






 本文提出一种新方法,通过利用HM3D的未标记3D建筑,自动生成大规模VLN数据集,通过2D对象检测和伪3D标签生成,解决数据稀缺问题,显著提高模型在未见过环境中的导航性能。
本文提出一种新方法,通过利用HM3D的未标记3D建筑,自动生成大规模VLN数据集,通过2D对象检测和伪3D标签生成,解决数据稀缺问题,显著提高模型在未见过环境中的导航性能。
这篇论文是关于高级指令的
摘要
在视觉和语言导航 (VLN) 中,实体代理需要按照自然语言指令在真实的 3D 环境中进行导航。现有 VLN 方法的一个主要瓶颈是缺乏足够的训练数据,导致对未见过的环境的泛化效果不理想。虽然 VLN 数据通常是手动收集的,但这种方法成本高昂并且阻碍了可扩展性。在这项工作中,我们通过建议从 HM3D 的 900 个未标记的 3D 建筑物自动创建大规模 VLN 数据集来解决数据稀缺问题 [45]。我们为每个建筑物生成一个导航图,并从 2D 传输对象预测,通过跨视图一致性生成伪 3D 对象标签。然后,我们使用伪对象标签作为提示来微调预训练的语言模型,以减轻指令生成中的跨模式差距。我们生成的 HM3D-AutoVLN 数据集在导航环境和指令方面比现有 VLN 数据集大一个数量级。我们通过实验证明 HM3D-AutoVLN 显着提高了 VLN 模型的泛化能力。在 SPL 指标上,我们的方法在 REVERIE 和 SOON 数据集的未见验证分割上分别比现有技术提高了 7.1% 和 8.1%。
介绍
让机器人执行各种家务是科幻小说中的常见愿景。这样的长期目标需要一个实体代理来理解我们的人类语言,在物理环境中导航并与物体交互。作为实现这一目标的第一步,视觉和语言导航任务(VLN)[3]已经出现并吸引了越来越多的研究关注。早期的 VLN 方法 [3,28] 为代理提供了到达目标位置的分步导航指令,例如“走出卧室。右转,沿着走廊走。在走廊尽头左转。走到沙发前停下来”。虽然这些详细的指令降低了任务的难度,但它们降低了人们在现实生活中指挥机器人时的实用价值。因此,最近的 VLN 方法 [43,57] 专注于高级指令,并要求代理在目标位置找到特定对象,例如,“到客厅把沙发上最靠近灯的白色靠垫拿给我”。智能体需要自行探索 3D 环境以找到“靠垫”。
与分步instruction相比,遵循这种高级目标驱动的说明更具挑战性。由于没有详细的指导,智能体需要了解环境的结构才能进行有效的探索。然而,大多数现有的 VLN 任务,如 REVERIE [43] 或 SOON [57] 都是基于 Matterport3D (MP3D) 数据集 [4] 的 3D 扫描,并且包含少于 60 个建筑物和大约 10K 训练轨迹。有限的训练数据量使得 VLN 模型过度适应可见环境,从而导致在未见环境中导航策略的通用性较差。然而,手动收集更多 VLN 数据成本高昂且不可扩展。为了解决这个数据稀缺问题,之前的工作研究了各种数据增强方法,例如通过说话者模型在所见环境中合成更多指令和轨迹[16]、环境丢失[49]或编辑[30],以及混合所见环境[33]。尽管如此,这些方法仍然基于少量的 3D 环境,无法覆盖广泛的对象和场景。为了解决视觉多样性,VLN-BERT [36] 利用来自网络的图像标题对来提高泛化能力,而 Airbert [18] 表明来自室内环境(BnB 数据集)的图像标题对对 VLN 任务更有利。然而,图像标题对很难模仿 3D 环境中代理的真实导航体验,这使得通过动作预测学习导航策略变得具有挑战性。
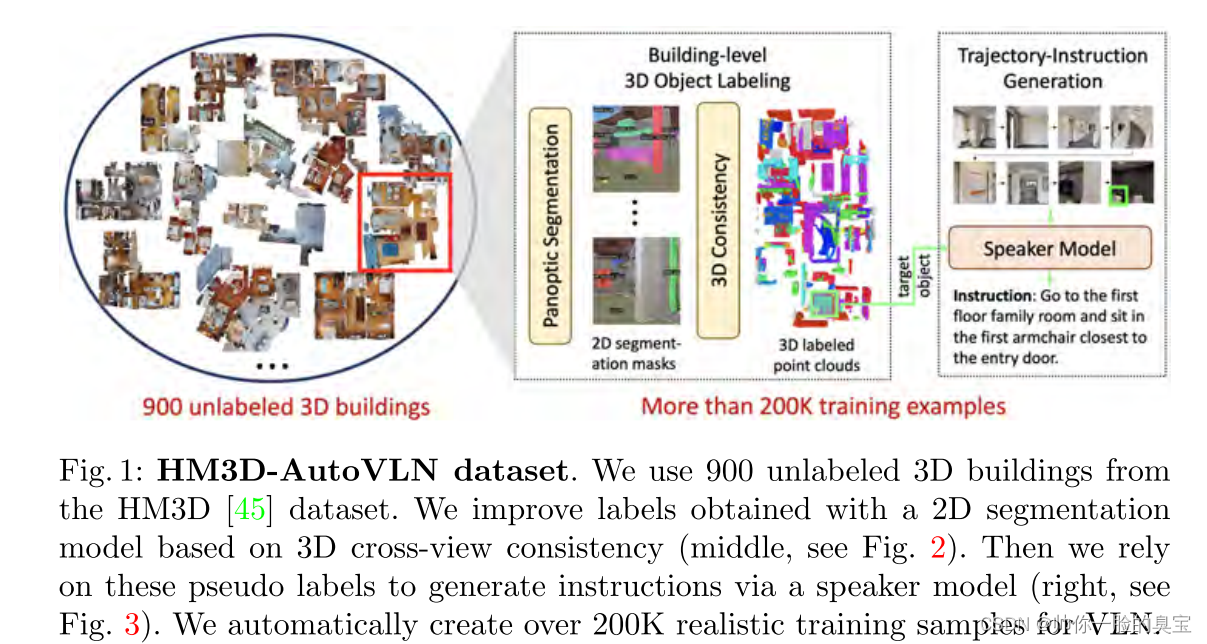
在这项工作中,我们提出了一种新的数据生成方法,通过学习大规模未标记的 3D 建筑来提高模型对未见过的环境的泛化能力(见图 1)。我们利用最新的 HM3D 数据集 [45],其中包含 900 座 3D 建筑物。然而,这些数据没有任何标签。为了在各种未见过的环境中生成高质量的指令轨迹对,我们使用大规模预训练的视觉和语言模型。我们首先使用图像分割模型 [10] 来检测环境中图像的 2D 对象,并利用 3D 中的跨视图一致性来提高伪 3D 对象注释的准确性。然后,我们使用伪对象标签作为提示来微调语言模型 GPT-2 [44],以生成该对象的高级导航指令。通过这种方式,我们构建了 HM3D-AutoVLN 数据集,该数据集使用 900 个 3D 建筑物,由 36,562 个可导航节点、172,000 个 3D 对象和 217,703 个用于训练的对象-指令-轨迹三元组组成,比之前的 VLN 数据集大一个数量级。我们使用生成的 HM3D-AutoVLN 数据训练多个最先进的 VLN 模型 [8,9,22,49],并显示出显着的收益。具体来说,我们在 REVERIE 和 SOON 数据集上比最先进的 DUET 模型 [9] 分别提高了 7.1% 和 8.1%。总之,我们的贡献如下:
