






摘要
导航是具有视觉-运动能力的智能体的基本技能。我们提出了一种导航世界模型(Navigation World Model, NWM),这是一种可控的视频生成模型,能够基于过去的观察和导航动作预测未来的视觉观察。为了捕捉复杂的环境动态,NWM采用了一种条件扩散Transformer(Conditional Diffusion Transformer, CDiT),该模型在多样化的第一人称视角视频数据集上进行了训练,包括人类和机器人智能体的视频,并扩展到了10亿参数规模。在熟悉的环境中,NWM可以通过模拟导航轨迹并评估其是否达到预期目标来规划路径。与具有固定行为的监督导航策略不同,NWM能够在规划过程中动态地融入约束条件。实验表明,NWM在从头规划轨迹或对外部策略采样的轨迹进行排序方面表现出色。此外,NWM利用其学习到的视觉先验知识,能够从单张输入图像中想象出陌生环境中的轨迹,使其成为下一代导航系统中灵活而强大的工具。
-
模型设计:
- NWM是一种可控的视频生成模型。它通过**条件扩散Transformer(CDiT)**进行训练,CDiT是一种先进的神经网络架构,能够生成预测的视觉观测(例如视频帧)。
- 它基于过去的视觉观测和导航动作来预测未来的视觉情况。这意味着NWM不仅能够理解当前的环境状态,还能够预测未来的场景变化,这对于导航任务至关重要。
-
训练数据和规模:
- NWM在一个多样化的自我视角视频数据集上进行了训练,这些数据集包括了人类和机器人智能体的导航行为。这使得NWM能够学习到更为丰富的视觉-运动模式。
- 模型的参数量高达10亿个,这使其在处理复杂环境时具有较强的能力。
-
导航路径规划:
- 在熟悉的环境中,NWM能够通过模拟并评估不同路径的效果,来进行导航路径的规划。这与传统的监督学习导航策略有所不同,后者的行为是固定的,而NWM在规划过程中具有更多的灵活性。
-
实验效果:
- 该模型通过一系列实验验证了其在从零开始规划路径、对路径进行排序的能力。
- 在陌生环境中,NWM能够利用其学习到的视觉先验知识,根据单张输入图像来推测出合理的路径。
引言
导航是任何具有视觉的生物体的基本技能,在生存中起着至关重要的作用,使智能体能够定位食物、寻找庇护所并避开捕食者。为了成功导航环境,智能体主要依赖视觉,使其能够构建周围环境的表征,评估距离并捕捉环境中的地标,这些都对规划导航路径非常有用。
当人类智能体进行规划时,他们通常会考虑约束条件和反事实来想象未来的轨迹。然而,当前最先进的机器人导航策略(Sridhar等,2024;Shah等,2023)是“硬编码”的,训练后无法轻松引入新的约束条件(例如“禁止左转”)。当前监督式视觉导航模型的另一个局限性是,它们无法动态分配更多计算资源来解决复杂问题。我们的目标是设计一种新模型,以缓解这些问题。
(约束条件是指在导航规划过程中必须遵守的限制或规则。这些约束可以是物理的、环境的或人为设定的。NWM能够在规划过程中动态引入约束条件。例如,模型可以生成一条符合“禁止左转”约束的导航轨迹,或者确保机器人在规划路径时不会靠近悬崖边缘。)
(反事实是指在规划过程中,智能体(如人类或机器人)会考虑“如果采取不同的行动,会发生什么”的情景。换句话说,反事实是对不同决策路径的假设性思考。例如:如果机器人选择左转而不是右转,它会更快到达目标吗?NWM通过模拟不同的导航轨迹来评估它们的可行性。这种模拟过程类似于反事实推理,模型可以生成多条可能的路径,并评估每条路径的优劣,从而选择最优的导航策略。)
在导航规划中,约束条件和反事实通常是结合使用的。智能体在规划路径时,不仅会考虑当前的约束条件,还会通过反事实推理来评估不同决策的后果。
-
例子:假设机器人需要从A点导航到B点,但中间有一个障碍物。机器人会考虑以下问题:
-
约束条件:不能穿过障碍物。
-
反事实推理:如果选择左转绕过障碍物,路径会更长但更安全;如果选择右转绕过障碍物,路径会更短但可能会遇到其他障碍。
-
决策:根据反事实推理的结果,机器人选择最优的路径。
-
在导航策略中,“硬编码”意味着导航规则或行为是预先定义好的,并且在训练过程中被固定下来。例如,假设在训练时,机器人被允许左转和右转。如果在实际应用中需要引入“禁止左转”的约束,硬编码的策略无法轻松实现这一点,因为它的行为模式已经被固定。
在导航任务中,某些问题可能比其他问题更复杂。例如,在简单的环境中(如空旷的走廊),导航任务可能只需要少量的计算资源;而在复杂的环境中(如拥挤的商场或动态变化的户外环境),导航任务可能需要更多的计算资源来规划最优路径。
为什么当前模型无法动态分配计算资源?
-
固定计算模式:当前的监督视觉导航模型通常在训练时使用固定的计算模式。例如,模型可能被设计为在每次规划时使用相同数量的计算资源(如固定的神经网络层数或固定的推理时间),而不会根据任务的复杂程度进行调整。
-
缺乏适应性:这些模型缺乏对任务复杂性的感知能力。无论任务简单还是复杂,它们都会使用相同的计算资源,这可能导致在简单任务上浪费资源,而在复杂任务上表现不佳。
-
计算资源的限制:在实际应用中,计算资源(如GPU、内存等)是有限的。如果模型无法动态调整资源分配,可能会导致在复杂任务上无法获得足够的计算支持,从而影响导航性能。

