






QueryDet: Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection
Abstract
在过去几年中,基于深度学习的通用目标检测取得了巨大的成功,但对小物体的检测性能和效率仍然不尽如人意。促进小物体检测最常见和有效的方法是使用高分辨率的图像或特征图。然而,这两种方法都会导致昂贵的计算,因为随着图像和特征的尺寸增加,计算成本将呈平方增长。为了兼顾两者的优势,我们提出了QueryDet,它使用一种新颖的查询机制来加速基于特征金字塔的目标检测器的推理速度。该流程包括两个步骤:首先在低分辨率特征上预测小物体的coarse locations,然后在高分辨率特征上通过coarse positions来计算准确的检测结果。这样,我们不仅可以利用高分辨率特征图的优势,还可以避免对背景区域进行无用的计算。在流行的COCO数据集上,所提出的方法将检测mAP提高了1.0,mAPsmall提高了2.0,高分辨率推理速度平均提高了3.0倍。在包含更多小物体的VisDrone数据集上,我们创造了新的最先进性能,同时平均获得了2.3倍的高分辨率加速。
1. Introduction
近年来,随着深度学习的不断进步,视觉目标检测在性能和速度方面取得了巨大的提升。然而,检测小物体仍然是一个具有挑战性的问题。小尺寸物体和普通尺寸物体之间存在很大的性能差距。以RetinaNet 为例,它在中等和大尺寸物体上的mAP分别为44.1和51.2,但在COCO测试集上的小物体上仅获得24.1的mAP。这种性能下降主要由三个因素造成:1)由于卷积神经网络(CNN)的主干网络中的下采样操作,强调小物体的特征消失,因此小物体的特征常常受到背景噪声的污染;2)低分辨率特征上的receptive field可能与小物体的尺寸不匹配;3)定位小物体比大物体更困难,因为边界框的微小扰动可能会导致交并比(IoU)指标的显著扰动。
小物体检测可以通过调整输入图像的大小或减少CNN的下采样率来改进,以保持高分辨率的特征图,因为这样可以增加生成特征图的effective resolution。然而,仅增加特征图的分辨率会带来相当大的计算成本。一些工作提出通过重新使用CNN不同层的多尺度特征图来构建 feature pyramid来解决这个问题。不同尺度的物体在不同级别上进行处理:大物体往往在高级特征上被检测,而小物体通常在低级特征上被检测。特征金字塔范式节省了在主干网络中从浅层到深层维持高分辨率特征图的计算成本。然而,低级特征上的检测头的计算复杂性仍然很大。例如,将额外的金字塔级别P2添加到RetinaNet中将带来300%的额外计算(FLOPs)和内存开销,从而严重降低了在NVIDIA 2080Ti GPU上的推断速度,从13.6 FPS降至4.85 FPS。
在本文中,我们提出了一种简单有效的方法,QueryDet,可以在提升小物体性能的同时节省 detection head的计算。这一方法的动机来自两个关键观察结果:1)在低级特征上的计算高度冗余。在大多数情况下,小物体的空间分布非常稀疏:它们仅占据高分辨率特征图的一小部分区域,因此大量计算被浪费。2)特征金字塔是高度结构化的。虽然我们无法在低分辨率特征图中精确检测小物体,但我们仍然可以在high confidence下推断它们的存在和大致位置。
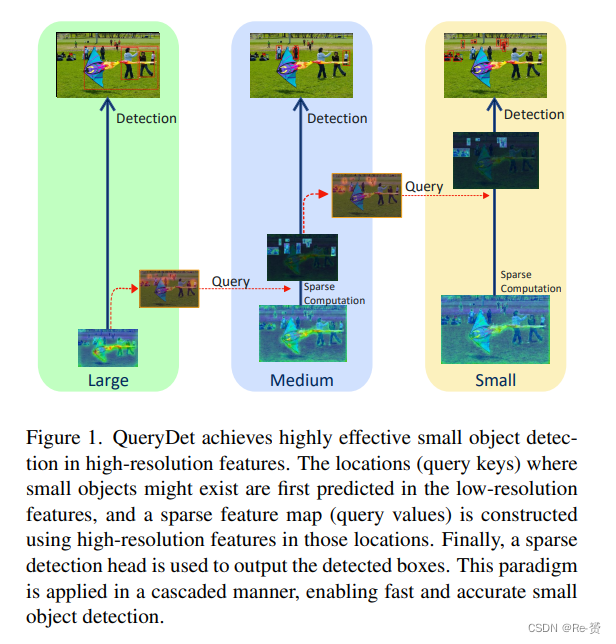
