







-
Auto-TS 自动化时间序列预测
1、Auto-TS介绍
Auto-TS 是 AutoML 的一部分,它将自动化机器学习管道的一些组件。这自动化库有助于非专家训练基本的机器学习模型。
是一个开源 Python 库,主要用于自动化时间序列预测。它将使用一行代码自动训练多个时间序列模型,这将帮助我们为我们的问题陈述选择最好的模型。
Auto_TimeSeries 能够帮助我们使用 ARIMA、SARIMAX、VAR、可分解(趋势+季节性+残差)模型和集成机器学习模型等技术构建和选择多个时间序列模型。
2、Auto-TS 库的特点
1、使用遗传规划优化找到最佳时间序列预测模型。
2、训练普通模型、统计模型、机器学习模型和深度学习模型,具有所有可能的超参数配置和交叉验证。
3、通过学习最佳 NaN 插补和异常值去除来执行数据转换以处理杂乱的数据。
4、选择用于模型选择的指标组合。
总结:可以使用所有这些参数并分析我们模型的性能,然后可以为我们的问题陈述选择最合适的模型。
-
时间序列模型
在生产和科学研究中,对某一个或者一组变量进行观察测量,将在一系列时刻所得到的离散数字组成的序列集合,称之为时间序列(定量预测法)
时间序列分析是根据系统观察得到的时间序列数据,通过曲线拟合和参数估计来建立数学模型的理论和方法。时间序列分析常用于国民宏观经济控制、市场潜力预测、气象预测、农作物害虫灾害预报等各个方面。
-
据平稳性与差分法:
- 平稳性
1、平稳性就是要求经由样本时间序列所得到的拟合曲线在末来的一段期间内仍能顺着现有的形态“惯性”地延续下去。
2、平稳性要求序列的均值和方差不发生明显变化。
2、平稳性检验
序列平稳性是进行时间序列分析的前提条件,在大数定理和中心定理中要求样本同分布(时间序列的平稳性),而我们的建模过程中有很多都是建立在大数定理和中心极限定理的前提条件下的,如果它不满足,得到的许多结论都是不可靠的。以虚假回归为例,当响应变量和输入变量都平稳时,我们用t统计量检验标准化系数的显著性。而当响应变量和输入变量不平稳时,其标准化系数不在满足t分布,这时再用t检验来进行显著性分析,导致拒绝原假设的概率增加,从而得出错误的结论。
3、平稳时间序列有两种定义:(严平稳和宽平稳)
严平稳:严平稳表示的分布不随时间的改变而改变。
弱平稳: 期望与相关系数 (依赖性 ) 不变(大部分数据基本都服从弱平稳)
未来某时刻的t的值(Xt)依赖于它的过去信息,所以需要依赖性。
弱平稳又叫二阶平稳(均值和方差平稳),它应满足:
常数均值、常数方差、常数自协方差
4、ARIMA前言
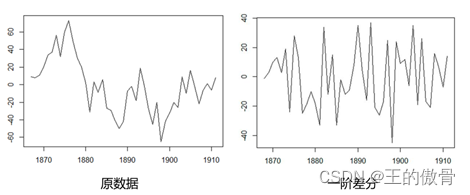
ARIMA模型对时间序列的要求是平稳型。因此,当得到一个非平稳的时间序列时,首先要做的即是做时间序列的差分,直到得到一个平稳时间序列。如果你对时间序列做d次差分才能得到一个平稳序列,那么可以使用ARIMA(p,d,q)模型,其中d是差分次数。
差分法:时间序列在t与t-1时刻的差值(dropna()缺失值丢弃)
当数据差异特别大时,为使数据变得稳定些,可以使用差分法(做一次差分就够了)
差分后平稳检验(ADF)
-
自回归模型 ( AR )
1、描述当前值与历史值之间的关系,用变量自身的历史时间数据对自身进行预测。
2、自回归模型必须满足平稳性的要求(自相关系数,可用最大似然估计,最小二乘法等来求解)
3、p阶自回归过程的公式定义:
![]()
预测的值不光和前一天有关,还和前2天…前p天有关,累加的和。
2、P表示时间间隔,比如假设按天统计数据,1阶表示今天和昨天,2阶表示今天和前天…i表示当前值与历史值前边多少个有关系。
3、![]() 是当前值,
是当前值,![]() 是常数项,p是阶数,
是常数项,p是阶数,![]() 是自相关系数
