






1 是什么?

2 为什么使用纹理

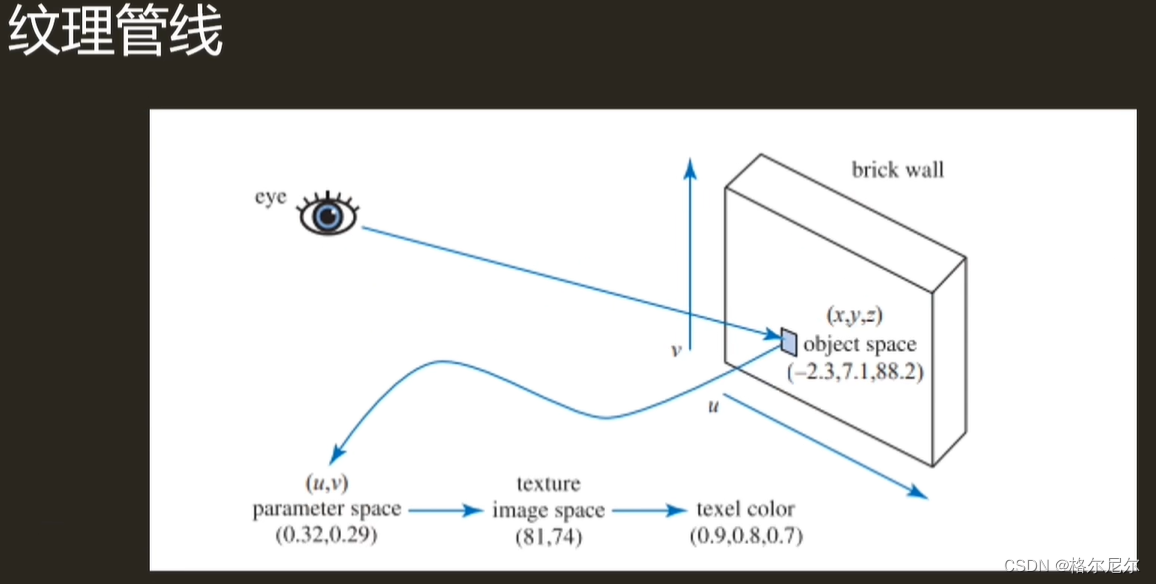
3 纹理管线
纹理投影 展开UV到UV坐标系
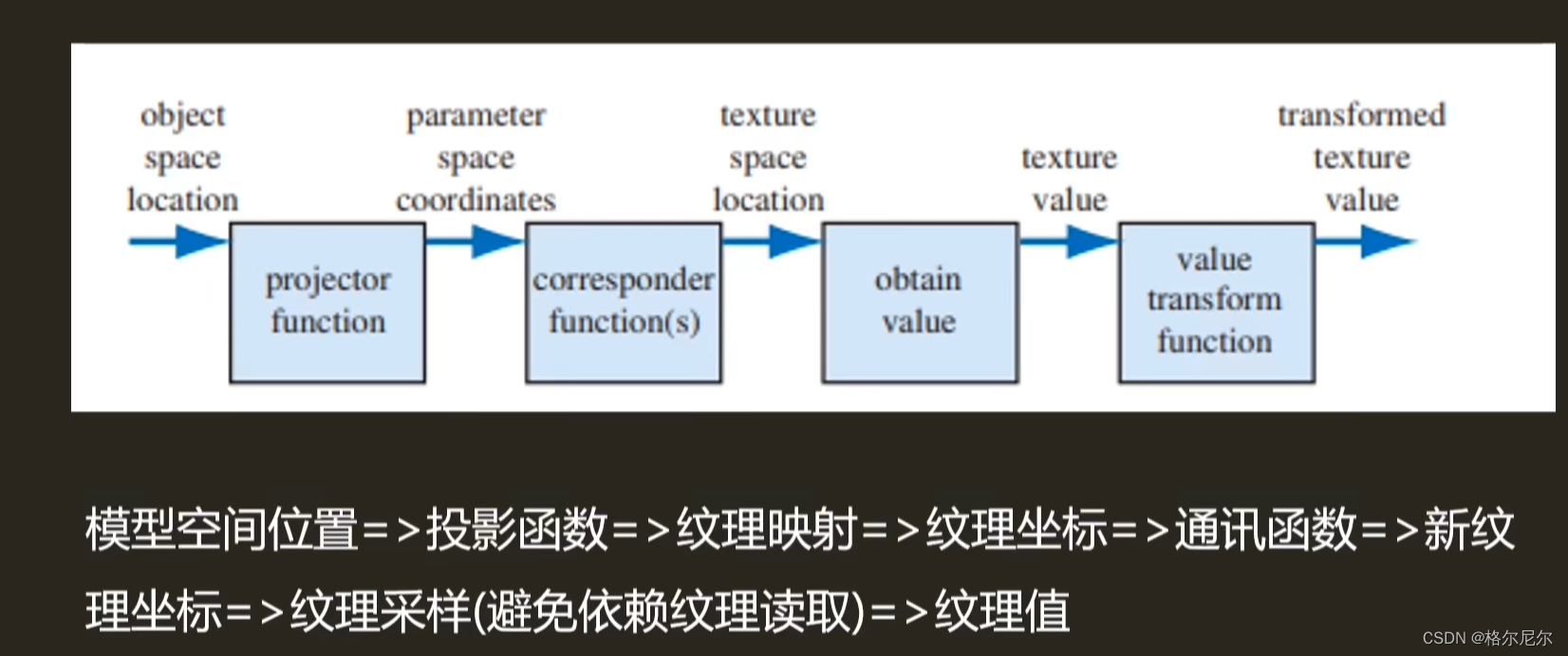
模型坐标> uv坐标 > 乘分辨率(256 256) > 颜色采样
4 纹理模式
重复,镜像重复,边界拉伸,填充颜色

5 采样模式
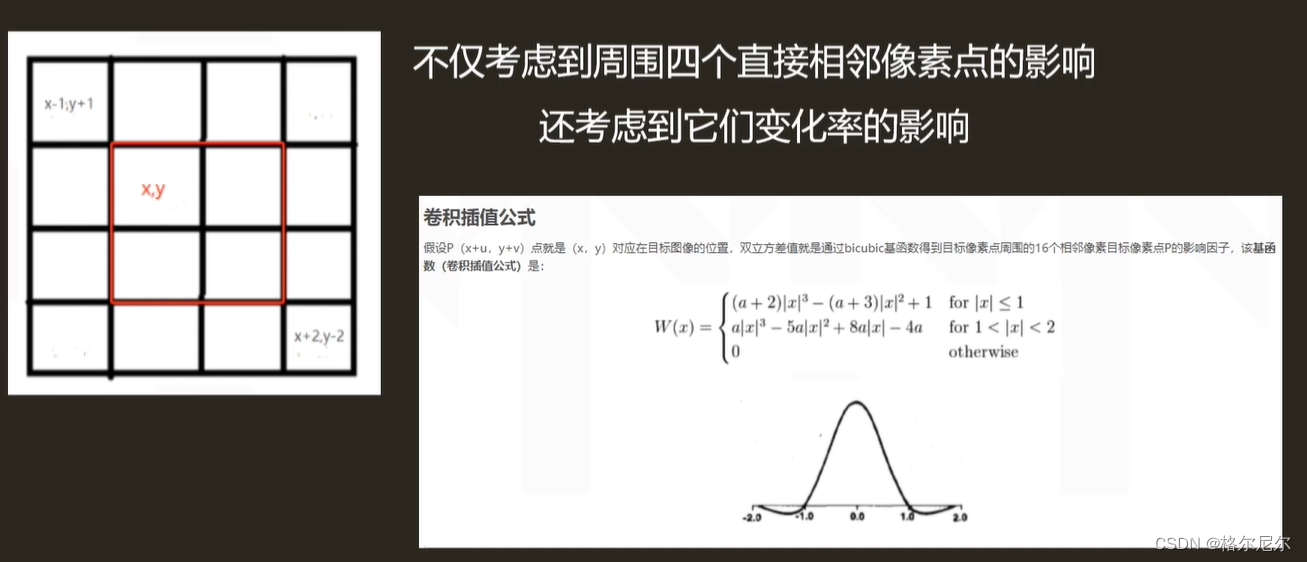
它决定了当纹理由于变换而产生拉伸时,要采用哪一种滤波(这里说的是图像处理中的滤波)模式来调整其表现,即使纹理大小完全相同的情况下,也有可能因为没有对齐或者旋转,或角度问题导致一个像素覆盖四个相邻像素的情形,因此还是需要一定程度过滤。
简单来讲,纹理过滤就是用来描述在不同形状、大小、角度和缩放比的情况下如何应用纹理。
放大过滤
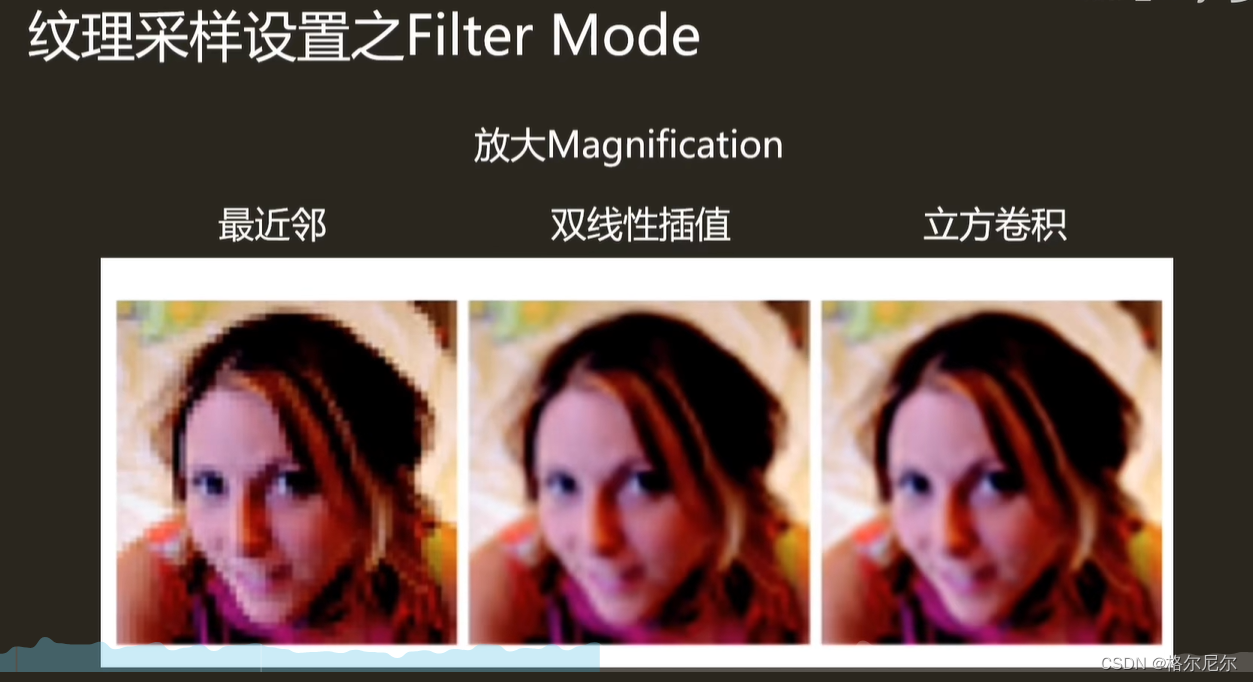
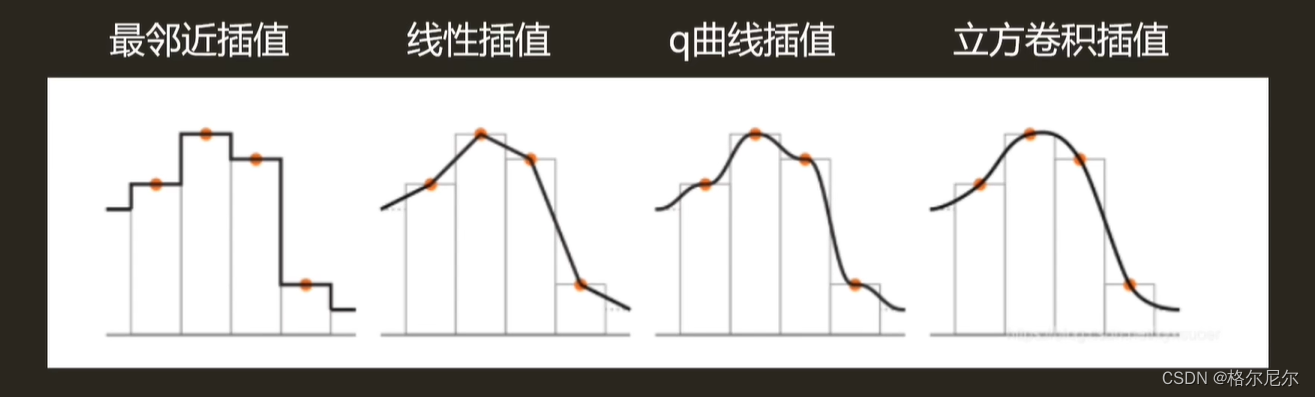
最邻近采样——直接取最邻近的像素颜色值,性能消耗最低,但是效果也最差
双线性插值——取最邻近的四个点进行插值运算,性能消耗较低,效果一般
立方卷积插值——在双线性插值的同时考虑了周围点的变化率来做运算,性能消耗较高,效果很好
Q曲线插值——在双线性插值上做了优化,属于双线性和立方卷积的折中方案
