







Transformer
Transformer带来的其他优点
-
并行计算, 提高训练速度
Transformer用attention代替了原本的RNN; 而RNN在训练的时候, 当前step的计算要依赖于上一个step的hidden state的, 也就是说这是一个sequential procedure, 我每次计算都要等之前的计算完成才能展开. 而Transformer不用RNN, 所有的计算都可以并行进行, 从而提高的训练的速度. -
建立直接的长距离依赖
原本的RNN里, 如果第一帧要和第十帧建立依赖, 那么第一帧的数据要依次经过第二三四五…九帧传给第十帧, 进而产生二者的计算. 而在这个传递的过程中, 可能第一帧的数据已经产生了biased, 因此这个交互的速度和准确性都没有保障. 而在Transformer中, 由于有self attention的存在, 任意两帧之间都有直接的交互, 从而建立了直接的依赖, 无论二者距离多远.
Transformer没有解决的问题
上面说到, Transformer可以使模型进行并行训练, 但是仍然是一个autoregressive的模型; 也就是说, 任意一帧的输出都是要依赖于它之前的所有输出的. 这就使得inference的过程仍然是一个sequential procedure. 这也是当前绝大多数seq2seq模型的问题, 不论是ConvS2S等等. 因此如何打破这个特点, 建立Non autoregressive model, 并且取得和autoregressive model接近的性能是一个重要的问题.
模型概览
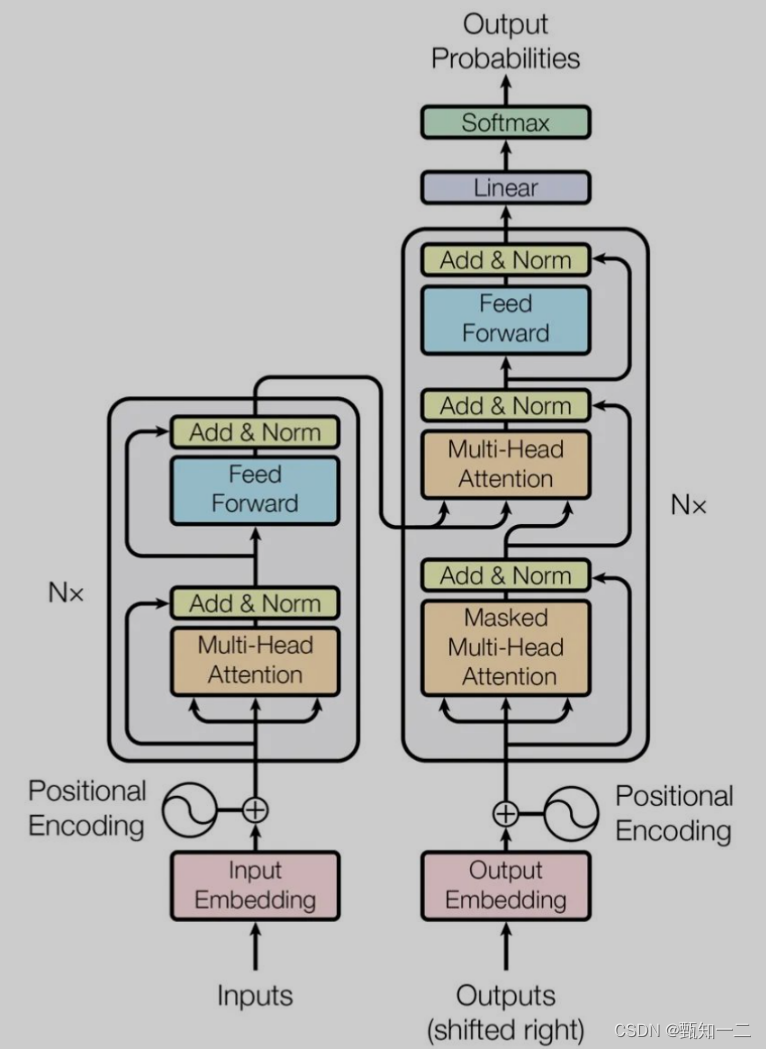
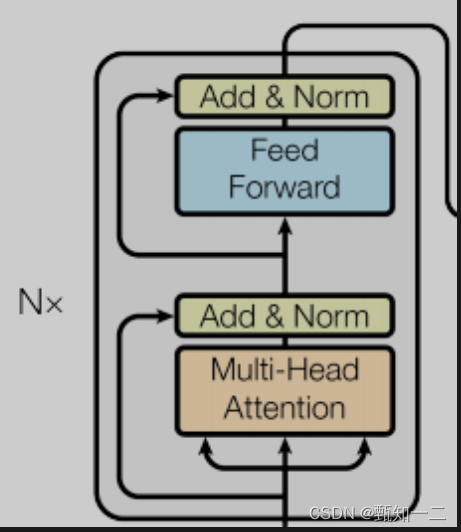
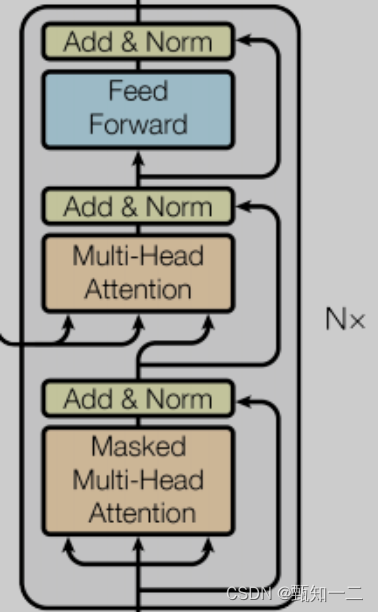
