






论文笔记:Meta-attention for ViT-backed Continual Learning CVPR 2022
论文介绍
这篇论文思想非常的新颖,其首次将增量学习(也叫终身学习)和 Vision transformer 结合在一起,想借助VIT的高性能来增强增量学习的准确度。其结合方法是加mask,这有点像
P
a
c
k
N
e
t
PackNet
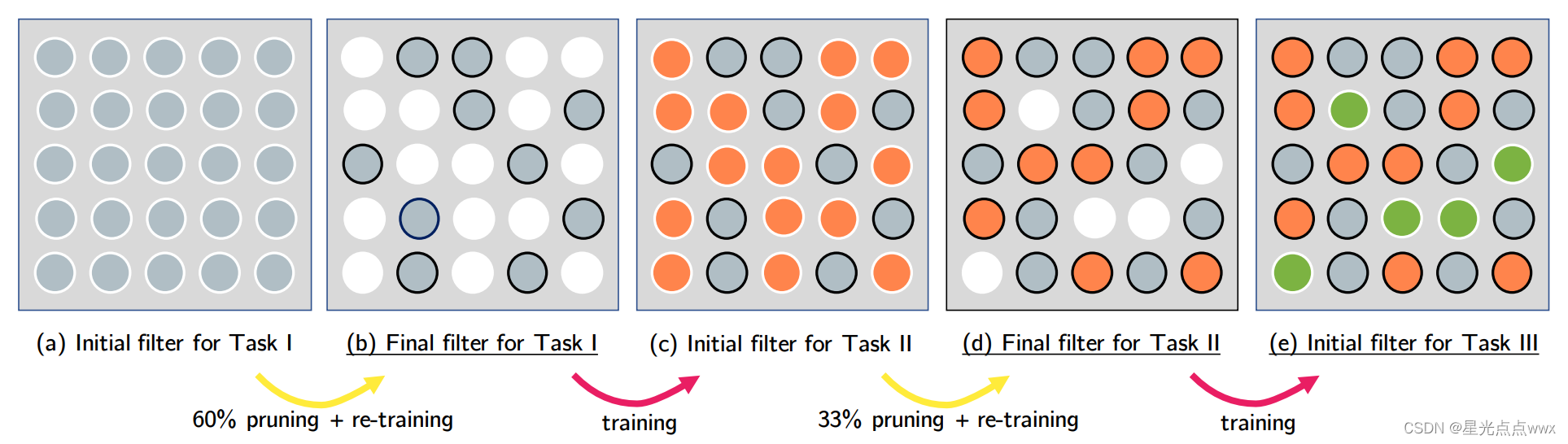
PackNet如下图,有些任务用不到网络的全部节点,这样就可以做多任务了。其中作者还利用 Gumbel-max 重参数化技巧来训练mask,这一点让我非常迷惑且难受。
论文地址以及参考资料
论文地址:Meta-attention for ViT-backed Continual Learning CVPR 2022
Vision Transformer 讲解视频: B站传送门
重参数化技巧:Categorical Reparameterization with Gumbel-Softmax ICLR 2017
Transformer 回顾
首先,回忆一下Self-Attention。
Self-Attention
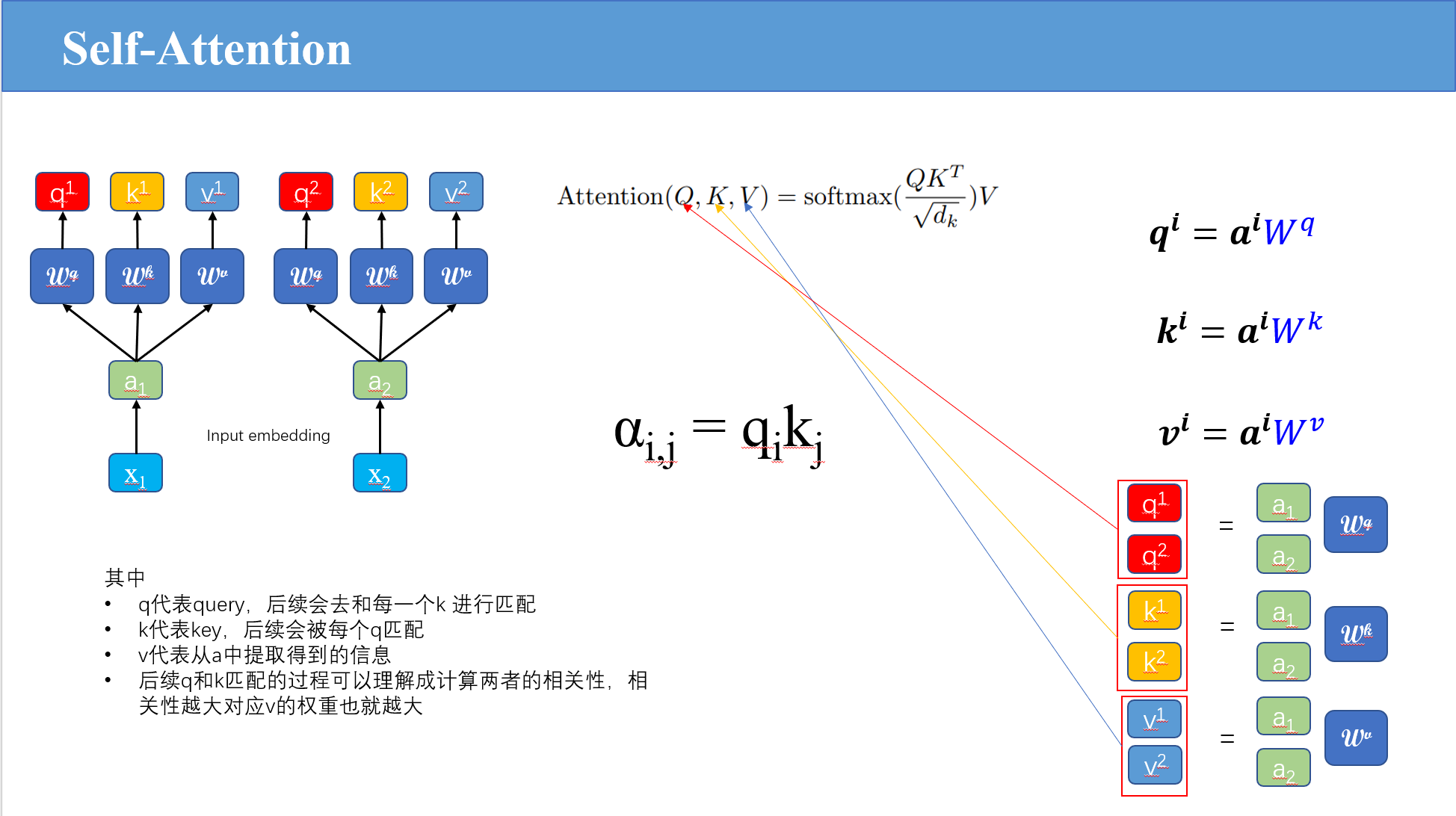
如上图,序列中的
x
i
x_i
xi会经过一个线性层
[
W
q
,
W
k
,
W
v
]
[W^q,W^k,W^v]
[Wq,Wk,Wv]得到
q
i
,
k
i
,
v
i
q_i,k_i,v_i
qi,ki,vi, 这里我插一嘴,可能有人会说得到
q
i
,
k
i
,
v
i
q_i,k_i,v_i
qi,ki,vi这三个是不是有点多啊,我就只有
q
i
,
k
i
q_i,k_i
qi,ki行不行 (某次组会师兄被怼😭),我可以明确的说不行,为啥不行,我先从数学方面解释,先看公式:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
其实,
Q
,
K
Q,K
Q,K的作用是产生注意力
α
\alpha
α, 这里
α
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
\alpha = softmax(\frac{QK^T}{\sqrt{d_k}})
α=softmax(dkQKT),注意这里有一层
