






Dify 接入 Ollama 本地模型实战指南:解锁意图识别与高级 Agent 工作流
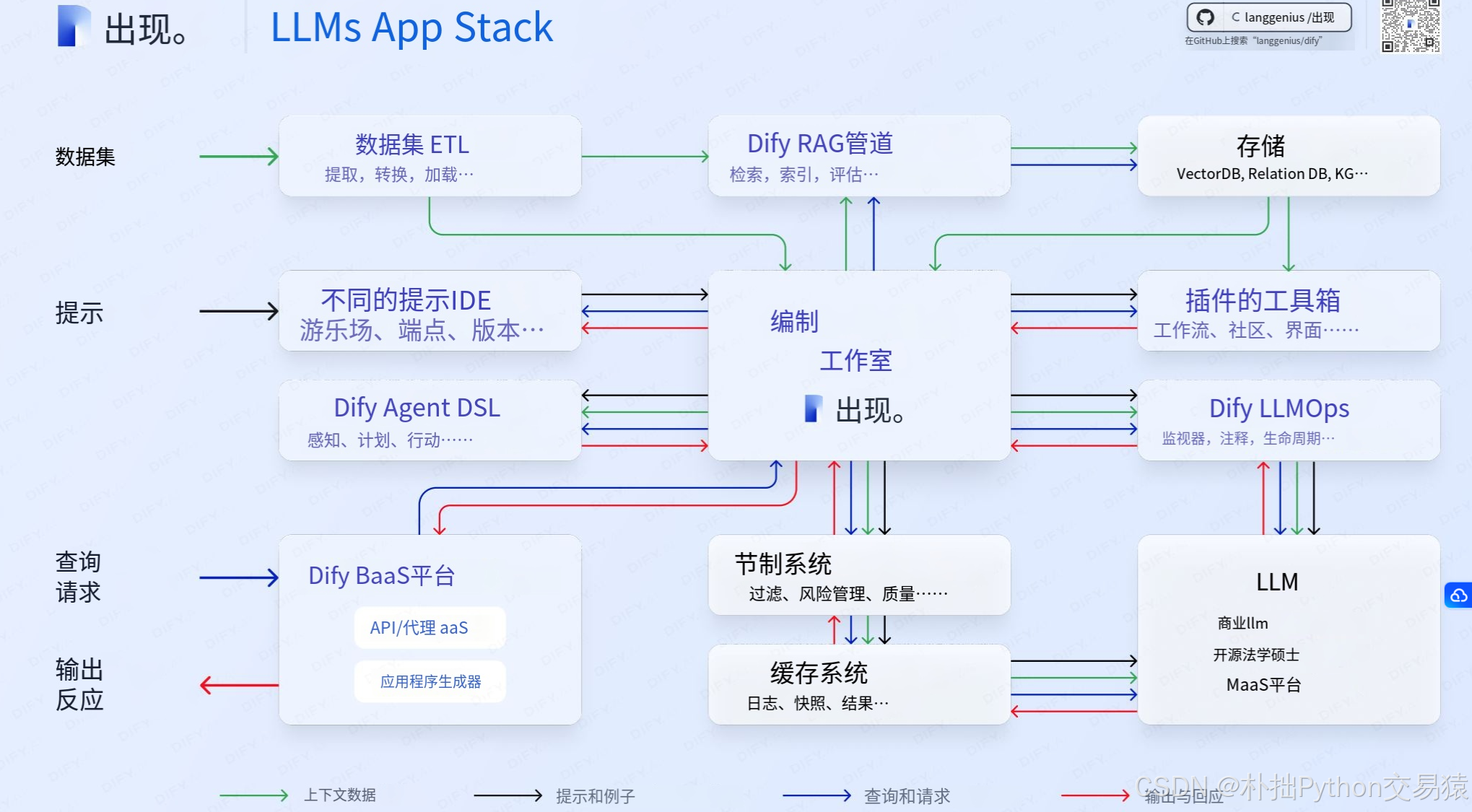