最邻近采样示意图
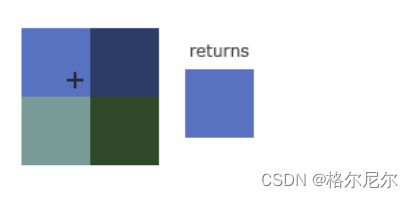
双线性插值示意图
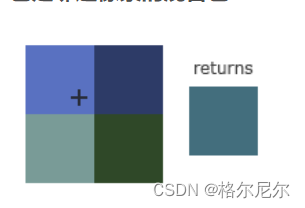

卷积插值
MipMap - 纹理过滤
想要了解为什么要使用Mipmap,首先要知道纹理过滤是什么。
当你在玩吃鸡的时候可能会发现一个现象,一个人在距离你5米的地方,可以观察到敌人的一举一动,包括身上的装备等等,但当你拿到98k时,你会蹲在远处狙击别人,这时不开镜的你看500米远处的敌人只能看到一个黑点,这其中远近看到的区别就有应用到纹理过滤。
想象一下,假设我们有一个包含着上千物体的大房间,每个物体上都有纹理。有些物体会很远,但其纹理会拥有与近处物体同样高的分辨率。由于远处的物体可能只产生很少的片段,OpenGL从高分辨率纹理中为这些片段获取正确的颜色值就很困难,因为它需要对一个跨过纹理很大部分的片段只拾取一个纹理颜色。在小物体上这会产生不真实的感觉,更不用说对它们使用高分辨率纹理浪费内存的问题了。
MipMap 叫做多级渐远纹理(Mipmap)来解决这个问题,它简单来说就是一系列的纹理图像,后一个纹理图像是前一个的二分之一。多级渐远纹理背后的理念很简单:距观察者的距离超过一定的阈值,OpenGL会使用不同的多级渐远纹理,即最适合物体的距离的那个。由于距离远,解析度不高也不会被用户注意到。同时,多级渐远纹理另一加分之处是它的性能非常好。
