






1.最小二乘法
2.极大似然估计
3.交叉熵
最小二乘法

神经网络训练过程 x是标签,y是预测值
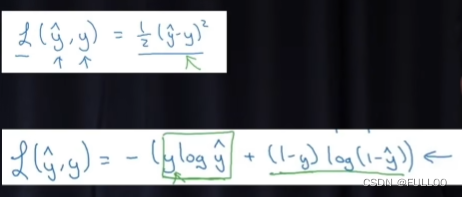
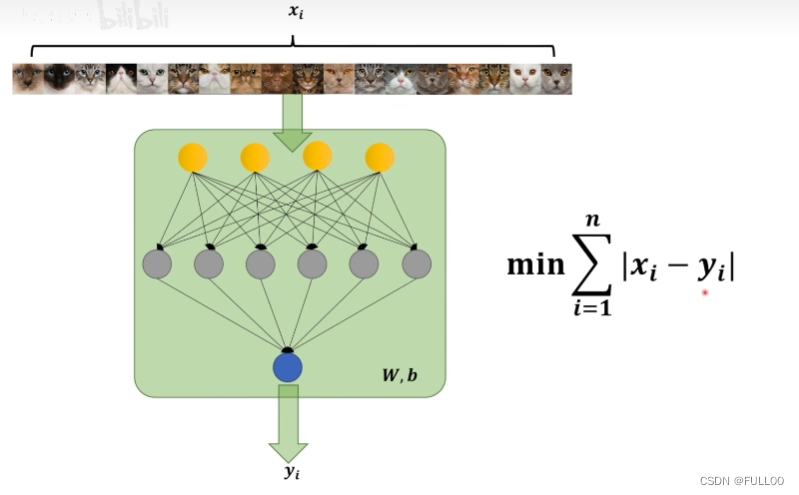 找差距,但绝对值在定义域上不一定全过程可导。所以采用了平方的方式,不会影响两个之间的关系。
找差距,但绝对值在定义域上不一定全过程可导。所以采用了平方的方式,不会影响两个之间的关系。

以上是对最小二乘法的解释
极大似然估计
从理念世界到现实世界,概率论

抛硬币的概率


假设概率模型是这样的条件下,投出右边C这种情况的概率。
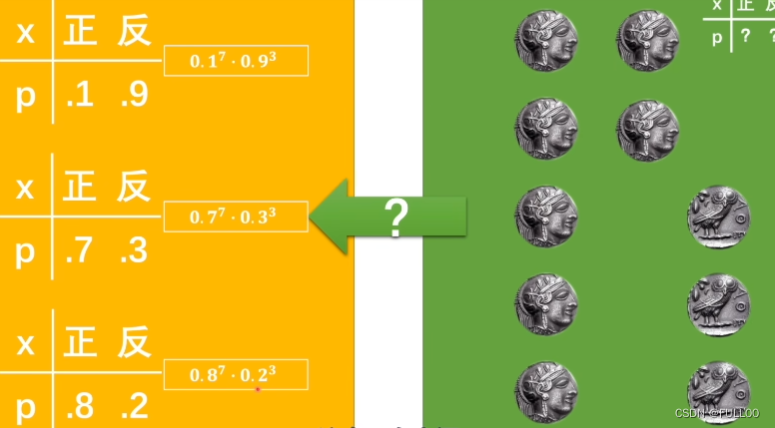
似然值是真实的情况巳经发生,我们假设它有很多模型,在这个概率模型下,发生这种情况的可能性。最大似然估计法由此而生。
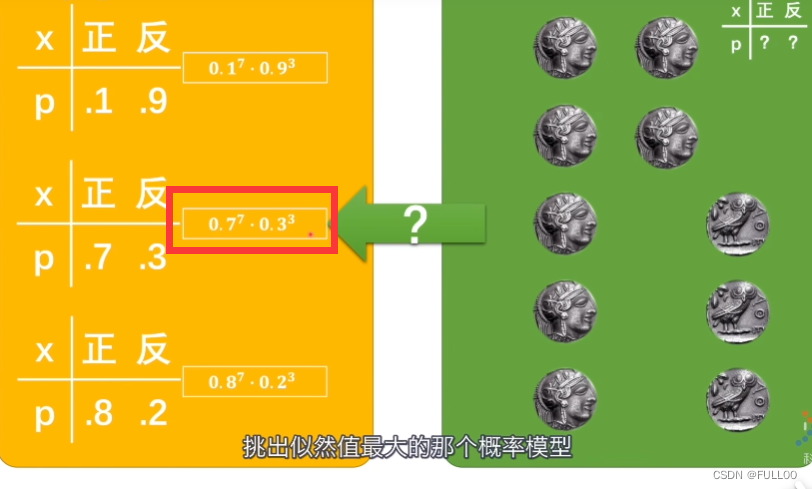
这个概率模型和本来的概率模型最接近。
给出的图片就像一个个抛出的硬币,极大似然估计本质上就是在计算神经网络里面的概率模型的似然值,找到最大似然值,就最接近真实的概率模型。
硬币落到地面是现实,人判断猫是现实。

