









文章目录
1 为什么引入RNN?
对于图片分类,输入的每张图往往都是独立的,前后无关,这时CNN就够了。
但是对于很多语言类的问题,输入的语境和语序都是很重要的此时要用到RNN,RNN考虑了时序的变化,让神经网络有了某种记忆的能力。


RNN的训练和传统的神经网络一样,也采用误差反向传播加上梯度下降来更新权重,只不过计算隐藏层时它要引入之前不同时刻的数据,就像人的记忆难以持久一样,这种时序上的依赖当然不能无限延伸,虽然建立了不同时刻隐藏层记忆的联系,实现了记忆的效果但只是基于前一时刻短期记忆,通常情况下超过十步就不太行了。
即普通RNN无法回忆起久远记忆的原因:梯度消失或者梯度爆炸
①梯度消失
试想一下在反向传播过程中,算出的权重W若小于1,则经过很多层反向传播的误差逐渐缩小(很多个小于1的数相乘接近0),到了第一层基本不会发生变化,即学习不到内容。

②梯度爆炸
试想一下在反向传播过程中,算出的权重W若大于1,则经过很多层反向传播的误差逐渐增大(很多个大于1的数相乘接近正无穷),到了第一层会发生很大的变化,学习的也不会很精确。

注意!!
RNN共享一套参数,其梯度消失的真正含义不是连乘效应,而是远距离忽略不计,近距离被梯度主导。
为了解决梯度消失或者梯度爆炸导致普通的RNN无法回忆起久远记忆的问题,在RNN基础上提出了LSTM。
2 LSTM 长短期记忆
LSTM的实质是:过滤重要特征 忽略无关信息
LSTM和普通RNN相比多出了三个控制器:输入、输出、忘记
可以形象地理解为LSTM加了一个日记本


在每一部分的日记本训练中,如上图:
f1忘记门:Sigmoid 函数在0~1之间矩阵元素相乘时会抹掉值为0的元素,删除。相当于选择性遗忘了部分记忆:过滤重要特征 忽略无关信息
f2输入门:像一支铅笔,再次根据昨天的记忆和今天的输入决定在日记本上增加哪些记录,数学语言描述sigmoid再次对记忆进行选择 tan不是遗忘,而是相当于把这两天发生的事情进行梳理和归纳。
和RNN相比LSTM引入了更多的参数矩阵,因此训练起来更麻烦一些,但依然可以用梯度下降法。由于深度发掘了数据时序上的有趣关联LSTM在某种程度上模拟了大脑关注重要片段,而忽略无关信息。
LSTM与卷积神经网络CNN和反向传播一起,构成了人工智能20多年来发展最重要的三大基石。
3 Transformer
在Transformer中,编码器&解码器架构表现得最好。

3.1 编码器和解码器
编码器:对原始输入进行编程,生成机器学习可以理解的向量。多个enconder结构相同,参数相互独立。
解码器:拿到编码器输入,拿到一个m序列。
编码器和解码器的区别:
①编码器可以一起生成(根据一定的策略生成一次性将一批数据转化为机器可以理解的向量)
②解码器是一个个生成的(类比翻译:我、爱、你依次有顺序生成)
③解码器使用自回归,即在过去时刻的输出可以作为当前时刻的输入(y1~yt可以对yt+1有影响)
Transformer结构
由N个编码器和解码器叠加而成。

其中编码器的输出作为解码器的输入,下图为编码器结构

解码器中的Masked Muti-Head Attention 表明了此时生成的数据不受后面生成数据的影响(yt不受yt+1的影响,只受y1~yt-1的影响)。
3.2 layernorm & batchnorm
Batchnorm每次把列(特征)均值变为0方差变为1,再加两个学习的参数。
layernorm对每个样本做均值为0方差为1的归一化操作。

但是在三维及以上的空间中但是每个样本序列的长度不一定相同,没有的列就变成0,所以用layernorm。
Layernorm不用存全局变量,更好用。

3.3 注意力
注意力函数(query、keys、values、output)是一个将一个query和一些key-value对映射成一个输出output的函数,具体output是value的加权和(维度相同)。权重是query和value对应的key的相似度。不同的注意力机制有不同的算法。最简单的注意力机制:
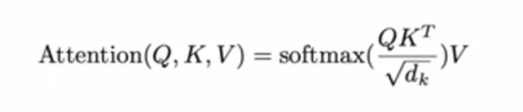
多头注意力


Mask保护后不用前的数据(yt时刻的数据与yt+1无关)
3.4 position encoding位置编码

和RNN不同,Attention把整个序列里面的信息抓取出来做一个汇聚。但是他们关注点都在如何有效地使用序列信息,但是Attention不会利用时序信息,进而引出position encoding。
Transformer一般需要为节点加上位置编码信息,必要时为图增加全局编码。
4 Transformer VS CNN
CNN 是SA(自注意力)的一个特例。
4.1 CNN的优缺点
①
如果CNN想获得更大的感受野(全局的信息),就必须堆叠很多层卷积,然而不断地卷积池化操作有些麻烦而且效果不一定好。
而Tranformer浅层就可以捕获较大范围信息,全局信息丰富,可以更好地理解整个图像。
②
卷积的优点是可以做多个输出通道,每个输出通道可以识别不一样的模式(比如眼睛、鼻子、嘴巴,学习到不同抽象的特征),对应的提出了多头注意力机制(每一个头识别不一样的模式)。
4.2 Tranformer的优缺点
transformer的优点是对大数据适配能力强;缺点是训练数据非常多才可以
4.3 Tranformer vs CNN

关于TF很全的一个解释:
https://wmathor.com/index.php/archives/1438/
















 5032
5032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