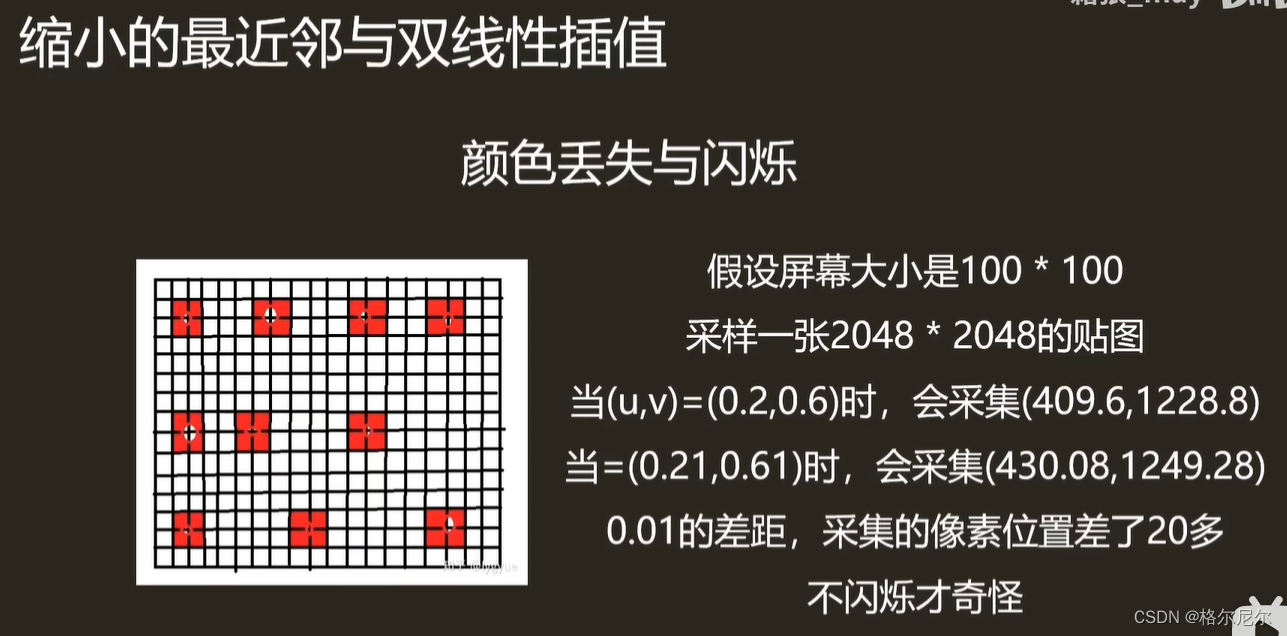
对于一般纹理来说,每个像素最多应该有一个纹理坐标来避免闪烁和丢失,所以要么就提高像素的采样频率(用较好的插值运算法),要么就降低纹理的频率,降低纹理频率最典型的方法就是 MipMap - 预处理纹理,将原始图像作为零级(level 0)底部,并将2x2的4个相邻的纹理平均值作为下一级的新纹理值,新一级的纹理是原纹理的四分之一大,不断重复,直到最后生成1x1的纹理level。这样做会使内存增大3分之一,但是可以减少带宽运算。
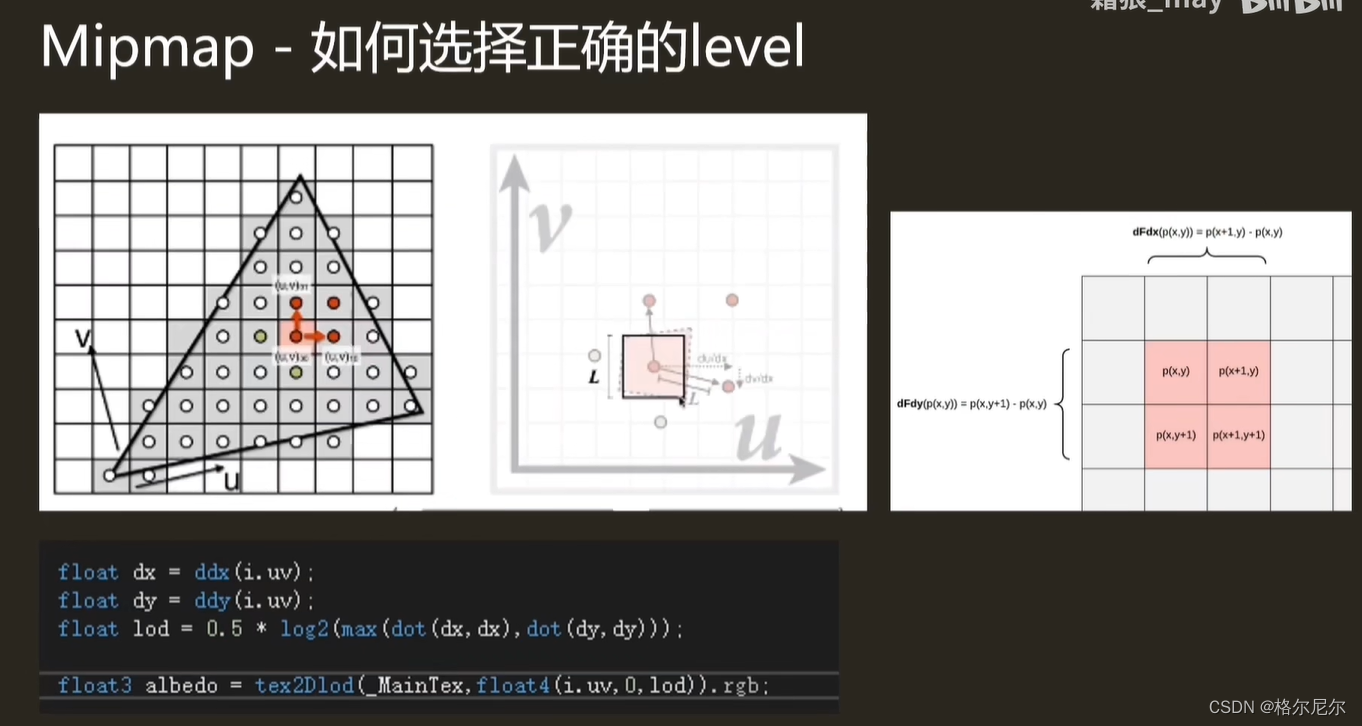


在先前讲的1颗像素需要映射2020的纹理像素时,显示效果失真,锯齿以及可能会产生摩尔纹,发生的原因是在纹理过滤时,一颗像素只采样了原本2020纹理像素里2*2纹理像素的颜色进行线性插值,得到最终的颜色,其他的396颗纹理像素无用,浪费显存且取色不精确。
Mipmap创建:预先创建原纹理大小2分之一的多级渐远纹理,在多级渐远纹理取色采样时,也会进行线性过滤,可以理解成预先创建每隔一定阈值(也就是每次映射像素为上一级别多级渐远纹理的2分之一的时候)并经过了线性过滤的纹理。
2
使用Mipmap的渲染过程:2020的像素需要映射400400的纹理像素时,检测到一颗像素需要映射到纹理像素为2020,在Mipmap纹理中里寻找最接近2020纹理像素的多级渐远纹理,并使用此多级渐远纹理进行采样。
