









神经网络入门
本篇笔记选取了3blue1brown的神经网络入门学习系列进行简单的记录。具体的推导过程视频中讲解得很清楚,就不作具体的推导笔记说明了,只对关键点做批注。另在每一part上均标注了官方的链接。
文章目录
一、Part1:神经网络的结构
链接:【官方双语】深度学习之神经网络的结构 Part 1 ver 2.0
了解神经网络的结构需要解决这几个问题:
-
为什么神经网络是层状结构?为什么分层可靠?
-
上一层网络是如何影响下一层的?
-
中间层做什么?
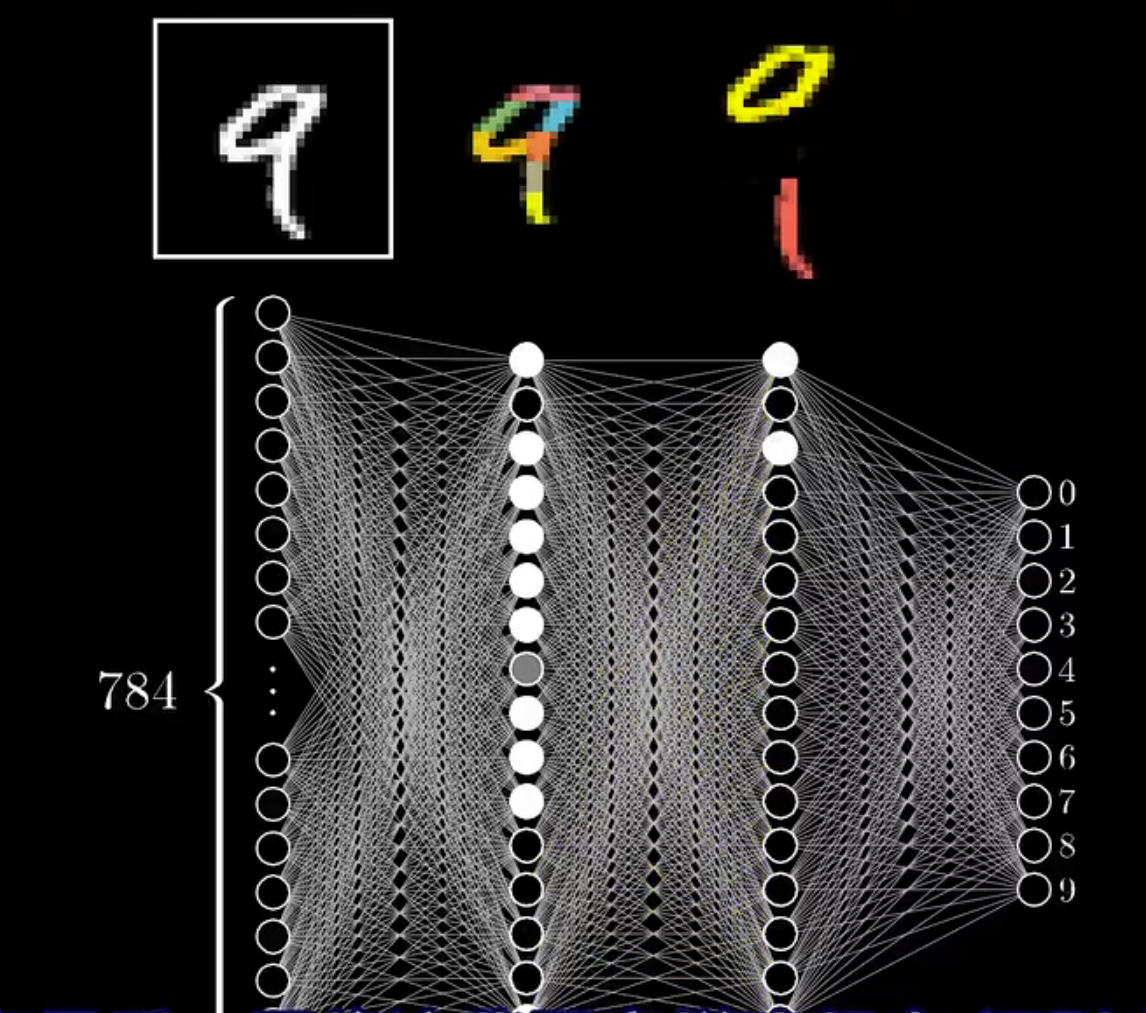
这里利用神经网络的倒数第2层和最后一层,使用了将数字图形分割成若干较大部分,各个大部分组成完整数字的而例子。前面的层以此类推,做分割……这个例子实际是给与了神经网络的可解释性,至于是不是真的是这样的?分析神经网络。
总结:从某个角度理解神经网络——计算机如何设置这些巨大数量的参数?设置这个参数的过程即是训练神经网络的过程。