利用这两个观察结果的一个自然想法是,我们只需要将检测头应用于小物体的 spatial locations。这种策略需要以low cost和 sparse computation 定位小物体的大致位置,并在所需的特征图上进行计算。在这项工作中,我们提出了基于新颖查询机制Cascade Sparse Query (CSQ)的QueryDet,如图1所示。我们在较低分辨率的特征图上递归地预测小物体的大致位置(查询),并使用它们来引导较高分辨率特征图上的计算。借助于sparse convolution的帮助,我们显著降低了低级特征上检测头的计算成本,同时保持了小物体的检测准确性。值得注意的是,我们的方法是为了在空间上节省计算,因此与其他加速方法(如轻量化主干网络、模型剪枝、模型量化和知识蒸馏)兼容。
我们在COCO检测基准和具有大量小物体的具有挑战性的数据集VisDrone 上评估了我们的QueryDet,结果显示我们的方法可以显著加速推理过程并提高检测性能。总结起来,我们的工作主要有两个贡献:
-
我们提出了QueryDet,其中设计了一个简单而有效的Cascade Sparse Query (CSQ)机制。它可以减少所有基于特征金字塔的目标检测器的计算成本。我们的方法可以通过有效利用高分辨率特征来提高小物体的检测性能,并保持快速推理速度。
-
在COCO数据集上,QueryDet将RetinaNet基线提升了1.1个AP和2.0个APS,通过利用高分辨率特征,高分辨率检测速度平均提高了3.0倍。在VisDrone数据集上,我们在检测mAP方面推进了最先进的结果,并平均提高了2.3倍的高分辨率检测速度。
2. Related Works
略过
3. Methods
在这一部分,我们描述了用于准确快速小目标检测的QueryDet方法。我们基于RetinaNet来说明我们的方法,它是一种流行的 anchor-based的密集检测器。需要注意的是,我们的方法不局限于RetinaNet,它可以应用于任何一阶段检测器以及带有FPN的两阶段检测器中的 proposal network(RPN)。首先,我们将回顾RetinaNet并分析不同组件的计算成本分布。然后,我们将介绍如何使用我们提出的Cascade Sparse Query在推理过程中节省计算成本。最后,我们将介绍训练细节。
3.1. Revisiting RetinaNet
RetinaNet由两部分组成:带有FPN的骨干网络,输出多尺度特征图,以及用于分类和回归的两个检测头。当输入图像的尺寸为H×W时,FPN特征的尺寸为P = {Pl ∈ RH′×W′×C }。其中,l表示金字塔层级,(H′, W′)通常等于(⌊H/2l ⌋, ⌊W/2l ⌋)。检测头由四个3×3的卷积层组成,后面跟着一个额外的3×3卷积层进行最终预测。为了参数效率,不同的特征层共享相同的检测头(参数)。然而,不同层之间的计算成本高度不平衡:从P7到P3的检测头的浮点运算量(FLOPs)以特征分辨率的缩放呈二次方增长。如图2所示,P3 head占据了近一半的FLOPs,而低分辨率特征P4到P7的成本仅占15%。因此,如果我们想要将FPN扩展到P2以获得更好的小目标性能,成本是不可承受的:高分辨率的P2和P3将占据总成本的75%。接下来,我们将描述我们的QueryDet如何减少对高分辨率特征的计算,并提高RetinaNet的推理速度,即使有额外的高分辨率P2。

3.2. Accelerating Inference by Sparse Query
