







 本文提出了一种关键帧为中心的时空令牌丢弃方法,通过在视频动作检测中保留关键帧和动作相关的令牌,降低ViTs的计算需求,提高实时性能。EVAD在保持识别精度的同时,降低了GFLOPs并提升在高分辨率输入下的性能。未来研究方向包括自适应令牌修剪和一体化动作识别模块。
本文提出了一种关键帧为中心的时空令牌丢弃方法,通过在视频动作检测中保留关键帧和动作相关的令牌,降低ViTs的计算需求,提高实时性能。EVAD在保持识别精度的同时,降低了GFLOPs并提升在高分辨率输入下的性能。未来研究方向包括自适应令牌修剪和一体化动作识别模块。
文章目录
动机
Streaming video clips with large-scale video tokens impede vision transformers (ViTs) for efficient recognition, especially in video action detection where sufficient spatiotemporal representations are required for precise actor identification.
对于高效的识别任务,尤其是在视频动作检测中,具有大规模视频标记 large-scale video tokens 的流媒体视频剪辑会妨碍 vision transformers (ViTs)的使用。在视频动作检测中,需要足够的时空表示来准确识别演员。 (因为,视频序列中的时序动作信息应该被保留为了准确地识别每个演员,并且保持场景上下文以区分其他演员。)
简单来说,large-scale video tokens 会导致 vision transformer 在视频动作检测中效率低下,并且需要更多的时空表示来准确识别演员。
针对动机的做法
- 从关键帧的角度提出了一种时空令牌丢弃的方法。
- 在一个视频片段中,我们保留关键帧的所有tokens。
- 保留与演员运动相关的其他帧中的tokens,并丢弃该片段中其余的tokens。
- 我们通过利用剩余的tokens来更好地识别参与者身份来改进场景上下文。
- 我们的动作检测器中的感兴趣区域 (RoI) 被扩展为时域。
- 在具有注意力机制的解码器中,通过场景上下文对捕获的时空行为者身份表征进行细化
摘要和结论
主要讲述了动机和作者针对动机的做法。又说了一下作者工作的指标:
与普通 ViT 主干相比,我们的 EVAD 将整体 GFLOPs 降低了 43%,并且没有性能下降的情况下将实时推理速度提高了 40%。此外,即使在类似的计算成本下,我们的 EVAD 也可以在更高分辨率的输入下将性能提高 1.1 mAP。
在结论中说:
- 我们希望 EVAD 能够作为未来研究的有效端到端基线。
- 我们的方法的一个局限性是,EVAD 需要重新训练一次,才能获得减少计算量和通过消除冗余进行更快推理的好处。一种潜在的研究方法是探索transformer 自适应令牌修剪算法 (transformer-adaptive token pruning algorithms)。
- 此外,我们遵循 WOO 的端到端框架来验证 EVAD 的效率和有效性,但 WOO 仍然是一个“两阶段”管道,它依次进行演员定位和动作分类模块。在未来的工作中,我们的目标是将这两个模块集成到一个统一的头部中,这可以减少通过探测器头的推理时间,从而放大 EVAD 的效率优势。
引言
在视频动作检测中,需要足够的时空表示来准确识别演员。
For each actor, the temporal motion in video sequences shall be maintained for consistent identification. Meanwhile, the scene context ought to be kept to differentiate from other actors.
因为,视频序列中的时序动作信息应该被保留为了准确地识别每个演员,并且保持场景上下文以区分其他演员。
In this paper, we preserve video tokens representing actor motions and scene context, while dropping out irrelevant tokens.在本文中,我们保留代表演员动作和场景上下文的视频标记,同时丢弃不相关的标记。
基于视频片段的时间相干性,我们从以关键帧为中心的角度提出了一种时空标记丢失。
For each video clip, we can select one keyframe representing the scene context where all the tokens shall be maintained. Meanwhile, we select tokens from other frames representing actor motions. Moreover, we drop out the remaining video tokens in this clip.