s
o
f
t
m
a
x
softmax
softmax,所以神经网络forward的时候,
Q
,
K
Q,K
Q,K会先变成
α
\alpha
α然后forward,至于
V
V
V,从公式上看,他是直接“forward”,很明显,这会导致梯度回传(Back Propagation)时,
Q
,
K
Q,K
Q,K 和
V
V
V更新方式不一样,单纯的用
K
K
K替换
V
V
V可能会在更新时产生冲突, 例如:
K
K
K变小,
V
V
V变大
⇒
替
换
\xRightarrow{替换}
替换
K
K
K变小 且
K
K
K变大
所以说
Q
,
K
,
V
Q,K,V
Q,K,V缺一不可。
Vision transformer
VIT将图片分割成一个一个的patch,然后再进入transformer,如下图:

其实,对于上图这个图片分类的例子,有些patchs是不重要的,比如说这个图片是房子的类别,那么像天空的patch(背景patch)是不重要的。所以MEAT这篇论文在这就有点想法。
论文的方法
MEAT的作者想物尽其用, 有些patchs不太重要,可以通过添加掩膜,将patchs和其所对应的参数权重进行隔离,如下图:

MEta-ATtention (MEAT) — Attention to Self-attention
此篇论文的作者具体做法其实是在Self-attention之前,又做了一次attention,确定哪些patchs及其对应的权重可以被隔离,作者称这种方法为Attention to Self-attention 或者 MEta-ATtention (MEAT)
在论文中,作者首先将Self-attention公式改写成(这里是以多头的公式改写的)
h
e
a
d
h
=
Ψ
h
V
h
=
σ
(
A
h
)
V
h
=
σ
(
Q
K
T
d
k
)
V
h
head_h = \Psi_h V_h = \sigma(A_h) V_h=\sigma(\frac{QK^T}{\sqrt{d_k}})V_h
headh=ΨhVh=σ(Ah)Vh=σ(dkQKT)Vh
这里
Ψ
h
\Psi_h
Ψh可以理解为第h个头的注意力权重矩阵
α
\alpha
α,(下面,为了跟论文对应,我把
α
\alpha
α通通换成
Ψ
\Psi
Ψ)
Ψ
\Psi
Ψ矩阵:
[
Ψ
1
,
1
Ψ
1
,
2
.