二、Part2:梯度下降法
链接:【官方双语】深度学习之梯度下降法 Part 2 ver 0.9
两个目标:
- 神经网络的基础:梯度下降的思想
- 分析神经网络
神经网络的基础:梯度下降
key points:
-
神经网络的训练过程
-
代价函数的概念Cost Function
- Input:大量的权重(weights)和偏置值(biases)
- Output:1 number(the cost)
- Parameters:训练数据
-
梯度下降的思想:如何改变这些参数,使神经网络的变得优秀、有效(代价函数值最小)

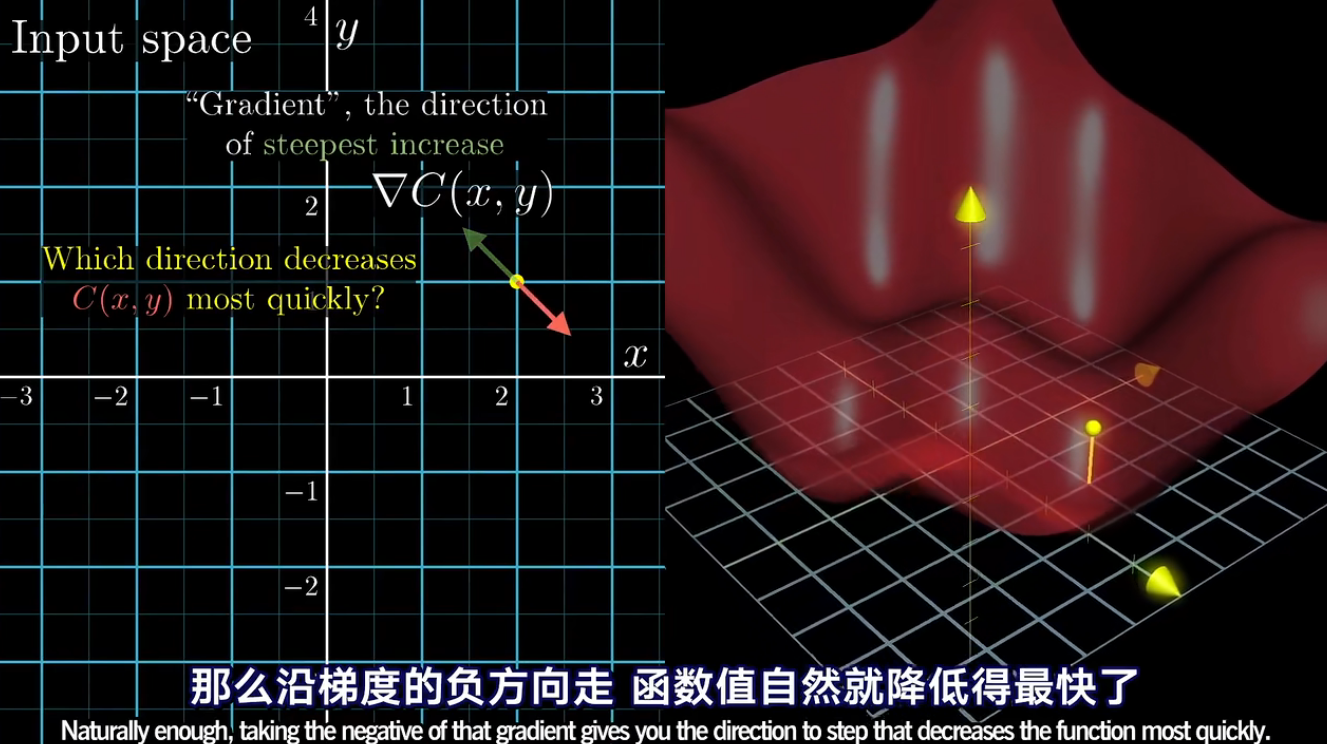
计算梯度的算法是网络的核心:反向传播算法BP(back propgation)
-
参数的另一种理解形式:参数对于cost的重要性,或者说是“性价比”
分析神经网络
神经网络真的是这么做的吗?