是自相关系数![]() 是误差(服从独立同分布)
是误差(服从独立同分布)
预测的值不光和前一天有关,还和前2天…前p天有关,累加的和。
2、P表示时间间隔,比如假设按天统计数据,1阶表示今天和昨天,2阶表示今天和前天…i表示当前值与历史值前边多少个有关系。
3、![]() 是当前值,
是当前值,![]() 是常数项,p是阶数,
是常数项,p是阶数,![]() 是自相关系数
是自相关系数![]() 是误差(服从独立同分布)
是误差(服从独立同分布)
自回归模型的缺陷
1、自回归模型是用自身的数据来进行预测。
2、必须具有平稳性。
3、必须具有自相关性,如果γi 自相关系数小于0.5,不宜采用。
4、自回归只适用于预测与自身前期相关的现象。
1、2移动平均模型 (MA)
- 移动平均模型是自回归模型中的误差项的累加。
- q阶自回归过程的公式定义:
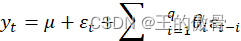
-
移动平均法能有效地消除预测中的随机波动。
-
-
- 自回归移动平均模型 (ARMA)
-
-
自回归与移动平均的结合

p(自回归模型阶数 ),q (移动回归模型阶数) 需要自己指定;
γi和θi![]() 需要自己求解。
需要自己求解。
1、差分自回归移动平均模型(ARIMA)
I表示差分项(d)
A R是自回归,p为自回归项,M A为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数。
原理:将非平稳时间序列转化为平稳时间序列然后将因变量仅对它的滞后值(阶数)以及随机误差项的现值和滞后值进行回归所建立的模型。
2、相关函数评估方法:单位根检验(p<0.5)
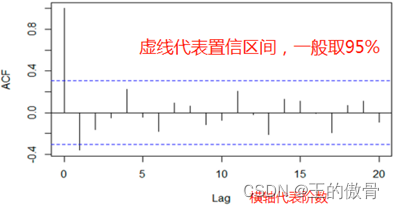
自相关函数(ACF)
1、有序的随机变量序列与其自身相比较。
2、自相关函数反映了同一序列在不同时序的取值之间的相关性。
3、pk的取值在[-1,1]

1、3偏自相关函数(PACF)
1、对于一个平稳AR(p)模型,求出滞后k自相关系数p(k)时实际上得到并不是x(t)与x(t-k)之间单纯的相关关系。
2、自相关函数ACF包含了其他变量的影响。
3、偏自相关系数PACF是严格这两个变量之间的相关性。
4、可以通过ACF和PACF的图选择出p值和q值。
ARIMA(p,d,q)阶数的确定:
| 模型 | ACF | PACF |
| AR(p) | 衰减趋于零 | P阶后截尾 |
| MA(q) | q阶后截尾 | 衰减趋于零(几何型或振荡型) |
| ARMA(p,q) | q阶后衰减趋于零(几何型或振荡型) | p阶后衰减趋于零(几何型或振荡型) |
截尾:落在置信区间内(95%的点)
AR(p)看PACF MA(q)看ACF
1、4白噪声检验(纯随机性检验)
我们主要看第二列的P值,lags为检验的延迟数,一般指定是20,或是序列长度,每一个P值都小于0.05或等于0,说明该数据不是白噪声数据,数据有价值,可以继续分析。
反之如果大于0.05,则说明是白噪声序列,是纯随机性序列。
ARIMA模型评估标准:(越低越好)
AIC:赤池信息准则 AIC=2k-2lnL
BIC:贝叶斯信息准则 BIC=klnn-2lnL
K为模型参数个数(k值越小越好),n为样本数量,L为似然函数(似然函数大一些好)BIC的结果受样本的影响,使用同一样本时,可以选择BIC。(不局限于这两种)
可以通过遍历,画出热力图(值越小越好)
1、5 ARIMA模型型残差检验:(plot_diagnostics)
比较好的ARIMA模型平稳性较好
1、ARIMA模型的残差是否是平均值为0且方差为常数的正态分布。
2、QQ图: 线性即正态分布。(散点一条直线)
