






前言: 这是2022年第一个关于YOLO的改版,该版本由百度提出,称之为YOLOE,是目前各项指标sota的工业目检测器,性能sota且部署相对友好。
该检测器的设计机制包括:
- Anchor free无锚盒机制
- 可扩展的backbone和neck,由CSPRepResStage(CSPNet+RMNet)构成
- 使用Varifocal Loss(VFL)和Distribution focal loss(DFL)的头部机制ET-head
- 动态标签分配算法Task Alignment Learning(TAL)
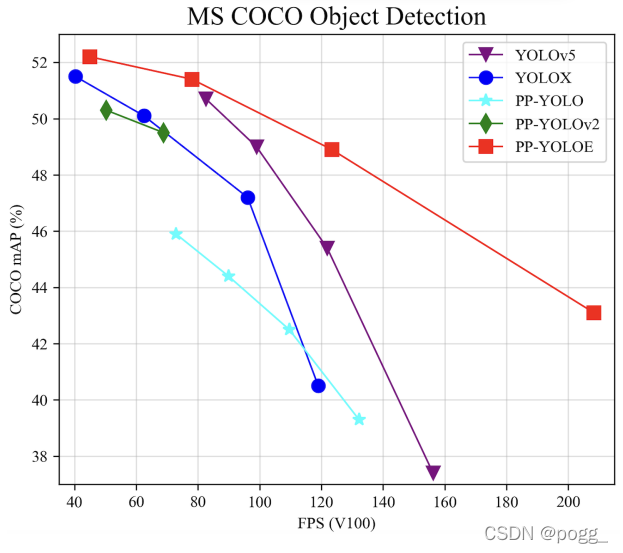
该团队提供了s/m/l/x模型,YOLOE-l在COCO-Test中mAP达到51.1,在V100上可达71.1FPS,相对于YOLOX-l加速24.96%,mAP提高1.0,使用trt fp16进行推理可达149FPS.
论文地址: https://arxiv.org/pdf/2203.16250.pdf
代码已开源: https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/ppyoloe
1、介绍
目前YOLOX以50.1达到了速度和精度的最佳平衡,V100上测试可达68FPS,是当前YOLO系列网络的集大成者,YOLOX引入了先进的动态标签分配方法,在精度方面显著优于YOLOv5,受到YOLOX的启发,作者进一步优化了之前的工作PP-YOLOv2。在PP-YOLOv2的基础上提出YOLOE,该检测器避免使用deformable convolution和matrix nms等运算操作,能在各种硬件上得到很好的支持。
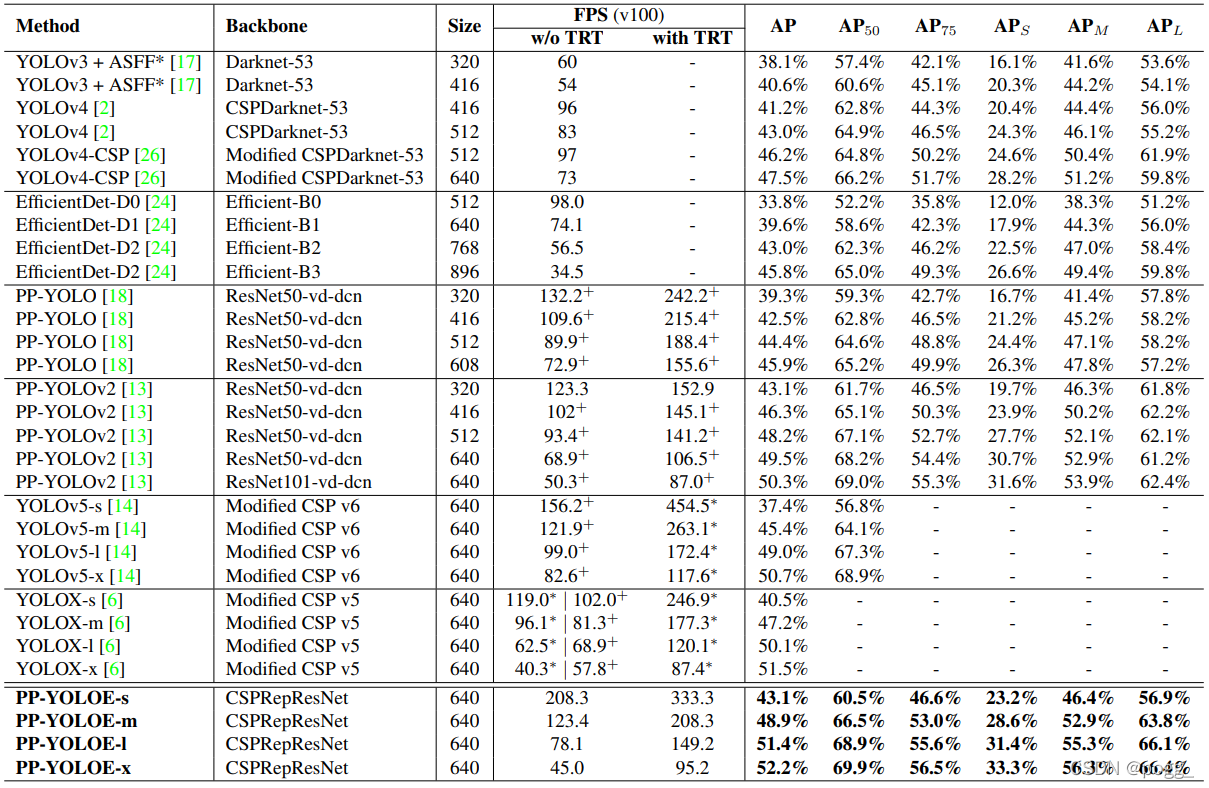
YOLOE在速度和准确性权衡方面优于YOLOv5和YOLOX。 在640 × 640的分辨率下,YOLOE-l 达到 51.4 mAP,78.1 FPS:
- 以1.9% AP高于 PP-YOLOv2,
- 以1.0% AP高于YOLOX-l(截止2月31日YOLOX官网的精度)
- 以2.3% AP高于 YOLOv5-l(截止2月31日YOLOv5官网的精度)