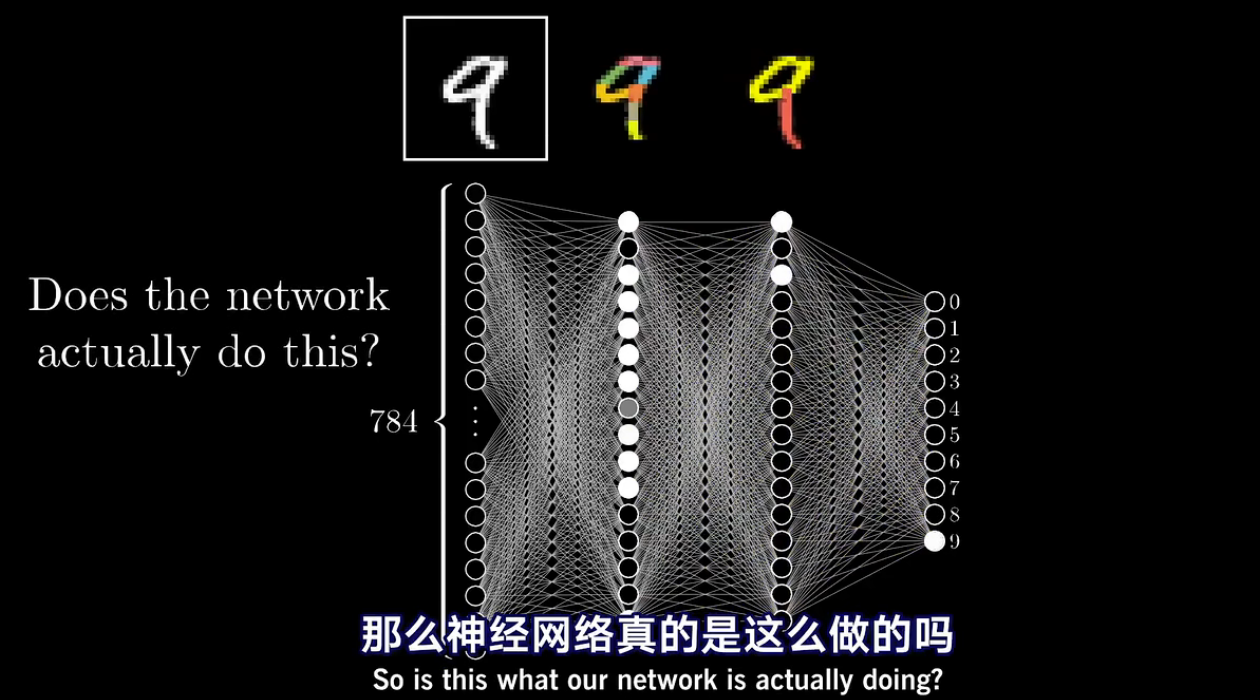
完全不是:旧的理解帮助我们理解神经网络的新的变种
三、Part3:反向传播算法
链接:【官方双语】深度学习之反向传播算法 上/下 Part 3 ver 0.9 beta
反向传播的直观感受
改变最后损失函数值的三种方式:
- 改变偏置值b
- 提升权重值 w i w_i wi
- 改变 a i a_i ai
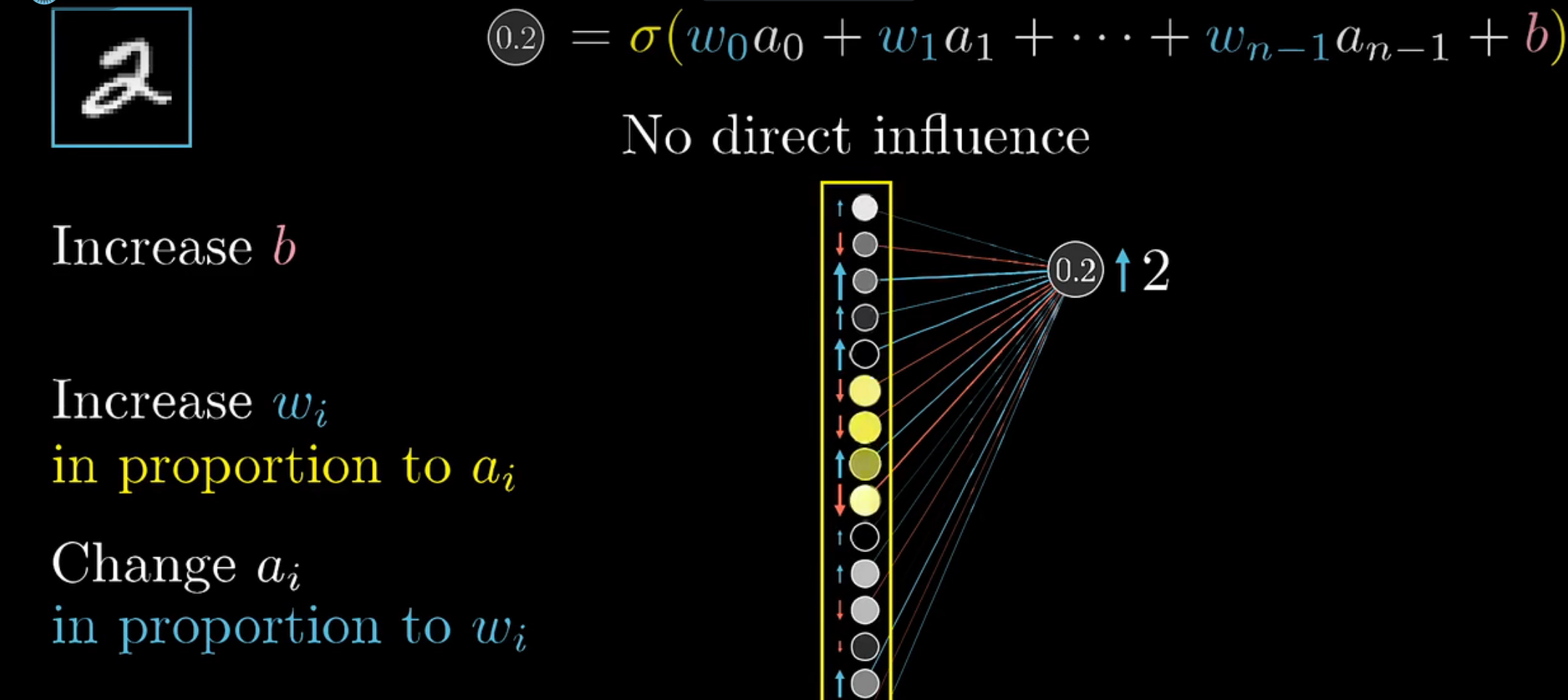
在这一部分,并不从梯度下降的角度去理解参数的调整,而是从调整参数的“性价比”理解参数的反向传播算法。
反向传播的核心:
