







前言
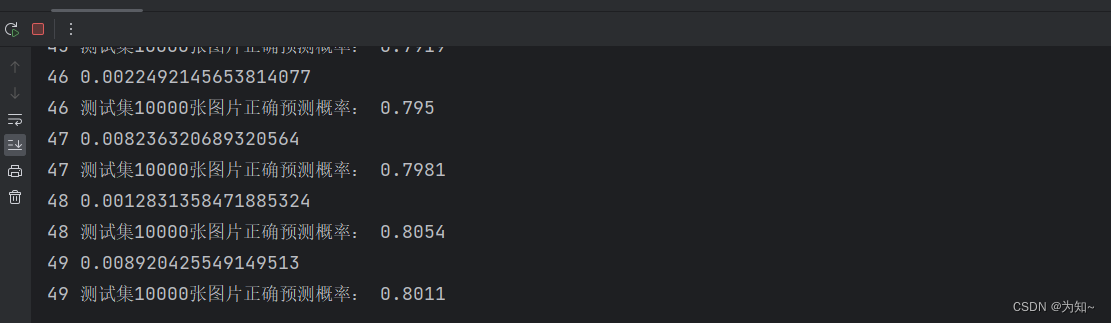
书接上回,我们使用lenet5实战cifar10在测试集上实现了50%-60%的正确率,效果还是比较差的,接下来我将基于pytorch框架从零实现resnet18来实战下cifar10数据集。 网络结果参考深度学习花书设计,最终实现80%的准确率,准确率直接提高了20%,当然据说使用resnet18在cifar10能实现90的正确率,当然这个效果的参数我没调得。
Resnet简介
神经网络就是一个比较复杂的函数,我训练神经网络是为了让这个函数f(x)能够逼近理想函数I(x)。为了让f(x)能最佳逼近理性函数I(x),我们下意识地会去猜测,我们让这个网络参数变多,网络层数变多不就有可能让这个网络最大程度地去逼近这个理想函数I(x)。但是实际上这么去做的时候,发现效果反而退化了,这与我们的直觉相违背。
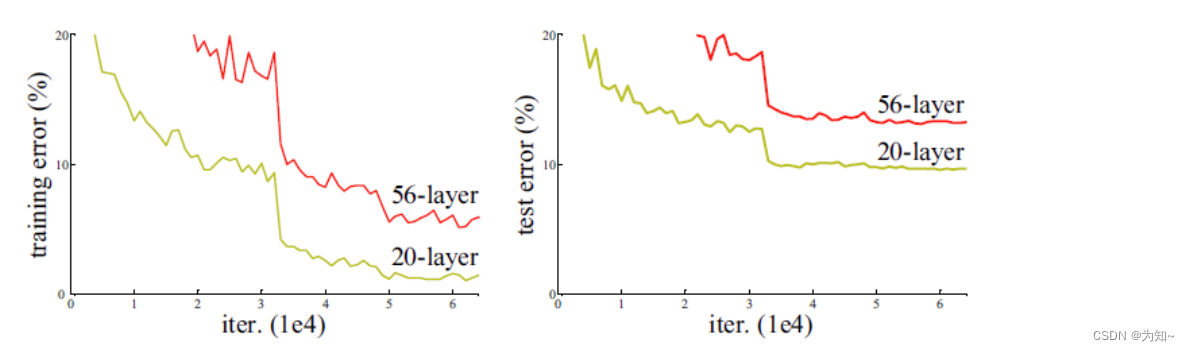
针对这一问题,何恺明等人提出了Resnet, 它在2015年的ImageNet图像识别挑战赛拿到了第一名,并深刻影响了后来的深度神经网络的设计。
Residual结构(Resnet核心基本单元)
这个结构从图中我们可以看出其实就是,x经过两个带有权重的层(两个卷积层)输出F(x)与x直接做加法。
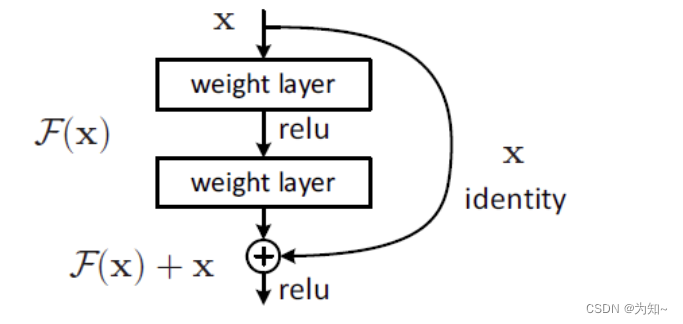
Residual结构的有什么意义呢?