模型大致分为Encoder(编码器)和Decoder(解码器)两个部分
第一个子层是一个Multi-Head Attention(多头的自注意机制),第二个子层是一个简单的Feed Forward(全连接前馈网络)。两个子层都添加了一个残差连接+layer normalization的操作
模型的解码器同样是堆叠了N个相同的层,不过和编码器中每层的结构稍有不同。对于解码器的每一层,除了编码器中的两个子层Multi-Head Attention和Feed Forward,解码器还包含一个子层Masked Multi-Head Attention,如图中所示每个子层同样也用了residual以及layer normalization
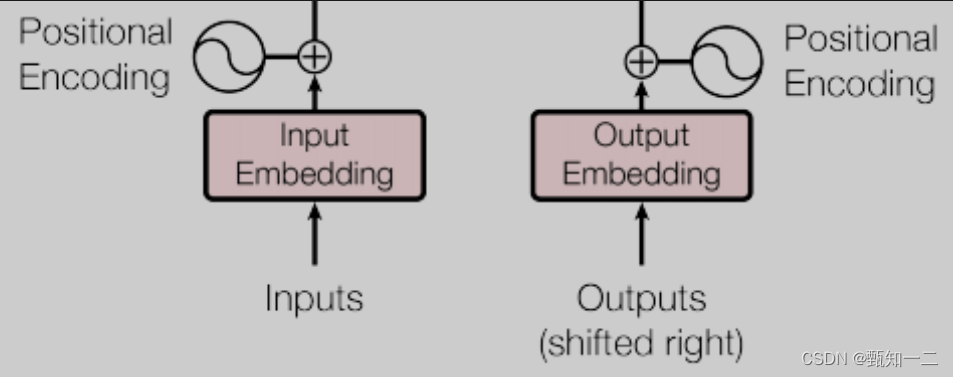
模型的输入由Input Embedding和Positional Encoding(位置编码)两部分组合而成,模型的输出由Decoder的输出简单的经过softmax得到
模型输入
输入部分包含两个模块,Embedding 和 Positional Encoding
最终模型的输入是若干个时间步对应的embedding,每一个时间步对应一个embedding,可以理解为是当前时间步的一个综合的特征信息,即包含了本身的语义信息,又包含了当前时间步在整个句子中的位置信息
Embedding
Embedding层的作用是将某种格式的输入数据,例如文本,转变为模型可以处理的向量表示,来描述原始数据所包含的信息
位置编码
Positional Encodding位置编码的作用是为模型提供当前时间步的前后出现顺序的信息。
因为Transformer不像RNN那样的循环结构有前后不同时间步输入间天然的先后顺序,所有的时间步是同时输入,并行推理的,因此在时间步的特征中融合进位置编码的信息是合理的
