







文章目录
梯度消失\梯度爆炸(Vanishing/exploding gradients)
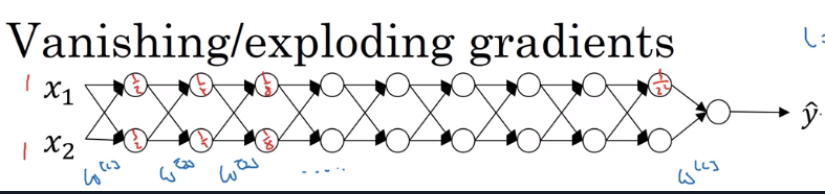
对于一个深层神经网络,其层数是非常多的.

即使我们设置的初始权重矩阵的值是接近于1的,但经过一个深层的网络计算后值都会呈指数级下降或增大
vanishing gradient和 exploding gradient当然不仅仅只是RNN的问题,在许多深层神经网络中都存在这个问题,只要层数L很深,那么输出的前一层的值都可能算出来是很大或者很小的,那么如果其算出来的梯度就很大,随着反向传播,梯度呈指数级增加,就会出现gradient exploding的问题,而如果其算出来很小,(小于1比较多),随着层数的加深,梯度会越来越小越来越小,导致整个优化难以进行。
神经网络的权重初始化的方法(解决梯度消失和梯度爆炸的问题)

对 于 深 层 神 经 网 络 , 我 们 想 到 的 就 是 让 初 始 化 权 重 矩 阵 W [ L ] 变 得 更 小 一 点 , 于 是 我 们 想 到 了 让 对于深层神经网络,我们想到的就是让初始化权重矩阵W^{[L]}变得更小一点,于是我们想到了让 对于深层神经网络,我们想到的就是让初始化权重矩阵W[L]变得更小一点,于是我们想到了让
其 乘 以 2 / n , 所 以 公 式 体 现 出 来 就 是 下 面 这 个 样 子 : 其乘以2/n,所以公式体现出来就是下面这个样子: 其乘以2/n,所以公式体现出来就是下面这个样子:
ω [ l ] = n p . r a n d o m . r a n d n ( s h a p e ) ∗ n p . s q r t ( 2 n [ l − 1 ] ) \omega^{[l]}=np.random.randn(shape)*np.sqrt(\frac{2}{n^{[l-1]}}) ω[l]=np.random.randn(shape)∗np.sqrt(n[l−1]2)
这是针对Relu激活函数的
而对于Tanh激活函数 一般使用
ω [ l ] = n p . r a n d o m . r a n d n ( s h a p e ) ∗ n p . s q r t ( 1 n [ l − 1 ] ) \omega^{[l]}=np.random.randn(shape)*np.sqrt(\frac{1}{n^{[l-1]}}) ω[l]=np.random.randn(shape)∗np.sqrt(n[l−1]1)
经过这样的初始化处理后,我们就能使得w权重矩阵控制在一个合理的值,同时z算出来就不会是一个很大的值,从而避免了梯度消失/爆炸的可能性.
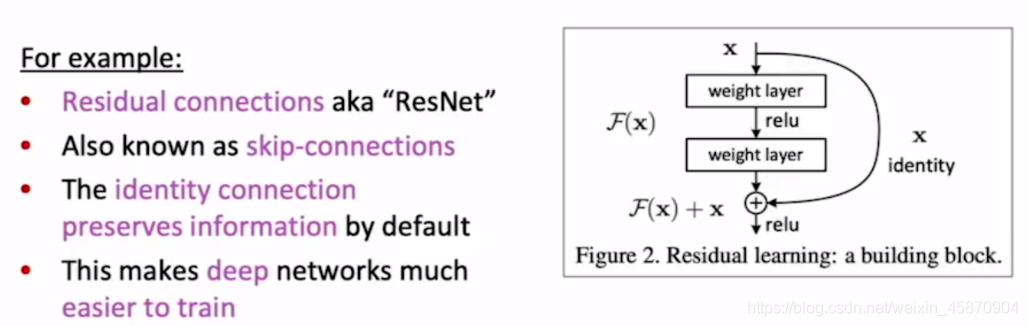
用shortcut connection的方法解决这个问题
vanishing 和 exploding gradients一个直观的体现方式就是反向传播的时候,即使你第一个梯度接近于1,或者说第一个梯度因为前面的计算,W已经变得很小,那么再经过链式法则,整个就会变得更小,从很难以去学习,所以从前面加short cut connection是一个增加层数较深的层的梯度的不错的解决方案。
例如 Resnet 解决了CNN不能太深的问题:

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