之前我们提到在原来层数少的网络结构上逐渐加层,但是加了层后,网络对于实际数据集的拟合能力反而退化了,也就是意味着更多的参数训练过程中反而让网络偏离了理想的函数I(x)。
生动的理解就是:好家伙?我花10万元装修房子感觉效果符合自己口味,后来想花50万元装修房子希望装修出更令自己满意的效果。结果因为经费给多了,想法也可以更多,思路也更多,结果装修公司,重新走了个风格,反而装修的效果令人更不满意,这不血亏吗?所以问题出在哪呢,问题出在我们没有给装修公司更好地描述自己的想法,我希望装修公司从一开始10万元的效果上继续完善,而不是重新搞一条新的装修风格,结果令自己还不满意。
所以Resnet的思想其实也装修的思路一样就是希望给它更多的网络参数,能够在原来的基础上更好地去拟合理想地网络。所以如果我们让一个基本单元F(x)=f(x)+x,那么这样一个单元有了近似的短路线的可能。训练时参数迭代过程中,为了达到更好的效果,有可能让某一层参数近似于没有。如果没有这样的操作,训练时网络就会尽可能用上所有的参数,网络参数迭代的路线就比较‘’花‘’,到最后没办法逼近最优解。
就好比给了装修公司一笔钱,告诉让它朝着一个风格去装修,有的地方该花钱就可以花,不要花钱的地方就不花,效果令人满意就行,多的钱就不要花了。是为了装修好看而花钱,而不是为了花完钱而装修。
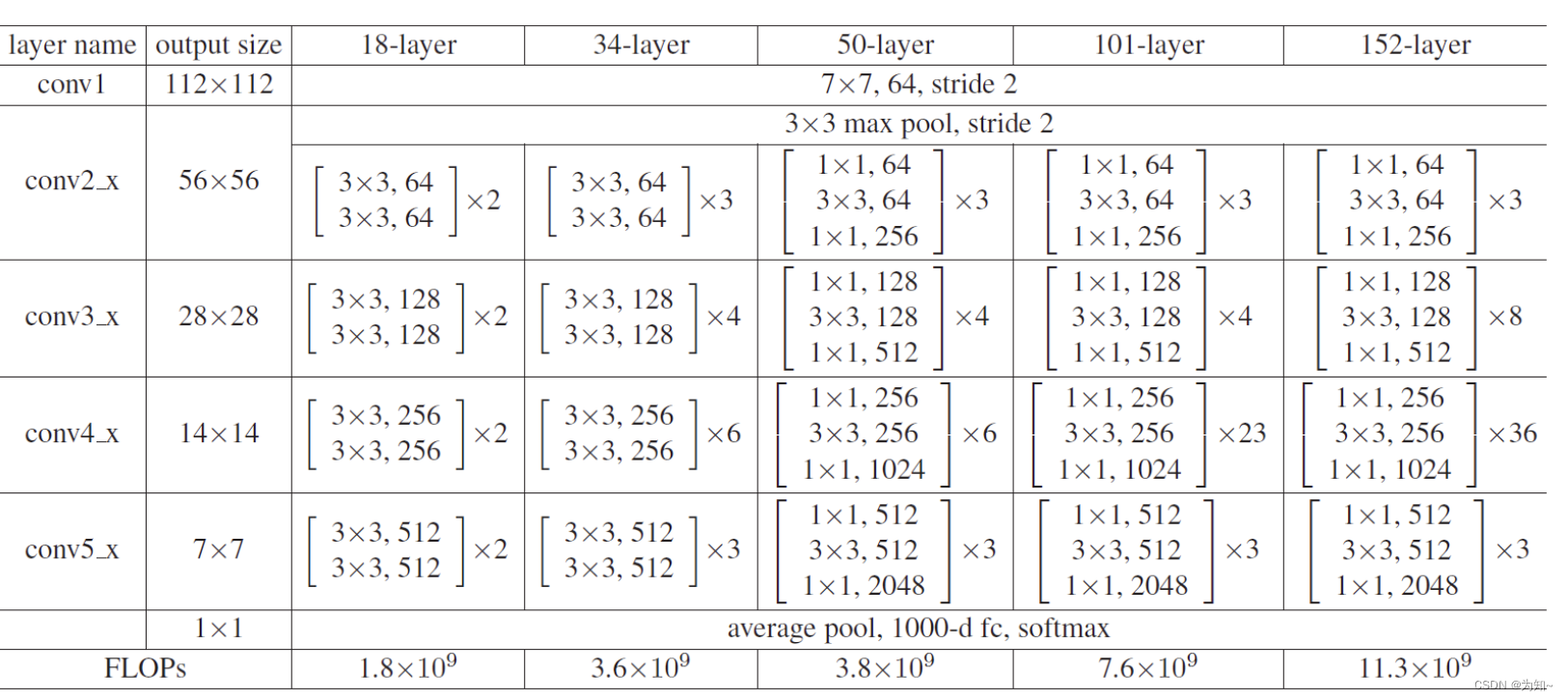
Resnet完整结构介绍
我们可以到18层的Resnet
依次经过:
输入卷积层
最大值池化层
四个大残差块(分别由小残差块组成 写x2就是表示一个大残差块有两个残差块基本单元组成)
平均池化层
全连接层
本程序 改动的地方:
我们实战用Cifar10输入大小比较小是32*32所以呢,最大值池化层这里stride改为1,不然卷积到最后图像的长和宽太小没法再进行卷积了。改成1这里刚好。
Resnet代码(resnet.py)
import torch
from torch import nn
from torch.nn import functional as F
"""
Resnet18结构介绍:(resnet18 18:是指17层卷积层+加上一层全连接层)
第1层:7*7卷积 批量归一化 3*3最大池化层
2-17: 4个大残差块,每个大残差块包含两个小残差块,每个小残差块:由两层卷积层和两层批量归一化层组成
(注意:每次卷积层后要经过批量归一化,每个批量归一化层输出经过激活函数)
全局平均池化层
18:全连接层
"""
class Residual(nn.Module): #残差块基本单元
def __init__(self,ch_in,ch_out,stride=1): #ch_in,ch_out表示输入图片的通道和输出图片的通道
super(Residual,self).__init__() #继承父类 接下来定义些ResBlk的方法(函数)
self.conv1= nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=stride,padding=1)#卷积模块
self.bn1 = nn.BatchNorm2d(ch_out) #正则 批量归一化
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra =nn.Sequential() #短路连接线
if ch_out !=ch_in: # 由于短路连接线是与卷积模块输出做加法,
self.extra = nn.Sequential( #当ch_out不等于ch_in需要用一个1*1卷积层转换通道数和分辨率使得短路线能与卷积输出相加
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self,x):
out=self.conv1(x) #卷积
out=self.bn1(out) #batchnorm
out=F.relu(out) #激活函数
out=self.bn2(self.conv2(out))
""" 调试短路线连接匹配问题,有时候调参会让这个不匹配导致报错
# print("self.extra(x):",self.extra(x).shape)
# print("out.shape:", out.shape)
"""
out=self.extra(x)+ out #短路连接