让神经网络的模型尽量和人脑的模型一致,调整参数尽量和图像重叠


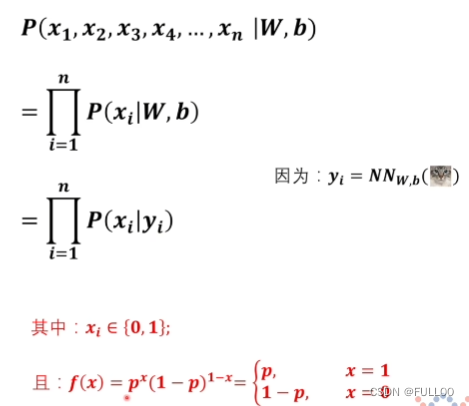

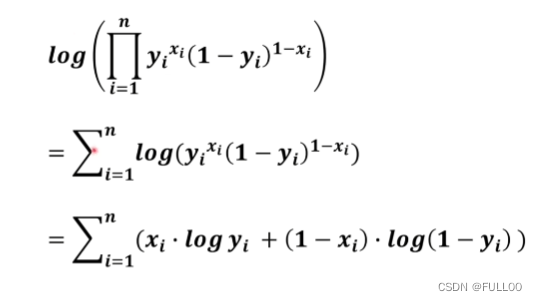
用log连乘变连加,不改变单调性
这个似然值最大就可以认定神经网络的模型和人脑模型最接近

但计算时,我们更习惯求最小值,所以加一个负号
为什么用极大似然估计推出来的是交叉熵呢?
交叉熵
前面两个都是在定量衡量两个模型(真实的模型和神经网络的预测模型)之间的差异
先把模型换成熵这样的数值,再用数值去比较不同模型之间的差异。
为什么要先转换呢?
两个模型之间的比较有障碍,模型不一样时,无法比较。
熵:一个系统里面的混乱程度。
不同信息含有不同的信息量。
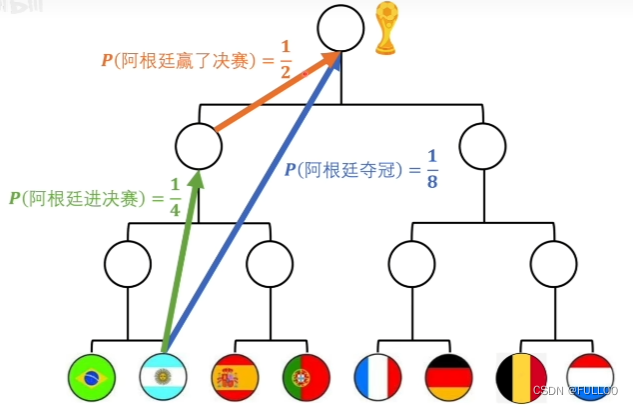