在现代基于FPN的检测器设计中,小目标往往是从high-resolution low-level特征图中检测出来的。然而,由于小目标在空间上通常分布稀疏,高分辨率特征图上的密集计算方式非常低效。受到这一观察的启发,我们提出了一种从粗到细的方法来减少低层级金字塔的计算成本:首先,在粗糙的特征图上预测小目标的大致位置,然后在fine feature maps上密集计算相应位置。这个过程可以看作是一种查询过程:粗糙位置是 query keys,用于检测小目标的高分辨率特征是 query values;因此我们将我们的方法称为QueryDet。我们方法的整个流程如图3所示。
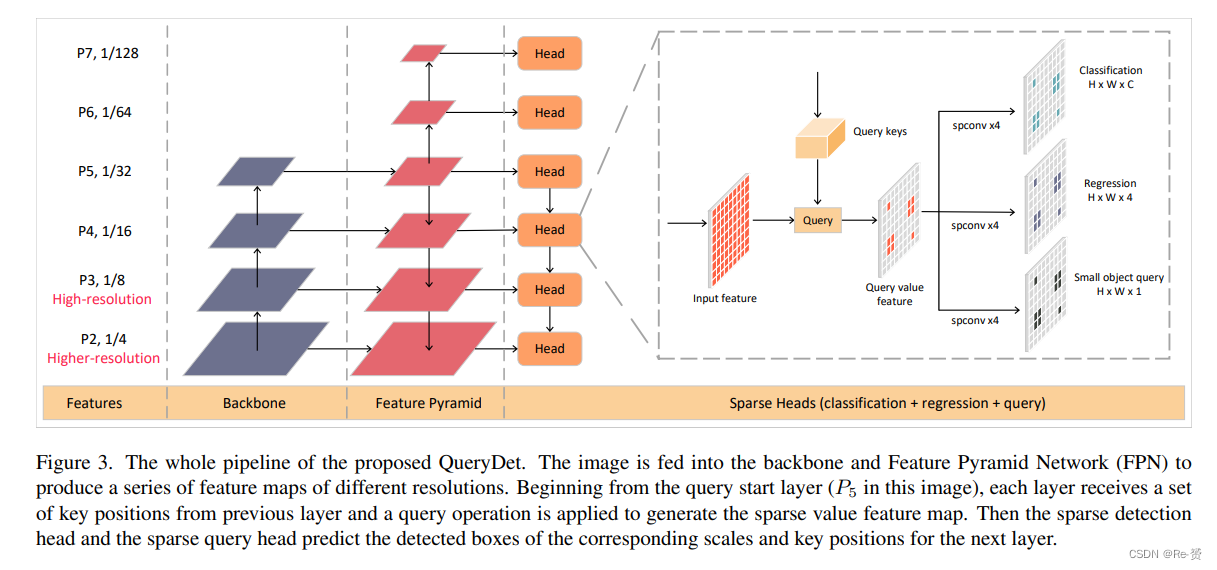
为了预测小目标的coarse locations,我们在分类和回归头的旁边添加了一个 query head。 query head接收带有步长2l的特征图Pl作为输入,并输出一个热图Vl ∈ RH′×W′,其中Vi,j l表示网格(i, j)包含小目标的概率。在训练过程中,我们将每个层级上的小目标定义为其尺度小于预定义阈值sl的对象。为了简单起见,我们将sl设置为Pl上的最小锚点尺度,对于anchor-free的检测器,sl设置为Pl上的minimum regression range。对于一个小目标o,我们通过计算其中心位置(xo, yo)与特征图上每个位置之间的距离,并将距离小于sl的位置设置为1,否则设置为0,来对查询头的 target map进行编码。然后使用FocalLoss 来训练查询头。在推理过程中,我们选择预测得分大于阈值σ的位置作为queries。然后,将qol映射到其在Pl−1上的最近的四个邻居作为 key positions {kol−1}。
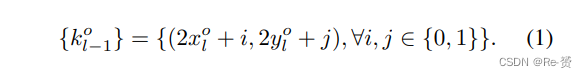
收集Pl−1上的所有{kol−1}形成 key position集合{kl−1}。然后,三个heads将仅处理这些位置来检测对象并计算下一层的查询。
为了最大化推理速度,我们以cascade的方式应用查询。特别地,Pl−2的查询只会从{kl−1}生成。我们将这种方式命名为级联稀疏查询(Cascade Sparse Query,CSQ),如图1所示。
我们的CSQ的好处在于,我们可以避免从单个Pl生成查询{ql},从而在查询映射时,随着l的减小,相应的键位置kl的大小呈指数增长。
3.3. Training
我们保持分类和回归头部的训练与原始的RetinaNet相同。对于query head,我们使用FocalLoss对其进行训练,并生成binary target map:设Pl上小目标o的真实边界框为bol = (xol, yol, wol, hol)。我们首先计算Pl上每个特征位置(x, y)与所有小目标中心点{((xol, yol)}之间的最小距离图Dl
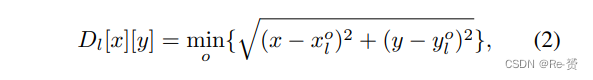
然后,我们定义ground truth query map V∗l为:
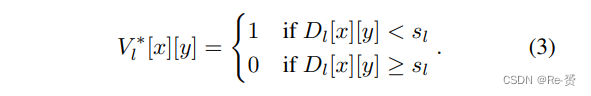
对于每个级别Pl,损失函数定义如下:
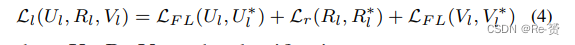