out= F.relu(out) #激活函数
return out
def ResBlk(ch_in,ch_out,num_residuals,first_block=False): #num_residuals为残差块数量 定义大残差块ResBlk由多个小残差块组成
blk=[]
for i in range(num_residuals):
if i==0 and not first_block: #第一个chin chout设置相同,
blk.append(Residual(ch_in,ch_out,stride=2))#如果第一个的stride输入2,而短路线不经过1*1卷积核转化通道数和转换分辨率,
else: #out=self.extra(x)+ out 短路连接不匹配程序会报错
blk.append(Residual(ch_out,ch_out))
return blk
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18,self).__init__()
self.blk0 =nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64) ,
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=1,padding=1)
)
#followed 4 blocks
# [b, 64, h, w] => [b, 128, h, w]
self.blk1 = nn.Sequential(*ResBlk(64, 64, 2,first_block=True)) #用ResBlk构建两个基本残差块的列表
# [b, 128, h, w] => [b, 256, h, w] #*进行序列解包,用Sequential方法构建一个大的残差块
self.blk2 = nn.Sequential(*ResBlk(64, 128, 2))
# [b, 256, h, w] => [b, 512, h, w]
self.blk3 = nn.Sequential(*ResBlk(128, 256, 2))
# [b, 512, h, w] => [b, 512, h, w]
self.blk4 = nn.Sequential(*ResBlk(256, 512, 2)) # [b,512,2,2]
self.outlayer = nn.Linear(512, 10) # 全连接层
def forward(self,x):
x = self.blk0(x)#输入层7*7卷积层 批量归一化层 池化层
x = self.blk1(x) #接下是四个大残差块
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x) #
x = F.adaptive_avg_pool2d(x, output_size=[1, 1]) # 自适应池化 输出大小1*1
x = x.view(x.size(0), -1) #转换为[batch,512] 输全连接层
x = self.outlayer(x)
return x
if __name__ == '__main__': #用于编写网络时,对网络输出shape进行测试
net = ResNet18()
X = torch.randn(1, 3, 32, 32)
out =net(X)
print("out shape:",out.shape)
训练主函数(resnet18_main.py)
import torch
from torch.utils.data import DataLoader
"""
DataLoader:是一种数据加载器,可设定batch大小,是否随机洗牌、并行加载(多线程加载,多个进程(多CPU加载))
可加载自定义数据集数据
数据拼接(补齐、截断)
配合transform实现数据预处理,数据统计
DATALOADER可以利用for循环当成迭代器使用(迭代器从零设计见 人工智能总结专栏3 线性回归从零设计)
"""
from torchvision import datasets, transforms
"""
datasets:用于下载一些常见数据集如MINIST、CIFAR-10、CIFAR-100、ImageNet等
transforms:进行图像的预处理操作,如随机裁剪、尺寸调整、归一化、颜色变换、旋转等
