







这个是课程设计做的项目 刨除了前端部分
逻辑过程如下
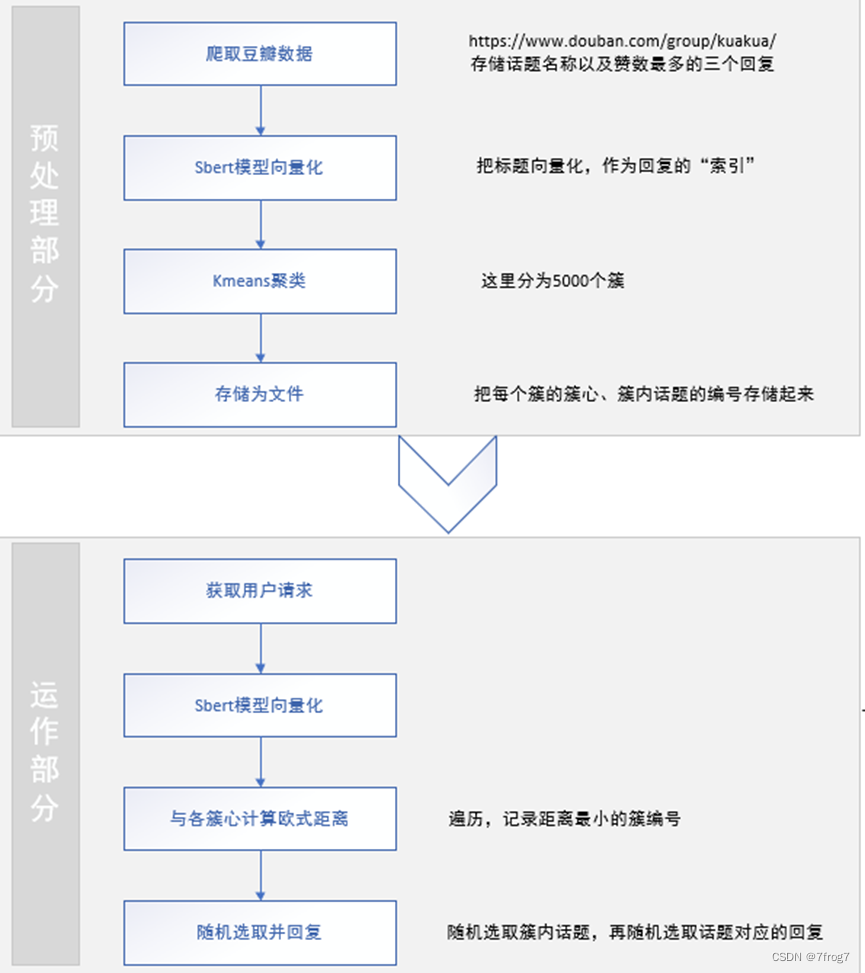
1.爬取话题和网址
豆瓣话题的页面非常友好 start后面的数字就是开始的条数
需要用cookie来访问
获取cookie的方法
在豆瓣的首页刷新一次 复制cookie
import random
import re
import time
import requests
from lxml import etree
writeurl = open('url_path.txt','w',encoding='utf-16')
writecontent = open('content.txt','w',encoding='utf-16')
cookie = [] #这里要去复制cookie 最好多几个
class spider:
def __init__(self):
self.contenturl = 'https://www.douban.com/group/kuakua/discussion?start='
self.url_list = []
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 OPR/66.0.3515.115'}
def run(self,pages):
#url_collector
for i in range(0,pages):
page_url = self.contenturl + str(i*25)
cookie_random = random.randint(0,1)#根据数量改上限
sleep_time = random.randint(1,4)
get_page = requests.get(page_url,headers=self.headers,cookies=cookie[cookie_random])
get_page = get_page.content.decode()
toTree = etree.HTML(get_page)
first_step = toTree.xpath('//td[@class="title"]/a//text()')
urls = toTree.xpath('//td[@class="title"]/a//@href')
#print(urls)
lenf = len(first_step)
for i in range(0,lenf):
writeurl.write(urls[i])
writeurl.write('\n')
solution = first_step[i]
solution = solution.replace('\n','')
solution = solution.split()
writecontent.writelines(solution)
writecontent.write('\n')
time.sleep(sleep_time)
#print(first_step)
newspd = spider()
newspd.run(2000)
tips:
在pycharm上跑了好久才被封 用自己的服务器往往要不了几分钟就会被禁 很有趣
如果不急的话可以把时间频率调长些
2.把对应网址里的答案取出来
'''
urlread = open('url_path.txt','r',encoding='utf-16')
titleread = open('content.txt','r',encoding='utf-16')
url_list = str(urlread).split('\n')
title_list = str(titleread).split('\n')
for items in title_list:
'''
import logging
import random
import requests
from lxml import etree
import time
cookie = []
urlread = open('url_path.txt','r',encoding='utf-16')
class solver:
def __init__(self):
self.url_list = []
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.52'}#换了个头
def run(self):
while True:
weburl = urlread.readline()[:-1]
#print(weburl)
if not weburl:
break
contentwrite = open('ans_content.txt', 'a', encoding='utf-16')
get_page = requests.get(weburl, headers=self.headers, cookies=cookie[1])
print(get_page)#监控状态 如果连续4xx基本上就是被ban了
get_page = get_page.content.decode()
toTree = etree.HTML(get_page)
first_step = toTree.xpath('//div[@class="reply-doc content"]/p/text()')
lenf = len(first_step)
#选取包括人气回答的前3个回答
ans_list = []
if lenf > 3:
ans_list = first_step[:3]
else:
ans_list = first_step
writestr = ''
for items in ans_list:
writestr += items + '##'
writestr += '\n'
contentwrite.write(writestr)
sleeptime = random.randint(1,4)
time.sleep(sleeptime)
contentwrite.close()
solver = solver()
solver.run()
处理答案
import random
reading = open('ans_content.txt','r',encoding='utf-16')
writring1 = open('ans_content_1.txt','w',encoding='utf-16')