其中,Ul、Rl和Vl分别是classification输出、regressor输出和 query score输出,而U∗l、R∗l和V∗l是它们对应的ground-truth map;LFL是Focal Loss,Lr是边界框回归损失,它通常使用 smooth L1损失函数。整体的损失函数定义如下:

在这里,我们通过βl re-balance每一层的损失。原因是随着我们添加高分辨率的特征图(例如P2),训练样本的分布发生了显著变化。P2上的训练样本总数甚至大于P3到P7上的训练样本总数。如果我们不减少P2层的权重,训练过程将被小目标主导。因此,我们需要重新平衡不同层的损失,使模型能够同时从所有层中学习。通过引入权重因子βl,我们可以在整体损失函数中平衡不同层之间的重要性,从而更好地训练QueryDet模型。
3.4. Relationships with Related Work
值得注意的是,尽管我们的方法与使用RPN的两阶段目标检测器有一些相似之处,但它们在以下几个方面有所不同:1)我们在 coarse prediction中仅计算分类结果,而RPN则计算分类和回归结果。2)RPN在所有层的完整特征图上进行计算,而我们的QueryDet的计算是sparse and selective的。3)两阶段方法依赖于RoIAlign 或RoIPooling 等操作来对第一阶段的proposal进行特征对齐。然而,我们的方法没有在粗糙预测中输出边界框,因此不需要这些操作。值得注意的是,我们的方法与基于FPN的RPN兼容,因此可以将QueryDet集成到两阶段检测器中以加速候选框生成。
另一个密切相关的工作是PointRend ,它使用非常少的adaptive selected points来计算高分辨率分割图。我们的QueryDet与PointRend之间的主要区别在于:1)queries是如何生成的;2)sparse computation是如何应用的。对于第一个区别,PointRend根据每个位置的预测分数选择最不确定的区域,而我们直接添加辅助损失作为监督。我们的实验证明,这种简单的方法可以产生高召回率的预测并改善最终性能。至于第二个区别,PointRend使用多层感知器进行逐像素分类。它仅需要来自高分辨率特征图中单个位置的特征,因此可以轻松进行批处理以实现高效率。另一方面,由于目标检测需要更多的上下文信息进行准确预测,我们使用带有3×3卷积核的稀疏卷积。
4. Experiments
我们在两个目标检测数据集上进行了定量实验:COCO 和 VisDrone 。COCO是用于一般目标检测任务的数据集。它包含了一系列多样化的图像,涵盖了80个物体类别,常用于评估各种目标检测算法的性能。VisDrone则是专门针对无人机拍摄图像的数据集。其中,小物体占据了尺度分布的主导地位。
4.1. Implementation Details
我们的方法是基于PyTorch 和Detectron2工具包实现的。所有模型都是在8个NVIDIA 2080Ti GPU上训练的。对于COCO数据集,我们遵循常见的训练实践:采用标准的1×训练策略和Detectron2中的默认数据增强方法。批大小设置为16,初始学习率为0.01。用于在不同层之间平衡损失的权重βl被设置为线性增长,从P2到P7分别从1增加到3。对于VisDrone数据集,将一张图像平均分割成四个不重叠的小块,在训练过程中独立处理这些小块。我们将网络训练50,000个迭代,初始学习率为0.01,第30,000和40,000个迭代时将学习率降低10倍。平衡权重βl被设置为线性增长,从1增加到2.6。对于这两个数据集,我们在训练过程中冻结了骨干网络中的所有批归一化(BN)层,并且在检测头部没有添加BN层。我们在所有实验中使用了混合精度训练来节省GPU内存。查询阈值σ设置为0.15,并从P4开始进行查询。如果没有特别说明,我们的方法是基于ResNet-50骨干网络的RetinaNet构建的。