"""
from torch import nn, optim
"""
nn:是neural networks的缩写,用于构建神经网络层、损失函数(MSE Cross Entropy)等,以及用于优化神经网络的优化器(SGD、adam等)
optim:提供了多种常见的优化算法,如SGD、Adam、RMSProp等
"""
import matplotlib.pyplot as plt # 用于显示图片
# from lenet5 import lenet5
from resnet import ResNet18
"""
网络训练六步走:(在本程序中总结的六步,不只限于六步)
1、加载数据集
2、加载模型到GPU或CPU
3、加载损失函数到GPU或CPU
4、定义优化器类型和相关参数
5、迭代:计算损失函数,梯度清零、计算梯度、更新梯度
6、保存网络、验证效果
"""
# 批次大小
batchsz = 100
if __name__ == "__main__":
# 加载cifar10训练集 50000张训练集和10000张测试集
cifar_train = datasets.CIFAR10(root='cifar', # 数据集放在文件名cifar的文件夹下 root=用于提示自己这个参数作用(也可不写)
train=True,
transform=transforms.Compose([
transforms.Resize((32, 32)), # Resize图片长宽为32*32
transforms.ToTensor(), # 默认是JPEG,PNG,GIF,BMP,TIF 等PIL格式,要转换为tensor格式
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# 数据预处理,将每个通道的像素取值转化合适范围,提高训练稳定性
# 先将数据归一化后,每个通道像素减去对应均值mean再除于标准差std如 (x-0.485)/0.229
]), download=True # 如果文件夹下没有cifar10会进行下载
)
cifar_train = DataLoader(cifar_train, # 得到数据加载器
batch_size=batchsz, # 输入每次迭代返回批次大小
shuffle=True) # 随机打乱数据
cifar_test = datasets.CIFAR10(root='cifar', # 数据集放在文件名cifar的文件夹下 root=用于提示自己这个参数作用(也可不写)
train=False, # 不用于训练
transform=transforms.Compose([
transforms.Resize((32, 32)), # Resize图片长宽为32*32
transforms.ToTensor(), # 默认是JPEG,PNG,GIF,BMP,TIF 等PIL格式,要转换为tensor格式
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# 数据预处理,将每个通道的像素取值转化合适范围,提高训练稳定性
# 先将数据归一化后,每个通道像素减去对应均值mean再除于标准差std如 (x-0.485)/0.229
]), download=True # 如果文件夹下没有cifar10会进行下载
)
cifar_test = DataLoader(cifar_test, # 得到数据加载器
batch_size=batchsz, # 输入每次迭代返回批次大小
shuffle=True) # 随机打乱数据
# 如果想返回第一个batch的数据,得先通过iter转换为严格的迭代器才能利用__next__方法进行查看
# 但是cifar_train又能直接用for进行迭代
x, label = iter(cifar_train).__next__()
print('x:', x.shape, 'label:', label.shape) # x是100个batch也就是100张图
"""
#如果想显示一张图运行一下代码,cifar10分辨率是32*32比较低,比较模糊
#加载数据时注释掉这个transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])会看清楚些