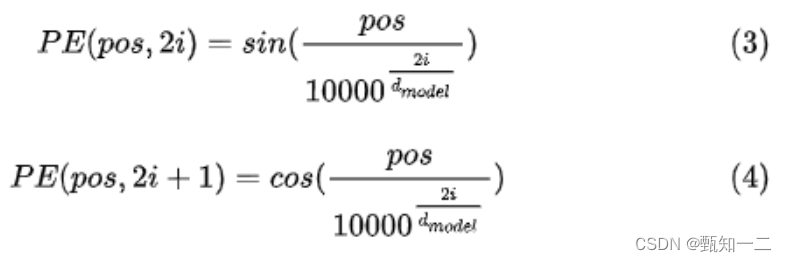
固定的位置编码。具体地,使用不同频率的sin和cos函数来进行位置编码(任意两个相距k个时间步的位置编码向量的内积都是相同的,这就相当于蕴含了两个时间步之间相对位置关系的信息。此外,每个时间步的位置编码又是唯一的,这两个很好的性质使得上面的公式作为位置编码是有理论保障的)
分类
位置编码是一种用于将输入序列中的每个位置编码为向量的技术。以下是一些常用的位置编码方式:
-
绝对位置编码(Absolute Position Encoding):将每个位置编码为一个唯一的向量,通常使用正弦和余弦函数来生成编码。
-
相对位置编码(Relative Position Encoding):将每个位置与其他位置之间的相对距离编码为向量。相对位置编码可以更好地捕捉输入序列中的位置关系。
-
基于注意力机制的位置编码(Attention-based Position Encoding):使用注意力机制来学习位置编码。这种方法允许模型根据输入序列的内容和上下文来动态地调整位置编码。
-
卷积位置编码(Convolutional Position Encoding):使用卷积神经网络来学习位置编码。这种方法可以将位置编码作为卷积操作的一部分来学习。
-
双向位置编码(Bidirectional Position Encoding):将每个位置编码为两个向量,一个用于正向顺序,一个用于逆向顺序。这种方法可以更好地捕捉输入序列的双向信息。
这些位置编码方式可以根据具体的任务和模型结构选择使用。不同的位置编码方式可能适用于不同的应用场景和数据特征。
Encoder和Decoder都包含输入模块
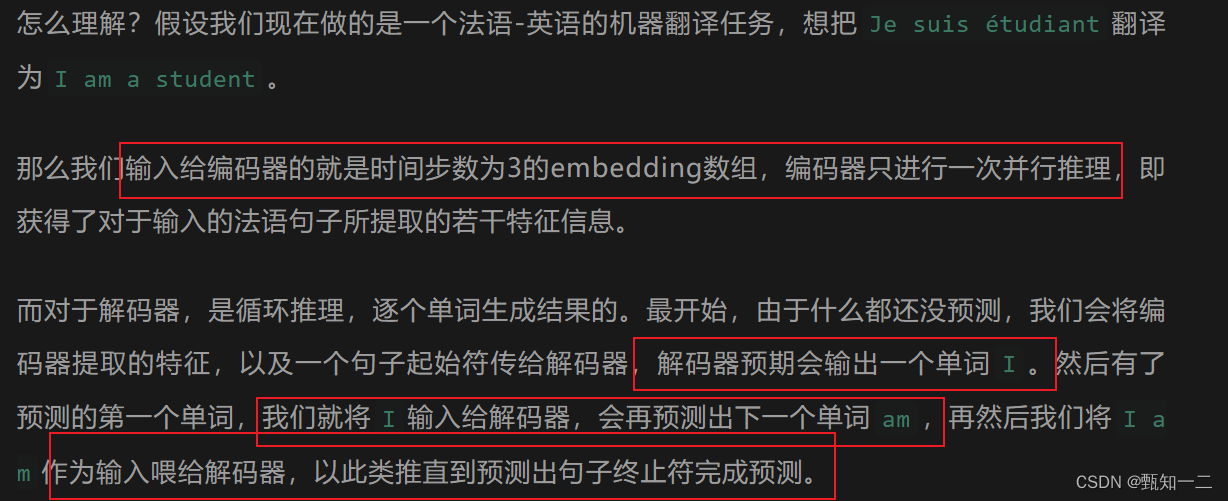
编码器和解码器两个部分都包含输入,且两部分的输入的结构是相同的,只是推理时的用法不同,编码器只推理一次,而解码器是类似RNN那样循环推理,不断生成预测结果的