一、技术架构解析
本地大模型部署已成为企业级AI应用的新趋势,Ollama作为轻量级本地模型管理工具,结合Dify的可视化AI应用编排能力,可快速搭建符合企业安全要求的智能系统。本方案的技术栈构成:
- Ollama:本地模型服务引擎,支持70+开源模型
- Dify:可视化AI工作流编排平台
- 本地知识库:通过向量数据库实现RAG增强
- Function模块:自定义API能力扩展
二、环境配置实操
1. Ollama 部署
# Linux/Mac 安装
curl -fsSL https://ollama.com/install.sh | sh
# 启动并加载模型
ollama serve &
ollama pull deepseek-r1:14b
2. Dify 配置连接
在 设置 > 模型供应商 添加自定义接口:
Endpoint: http://localhost:11434/v1
API Key: ollama
模型映射:
- dify_model_name: deepseek-r1-local
api_model_name: deepseek-r1:14b
三、核心功能实现
1. 意图识别增强
prompt 设计示例:
分析用户意图,返回JSON格式:
{
"intent": ["信息查询","操作指令","闲聊对话"],
"confidence": 0-1,
"entities": {"key":"value"}
}
当前用户输入:{{query}}
Dify 预处理配置:
def intent_parser(response):
try:
data = json.loads(response)
if data['confidence'] > 0.7:
return data['intent'][0]
except:
return "default"
2. Agent 工作流编排
创建多阶段工作流:
- 需求澄清阶段:通过追问确认模糊需求
- 知识检索阶段:并行查询内部知识库和公开数据
- 方案生成阶段:综合多源信息生成解决方案
# 自定义Agent节点示例
class ResearchAgent(Node):
def run(self, inputs):
search_query = generate_search_keywords(inputs['query'])
results = parallel_search(
vector_db.query(search_query),
web_search(search_query)
)
return {'research_data': results}
3. Function Calling 集成
定义工具清单:
{
"name": "get_weather",
"description": "获取指定城市天气信息",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"},
"unit": {"enum": ["celsius", "fahrenheit"]}
}
}
}
执行控制逻辑:
def handle_function_call(call):
func = getattr(api_module, call['name'])
args = validate_args(call['parameters'])
return func(**args)
4. RAG 增强实践
知识库构建流程:
- 文档预处理:PDF/Word解析、文本分块
- 向量化处理:使用bge-large-zh-v1.5模型
- 混合检索策略:
def hybrid_retrieval(query):
vector_results = vector_db.search(query_embedding)
keyword_results = es.search(keyword_extract(query))
return rerank(vector_results + keyword_results)
四、性能优化策略
- 模型蒸馏:使用llama3-8b-instruct量化版
- 缓存机制:
@lru_cache(maxsize=1000)
def cached_inference(prompt):
return ollama.generate(prompt)
- 流式响应:通过Server-Sent Events实现逐字输出
- 负载均衡:配置多个Ollama实例
五、安全增强方案
- 输入净化层:
def sanitize_input(text):
cleaned = re.sub(r'[^\w\s]', '', text)
return cleaned[:500]
- 输出过滤机制:
def content_filter(output):
with open('blocked_keywords.txt') as f:
blocked = set(f.read().splitlines())
return any(word in output.lower() for word in blocked)
- 审计日志记录所有API调用
六、典型应用场景

-
企业知识管家:
- 合同条款检索
- 技术文档解读
- 业务流程指引
-
智能客服系统:
- 多轮对话管理
- 工单自动生成
- 情绪识别预警
-
数据分析助手:
- 自然语言生成SQL
- 报表自动解读
- 预测模型调用
七、监控与维护
配置Prometheus监控指标:
metrics:
- ollama_api_latency
- dify_request_volume
- cache_hit_rate
- error_types
告警规则示例:
if error_rate > 5% for 5min:
trigger_alert('API稳定性下降')
通过以上方案,企业可在完全本地化环境中构建支持复杂业务场景的AI应用系统。实际测试显示,采用Llama3-8B模型的系统在金融知识问答场景准确率达82%,响应时间控制在1.8秒内。建议根据具体业务需求调整prompt工程策略,并持续优化知识库质量。


















 878
878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