.
.
Ψ
2
,
1
Ψ
2
,
2
.
.
.
.
.
.
.
.
.
.
.
.
]
\begin{bmatrix} \Psi_{1,1}&\Psi_{1,2}&...\\ \Psi_{2,1}&\Psi_{2,2}&...\\ ...&...&... \end{bmatrix}
⎣⎡Ψ1,1Ψ2,1...Ψ1,2Ψ2,2............⎦⎤
例如,上面矩阵的第一行对应着第一个patch的
q
q
q 与 其他patchs的
k
k
k 所得到的权重向量。
我们可以根据第一次attention得到的掩膜将
Ψ
\Psi
Ψ矩阵每一行变成:(假设第i行)
Ψ
h
i
=
[
Ψ
h
i
,
j
]
j
=
1
n
=
[
m
j
e
x
p
(
A
h
i
,
j
)
∑
s
=
1
n
m
s
e
x
p
(
A
h
i
,
s
)
]
j
=
1
n
\Psi_h ^i = [\Psi_h ^{i,j}]_{j=1} ^{n} = \bigg[ \frac{m^jexp(A_h^{i,j})}{\sum _{s=1}^n m^s exp(A_h^{i,s})}\bigg] _{j=1} ^{n}
Ψhi=[Ψhi,j]j=1n=[∑s=1nmsexp(Ahi,s)mjexp(Ahi,j)]j=1n
如果掩膜是二值掩膜(0或1)的话,上面的公式可进一步写成:
Ψ
~
h
i
,
j
=
{
m
j
e
x
p
(
A
h
i
,
j
)
∑
s
=
1
n
m
s
e
x
p
(
A
h
i
,
s
)
,
if
m
j
=
1
;
0
,
otherwise.
\tilde{\Psi}_h ^{i,j} = \begin{cases} \frac{m^jexp(A_h^{i,j})}{\sum _{s=1}^n m^s exp(A_h^{i,s})} , &\text{ if } m^j = 1; \\ 0, &\text {otherwise.} \end{cases}
Ψ~hi,j=⎩⎨⎧∑s=1nmsexp(Ahi,s)mjexp(Ahi,j),0, if mj=1;otherwise.