encoder
每个编码器层由两个子层连接结构组成:
第一个子层包括一个多头自注意力层和规范化层以及一个残差连接;
第二个子层包括一个前馈全连接层和规范化层以及一个残差连接;
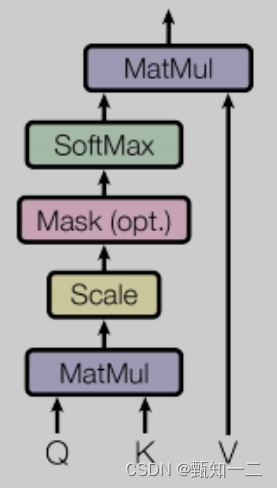
attention
当前时间步的注意力计算结果,是一个组系数 * 每个时间步的特征向量value的累加,
而这个系数,通过当前时间步的query和其他时间步对应的key做内积得到,这个过程相当于用自己的query对别的时间步的key做查询,判断相似度,决定以多大的比例将对应时间步的信息继承过来
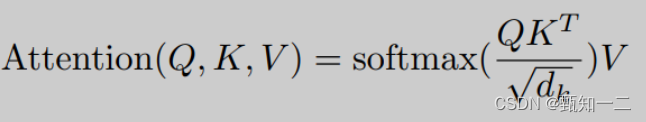
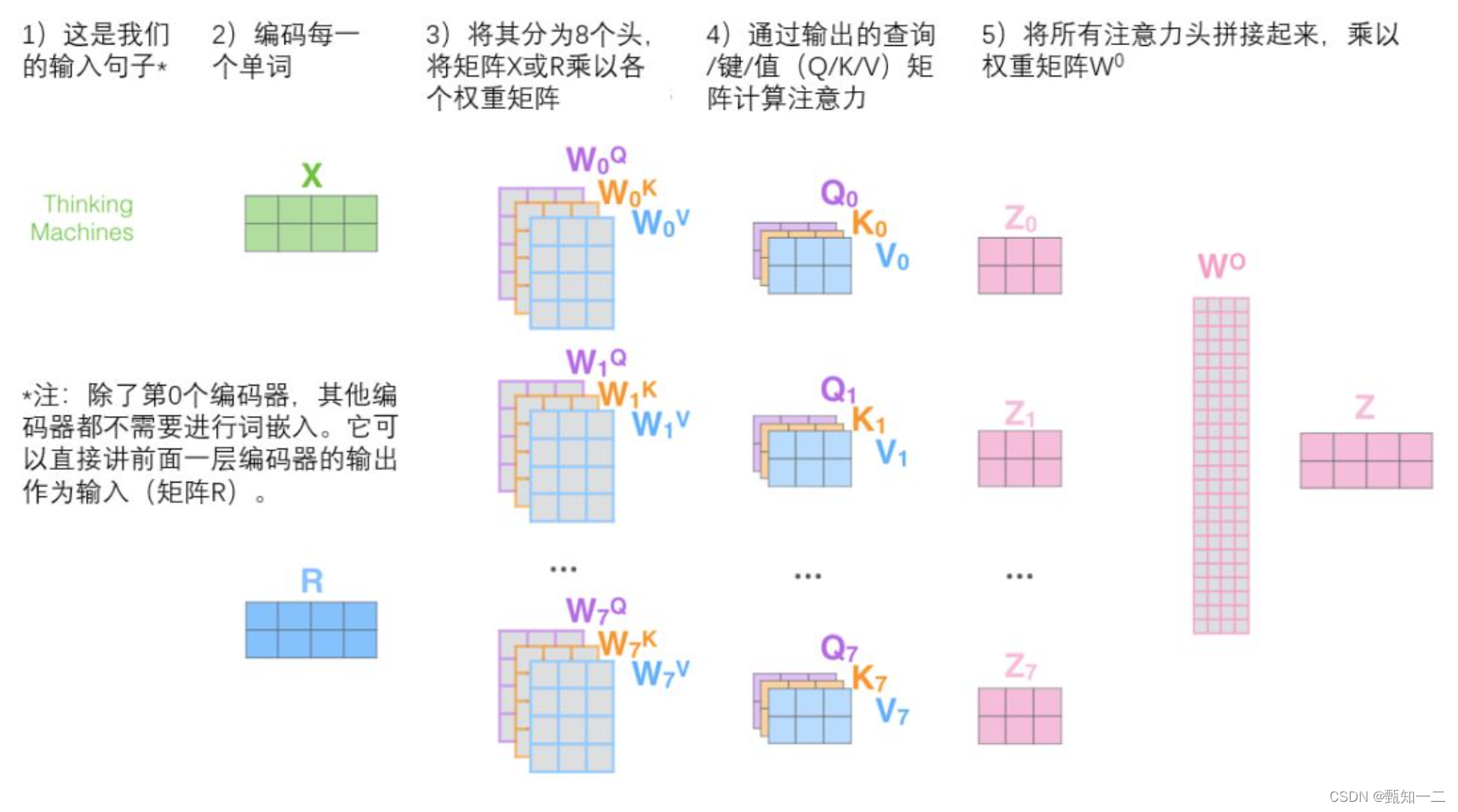
多头注意力
多个注意力模块组合在一起
这种结构设计能让每个注意力机制去优化每个词汇的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元表达
- 举个更形象的例子,bank是银行的意思,如果只有一个注意力模块,那么它大概率会学习去关注类似money、loan贷款这样的词。如果我们使用多个多头机制,那么不同的头就会去关注不同的语义,比如bank还有一种含义是河岸,那么可能有一个头就会去关注类似river这样的词汇,这时多头注意力的价值就体现出来了
前馈全连接层
encoder和decoder中的每一层都包含了一个全连接前向网络,对每个position的向量分别进行相同的操作,包括两个线性变换和一个ReLU激活输出
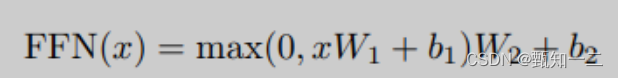