怎么把相乘变相加?
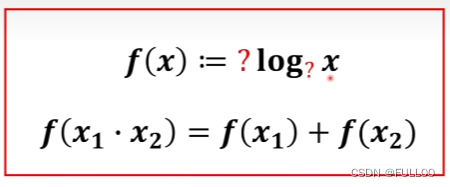
满足自洽,只是定义不用管其含义
x是自变量,一件事发生之前,概率越小,不确定性越大,信息熵越大,代表的信息量越大

以2为底去计算信息量,其实是在用抛硬币来衡量信息量。
一件事发生的概率1/2,就相当于抛1个硬币,1/8相当于3个硬币全部朝上的概率,1/3相当于1个和2个硬币之间。
(1/2)^x=1/3 x=1.58
信息量可以理解为从原来的不确定变为确定的难度有多大。信息量大就是难度大。
熵是衡量一个系统里面的所有事件从原来的不确定到确定难度有多大。

第一场比赛熵是1,相对于第二场不确定性更大。
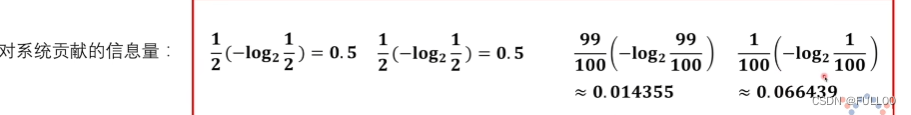
这里也可以理解成期望。
系统的熵:

对整体的概率模型进行衡量。
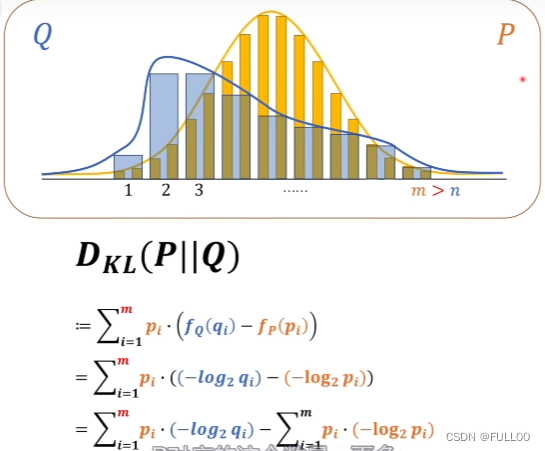
相对熵(KL散度)
相对熵涉及到两个概率系统。

KL散度的定义。
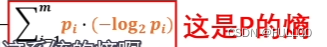
这个熵是恒定的,把p这个系统当作了基准。

KL散度等于0时,Q和P最接近。
两个值都是大于零的数,因为代表的是信息量。
前面>后面,交叉熵越大,KL散度距离0的距离就越远,p和q就越不像。
前面<后面,交叉熵越小,KL散度距离0的距离就越远,p和q就越不像。

证明KL散度>=0。
找到交叉熵最小的那个值,p,q差距就越小。
那么,

交叉熵越小,两个概率模型越接近。
** 怎么在神经网络利用交叉熵?**
m相等:

m<n:

m>n:

n是训练时用的照片的数量。
p是基准:要被比较的那个的概率模型,这里就是人脑,所以之间用的xi。
qi可以直接换成yi吗?
yi是在判断有多像猫,而在交叉熵的式子中,xi和yi要对应,xi是猫时,qi是有多像猫,xi不是猫时,qi是有多不像猫。

交叉熵和极大似然估计推出来的式子一样,但是物理意义不一样,交叉熵有量纲,极大似然估计没有量纲。
极大似然估计的log引入是因为喜欢做连加而不是连乘,以几为底无所谓。而交叉熵是用信息量和熵,log是其定义,2为底是因为最后计算单位是比特。
极大似然估计最后应该是求最大值,符合习惯才求的最小值,交叉熵的负号是在定义里面。















 1958
1958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