在本研究中,我们提出了一种导航世界模型(Navigation World Model, NWM),该模型经过训练,能够基于过去的帧表征和动作预测未来视频帧的表征(见图1(a))。NWM在从各种机器人智能体收集的视频片段和导航动作上进行训练。训练完成后,NWM通过模拟潜在的导航计划并验证它们是否达到目标来规划新的导航轨迹(见图1(b))。为了评估其导航能力,我们在已知环境中测试NWM,评估其独立规划新轨迹或通过对外部导航策略进行排序的能力。在规划设置中,我们在模型预测控制(Model Predictive Control, MPC)框架中使用NWM,优化动作序列以使NWM能够达到目标。在排序设置中,我们假设可以访问现有的导航策略(例如NoMaD),这使得我们能够采样轨迹,使用NWM进行模拟,并选择最佳轨迹。我们的NWM在独立性能上表现出色,并在与现有方法结合时达到了最先进的水平。
模拟导航计划是指模型根据当前的观察和可能的动作序列,生成未来的一系列视觉状态(即未来的图像帧)。为了评估NWM的导航能力,作者在已知环境中进行了测试。评估分为两种方式:独立规划:NWM完全独立地规划导航轨迹,NWM被嵌入到模型预测控制(MPC)框架中,通过反复预测未来的状态并优化动作序列,使系统能够达到目标。排名外部策略:NWM与现有的导航策略(如NoMaD)结合,通过模拟和排名来选择最优的轨迹。即从现有的导航策略中采样多条可能的轨迹,使用NWM模拟这些轨迹,生成未来的视觉状态,通过比较生成的未来图像与目标图像的相似性,选择最优的轨迹。
独立规划和排名外部策略是两种不同的导航规划方法,它们的核心区别在于是否依赖现有的导航策略以及规划过程的自主性。
独立规划:假设机器人需要从A点导航到B点,NWM会生成多条可能的路径(如“向前移动1米,然后右转”或“向左转,然后向前移动2米”),并通过模拟和优化选择最优路径。
排名外部策略:假设现有的导航策略(如NoMaD)生成了10条可能的路径,NWM会模拟这些路径,并通过比较生成的未来图像与目标图像的相似性,选择最优的路径。
导航世界模型(NWM)在概念上与最近基于扩散的世界模型(用于离线基于模型的强化学习)相似,例如DIAMOND(Alonso等人)和GameNGen(Valevski等人,2024)(DIAMOND和GameNGen这些模型主要用于游戏环境(如Atari和Doom)的模拟,通常在单一环境或任务中进行训练,缺乏对多样化环境和任务的支持)。然而,与这些模型不同的是,NWM在多种环境和实体上进行训练,利用了来自机器人和人类代理的多样化导航数据。这使得我们能够训练一个大型扩散变换器模型,该模型能够有效地随着模型规模和数据的增加而扩展,以适应多种环境。我们的方法还与新颖视图合成(Novel View Synthesis, NVS)方法(如NeRF(Mildenhall等人,2021)、Zero-1-2-3(Liu等人,2023)和GDC(Van Hoorick等人,2024))有相似之处(这些方法的目标是从单张或多张输入图像中生成新的视角图像,通常用于3D场景重建或虚拟现实。许多NVS方法依赖于3D先验(如深度信息或3D模型)来生成新视角图像。),并从中汲取了灵感。然而,与NVS方法不同的是,我们的目标是训练一个单一模型,用于在多样化环境中进行导航,并从自然视频中建模时间动态,而不依赖于3D先验(NWM不依赖于3D先验,而是直接从2D图像中学习环境动态)。
为了学习NWM,我们提出了一种新的条件扩散变换器(Conditional Diffusion Transformer,简称CDiT),该模型被训练为在给定过去的图像状态和动作作为上下文的情况下,预测下一个图像状态。与DiT(Peebles和Xie,2023)不同,CDiT的计算复杂度与上下文帧的数量线性相关,它在训练过程中能够有效扩展,支持多达10亿参数,并且与标准DiT相比,所需的FLOP数量减少了4倍,同时在未来预测任务上取得了更好的结果。