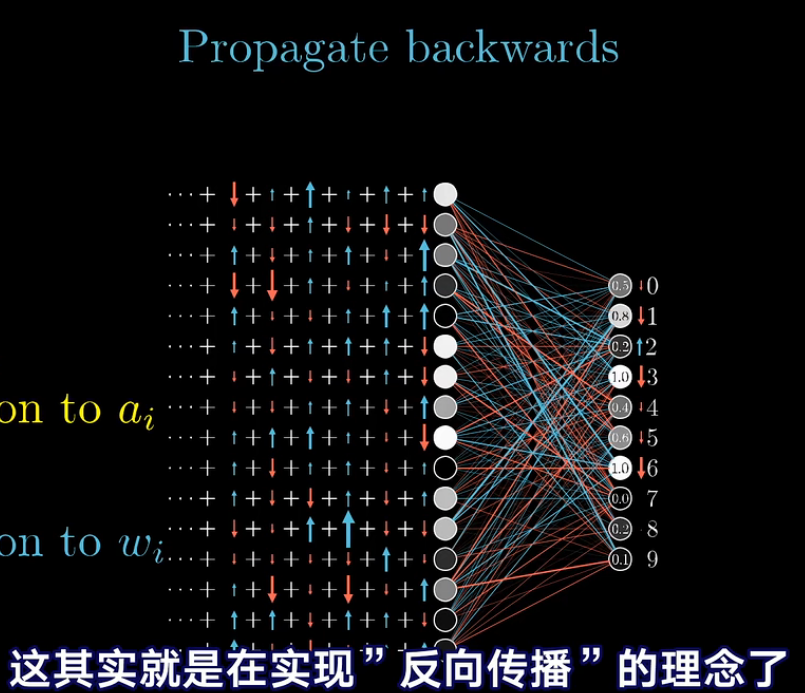
赫布理论:一同激活的神经元关联在一起。
反向传播的微积分原理
最简单的例子
首先聚焦最简单的例子:一个有4层,4个神经元组成的3层网络:
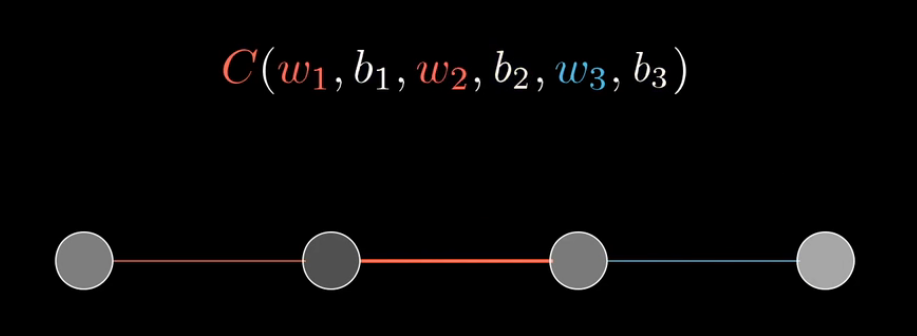
目标:理解代价函数对于这些变量的变化有多敏感,如何调整这些变量才能使得代价下降得最快。
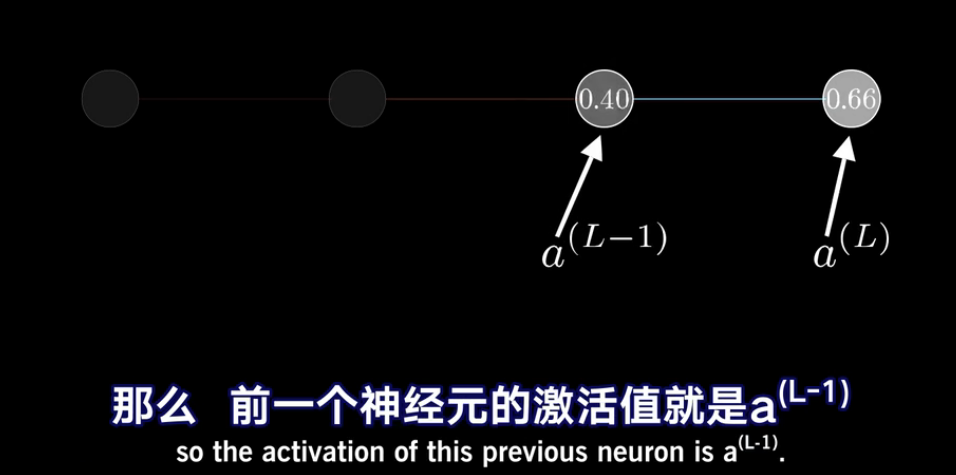
同时使用另一个神经元 y y y表示最终要接近的目标值, y y y要么是1要么是0.
那么代价的表示为:
C
0
(
.
.
.