这时采样用的多级渐远纹理的颜色也是从上一级的多级渐远纹理迭代采样插值计算而来,也就是一颗像素映射此多级渐远纹理间接插值计算了2020的纹理像素的颜色,取色的效果当然比一颗像素直接映射原图2020只采样了2*2的纹理像素颜色进行线性插值要好得多,使用Mipmap就避免了采样的纹理像素过少而失真,
五、Mipmap的优点与缺点
优点:
1.质量高:避免了在远距离情况下的采样频率低和数据频率高造成的失真和摩尔纹,效果比无Mipmap好得多。
2.性能好:避免了不使用Mipmap下距离远时采样频率低和数据频率高而照成texture cache命中率不高(相邻Pixel采样Texel时uv相差比较大)使性能下降。
缺点:
1 结果不够准确、只能用于正方形(2的幂次方)贴图,以及增加了额外的存储量(增量约为1/3)。
2 当计算出的层数恰好不是整数的时候(事实上经常会出现这种情况),同一纹理上的不同Mip之间会出现明显的断层现象,十分地不自然。
出现了这种不自然的过渡,解决办法依然是老办法:「插值」
Mipmap优点:不需要实时的累加所有影响这个像素的纹素,只需访问经过预处理的Mipmap图集,无论最后计算所得level为多少,但花费时间一样。虽然会增加包的体积的1/3但是消耗带宽较少,只需传输较小的想要的那张图即可,不需要都传;