pil_image=transforms.ToPILImage()(x[1])
print(pil_image)
plt.imshow(pil_image)
plt.axis('off')#不显示坐标轴
plt.show()
"""
if torch.cuda.is_available():
device = torch.device('cuda')
print("CUDA is available")
else:
device = torch.device('cpu')
print("CUDA is not available")
# 2、加载模型到GPU或CPU
model = ResNet18().to(device) # 获取自定义的Resnet18网络
print(model) # 打印网络结构
# 3、加载损失函数到GPU或CPU
criteon = nn.CrossEntropyLoss().to(device)
# 4、定义优化器类型和相关参数
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(1000):
model.train()
# 通常网络会包含 self.dropout = nn.Dropout(p=0.5) self.batchnorm2 = nn.BatchNorm2d(32)操作
# 执行model.train()那么训练时,让这些正则化操作有效 执行model.eval()是正则化操作会无效或改变
"""
正则化:减轻过拟合
dropout:随机丢弃一些神经元的输出
batch_normal:有效时,用当前batch均值和标准差进行 normalize操作,无效使用之前累计的平均均值和方差进行normalize操作
normalize:减去均值除标准差
"""
for batchidx, (x, label) in enumerate(cifar_train):
# enumerate用于返回:batchidx
x, label = x.to(device), label.to(device) # 将数据放入GPU
logits = model(x) # 网络返回的是shape[batch,10]的数据
loss = criteon(logits, label)
"""
交叉熵公式:
p(i)是输入图像x的情况下,属于某个类别的真实概率,在这里属于类1,概率为1,p(i!=1)的概率都为零
q(i)是预测某个类别的概率
-p(i)logq(i)将i遍历所有类别求和结果就是交叉熵。
CrossEntropyLoss(logits,label):
logits:输入[batch,10]:这里10为类别,该函数会计算sofmax将-1到1左右的值转换为0-1的数值
label:输入对应类别0-9即可,函数会根据交叉熵公式计算,所以label输入应为[batch]
batch通常不为1:函数会计算多个图片对应交叉熵运算平均值
"""
optimizer.zero_grad() # 每次计算梯度的结果是累计的,所以运算前要清零梯度信息
loss.backward() # 计算梯度
optimizer.step() # 更新梯度
print(epoch, loss.item()) # 每个epoch都会打印一次当前损失
model.eval() # 开启测试模式
# 每个训练的epoch都进行一次验证
acc_record = 0
with torch.no_grad(): # 表示接下来操作,计算图不需要计算梯度,提高代码运行效率
total_correct = 0
total_num = 0
for x, label in cifar_test:
x, label = x.to(device), label.to(device)
logits = model(x) # logits[batch,10]
pred = logits.argmax(dim=1) # 在dim=1维度,也就是第二个维度,获取该维度最大值的索引,也就是预测的类别
# pred[batch]
total_correct += torch.eq(pred, label).float().sum().item()
# 计算预测label与真实label相同的图片数量,.float()转为true为1.0 false为0.0,
# sum()所有正确预测求和 item()取数值
total_num += x.size(0) # 取一次预测所有图片数量,并迭代获得所有图片的数量 测试是总共有10000张测试集