1、我们引入了一种从未标记的 3D 建筑物构建大规模 VLN 数据集 HM3D-AutoVLN 的自动方法。我们依靠 2D 图像模型来获取伪 3D 对象标签,并依靠预训练的语言模型来生成指令。
2、我们对两个具有挑战性的 VLN 任务 REVERIE 和 SOON 进行了广泛的实验。 HM3D-AutoVLN 数据集上的训练显着提高了多个最先进的 VLN 模型的性能。
3、我们提供有关数据收集和利用未标记环境所固有的挑战的见解。这表明环境的多样性比单独的训练样本数量更重要。
相关工作
vision and language navigation
随着各种支持数据集的出现,VLN 任务最近得到了普及[3,6,23,27,28,39,48,50]。不同的指令定义了 VLN 任务的变化。分步指令[3,6,28]要求智能体严格遵循路径,而目标驱动的高级指令[43,57]主要描述目标地点和物体,并命令智能体检索特定的远程对象。具身的问答任务要求代理导航并回答问题[12,55],而视觉和语言对话[13,38,39,50]任务使用与代理的交互式通信来指导导航。由于固有的多模态性质,VLN 任务的工作提供了有吸引力且富有创意的模型架构,例如跨模态注意机制 [16,34,35,49,52]、对象感知 [20,37,42]、序列建模使用transformer [8,22,40]、贝叶斯状态跟踪 [1] 和基于图的结构来更好地探索 [9,14,51]。这些模型通常以teacher forcing方式进行预训练 [8,19],然后使用student forcing [3,9]、随机采样 [31] 或强化学习 [8,22,49,53] 进行微调。虽然大多数现有的 VLN 工作侧重于具有预定义导航图的离散环境,但连续环境中的 VLN [26,27] 在现实世界中更实用 [2]。离散环境也被证明有利于连续 VLN,例如提供路点监督 [46] 并支持低级和高级操作的分层建模 [7,21]。
Data-centric VLN approaches
VLN 的主要挑战之一仍然是训练数据的稀缺,导致见过环境和未见过环境之间存在巨大差距。数据增强是解决过度拟合的一种有效方法,例如丢弃环境特征[49]、更改图像样式[30]、不同环境中的混合室[33]、从说话者模型生成更多路径指令对[16, 17,49] 和来自 GAN 的新图像 [24]。然而,这些数据增强方法仍然基于有限数量的环境,削弱了对未知环境的泛化能力。与上述相反,VLNBert [36] 和 Airbert [18] 利用丰富的网络图像标题来提高泛化能力。然而,这些数据并不完全类似于真实的导航体验,因此它们只能用于训练兼容性模型来测量路径指令相似性,而不是学习导航策略。在我们的工作中,逼真的 3D 环境用于学习导航策略。
3D environments
3D环境和仿真平台[25,29,41,47]是促进具身智能研究的基础。有一些基于视频游戏引擎的人工环境,例如 iThor [25] 和 VirtualHome [41],它们利用合成场景并允许与对象交互。然而,合成场景的视觉多样性有限,不能完全反映现实世界。因此,我们专注于 VLN 的逼真 3D 环境。 MP3D [4] 数据集是 90 个标记环境的集合,在 R2R [3]、RxR [28]、REVERIE [43] 和 SOON [57] 等现有 VLN 数据集中得到最广泛采用。虽然拥有高质量的重建,但 MP3D 中的房屋数量有限。 Gibson [54] 数据集包含 571 个场景,但它们的 3D 重建质量很差。最近的 HM3D 数据集 [45] 拥有最多数量的 3D 环境,但没有标签。它包含世界各地 1,000 个高质量且多样化的建筑规模重建(900 个公开发布),例如多层住宅、商店、办公室等。在这项工作中,我们采用未标记的 HM3D 数据集来扩展 VLN 数据集。

















 2441
2441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