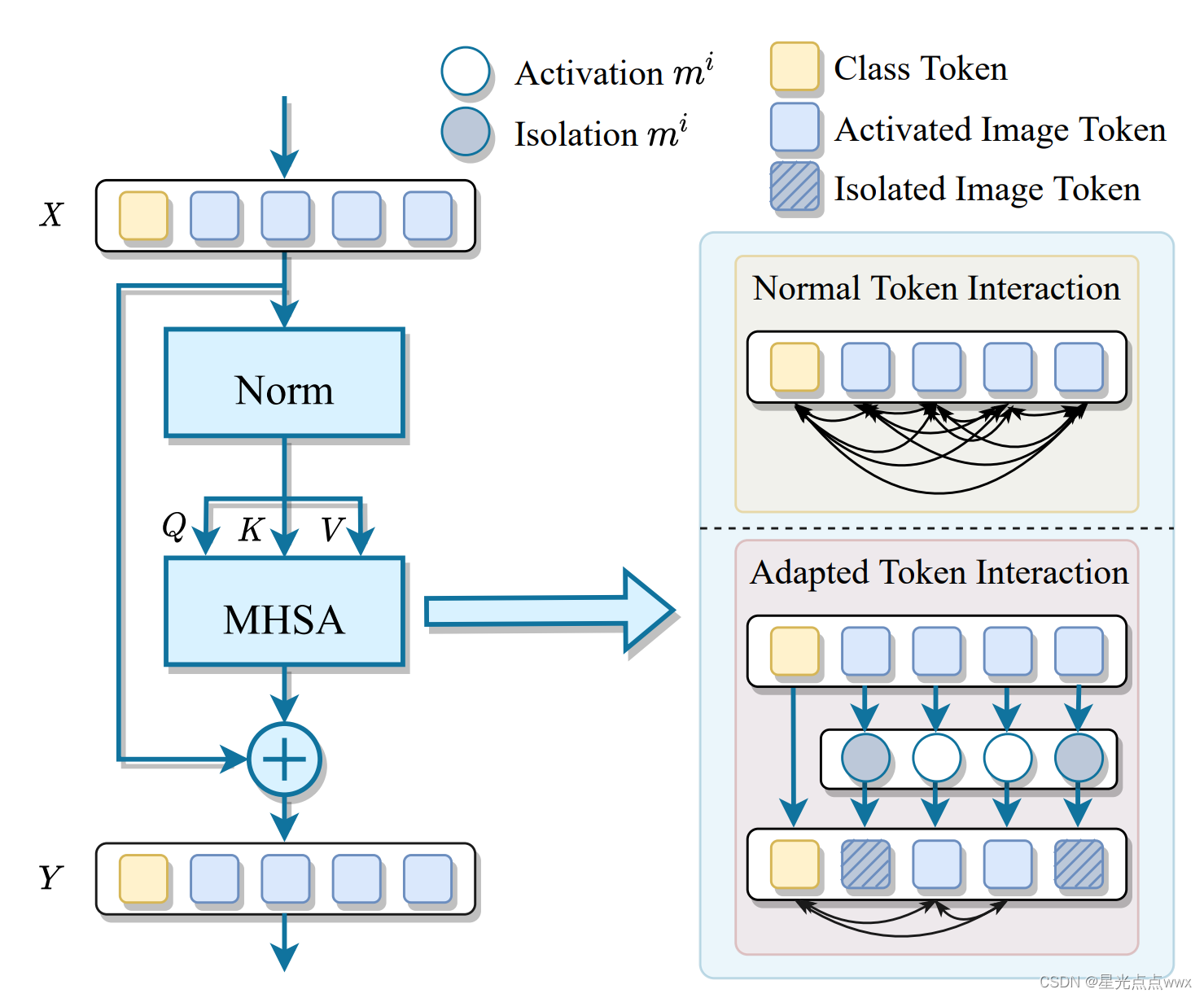
具体过程如下图,掩膜如何学习将在下一节展开
Binary attention masks - Gumbel Max技巧
作者所提出的掩膜是非常难学的,他是一个二值掩膜[one-hot]无法进行梯度下降,那怎么办呢?我们先想想面对one-hot向量有什么解决办法,我们可以采用softmax对one-hot向量进行近似。
传统方法
比如说我用一个 线性层(FC) 得到掩膜的二分类输出[20,15],要换成one-hot码是[1,0](这里第一个1代表要掩膜,第二个代表不要掩膜),即 [20,15] 变成 [1,0]
[20,15] 通过softmax 即
p
i
=
e
x
p
(
p
i
)
∑
j
=
1
2
e
x
p
(
p
j
)
p_i = \frac{exp(p_i)}{\sum_{j=1} ^2 exp(p_j)}
pi=∑j=12exp(pj)exp(pi)
得到 [0.993,0.007] ,这与[1,0]非常的近似。
还可以进一步调整softmax,引入知识蒸馏的温度
τ
\tau
τ 以调整软化程度:
p
i
=
e
x
p
(
p
i
/
τ
)
∑
j
=
1
2
e
x
p
(
p
j
/
τ
)
p_i = \frac{exp(p_i / \tau)}{\sum_{j=1} ^2 exp(p_j / \tau)}
pi=∑j=12exp(pj/τ)exp(pi/τ)
其实到这里,一开始,我个人觉得掩码这一块应该就结束了,但是作者却用了Gumbel-Softmax,这是为什么呢?