Mipmap缺点:过度模糊,因为我们一直假设这个 Texture 在投射屏幕上是各向同性的,如果一个像素单元格在 U 上覆盖了大量的纹理,但是在 V 上覆盖了少量的纹理,也就是说在 MipMap 情况下,那些被平均过的纹理就会被限制到这些正方形中,于是就产生了各向异性过滤处理部分问题

各向异性过滤 Anisotropic Filtering
各向异性是指物质的全部或部分化学、物理等性质随着方向的改变而有所变化,在不同的方向上呈现出差异的性质。各向异性是材料和介质中常见的性质,在尺度上有很大差异,从晶体到日常生活中各种材料,再到地球介质,都具有各向异性。值得注意的是,各向异性与非均匀性是从两个不同的角度对物质进行的描述,不可等同。
当几何图形进行纹理贴图时,如果它的观察方向和观察点怡好垂直,那么这个过程是相当完整的。当我们从一个角度倾斜地观察这个几何图形时,对周围纹理单元进行常规采样,会导致一些纹理信息丟失(如下图的轨道与我们的观察视角不垂直,看上去显得模糊)。为了更加逼真和准确的采样应该沿著包含纹理的平面方向进行延伸。如果我们进行处理纹理过滤时,考虑了观察角度,那么这个过滤方法就叫“各向异性过滤”。在Mip贴图纹理过滤模型中,或者其它所有的基本纹理过滤我们都可以应用各向异性过滤。

各向异性纹理过滤(Anisotropic texture filtering) 并不是OpenGL核心规范中的一部分,但它是一种得到广泛使用的扩展,可以极大提高纹理过滤操作的质量。