acc = total_correct / total_num # 求正确预测概率
if acc_record < acc:
torch.save(model.state_dict(), "resnet18_model.pth")
print(epoch, "测试集10000张图片正确预测概率:", acc)
测试函数(resnet_test.py)
import torch
from resnet import ResNet18
import torch.nn as nn
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
save_path = "resnet18_model.pth"
batchsz=50
if __name__ =="__main__":
cifar_test= datasets.CIFAR10(root='cifar', #数据集放在文件名cifar的文件夹下 root=用于提示自己这个参数作用(也可不写)
train=False ,#不用于训练
transform=transforms.Compose([
transforms.Resize((32,32)), #Resize图片长宽为32*32
transforms.ToTensor(), #默认是JPEG,PNG,GIF,BMP,TIF 等PIL格式,要转换为tensor格式
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
#数据预处理,将每个通道的像素取值转化合适范围,提高训练稳定性
#先将数据归一化后,每个通道像素减去对应均值mean再除于标准差std如 (x-0.485)/0.229
]),download=True #如果文件夹下没有cifar10会进行下载
)
cifar_test =DataLoader(cifar_test, #得到数据加载器
batch_size=batchsz,#输入每次迭代返回批次大小
shuffle=True)# 随机打乱数据
if torch.cuda.is_available():
device = torch.device('cuda')
print("CUDA is available")
else:
device = torch.device('cpu')
print("CUDA is not available")
model= ResNet18().to(device)
model.load_state_dict(torch.load(save_path))
total_correct = 0
total_num = 0
for x, label in cifar_test:
x, label = x.to(device), label.to(device)
logits = model(x) # logits[batch,10]
pred = logits.argmax(dim=1) # 在dim=1维度,也就是第二个维度,获取该维度最大值的索引,也就是预测的类别
# pred[batch]
total_correct += torch.eq(pred, label).float().sum().item()
# 计算预测label与真实label相同的图片数量,.float()转为true为1.0 false为0.0,
# sum()所有正确预测求和 item()取数值
total_num += x.size(0) # 取一次预测所有图片数量
acc = total_correct / total_num # 求正确预测概率
print("total_correct:",total_correct)
print("total_num:", total_num)
print("acc:",acc)
总结和下一章预告
这一章利用resnet18实战cirfar10,实现了80%正确率的预测,下一章将用torchvision的已训练好的resnet18进行迁移学习实战cirfar10。















 6011
6011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