其实就是简单的由两个前向全连接层组成,核心在于**,Attention模块每个时间步的输出都整合了所有时间步的信息**,而Feed Forward Layer每个时间步只是对自己的特征的一个进一步整合,与其他时间步无关
layer normalization
随着网络层数的增加,通过多层的计算后输出可能开始出现过大或过小的情况,这样可能会导致学习过程出现异常,模型可能收敛非常慢。
因此都会在一定层后接规范化层进行数值的规范化,使其特征数值在合理范围内
- 1,能够加快训练的速度。
- 2.提高训练的稳定性
残差
深度神经网络会发生退化
假如某个神经网络的最优网络层数是18层,但是我们在设计的时候并不知道到底多少层是最优解,本着层数越深越好的理念,我们设计了32层,那么32层神经网络中有14层其实是多余地,我们要想达到18层神经网络的最优效果,必须保证这多出来的14层网络必须进行恒等映射,恒等映射的意思就是说,输入什么,输出就是什么,可以理解成F(x)=x这样的函数,因为只有进行了这样的恒等映射咱们才能保证这多出来的14层神经网络不会影响我们最优的效果。
但现实是神经网络的参数都是训练出来地,要想保证训练出来地参数能够很精确的完成F(x)=x的恒等映射其实是很困难地。多余的层数较少还好,对效果不会有很大影响,但多余的层数一多,可能结果就不是很理想了
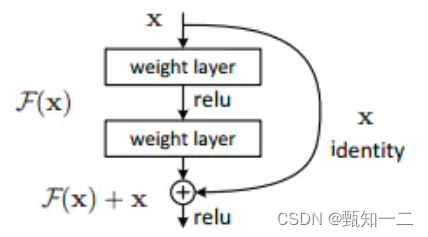
X是这一层残差块的输入,也称作F(X)为残差,X为输入值,F(X)是经过第一层线性变化并激活后的输出,
该图表示在残差网络中,第二层进行线性变化之后激活之前,F(X)加入了这一层输入值X,然后再进行激活后输出。
在第二层输出值激活前加入X,这条路径称作shortcut连接
h(X)=F(X)+X,我们要让h(X)=X,那么是不是相当于只需要让F(X)=0就可以了
神经网络通过训练变成0是比变成X容易很多地
decoder
解码器层
每个解码器层由三个子层连接结构组成