anslist = []
entity = ""
while True:
rdln = reading.readline()
if not rdln:
break
if rdln[-3:] == '*&\n':
entity += rdln
anslist.append(entity)
writring1.write(entity)
entity = ""
else:
entity += rdln[:-1]
3.标题聚类处理
这一步可以用来降低查找答案的复杂度
先找到距离最近的簇心 再选出一簇中最适合的问题 random一个回答
这里用了一个macbert模型 也可以使用自己fine-tune的
import gensim
from sentence_transformers import SentenceTransformer, util
import re
from sklearn.cluster import KMeans
import matplotlib
import torch
device = torch.device("cpu")
embedder = SentenceTransformer('/home/QAQ/NLP-Series-sentence-embeddings/output/sts-sbert-macbert-64-2022-03-05_10-23-37',device=device)
file = open('content.txt', encoding='utf-16')
fstr = []
sentence = []
while True:
rd = file.readline()
if not rd:
break
sentence.append(rd)
flen = len(fstr)
word_embedding = {}
sentences = []
words = {}
count = 1
sentences_map = {}
for items in sentence:
items = re.findall(r'[\u4e00-\u9fa5]',items)#筛选出汉字
str1 = ''
for itemss in items:
str1 += itemss
sentences.append(str1)
sentences_map[str1] = count
count += 1
corpus_embeddings = embedder.encode(sentences)
num_clusters = 1000
clustering_model = KMeans(n_clusters=num_clusters)
clustering_model.fit(corpus_embeddings)
print('fit')
cluster_assignment = clustering_model.labels_
clustered_sentences = [[] for i in range(num_clusters)]
for sentence_id, cluster_id in enumerate(cluster_assignment):
clustered_sentences[cluster_id].append(sentences[sentence_id])
print('done')
for i, cluster in enumerate(clustered_sentences):
print("Cluster ", i+1)
print(cluster)
print("")
聚类的结果还是比较理想的
分成了1000簇




也可以大致对比查看聚类的效果 UPD:建议用gpu节省时间
import gensim
from sentence_transformers import SentenceTransformer, util
import re
from sklearn.cluster import KMeans
import matplotlib
import torch
import numpy
device = torch.device("cpu") # torch.device("cuda")
embedder = SentenceTransformer('chinese_macbert_base',device=device)
file = open('content.txt', encoding='utf-16')
fstr = []
sentence = []
while True:
rd = file.readline()
if not rd:
break
sentence.append(rd)
flen = len(fstr)
OMP_NUM_THREADS=3 #解除内存限制
word_embedding = {}
sentences = []
words = {}
count = 1
sentences_map = {}
for items in sentence:
items = re.findall(r'[\u4e00-\u9fa5]',items)
str1 = ''
for itemss in items:
str1 += itemss
sentences.append(str1)
sentences_map[str1] = count
count += 1
corpus_embeddings = embedder.encode(sentences)
lenc = len(corpus_embeddings)
print('encoded')
num_clusters = [100,300,500,700,900,1000]
for num_cluster in num_clusters:
clustering_model = KMeans(n_clusters=num_cluster)
clustering_model.fit(corpus_embeddings)
print('fit')
cluster_assignment = clustering_model.labels_
cluster_centre = clustering_model.cluster_centers_
clustered_sentences = [[] for i in range(num_cluster)]
overall_distance = 0.
