)。
设置。 对于短期和长期预测,所有方法都遵循相同的实验设置,预测范围 H ∈ {24, 48, 96, 192, 336, 720}。 我们收集了 PatchTST 报告的一些基线结果,以与 LightMTS 进行性能比较,其中 PatchTST 调整了 FEDformer 和 Autoformer 的回溯长度 L。 对于其他方法,我们将L设置为336。我们使用均方误差(MSE)和平均绝对误差(MAE)作为评估指标。
5.2 PERFORMANCE EVALUATION
表 1 比较了四种最先进方法和 LIFT 在六个 MTS 数据集上的预测性能,表明 LIFT 在大多数情况下可以优于 SOTA 方法。 具体来说,LIFT 平均将相应的主干提升了 5.5%。
对 CI 主干的改进。 在六个数据集上,LIFT 比 PatchTST 和 DLinear 平均提高了 7.9%。 值得注意的是,PatchTST 和 DLinear 在天气、电力和交通数据集上大幅超过 Crossformer 和 MTGNN,这表明对通道依赖性建模的挑战。 有趣的是,LIFT 在这些具有挑战性的数据集上显着改善了 CI 主干,平均提高了 4.7%,在大多数情况下实现了最佳性能。 这证实了 LIFT 可以通过引入有关通道依赖的先验知识来降低过度拟合风险。
对 CD 主干的改进。 LIFT 在六个数据集上比 Crossformer 和 MTGNN 平均提高了 3.2%。 由于 CD 骨干网在 Solar、Wind 和 PeMSD8 上的表现优于 CI 骨干网,我们推测这些数据集在通道依赖性方面的分布变化较少,从而导致过拟合风险较小。 尽管 CD 主干网受益于渠道依赖性,LIFT 仍然可以改进他们的预测,例如,将 Solar 上的 Crossformer 提高 4.1%。 这表明,如果没有先行指标和领先步骤的动态变化的先验知识,现有的 CD 方法无法充分利用超前滞后关系。 此外,Crossformer 混合了来自同一时间步长的相似变量的信息,但对领先指标的不同但信息丰富的信号关注不够。 MTGNN 在训练数据的变量之间学习静态图结构,并在变量的固定子集中聚合信息。 MTGNN 很可能会受到渠道依赖的分布变化的影响,而 LIFT 会动态选择领先指标并降低过度拟合风险。
表 1:预测误差方面的性能比较。 我们用粗体突出显示每对主干和 LIFT 之间的更好结果,并用下划线突出显示每个数据集上所有方法中的最佳结果。 我们在最右列中展示了 LIFT 相对于相应骨干网的相对改进。

LightMTS 作为强大的基线。 此外,我们还比较了 LightMTS 与天气、电力和交通数据集的所有基线的性能。 我们借用 PatchTST 论文的基线结果,其中 H ∈ {96, 192, 336, 720}。 如图 5a 所示,以简单线性层为骨干的 LightMTS 在最先进的模型中仍然显示出相当可观的性能。 特别是,LightMTS 在天气方面超过了 PatchTST(复杂的 Transformer 模型)3.2%,在电力方面超过了 0.7%。 然而,PatchTST 在 Traffic 数据集上的性能明显优于 LightMTS。 由于流量包含数量最多且具有复杂时间模式的变量,因此需要强大的骨干来对复杂的跨时间依赖性进行建模。 尽管如此,LightMTS 仍然是 Traffic 上最具竞争力的基线。
5.3 ABLATION STUDY
为了验证我们设计的有效性,我们通过删除等式中的影响项
∑
k
=
1
K
U
~
k
(
j
)