第一个子层连接结构包括一个带掩码的多头自注意力子层和规范化层以及一个残差连接,
第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接,
第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
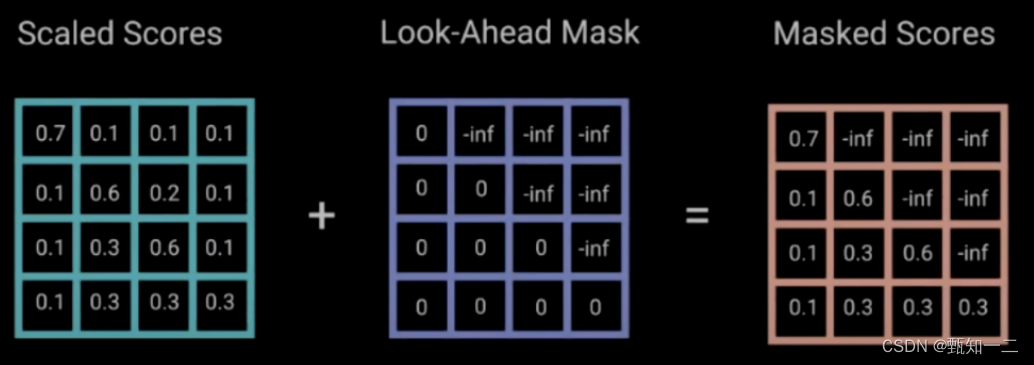
mask
Look-head mask」 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,**在 time_step 为 t 的时刻,我们的「解码」输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。**因此我们需要想一个办法,把 t 之后的信息给隐藏起来
产生一个上三角矩阵,上三角的值全为 「-inf」 。把这个矩阵加在每一个序列上,就可以达到我们的目的

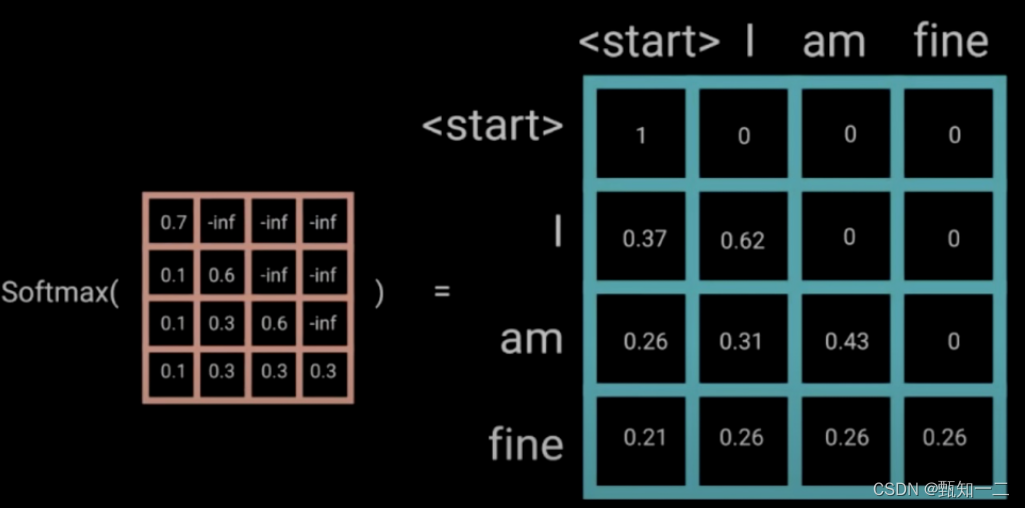
掩码及其作用
- 一个是屏蔽掉无效的padding区域,Encoder中的掩码主要是起到第一个作用,
我们训练需要组batch进行,就以机器翻译任务为例,一个batch中不同样本的输入长度很可能是不一样的,此时我们要设置一个最大句子长度,然后对空白区域进行padding填充,而填充的区域无论在Encoder还是Decoder的计算中都是没有意义的,因此需要用mask进行标识,屏蔽掉对应区域的响应
- 一个是屏蔽掉来自“未来”的信息。Decoder中的掩码则同时发挥着两种作用
attention的计算流程,它是会综合所有时间步的计算的,那么在解码的时候,就有可能获取到未来的信息,这是不行的。因此,这种情况也需要我们使用mask进行屏蔽
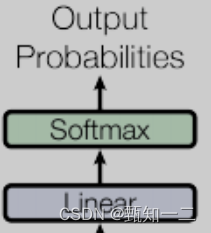