1 mipmap方法解决,这里生成各个变形角度的纹理来减少变形情况,但内存是原来的三倍。
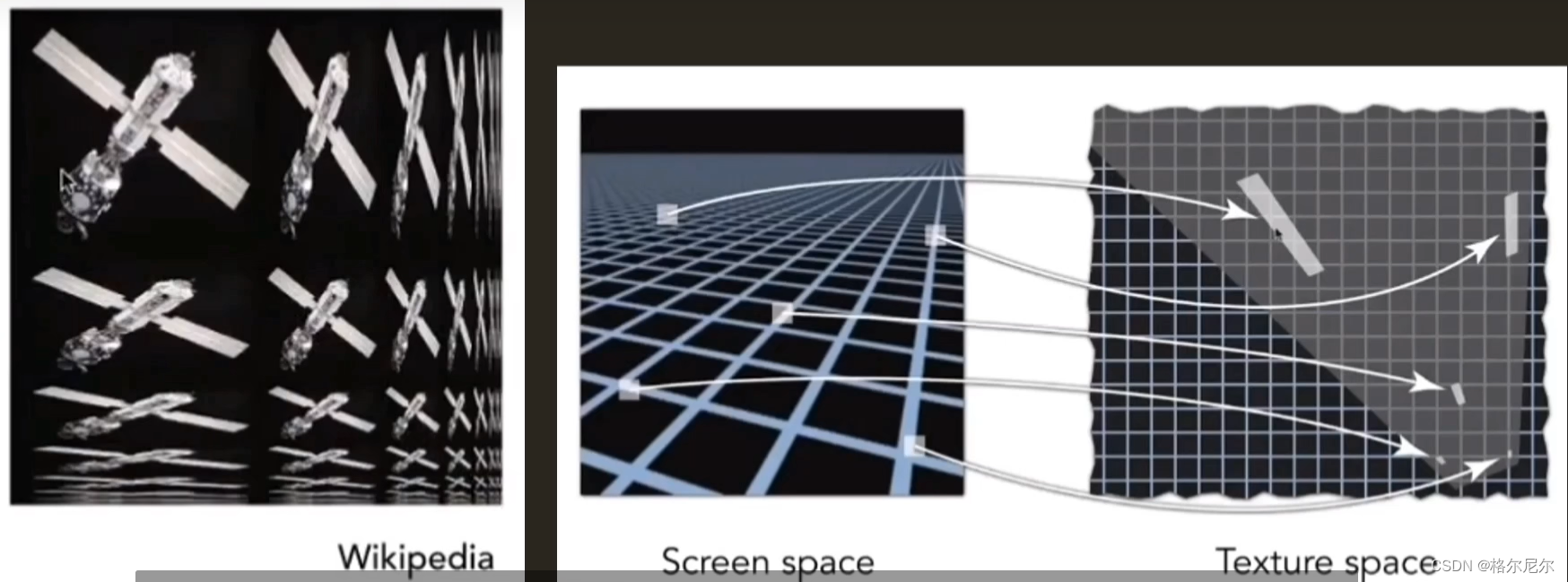
2 积分图计算方法解决
Ripmap:
它不仅仅进行了正方形的处理,是进行了各种比例的矩形预处理,以解决部分局限于正方形的问题,但也因此会生成许多额外的图,导致内存开销增大,那为什么说是部分解决?当我们沿着纹理对角线观察的时候,会出现一个很大斜角的矩形,此时即便是使用一个矩形来近似,也并不合适,因为包含了太多无关元素
RipMap 确实能比Mipmap带来更准确地结果,但是斜着的区域,同样会出现过度模糊的问题
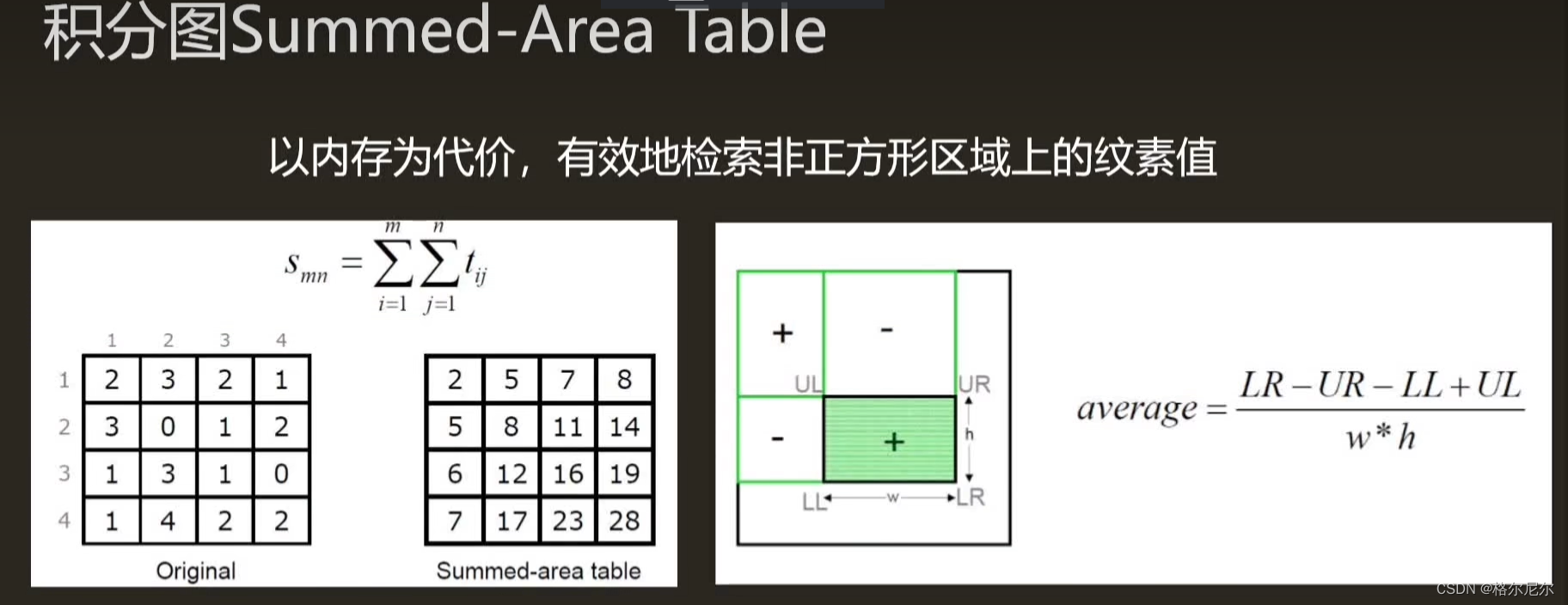
积分图Summed-Area Table
创建一个和纹理大小相同,但是储存颜色精度更高的数组,在数组的每个位置,以左上为元素的原点,每一个位置计算并储存这个位置和纹素原点所形成的的矩形所对应的所有的纹素的总和。
- 为什么在Unity/UE4里,开启各向异性过滤后,纹理内存并不是同理论般的3倍,而是1/3?
各向异性过滤是总称,Ripmap只是其中一种,如果任何一张纹理使用 RipMap 都会扩大纹理内存3倍,在实际项目中是用不起的。
对于现在的优化方法,重用Mipmap,将屏幕像素反向投影到纹理空间,根据方块的最短边确定level,较长的边则创建一条各向异性的线穿过方块中心,按照过滤等级的高低,沿着这条线进行多次的采样并合成,得到最终采样的结果。