Gumbel-Softmax
想详细了解请看Categorical Reparameterization with Gumbel-Softmax ICLR 2017这篇论文
Gumbel-Softmax是在带有温度
τ
\tau
τ的softmax上加入了一定的随机性,此随机性由Gumbel分布采样得到:
m
i
=
p
1
i
=
e
x
p
(
(
p
1
i
+
g
1
)
/
τ
)
∑
j
=
1
2
e
x
p
(
(
p
j
i
+
g
j
)
/
τ
)
m^i = p_1 ^i = \frac{exp((p_1 ^i +g_1)/ \tau)}{\sum_{j=1} ^2 exp((p_j ^i+g_j)/ \tau)}
mi=p1i=∑j=12exp((pji+gj)/τ)exp((p1i+g1)/τ)
这里
m
i
m^i
mi表示第i个patch的掩膜(上一节提到的one-hot码
[
p
1
i
,
p
2
i
]
[p_1 ^i,p_2 ^i]
[p1i,p2i],只取位置1),(随机性)
g
j
和
g
1
g_j 和 g_1
gj和g1是从Gumbel分布采样得到的,也就是
g
=
−
l
o
g
(
−
l
o
g
(
u
)
)
,
其
中
u
∼
U
n
i
f
o
r
m
(
0
,
1
)
g = -log(-log(u)), 其中u∼Uniform(0,1)
g=−log(−log(u)),其中u∼Uniform(0,1),这确实增加了模型的鲁棒性,因为可能随着照片视角的改变,掩码的位置不一定是一成不变的。我觉着这种做法是合理的。
吐槽:但是啊,作者却不是这种做法,他连二分类的线性层(FC) 都没有,作者默认掩码是属于 U n i f o r m ( − γ , γ ) Uniform(-\gamma,\gamma) Uniform(−γ,γ)分布的,其中, γ > 0 \gamma > 0 γ>0是个超参, 掩码的 [ p 1 i , p 2 i ] [p_1 ^i,p_2 ^i] [p1i,p2i]值是直接从 U n i f o r m ( − γ , γ ) Uniform(-\gamma,\gamma) Uniform(−γ,γ)采样得到的。
比如采样得到概率为
[
π
1
i
,
π
2
i
]
[\pi_1 ^i,\pi_2 ^i]
[π1i,π2i], 于是
[
p
1
i
,
p
2
i
]
=
[
l
o
g
(
π
1
i
)
,
l
o
g
(
π
2
i
)
]
[p_1 ^i,p_2 ^i] = [log(\pi_1 ^i),log(\pi_2 ^i)]
[p1i,p2i]=[log(π1i),log(π2i)],
注意:这里
[
p
1
i
,
p
2
i
]
[p_1 ^i,p_2 ^i]
[p1i,p2i]默认是 线性层(FC) 的输出, 是没有经过
s
o
f
t
m
a
x
softmax
softmax的,所以
[
π
1
i
,
π
2
i
]
[\pi_1 ^i,\pi_2 ^i]
[π1i,π2i]必须加
l
o
g
log
log。
于是作者的想法是:
m
i
=
p
1
i
=
e
x
p
(
(
l
o
g
(
π
1
i
)
+
g
1
)
/
τ
)
∑
j
=
1
2
e
x
p
(
(
l
o
g
(
π
j
i
)
+
g
j
)
/
τ
)
m^i = p_1 ^i = \frac{exp((log(\pi_1 ^i) +g_1)/ \tau)}{\sum_{j=1} ^2 exp((log(\pi_j ^i)+g_j)/ \tau)}
mi=p1i=∑j=12exp((log(πji)+gj)/τ)exp((log(π1i)+g1)/τ)
于是作者提出来一个关于掩码的损失:
ℓ
d
c
(
m
)
=
1
L
∑
l
=
1
L
(
λ
−
1
n
∑
i
=
1
n
m
l
i
)
\ell_{dc}(m) = \frac{1}{L}\sum_{l=1} ^{L} \bigg( \lambda - \frac{1}{n}\sum_{i=1} ^{n} m_l^i\bigg)
ℓdc(m)=L1l=1∑L(λ−n1i=1∑nmli)
于是总损失就是:
ℓ
=
ℓ
c
e
(
p
^
,
p
)
+
α
ℓ
d
c
(
m
)
\ell = \ell_{ce}(\hat{p}, p) + \alpha \ell_{dc}(m)
ℓ=ℓce(p^,p)+αℓdc(m)
下面是作者做的可视化,确实掩码大部分在背景:
















 1377
1377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