在未知环境中,我们的结果显示,NWM受益于在Ego4D等视频数据集上训练的无标签、无动作和奖励的视频数据。从定性分析来看,我们观察到,在单张图像上,视频预测和生成性能有所提高(见图1(c))。定量上,使用额外的无标签数据时,NWM在斯坦福Go(Hirose等,2018)数据集上进行评估时,能够产生更准确的预测。
我们的贡献如下:
1、我们提出了一个导航世界模型(NWM),并提出了一种新的条件扩散变换器(CDiT),该模型能够高效扩展至10亿参数,并且与标准DiT相比大大减少了计算需求。
2、我们在来自不同机器人智能体的视频片段和导航动作数据上训练CDiT,使其能够通过独立模拟导航计划或与外部导航策略一起规划,取得了最先进的视觉导航表现。
3、通过在无动作和奖励的视频数据上训练NWM(例如Ego4D),我们在未知环境中展示了改进的视频预测和生成性能。
与两个挑战的对应关系:
相关工作
1. 目标导向视觉导航
- 任务定义:目标导向视觉导航要求机器人具备感知和规划能力,通过给定的上下文图像和目标图像,生成可行的路径。
- 现有方法:
- NoMaD(Sridhar et al., 2024):通过行为克隆和时间距离目标训练扩散策略,以在已知环境中跟随目标或在新环境中探索。
- Active Neural SLAM(Chaplot et al.):结合神经 SLAM 和解析规划器在 3D 环境中规划路径。
- 强化学习方法(Chen et al.):通过强化学习训练导航策略。
- 本文的创新:本文提出使用世界模型(World Model)利用探索性数据来规划或改进现有的导航策略。
2. 世界模型
- 目标:世界模型的目标是模拟环境,即给定当前状态和动作,预测下一状态和奖励。
- 现有工作:
- 联合学习策略和世界模型:在 Atari 游戏(Hafner et al.)、模拟机器人环境(Seo et al., 2023)和真实机器人(Wu et al., 2023)中提高了样本效率。
- 多任务共享世界模型(Hansen et al.):通过引入动作和任务嵌入,实现跨任务共享。
- 语言描述动作(Yang et al.; Lin et al., 2024b):用语言描述动作。
- 潜在动作学习(Bruce et al., 2024):学习潜在动作。
- 游戏模拟:DIAMOND(Alonso et al.)和 GameNGen(Valevski et al., 2024)使用扩散模型学习游戏引擎(如 Atari 和 Doom)。
- 本文的创新:本文旨在学习一个通用的扩散视频 Transformer,适用于多种环境和代理的导航任务。
3. 视频生成
- 挑战:视频生成是计算机视觉中的长期挑战。
- 现有方法:
- 文本到视频合成:如 Sora(Brooks et al., 2024)和 MovieGen(Polyak et al., 2024)。
- 结构化控制:基于动作 - 对象类别(Tulyakov et al., 2018a)或动作图(Bar et al., 2021)控制视频生成。
- 强化学习中的应用:用于奖励生成(Escontrela et al., 2024)、预训练(Tomar et al., 2024)、模拟和规划操作(Finn and Levine, 2017; Liang et al., 2024)以及室内路径生成(Hirose et al., 2019b; Koh et al., 2021)。
- 扩散模型的应用:用于视频生成(Voleti et al., 2022)、预测(Lin et al., 2024a)和新视角合成(Chan et al., 2023; Poole et al.; Tung et al., 2025)。
- 本文的创新:本文使用条件扩散 Transformer 模拟轨迹进行规划,无需显式的 3D 表示或先验。
导航世界模型(NWM)
公式化
接下来,我们将描述我们的导航世界模型(NWM)公式化。直观上,NWM 是一个模型,它接收当前世界状态(例如图像观测)和描述如何移动以及如何旋转的导航动作。模型随后会根据代理的视角生成世界的下一个状态。