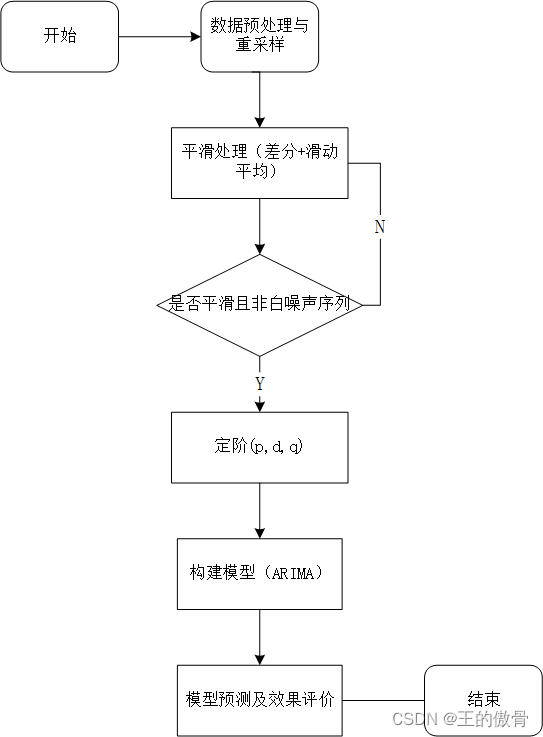
1、6 时间序列建模基本步骤:
- 获取被观测系统时间序列数据;对数据进行预处理和重采样
(分训练集和测试集)
2、对数据绘图,观测是否为平稳时间序列;对于非平稳时间序列要先进行d阶差分运算,化为平稳时间序列;
3、经过第二步处理,已经得到平稳时间序列。要对平稳时间序列分别求得其自相关系数ACF 和偏自相关系数PACF,通过对自相关图和偏自相关图的分析,得到最佳的阶层p和阶数q
4、由以上得到ARIMA模型。然后开始对得到的模型进行模型检验。
案列分析
例1 :对2015/1/1到2015/2/6某餐厅的销售数据进行建模。并对未来五天进行预测。
Step1: 导入被观测系统时间序列数据;对数据绘图,观测是否为平稳时间序列;
Step2:对数据进行单位根检验,发现原数据的P值为0.9984>0.05,检验结果为非平稳序列。
| ADF | cValue | p值 | ||
| 1% | 5% | 10% | ||
| 1.8138 | -3.7112 | -2.9812 | -2.6301 | 0.9984 |
Step3:对原数据进行一阶差分并进行ADF检验,p值0.0227<0.05, 差分序列的白噪声检验的结果为:0.0007<0.05,得到结论:现在的D_data数据为平稳非白噪声序列。
Step4:对已有的数据进行定阶(ACF,PACF)得到p,q值为(0,1)(BIC)
Step5:对未来进行预测,并通过summary2()函数和plot_diagnostics()函数得到详细数据和图像(残差图和QQ图)
| 2015/2/7 | 2015/2/8 | 2015/2/9 | 2015/2/10 | 2015/2/11 |
|
|
|
|
|
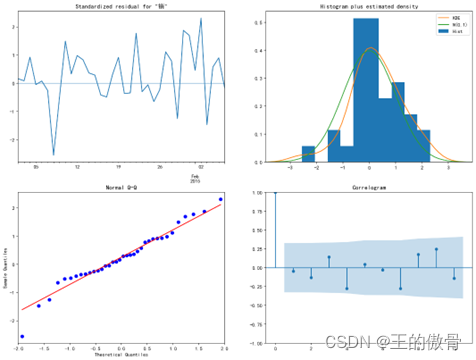
通过qq图可以看出,残差基本满足了正态分布。说明模型较好。
| 适用范围 | 优点 | 缺点 |
| 根据客观事物发展的这种连续规律性,运用过去的历史数据,通过统计分析,进一步推测市场未来的发展趋势。时间序列在时间序列分析预测法处于核心位置。 | 一般用ARMA模型拟合时间序列,预测该时间序列未来值。 Daniel检验平稳性。 自动回归AR(Auto regressive)和移动平均MA(Moving Average)预测模型。 | 当遇到外界发生较大变化,往往会有较大偏差,时间序列预测法对于中短期预测的效果要比长期预测的效果好。 |
| 马尔科夫预测(互补) | ||
| 适用于随机现象的数学模型(即在已知现情况的条件下,系统未来时刻的情况只与现在有关,而与过去的历史无直接关系) | 研究一个商店的未来某一时刻的销售额,当现在时刻的累计销售额已知。 | 不适宜用于系统中长期预测 |
-
时间序列模型的诊断(检验)
- 参数估计(模型诊断)
- 准确性(2)模型改进
(一元)残差分析 and 过度拟合
(多元)残差交叉相关性 and 多元混成统计
- 残差分析(好:残差序列是白噪声序列)(均值为0、方差恒定、序列不相关)
白噪声(0均值的正态分布)
主要任务:(1)是否均值为0(2)是否正态分布(3)检验自相关函数值
Step1:残差图(标准残差)看趋势、异常
Step2:残差的正态性检验(QQ图)
Shapiro-wilk正态性检验(p值)
Step3:(1)残差自相关(ACF)两倍标准差(置信区间)
(2)Ljung-BOX检验(卡方分布k-p-q)p值
2、过度拟合(两个特点)
(1)额外参数显著为0
(2)共同参数与原始估计相比无显著改变
对数似然值(值大好)AIC(值小好)
Tips:参数冗余
简单模型先检验 (2)残差分析(扩展)
1. import pandas as pd