模型输出
线性层的作用:通过对上一步的线性变化得到指定维度的输出,也就是转换维度的作用。转换后的维度对应着输出类别的个数
常见问题
为什么需要进行Multi-head Attention
相比于RNN/LSTM,有什么优势
如何并行化的

为什么使用Layer Normalization(LN)而不使用Batch Normalization(BN)呢?
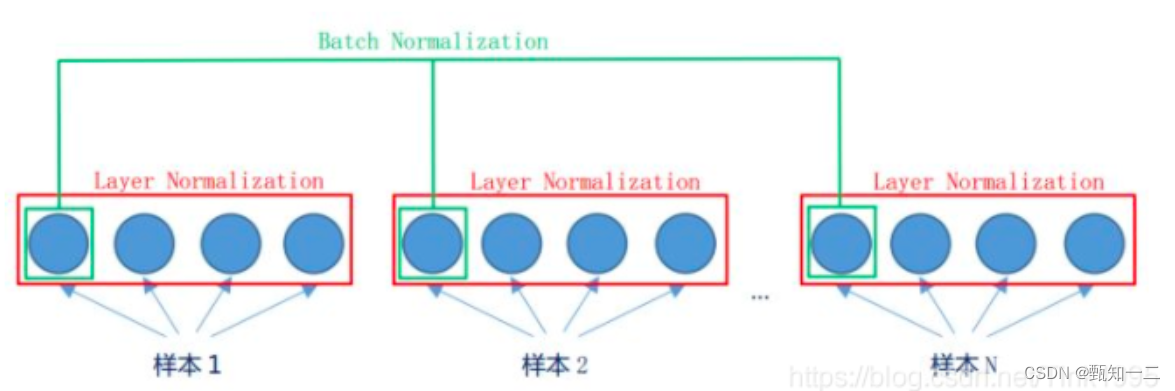
LN是在同一个样本中不同神经元之间进行归一化,
BN是在同一个batch中不同样本之间的同一位置的神经元之间进行归一化
BN是对于相同的维度进行归一化,
但是咱们NLP中输入的都是词向量,一个300维的词向量,单独去分析它的每一维是没有意义地,在每一维上进行归一化也是适合地,因此这里选用的是LN
为什么说 Transformer 可以代替 seq2seq
seq2seq 最大的问题在于「将 Encoder 端的所有信息压缩到一个固定长度的向量中」,并将其作为 Decoder 端首个隐藏状态的输入,来预测 Decoder 端第一个单词(token)的隐藏状态。在输入序列比较长的时候,这样做显然会损失 Encoder 端的很多信息,而且这样一股脑的把该固定向量送入 Decoder 端,Decoder 端不能够关注到其想要关注的信息
self-attention 模块,让源序列和目标序列首先“自关联”起来,这样的话,源序列和目标序列自身的 embedding 表示所蕴含的信息更加丰富
Transformer 并行计算的能力是远远超过 seq2seq 系列的模型
self-attention 公式中的归一化有什么作用















 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