scene context:指的是图像中的物体和它们相对位置的信息。
actor motions:识别演员的动作。(AVA在eval时的60个类)
我们默认选择带有框注释的输入剪辑的中间帧作为关键帧,关键帧用于定位。此外,我们提取了该关键帧增强的注意力图。这个注意力图指导非关键帧中的标记丢失。
定位后要进行动作识别。由于视频tokens在非关键帧中不完整,因此标记已被删除的 bbx 区域中的分类性能较差。不过,视频中固有的时间一致性有利于我们从剩余的视频标记中细化演员和场景上下文。我们为RoIAlign[18]扩展了时域的局部bbxs,以捕获与行动者运动相关的标记特征。然后,我们引入了一个解码器来细化由该剪辑中剩余的视频标记引导的演员特征。我们发现,在tokens丢失之后,通过使用剩余的视频tokens进行上下文细化,可以有效地恢复降级的动作分类。
方法
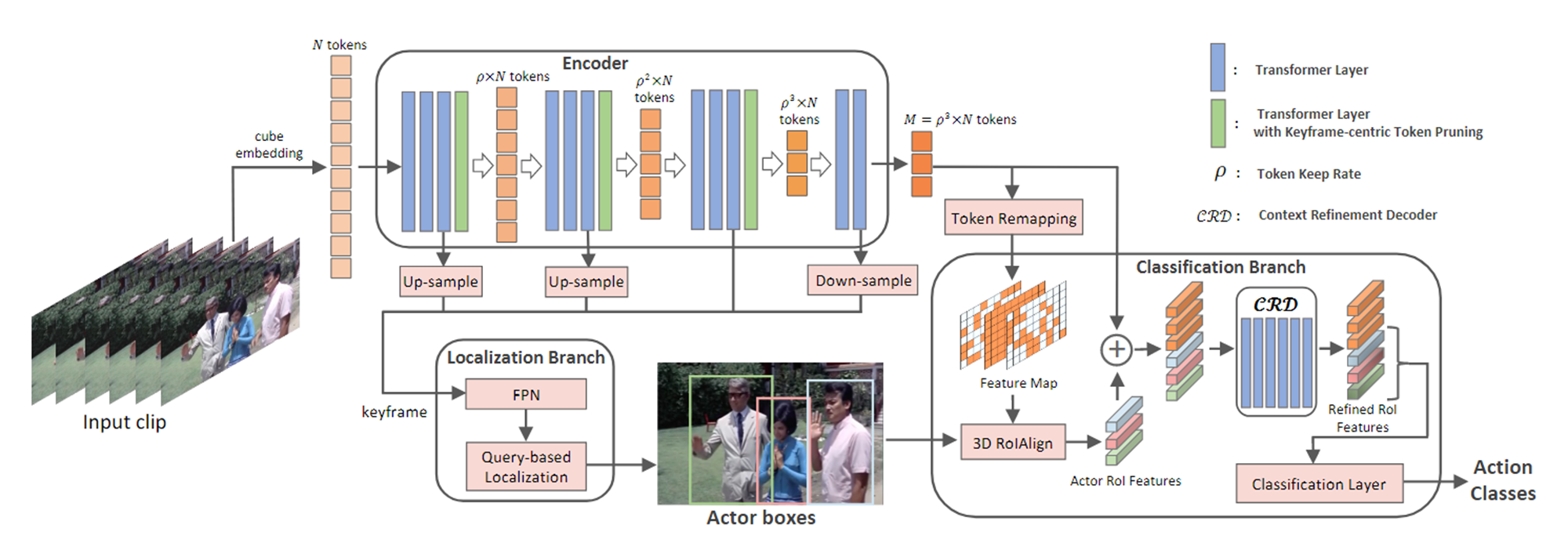
Overall EVAD Architecture
为了缓解联合时空注意力带来的计算瓶颈,我们设计了一种高效的视频动作检测器(EVAD),它具有编码器解码器架构,用于动作检测的特征。
EVAD 使编码器具有令牌修剪以消除冗余令牌,解码器改进参与者时空特征。按照WOO[7]中的设置,我们利用编码器中关键帧的多个中间空间特征图进行参与者定位,利用最后一个编码器层输出的时空特征图进行动作分类。
-
Token Pruning:令牌修剪。我们设计了一个以关键帧为中心的令牌修剪模块,以逐步减少视频数据的冗余,并确保为动作定位和分类提供少量且有前途的令牌
-
Localization:我们对关键帧的中间ViT特征图进行上采样或下采样,生成多尺度特征图,并将其发送到特征金字塔网络(FPN)[31]进行多尺度融合。定位分支通过基于查询的方法预测关键帧中的 n 个候选框,与 [45, 7] 中的相同。
-
Classification:我们将ViT编码器的紧凑上下文标记重新映射到具有规则结构的时空特征映射。
然后,我们使用来自定位分支的扩展预测框对恢复的特征图进行 3D RoIAlign,得到 n 个演员 RoI 特征。
随后,我们利用上下文细化解码器 (CRD) 进行参与者特征细化和编码器紧凑上下文之间的关系建模,并通过分类层对细化的 RoI 特征进行最终预测
Keyframe-centric Token Pruning
视频数据的高时空冗余使得相邻帧之间语义信息高度相似,这使得在transformer架构中高比例的token丢弃成为可能。
我们将所有时空标记拆分为关键帧标记和非关键帧标记。我们保留所有关键帧标记,以便在关键帧中进行准确的参与者定位。
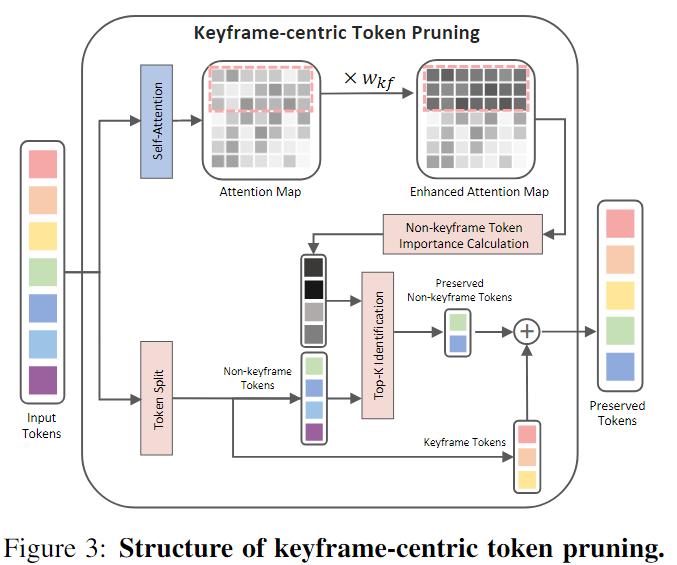
方法参考EViT
For the importance measure of non-keyframe tokens, we refer to the approach of EViT [29] in image classification, using the pre-computed attention map to represent the importance of each token without additional learnable parameters and nontrivial computational costs.