2. datafile = "arima_data.xls"
3. import matplotlib
4. %matplotlib inline
5. import matplotlib.pyplot as plt
6. from statsmodels.graphics.tsaplots import plot_acf
7. from statsmodels.tsa.stattools import adfuller as ADF
8. from statsmodels.graphics.tsaplots import plot_pacf
9. from statsmodels.stats.diagnostic import acorr_ljungbox
10. from statsmodels.tsa.arima_model import ARIMA
11. #forecastunum = 5
12. data = pd.read_excel(datafile,index_col="日期")
13. data.head()
14.
15. #设置图像风格
16. plt.rcParams["font.sans-serif"] = ["SimHei"]
17. plt.rcParams["axes.unicode_minus"] = False
18. data.plot()
19. plt.show()
20. plot_acf(data).show()
21.
22. print("原始序列的ADF检验结果为:",ADF(data["销量"]))
23. #pvalue为0.9983>0.05 (单位根)
24. D_data = data.diff().dropna()
25. D_data.columns = ["销量差分"]
26. D_data.plot()
27. plt.show()
28. plot_acf(D_data).show()
29. plot_pacf(D_data).show()
30.
31. #定阶
32. data["销量"] = data["销量"].astype(float)
33. pmax = int(len(D_data)/10)
34. qmax = int(len(D_data)/10)
35.
36. bic_matrix = []
37. for p in range(pmax+1):
38. tmp = []
39. for q in range(qmax+1):
40. try:
41. tmp.append(ARIMA(data,(p,1,q)).fit().bic)
42. except:
43. tmp.append(None)
44. bic_matrix.append(tmp)
45. bic_matrix = pd.DataFrame(bic_matrix)
46. bic_matrix.head()
47.
48. p,q = bic_matrix.stack().idxmin()
49. print("BIC最小的P和q的值分别为:%s %s"%(p,q))
50. model = ARIMA(data,(p,1,q)).fit()
51. print("模型报告为:\n",model.summary2())
52. print("预测未来5天,其预测结果、准确误差、置信区间如下:\n",model.forecast(5))
53. model_results.plot_diagnostics(figsize=(16, 12));















 2801
2801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