总结下:因为其实它整套仍是用的还是Mipmap的算法;
纹理优化
1.CPU和GPU并行工作的原理
为了CPU和GPU可以并行工作,就需要一个命令缓冲区(Command Buffer)
命令缓冲区包含了一个命令队列,由CPU向其中添加命令,而由GPU从中读取命令。添加和读取的过程是相互独立的,因此命令缓冲区可以使CPU和GPU相互独立工作。当CPU需要渲染一些对象时,它可以向命令缓冲区添加命令,而GPU完成了上一次的渲染任务后,它就可以从命令队列里取出一个命令并执行它。
命令缓冲区中的命令有很多种类,而Draw Call是其中的一种,其它命令还有改变渲染状态等命令(改变使用的Shader,使用不同的纹理等)。
2.为什么 Draw Call多了会影响帧率?
在每次调用Draw Call之前,CPU需要向GPU发送很多内容,包括数据,状态,命令等。在这一阶段,CPU需要完成很多工作,例如检查渲染状态等。而一旦CPU完成了这些准备工作,GPU就可以开始本次的渲染。GPU的渲染能力是很强的,渲染300个和3000个三角网格通常没有什么区别,因此渲染速度往往快于CPU提交命令的速度。如果Draw Call的数量太多,CPU就会把大量时间花费在提交Draw Call命令上,造成CPU的过载。因此造成Draw Call性能问题的元凶是CPU。
3.如何减少DrawCall?