for sentence_id, cluster_id in enumerate(cluster_assignment):
clustered_sentences[cluster_id].append(sentences[sentence_id])
print('done')
for i, cluster in enumerate(clustered_sentences):
strf="cluster"+str(num_cluster)+"//Cluster"+str(i+1)+".txt"
writing = open(strf,'w+',encoding='utf-16')
writing.write(str(cluster_centre[i]))
writing.write('\n')
cluster = str(cluster)
writing.write(cluster)
writing.close()
distance = 0.
for i in range(0,lenc):
distance+=numpy.linalg.norm(corpus_embeddings[i]-cluster_centre[cluster_assignment[i]])
writing=open('result.txt','a')
writing.write(str(num_cluster)+" distance:"+str(distance)+'\n')
writing.close()
4.服务部分
import random
from flask import *
import numpy
from sentence_transformers import SentenceTransformer, util
import json
import numpy as np
import torch
import requests
import hashlib
device = torch.device("cpu")
embedder = SentenceTransformer('chinese_macbert_base',device=device)
NUM_CLUSTERS = 5000
MATRIX_LINES = 192
ans_sentence = []
ans_reading = open("ans_content_1.txt",'r',encoding='utf-16')
while True:
rd = ans_reading.readline()
if not rd:
break
rd = rd.split('##')
ans_sentence.append(rd)
center_matrix = []#装载簇心的矩阵
ans_list = []
banlist = []
for i in range(1,NUM_CLUSTERS+1):
vec_dims = 0
openstr = 'cluster5000a/'+'cluster'+str(i)+'.txt'
#print(openstr)
reading = open(openstr,'r',encoding='utf-16')
get_matrix = np.array([])
for j in range(1,MATRIX_LINES+1):
rdln = reading.readline()
if rdln[0] == '[':
rdln = rdln[1:]
if rdln[-2] == ']':
rdln = rdln[:-2]
rdln = rdln.split()
vec_dims += len(rdln)
for items in rdln:
get_matrix = numpy.append(get_matrix,float(items))
get_matrix = get_matrix.reshape(1,-1)
if vec_dims == 768:
break
center_matrix.append(get_matrix)
tosolve = ""
while True:
rdln = reading.readline()
if not rdln:
break
tosolve += rdln
tosolve = tosolve[1:-1]
tosolve = tosolve.split(',')
#print(len(tosolve))
# if len(tosolve)<=5:
# #print(i)
# banlist.append(i-1)
# print(banlist)
ans_list.append(tosolve)
reading.close()
print("done")
#375 3
import time
app = Flask(import_name=__name__)
@app.route("/getans",methods=['POST'])
def getans():
PEDIAFLAG = False
WEATHFLAG = False
TRANSFLAG = False
data1 = request.get_data(as_text=True)
print(data1)
data = json.loads(request.get_data(as_text=True))
sentence = data['text']
#sentence = re.findall(r'[\u4e00-\u9fa5]',sentence)
empty_str = ""
for items in sentence:
empty_str += items
sentence = empty_str
ptr = -1
for j,items in enumerate(sentence):
if items == '\u662f': #是
ptr = j
keystr = empty_str[:ptr]
sentence = embedder.encode(sentence)
sentence.astype('float32')
cluster_choice = -1
cluster_distance = 114514
for i in range(0,NUM_CLUSTERS):
distance = np.linalg.norm(sentence-center_matrix[i])
if cluster_choice == -1:
cluster_choice = i
cluster_distance = distance
else:
if cluster_distance > distance:
cluster_distance = distance
cluster_choice = i
# print(cluster_choice)
# print(ans_list[cluster_choice])
ans = []
lenx = len(ans_list[cluster_choice])
optflag = False
for i in range(0,lenx):
rand_ans_list = random.randint(0,lenx-1)
lenr = len(ans_sentence[(int)(ans_list[cluster_choice][rand_ans_list])])
if lenr == 1:
continue
else:
rand_ans_num = random.randint(0,lenr-2)
return ans_sentence[(int)(ans_list[cluster_choice][rand_ans_list])][rand_ans_num]
if not optflag:
return "加油哦"
app.run(host = "0.0.0.0",port=8888,debug = False)
做计算的速度比较理想,因此响应时间很短。作为练手的项目感觉还不错















 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