)
=
(
a
(
L
)
−
y
)
2
另外,额外定义:
z
(
L
)
=
w
(
L
)
a
(
L
−
1
)
+
b
(
L
)
a
(
L
)
=
σ
(
z
(
L
)
)
C_0(...)=(a^{(L)}-y)^2\\ 另外,额外定义:z^{(L)}=w^{(L)}a^{(L-1)}+b^{(L)}\\ a^{(L)}=\sigma(z^{(L)})
C0(...)=(a(L)−y)2另外,额外定义:z(L)=w(L)a(L−1)+b(L)a(L)=σ(z(L))
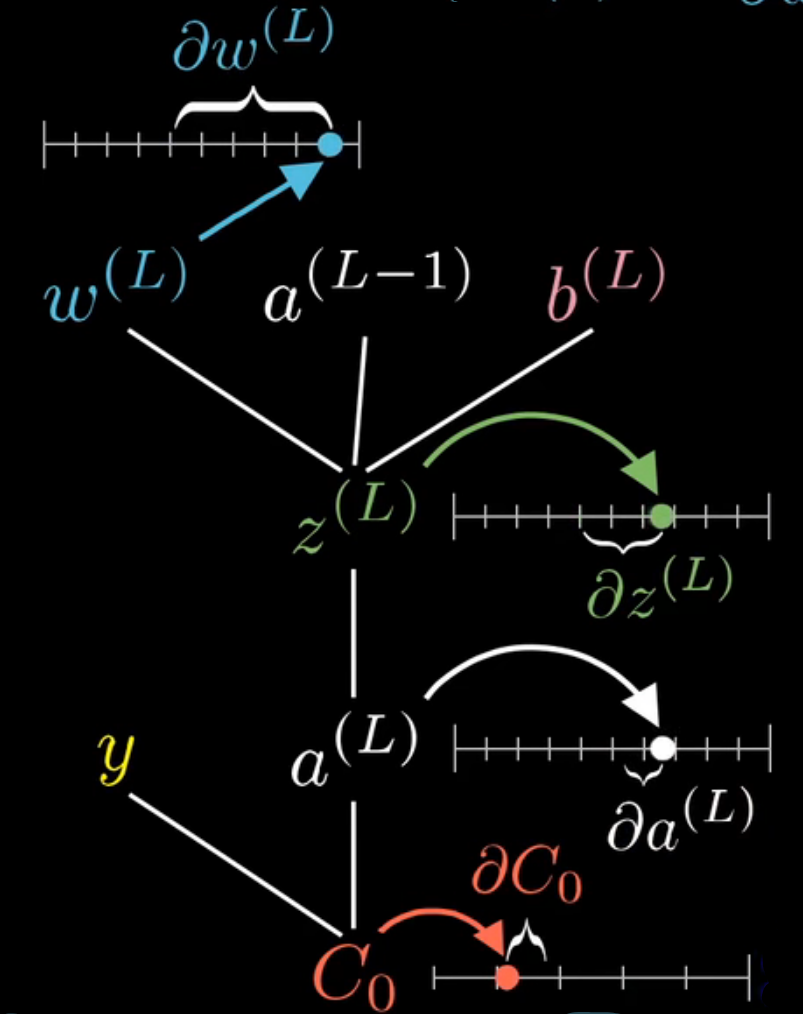
需要探讨
w
w
w的变化对代价的值的影响,即:
∂
C
0
∂
w
(
L
)
=
∂
z
(
L
)
∂
w
(
L
)
⋅
∂
a
(
L
)
∂
z
(
L
)
⋅
∂
C
0
∂
a
(
L
)
\frac{\partial{C_0}}{\partial{w^{(L)}}}=\frac{\partial{z^{(L)}}}{\partial{w^{(L)}}}\cdot \frac{\partial{a^{(L)}}}{\partial{z^{(L)}}}\cdot \frac{\partial{C_0}}{\partial{a^{(L)}}}
∂w(L)∂C0=∂w(L)∂z(L)⋅∂z(L)∂a(L)⋅∂a(L)∂C0
链式法则如上。把三个相乘,即得到C对
w
(
L
)
w^{(L)}
w(L)的变化有多敏感。
∂
C
0
∂
a
(
L
)
=
2
(
a
(
L
)
−
y
)
(1)
\frac{\partial{C_0}}{\partial{a^{(L)}}}=2(a^{(L)}-y)\tag{1}
∂a(L)∂C0=2(a(L)−y)(1)
意味着导数的大小和网络与最终目标的差成正比。其他的偏导结果如下:
∂
C
0
∂
a
(
L
)
=
2
(
a
(
L
)
−
y
)
∂
a
(
L
)
∂
z
(
L
)
=
σ
′
(
z
(
L
)
)
∂
z
(
L
)
∂
w
(
L
)
=
a
(
L
−
1
)
\begin{aligned} &\frac{\partial C_0}{\partial a^{(L)}}=2\left(a^{(L)}-y\right) \\ &\frac{\partial a^{(L)}}{\partial z^{(L)}}=\sigma^{\prime}\left(z^{(L)}\right) \\ &\frac{\partial z^{(L)}}{\partial w^{(L)}}=a^{(L-1)} \end{aligned}
∂a(L)∂C0=2(a(L)−y)∂z(L)∂a(L)=σ′(z(L))∂w(L)∂z(L)=a(L−1)
改变
w
w
w对代价影响的大小取决于前一层激活值的大小,“一同激活的神经元关联在一起”的出处即来源于此。不过这只是只包含一个训练样本的代价对
w
(
L
)
w^{(L)}
w(L)的导数,总的代价应该是所有的样本所有代价的总和:
∂
C
0
∂
a
(
L
)
=
1
n
∑
k
=
0
n
−
1
∂
C
k
∂
w
(
L
)
\frac{\partial C_0}{\partial a^{(L)}}=\frac{1}{n}\sum_{k=0}^{n-1}\frac{\partial{C_k}}{\partial w^{(L)}}
∂a(L)∂C0=n1k=0∑n−1∂w(L)∂Ck
但是这只是梯度向量
∇
C
\nabla C
∇C的一个分量,完整的梯度向量由代价函数对每一个权重和每一个偏置求偏导构成。
∇
C
=