YOLOE借鉴YOLOv5,采用width multiplier和depth multiplier的方式配置,支持TensorRT和ONNX,部署代码开源在PaddleDetection。
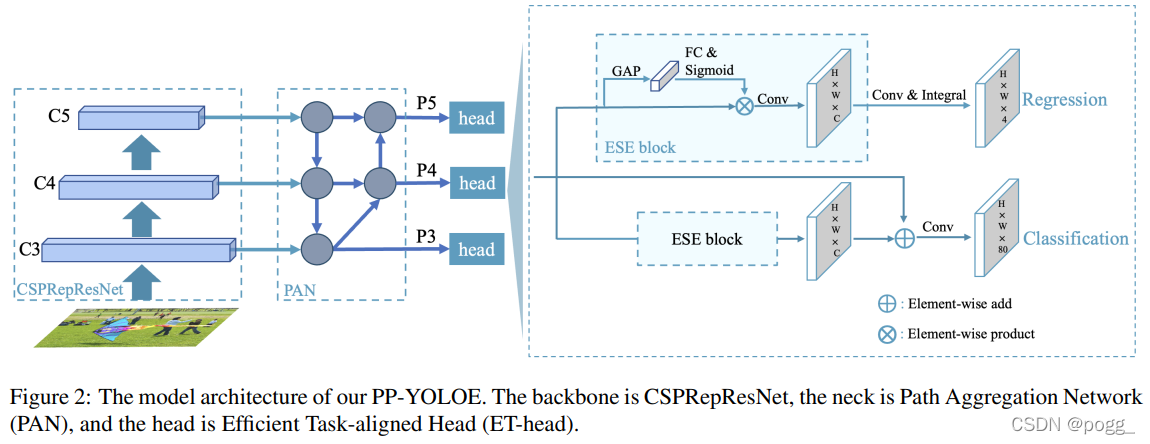
YOLOE网络结构:
2、 方法
Anchor-free. YOLOE借鉴FCOS,在每个像素上放置一个锚点,为三个检测头设置上、下边界,将 ground truths分配给相应的特征图。然后,计算 bounding box的中心位置,选择最近的像素点作为正样本。这种方式使模型更快一些,但损失了0.3 AP。
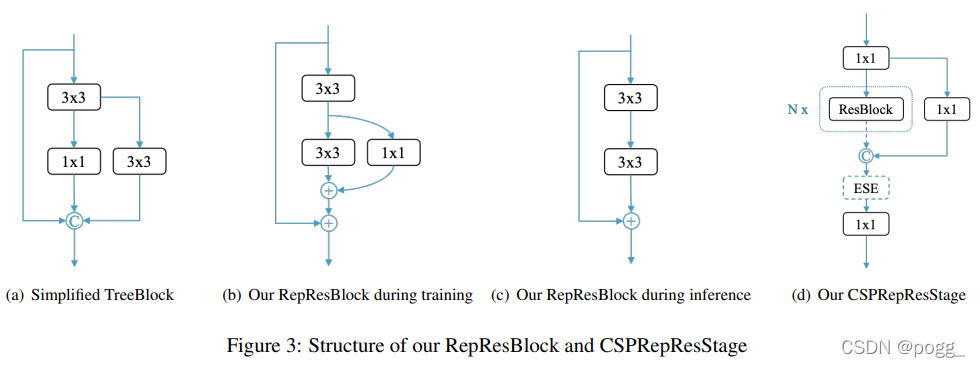
Backbone and Neck. Residual Connections和Dense Connections在现代卷积神经网络中得到了广泛的应用。Residual connections引入了捷径来缓解梯度消失问题,也可以作为一种模型集成方法。Dense Connections聚集了具有不同接受域的中间特征,在目标检测任务中表现出良好的性能。CSPNet利用跨阶段Dense Connections来降低计算负担,在不损失精度的情况下降低计算负担,这种方式在YOLOv4、YOLOv5上被使用,且证明是有效的。受这些工作的启发,作者提出了一种新的RepRes-Block,通过结合Residual Connections和Dense Connections,用于YOLOE的主干和颈部。但作者简化了原始的Block(图3(a))。使用 element-wise Add操作来替换连接操作(图3(b)),这两个操作在某种程度上近似于RMNet。因此,在推理阶段,可以重新参数化为RepResBlock(图3©)。作者使用RepResBlock构建类似于ResNet的网络,称之为CSPRepResNet(图3(d),ESE制SE注意力模块)。
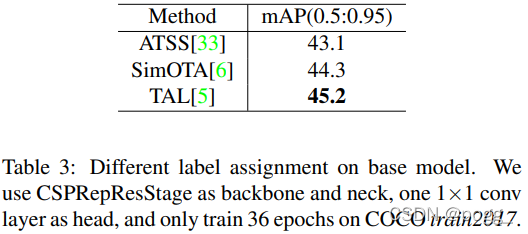
Task Alignment Learning (TAL). 标签分配是一个重要的问题。YOLOX使用SimOTA作为标签分配策略来提高性能。然而,为了进一步克服分类和定位的错位,在TOOD中提出了Task Alignment Learning,该策略由 dynamic label assignment和task aligned loss组成。通过对齐这两个任务,TAL可以同时获得最高的分类分数和最精确的边界框。