由于这个公式化的简洁性,它可以自然地跨环境共享,并且容易扩展到更复杂的动作空间,比如控制机械臂。与 Hafner 等人不同(a),我们旨在训练一个单一的世界模型,跨越不同的环境和表现形式,而不使用像 Hansen 等人那样的任务或动作嵌入。

一个可能出现的挑战是动作与时间的纠缠。例如,如果到达某个特定位置总是在某个特定时间发生,模型可能会仅仅依赖于时间,而忽略后续的动作,反之亦然。在实践中,数据可能包含自然的反事实——比如在不同的时间到达相同的区域。为了鼓励这些自然反事实,我们在训练过程中为每个状态采样多个目标。我们将在第4节进一步探讨这一方法。
Diffusion Transformer as World Model
如前所述,我们设计了作为一个随机映射,以便它能够模拟随机环境。这是通过使用条件扩散变换器(CDiT)模型来实现的,接下来将描述这一模型。
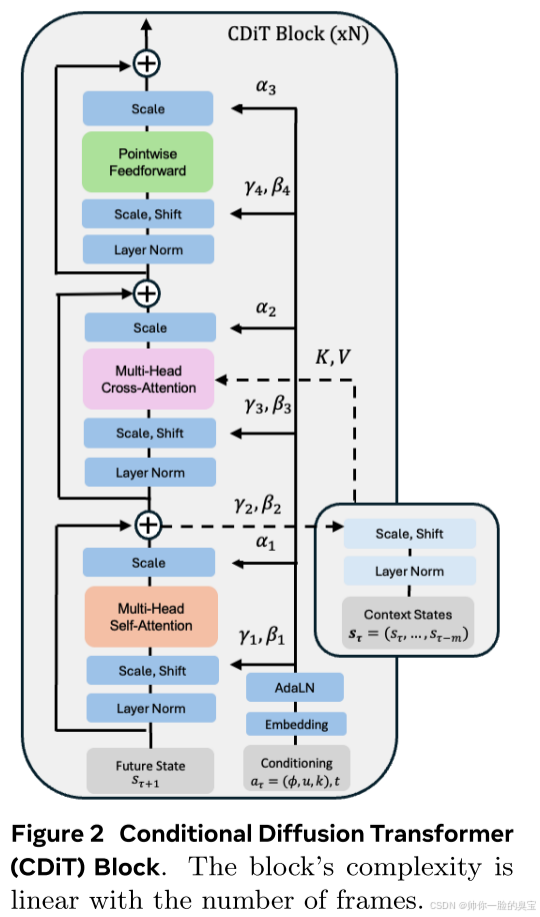
Conditional Diffusion Transformer Architecture
我们使用的架构是一个时间自回归Transformer模型,利用了高效的 CDiT 块(见图 2),该块在带有输入动作条件的潜变量序列上应用了 ×N次。
CDiT 通过仅在第一个注意力块中将注意力限制为来自目标帧的令牌,从而实现时间高效的自回归建模,该目标帧正在进行去噪处理。为了对过去帧的令牌进行条件化,我们加入了交叉注意力层,使得来自当前目标的每个查询令牌都能关注来自过去帧的令牌,这些令牌用作键和值。交叉注意力随后使用跳跃连接层来上下文化这些表示。


扩散训练

训练目标

使用世界模型进行导航规划
在这一部分,我们描述如何利用训练好的世界模型(NWM)来规划导航轨迹。直观地说,如果世界模型熟悉一个环境,我们可以使用它来模拟导航轨迹,并选择那些能够到达目标的轨迹。而在一个未知的、分布外的环境中,长期规划可能依赖于模型的“想象力”来进行推理和预测。
形式化描述

定义能量函数



















 212
212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