对于非关键帧标记的重要性度量,我们参考图像分类中EViT[29]的方法,使用预先计算的注意图来表示每个令牌的重要性,而不需要额外的可学习参数和非平凡的计算成本。
通常,关键帧包含当前样本最准确的语义信息,远离关键帧的其他帧会产生非平凡的信息偏差。因此,在关键帧的指导下进行令牌修剪是可行的。
为了保留与关键帧相关性更高的标记,我们在获取注意力图和计算每个非关键帧标记的重要性之间插入了一个关键帧关注度增强步骤。如图3所示,我们对关键帧查询应用了更大的权重值,从而保留了与关键帧标记具有更高相关性的标记。通过这种方式,我们能够更好地保留与关键帧相关的信息,以提高视频动作检测的效果。
我们丢弃一些只对非关键帧具有高响应的令牌,这些令牌可能不是高质量的令牌。只有当非关键帧成为前一个/下一个样本的关键帧时,这些高度响应的令牌都是高质量的
第一个令牌修剪从 1/3 的编码器层开始,以确保模型能够高级语义表示。然后,我们对总层的每 1/4 执行令牌修剪,丢弃冗余令牌并保持有效令牌。(12层)

Video Action Detection
-
Actor localization branch:关键帧用来定位,从VIT中采样多层次的语义信息来进行定位。(类似FPN)同时引入了一个基于query的定位头(受到Sparse R-CNN的启发)。最后,参与者定位分支的输出是关键帧中的 n 个预测框和相应的参与者置信度分数。
-
Action classification branch:与传统的特征提取不同,EVAD产生M个离散的视频令牌。我们需要恢复视频特征图的时空结构,然后可以执行与位置相关的操作,如RoIAlign。
-
restore the spatiotemporal structure:
1 initialize a blank feature map shaped as (T /2, H/16, W/16)
2 在用定位出来的bbox产生ROI feature的时候会有一个问题:ROIAlign无法在每一帧之间准确定位,因为人的移动和相机的抖动。直接扩大box的范围可能会影响actor的特征表示。EVAD可以正确地扩展框范围以添加偏离的特征,来消除这一困境。
3 在视频动作检测中,我们需要定位和分类所有演员的动作。然而,由于传统的token剪枝算法会导致空时上的演员特征不连贯,这对于准确识别演员动作是不利的。在编码器中,成对自注意力能够对令牌之间的全局依赖关系进行建模。actor区域内 dropout 标记的语义信息可以合并到一些保留的token中。因此,我们可以从保留的视频token中恢复移除的演员特征。
4 设计一个上下文细化解码器来细化演员的时空表示。将 n 个演员 RoI 特征与 M 个视频标记连接起来,并将它们输入到由 MHSA 和 FFN 组成的顺序堆叠transformer解码器中。由保留的token指导,演员特征可以通过来自其他帧的演员表示和运动信息来丰富自己。此外,在没有令牌修剪的情况下,解码器可以用作一种关系建模模块 [44, 59, 15, 46, 35] 来捕获参与者间和参与者上下文交互信息。解码器输出的 n 个细化演员特征被检索并通过分类层进行最终动作预测。

















 2141
2141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