[
∂
C
∂
w
(
1
)
∂
C
∂
b
(
1
)
⋮
∂
C
∂
w
(
L
)
∂
C
∂
b
(
L
)
]
\nabla C=\left[\begin{array}{c} \frac{\partial C}{\partial w^{(1)}} \\ \frac{\partial C}{\partial b^{(1)}} \\ \vdots \\ \frac{\partial C}{\partial w^{(L)}} \\ \frac{\partial C}{\partial b^{(L)}} \end{array}\right]
∇C=⎣
⎡∂w(1)∂C∂b(1)∂C⋮∂w(L)∂C∂b(L)∂C⎦
⎤
但是完成这么多偏导中的一个的计算就完成了大半的工作:
∂
C
0
∂
w
(
L
)
=
∂
z
(
L
)
∂
w
(
L
)
⋅
∂
a
(
L
)
∂
z
(
L
)
⋅
∂
C
0
∂
a
(
L
)
=
a
(
L
−
1
)
σ
′
(
z
(
L
)
)
2
(
a
(
L
)
−
y
)
\frac{\partial{C_0}}{\partial{w^{(L)}}}=\frac{\partial{z^{(L)}}}{\partial{w^{(L)}}}\cdot \frac{\partial{a^{(L)}}}{\partial{z^{(L)}}}\cdot \frac{\partial{C_0}}{\partial{a^{(L)}}}=a^{(L-1)}\sigma'(z^{(L)})2(a^{(L)}-y)
∂w(L)∂C0=∂w(L)∂z(L)⋅∂z(L)∂a(L)⋅∂a(L)∂C0=a(L−1)σ′(z(L))2(a(L)−y)
对偏置的求导过程也基本相同,只需要对(1)中的一项进行替换:
∂
C
0
∂
b
(
L
)
=
∂
z
(
L
)
∂
b
(
L
)
⋅
∂
a
(
L
)
∂
z
(
L
)
⋅
∂
C
0
∂
a
(
L
)
=
1
⋅
σ
′
(
z
(
L
)
)
2
(
a
(
L
)
−
y
)
=
σ
′
(
z
(
L
)
)
2
(
a
(
L
)
−
y
)
\frac{\partial{C_0}}{\partial{b^{(L)}}}=\frac{\partial{z^{(L)}}}{\partial{b^{(L)}}}\cdot \frac{\partial{a^{(L)}}}{\partial{z^{(L)}}}\cdot \frac{\partial{C_0}}{\partial{a^{(L)}}}=1\cdot\sigma'(z^{(L)})2(a^{(L)}-y)=\sigma'(z^{(L)})2(a^{(L)}-y)
∂b(L)∂C0=∂b(L)∂z(L)⋅∂z(L)∂a(L)⋅∂a(L)∂C0=1⋅σ′(z(L))2(a(L)−y)=σ′(z(L))2(a(L)−y)

同样,这里可以看出改变上一层的激活值对代价的敏感程度:
∂
C
0
∂
a
(
L
−
1
)
=
∂
z
(
L
)
∂
a
(
L
−
1
)
∂
a
(
L
)
∂
z
(
L
)
∂
C
0
∂
a
(
L
)
=
w
(
L
)
σ
′
(
z
(
L
)
)
2
(
a
(
L
)
−
y
)
\frac{\partial C_0}{\partial a^{(L-1)}}=\frac{\partial z^{(L)}}{\partial a^{(L-1)}} \frac{\partial a^{(L)}}{\partial z^{(L)}} \frac{\partial C 0}{\partial a^{(L)}}=w^{(L)} \sigma^{\prime}\left(z^{(L)}\right) 2\left(a^{(L)}-y\right)