对于task aligned loss,TOOD使用标准化 t t t,即 t ⃗ \vec t t,以替换损失中的目标。它采用每个实例内最大的IoU作为规范化。该分类的二进制交叉熵(BCE)可以重写为:
L c l s − p o s = ∑ i = 1 N p o s B C E ( p i , t ⃗ i ) L_{cls-pos}=\displaystyle\sum_{i=1}^{N_{pos}}BCE(p_i, \vec t_i) Lcls−pos=i=1∑NposBCE(pi,ti)
Efficient Task-aligned Head (ET-Head). 在目标检测中,分类和定位之间的任务冲突是一个众所周知的问题。YOLOX的解耦头从单级和两级探测器中吸取了教训,并成功地应用于YOLO模型。然而,解耦头可能会使分类和定位任务独立,缺乏任务特定学习。基于TOOD,作者改进了头部,并提出了ET-Head,目标是为了更快更准。如图2所示,作者使用ESE替换TOOD中的层注意力模块,将分类分支的对齐简化,将回归分支替换为Distribution
Focal Loss(DFL)层。通过上述实验,ET-Head在V100上增加了0.9ms。
对于分类任务和定位任务的学习,作者分别选择了Varifocal Loss(VFL)和Distribution focal loss(DFL)。PP-Picodet成功地将VFL和DFL应用于目标探测器中,并获得了性能的提高。VFL与中的Quality Focal Loss(QFL)不同,VFL使用目标评分来衡量正样本的损失权重。
这种实现使得具有高IoU的正样本对损失的贡献相对较大。这也使得模型在训练时更注重高质量的样本,而不是那些低质量的样本。并且两者都用IoU感知的分类评分(IACS)作为预测的目标,这可以有效地得到classification score和localization quality estimation的联合表示,使训练和推理之间具有高度的一致性。
为了解决Bounding Box表示不灵活的问题,作者提出使用一般分布来预测Bounding Box。
L
o
s
s
=