\sum_{k=1}^{K}\widetilde{U}_{k}^{(j)}
∑k=1KU
k(j) 来引入 LightMTS 的三种变体。 (11) 去掉方程中的差分项
∑
k
=
1
K
Δ
~
k
(
j
)
\sum_{k=1}^{K}\widetilde{\Delta}_{k}^{(j)}
∑k=1KΔ
k(j)(11) 式中直接使用
V
(
j
)
,
∑
k
=
1
K
U
k
(
j
)
a
n
d
∑
k
=
1
K
Δ
k
(
j
)
V^{(j)},\sum_{k=1}^{K}U_{k}^{(j)}\mathrm{~and~}\sum_{k=1}^{K}\Delta_{k}^{(j)}
V(j),∑k=1KUk(j) and ∑k=1KΔk(j)。 (11) 分别。
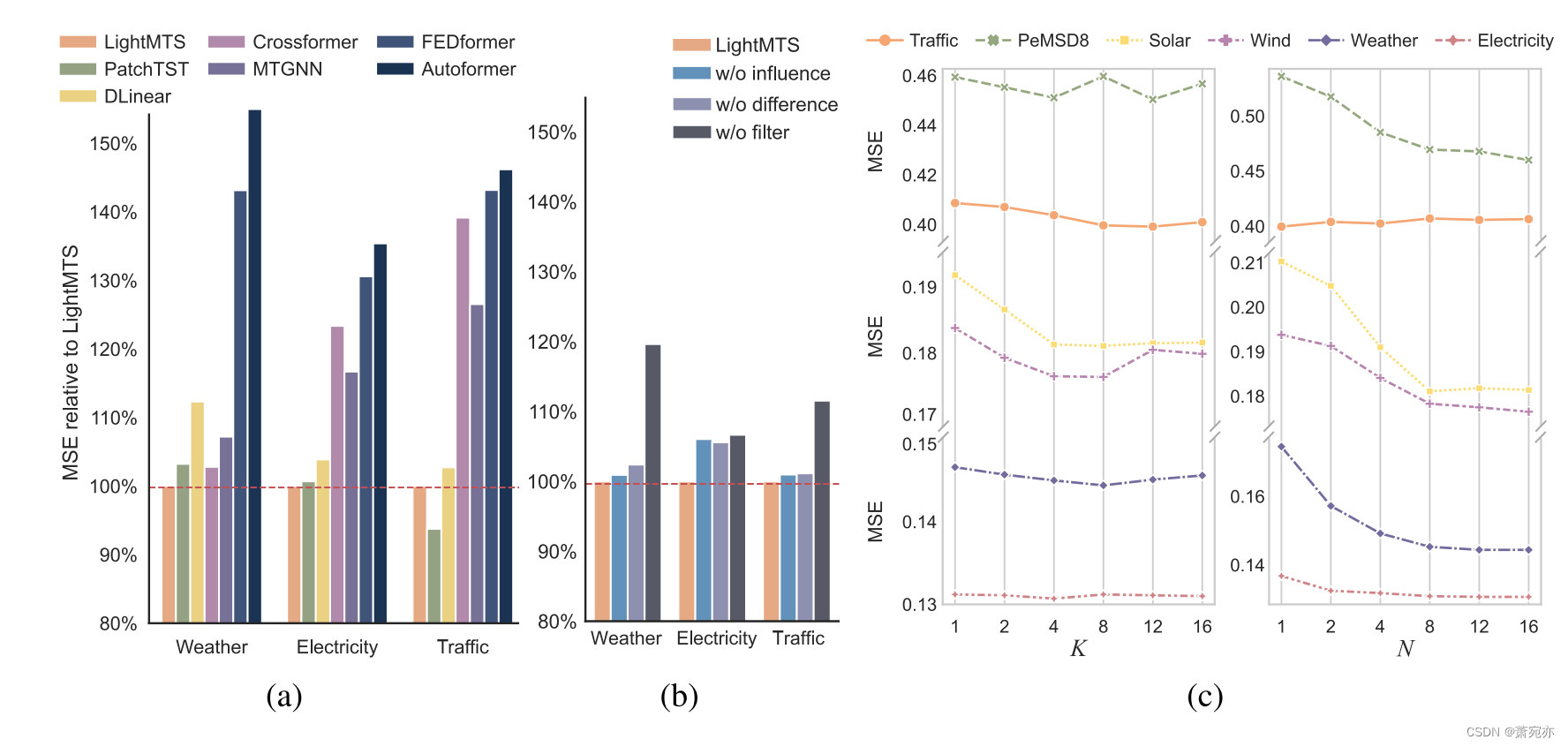
图 5:(a) LightMTS 与所有基线之间的性能比较; (b) LightMTS 变体之间的性能比较; © DLinear+LIFT 在不同数量的选定领先指标(即 K)和状态(即 N)下的表现。
如图 5b 所示,我们对这些变体进行实验,将 H 设置为 96,报告相对 MSE w.r.t。 LightMTS 关于天气、电力和交通数据集。 考虑到影响和差异,LightMTS 考虑了两种超前滞后关系,并在整个数据集上保持最佳性能。 相比之下,LightMTS w/ofluence和LightMTSw/odifference只考虑领先指标的片面信息,因此表现较差,尤其是在电力数据集上。 此外,没有滤波器的LightMTS在所有情况下都取得了最差的结果,无法自适应地滤除先行指标中的噪声。
5.4 HYPERPARAMETER STUDY
我们的方法仅引入了两个额外的超参数,即选定的领先指标的数量 K 和状态的数量 N。因此,超参数的选择需要少量的工作。
以DLinear为骨干,H设置为96,我们研究LIFT的超参数敏感性。 如图 5c 所示,LIFT 在大多数数据集上随着 K 的增加而实现了较低的 MSE。 然而,LIFT 很可能会包含更多具有太大 K 的噪声(例如,在 Wind 数据集上),从而导致性能下降。 此外,LIFT 在电力数据集上无法通过较大的 K 获得显着的改进,其中超前-滞后关系可能更加稀疏。 对于变量状态,在大多数情况下,随着 N 的增加,LIFT 实现了较低的 MSE。 当忽略变量状态时,我们观察到天气的性能下降最显着。 值得注意的是,天气变量(例如风速、湿度和气温)是由各种传感器记录的,超前-滞后模式自然会随着变量状态的变化而变化。
六、 CONCLUSION
在这项工作中,我们重新思考 MTS 中的通道依赖性,并强调变量之间的局部平稳超前滞后关系。 我们提出了一种称为 LIFT 的新颖方法,该方法可以有效地估计关系并动态地将领先指标纳入频域中以进行 MTS 预测。 LIFT可以作为即插即用模块工作,通常适用于任意预测模型。 我们进一步引入 LightMTS 作为 MTS 预测的轻量级但强大的基线,它保持与线性模型相似的参数效率并显示出相当可观的性能。 我们预计超前-滞后关系可以为 MTS 中的通道依赖性提供一种新颖的跨时间视角,这对于通道依赖性 Transformer 或其他复杂神经网络的未来发展来说是一个有希望的方向。















 2980
2980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