∂a(L−1)∂C0=∂a(L−1)∂z(L)∂z(L)∂a(L)∂a(L)∂C0=w(L)σ′(z(L))2(a(L)−y)
虽然我们不能直接改变激活值,但是我们可以反向应用链式法则,来计算代价函数对之前的权重和偏置的敏感程度:
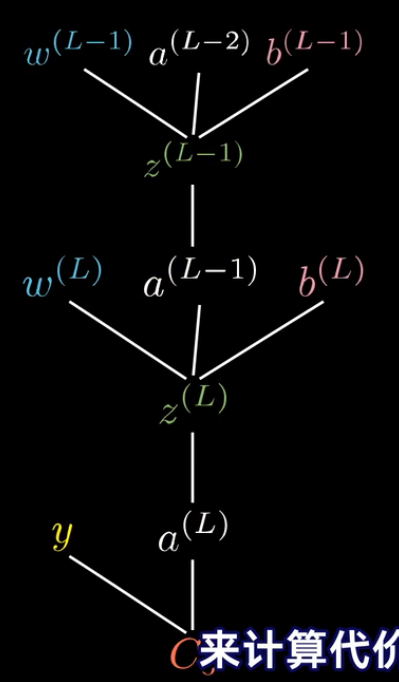
多个神经元的神经网络
对于下图所示的神经网络,我们有:
Z
j
=
w
j
0
(
L
)
a
0
(
L
−
1
)
+
w
j
1
(
L
)
a
1
(
L
−
1
)
+
w
j
2
(
L
)
a
2
(
L
−
1
)
+
b
j
(
L
)
Z_j=w_{j0}^{(L)}a_0^{(L-1)}+w_{j1}^{(L)}a_1^{(L-1)}+w_{j2}^{(L)}a_2^{(L-1)}+b_j^{(L)}
Zj=wj0(L)a0(L−1)+wj1(L)a1(L−1)+wj2(L)a2(L−1)+bj(L)
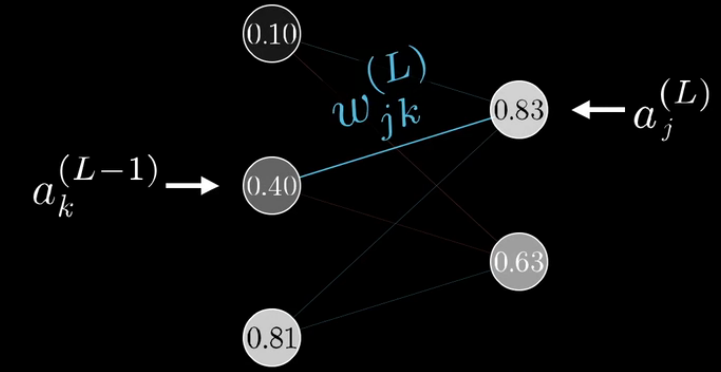
有了上面的三个神经元的例子,假设第
L
−
1
L-1
L−1层有
n
L
−
1
n_{L-1}
nL−1个神经元,第
L
L
L层有
n
L
n_L
nL个神经元,对于
L
L
L层的第
j
j
j个神经元,有:
Z
j
(
L
)
=
∑
k
=
0
n
L
−
1
w
j
k
(
L
)
a
k
(
L
−
1
)
Z_j^{(L)}=\sum_{k=0}^{n_{L-1}}w_{jk}^{(L)}a_k^{(L-1)}
Zj(L)=k=0∑nL−1wjk(L)ak(L−1)
进而,我们定义激活值
a
j
(
L
)
a_j^{(L)}
aj(L),以及损失函数值:
a
j
(
L
)
=
σ
(
z
j
(
L
)
)
C
0
=
∑
j
=
0
n
L
−
1
(
a
j
(
L
)
−
y
i
)
2
a_j^{(L)}=\sigma(z_j^{(L)})\\ C_0=\sum_{j=0}^{n_L-1}(a_j^{(L)}-y_i)^2
aj(L)=σ(zj(L))C0=j=0∑nL−1(aj(L)−yi)2
此时,
w
w
w变化对代价值变化的影响:
∂
C
0
∂
w
j
k
(
L
)
=
∂
z
j
(
L
)
∂
w
j
k
(
L
)
∂
a
j
(
L
)
∂
z
j
(
L
)
∂
C
0
∂
a
j
(
L
)
\frac{\partial C_0}{\partial w_{j k}^{(L)}}= \frac{\partial z_j^{(L)}}{\partial w_{j k}^{(L)}} \frac{\partial a_j^{(L)}}{\partial z_j^{(L)}} \frac{\partial C_0}{\partial a_j^{(L)}}
∂wjk(L)∂C0=∂wjk(L)∂zj(L)∂zj(L)∂aj(L)∂aj(L)∂C0
但是要注意,唯一改变的是代价对激活值的导数:
∂
C
0
∂
a
k
(
L
−
1
)
=
∑
j
=
0
n
L
−
1
∂
z
j
(
L
)
∂
a
k
(
L
−
1
)
∂
a
j
(
L
)
∂
z
j
(
L
)
∂
C
0
∂
a
j
(
L
)