α
.
l
o
s
s
V
F
L
+
β
.
l
o
s
s
G
I
o
U
+
γ
.
l
o
s
s
D
F
L
∑
i
=
1
N
p
o
s
t
⃗
i
Loss=\frac{\alpha.loss_{VFL}+\beta.loss_{GIoU}+\gamma.loss_{DFL}}{\displaystyle\sum_{i=1}^{N_{pos}}\vec t_i}
Loss=i=1∑Npostiα.lossVFL+β.lossGIoU+γ.lossDFL
t ⃗ \vec t t表示归一化的目标得分,ET-Head获得了0.5%的AP提升。
总体实验的效果如下,以PP-YOLOv2作为Baseline:
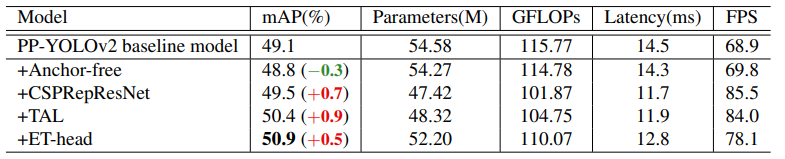
3、性能
YOLOE在COCO 2017 test-dev上与不同检测器的速性能比较。 标有“+”的结果是相应官方发布的最新结果。 标有“*”是在作者的环境中使用官方代码库和模型进行测试的结果。 速度的默认精度是 FP32(不带 trt)和 FP16(带 trt)。
4、总结
YOLOE共涉及到了几项改进:
- Anchor free无锚盒机制
- 可扩展的backbone和neck,由CSPRepResStage(CSPNet+RMNet)构成
- 使用Varifocal Loss(VFL)和Distribution focal loss(DFL)的头部机制ET-head
- 动态标签分配算法Task Alignment Learning(TAL)
以YOLOE-l为基准,所取得的的效果:
- 以1.9% AP高于 PP-YOLOv2,
- 以1.0% AP高于YOLOX-l(截止2月31日YOLOX官网的精度)
- 以2.3% AP高于 YOLOv5-l(截止2月31日YOLOv5官网的精度)
YOLOE-X在640分辨率下mAP达到52.2%
- 以0.7% AP高于YOLOX-X(截止2月31日YOLOX官网的精度)
- 以1.5% AP高于 YOLOv5-X(截止2月31日YOLOv5官网的精度)

















 3091
3091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