提交大量很小的Draw Call会造成CPU的性能瓶颈,即CPU把时间都花费在准备Draw Call的工作上了。那么,一个很显然的优化想法就是把很多小的Draw Call合并成一个大的Draw Call,这就是批处理的思想。
需要注意的是,由于我们需要在CPU的内存中合并网格,而合并的过程是需要消耗时间的。因此,批处理更适合静态的物体,例如不会移动的大地,石头等,对于这些静态物体我们只需合并一次即可。当然,我们也可以对动态物体进行批处理。但是,由于这些物体是不断运动的,因此每一帧都需要重新进行合并然后再发送给GPU,这对空间和时间都会造成一定的影响。

纹理优化方法:压缩为小文件格式,受限与gpu带宽

Cubmap
面选取根据最大的方向数值决定

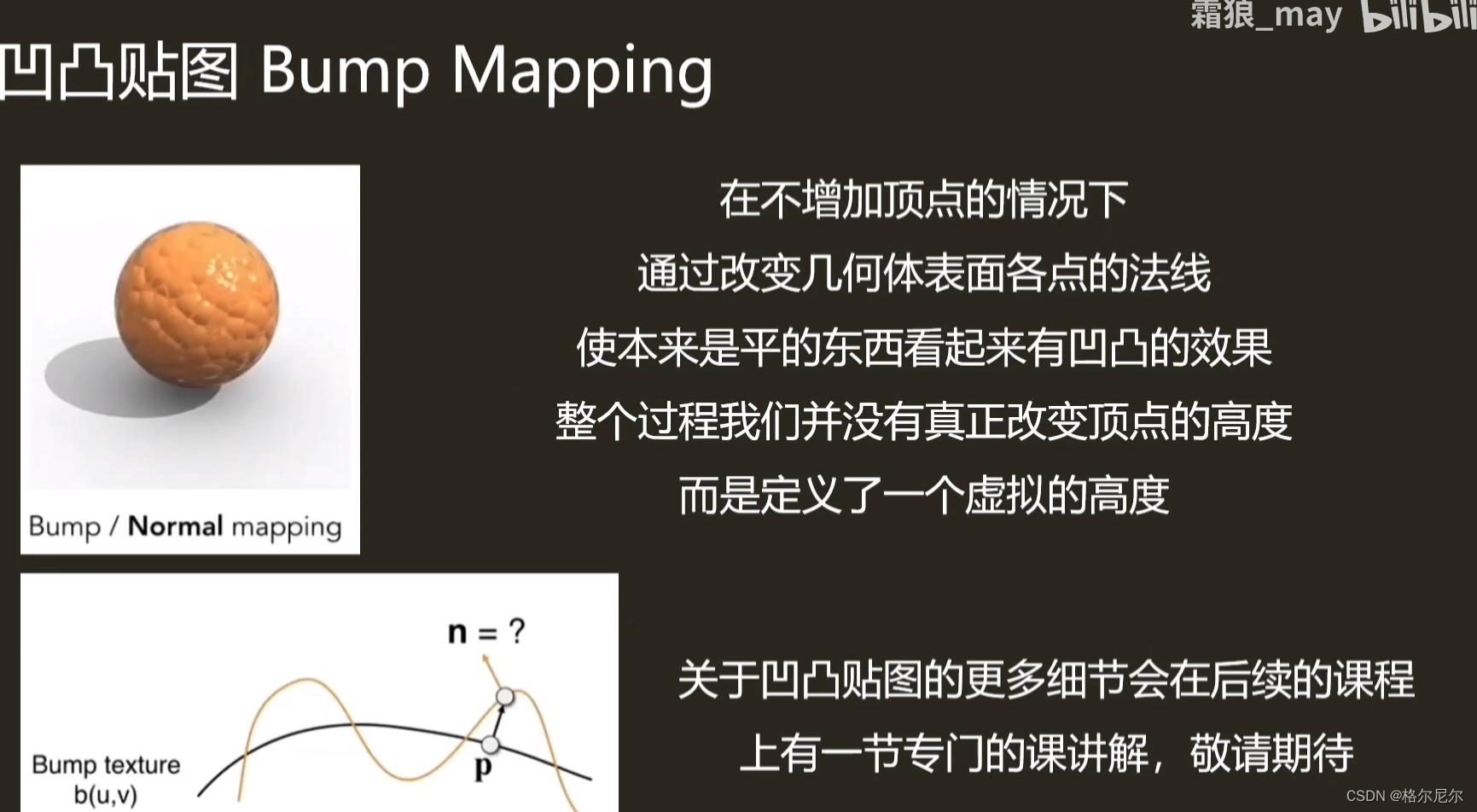
凹凸纹理















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