\frac{\partial C_0}{\partial a_{k}^{(L-1)}}= \sum_{j=0}^{n_L-1}\frac{\partial z_j^{(L)}}{\partial a_{k}^{(L-1)}} \frac{\partial a_j^{(L)}}{\partial z_j^{(L)}} \frac{\partial C_0}{\partial a_j^{(L)}}
∂ak(L−1)∂C0=j=0∑nL−1∂ak(L−1)∂zj(L)∂zj(L)∂aj(L)∂aj(L)∂C0
因为
a
k
(
L
−
1
)
a_k^{(L-1)}
ak(L−1)影响最终损失值的可能道路是
n
L
n_L
nL条,是
n
L
n_L
nL条道路偏导的和,如下:
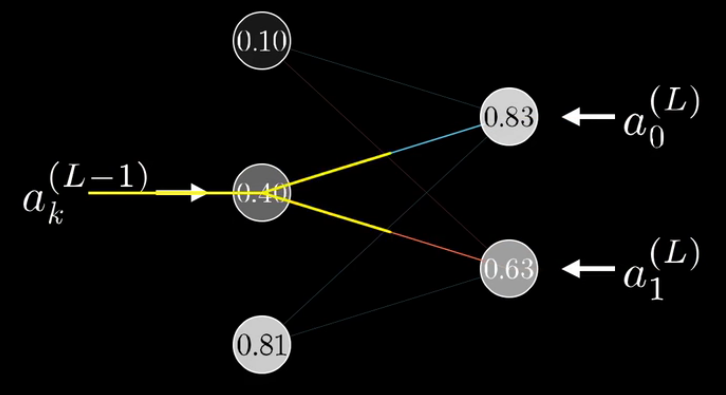
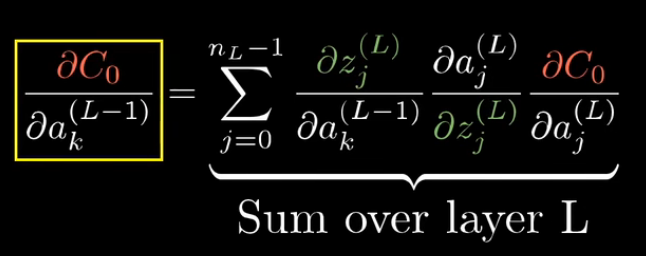
只要计算出倒数第二层的代价函数对激活值的敏感程度,接下来只要重复上述过程,接着计算倒数第二层的权重和偏置即可:
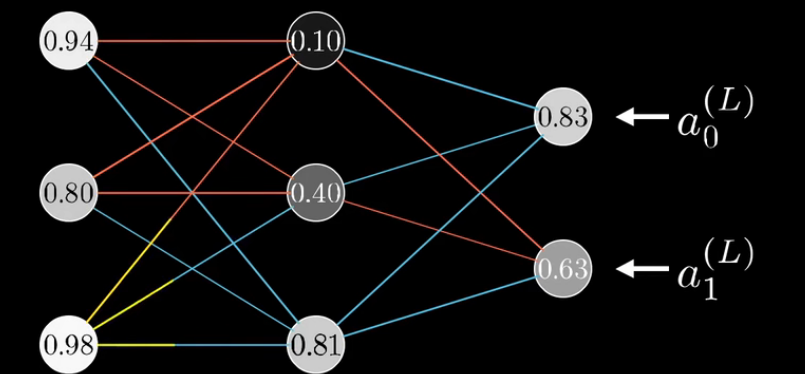
这样一层一层向前传递,最终能够计算出完整的梯度向量:
∇
C
=
[
∂
C
∂
w
(
1
)
∂
C
∂
b
(
1
)
⋮
∂
C
∂
w
(
L
)
∂
C
∂
b
(
L
)
]
\nabla C=\left[\begin{array}{c} \frac{\partial C}{\partial w^{(1)}} \\ \frac{\partial C}{\partial b^{(1)}} \\ \vdots \\ \frac{\partial C}{\partial w^{(L)}} \\ \frac{\partial C}{\partial b^{(L)}} \end{array}\right]
∇C=⎣
⎡∂w(1)∂C∂b(1)∂C⋮∂w(L)∂C∂b(L)∂C⎦
⎤
然后进行梯度下降,一步一步找到最优解的值。
梯度下降与反向传播
二者关系
神经网络按照层逐渐深入,对于神经网络计算梯度时,需要使用反向传播的方式进行计算,而反向传播的计算核心其实就是链式法则的使用。
反向传播算法是神经网络中最有效的算法,其主要的思想是将网络最后输出的结果计算其误差,并且将误差反向逐级传下去。反向传播运用的是链式求导的基本思想(隐函数求导)。
反向传播的思想
对于每一个训练实例,将它传入神经网络,计算它的输出;然后测量网络的输出误差(即期望输出和实际输出之间的差异),并计算出上一个隐藏层中各神经元为该输出结果贡献了多少的误差;反复一直从后一层计算到前一层,直到算法到达初始的输入层为止。
此反向传递过程有效地测量网络中所有连接权重的误差梯度,最后通过在每一个隐藏层中应用梯度下降算法来优化该层的参数(反向传播算法的名称也因此而来)。
引文及原博客链接:
for each training instance the backpropagation algorithm first makes a prediction (forward pass), measures the error, then goes through each layer in reverse to measure the error contribution from each connection (reverse pass), and finally slightly tweaks the connection weights to reduce the error (Gradient Descent step).
















 866
866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