4.2. Effectiveness of Our Approach && 4.3. Ablation Studies
略过
4.4. Discussions
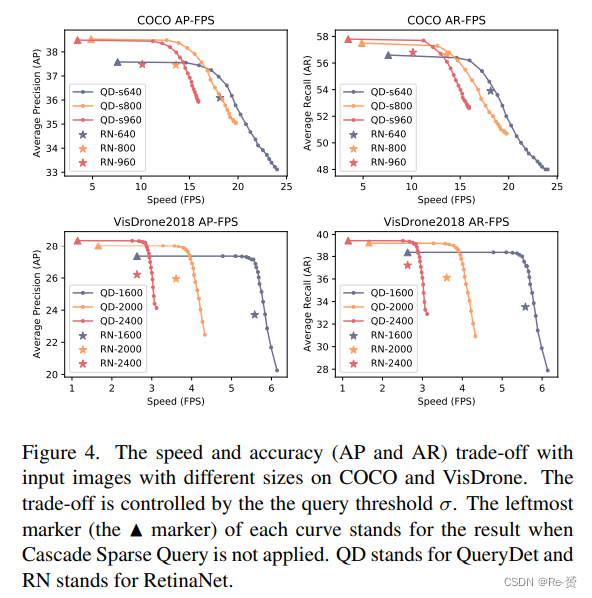
Influence of the Query Threshold 在这里,我们研究了在Cascade Sparse Query中的准确性和速度之间的权衡。我们测量了不同查询阈值σ下的检测准确性(AP)和检测速度(FPS),其中σ的作用是确定输入图像中的网格(低分辨率特征位置)是否包含小目标。直观上,增加该阈值会降低小目标的召回率,但会加速推理,因为考虑的位置更少。图4展示了在不同输入尺寸下的准确性和速度之间的权衡。我们按照0.05逐渐增加σ,相邻数据点上的一条曲线表示相同的查询阈值,最左侧的数据点表示未应用CSQ时的性能。我们观察到即使非常低的阈值(0.05)也可以带来巨大的速度提升。这一观察结果验证了我们方法的有效性。另一个观察结果是不同输入分辨率下AP上界和下界之间的差距。对于大尺寸图像,这一差距很小,但对于小尺寸图像来说,差距很大。这表明对于较高分辨率的输入,即使将查询阈值设置得较高,我们的CSQ也能保证较好的AP下界。
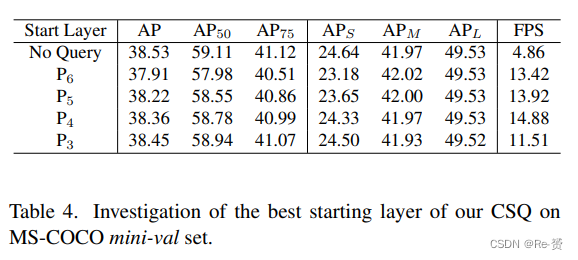
Which layer to start query? 在我们的Cascade Sparse Query中,我们需要决定从哪个层级开始查询,从该层级以上的层级开始运行传统的卷积以获取大目标的检测结果。我们不从最低分辨率层级开始是因为有以下两个原因:1)对于低分辨率特征,常规的卷积操作非常快速,因此通过CSQ节省的时间无法弥补构建sparse feature map所需的时间;2)在分辨率非常低的特征图上很难区分小目标。结果如表4所示。我们发现获得最高推理速度的层级是P4,这验证了从非常高层级(例如P5和P6)开始查询会导致速度损失。我们观察到随着开始层级的提高,AP损失逐渐增加,这表明网络在非常低分辨率层级上寻找小目标的难度增加。
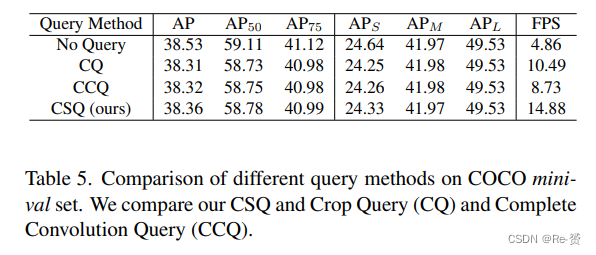
What is the best way to use queries? 我们演示了我们Cascade Sparse Query的高效性,并进行了两种替代的查询操作进行比较。第一种是Crop Query(CQ),其中由queries指示的相应区域从高分辨率特征中裁剪出来,用于后续计算。注意,这种类型的查询类似于AutoFocus方法。另一种是Complete Convolution Query(CCQ),我们使用常规卷积来计算每个层级的完整特征图,但只从查询的位置提取结果进行后处理。对于CQ,我们从特征图中裁剪出一个11×11的区域,该区域被选择以适应检测头部五个3×3连续卷积的感受野。我们在表5中展示了结果。总体而言,这三种方法都可以在几乎没有AP损失的情况下成功加速推理。其中,我们的CSQ可以实现最快的推理速度。
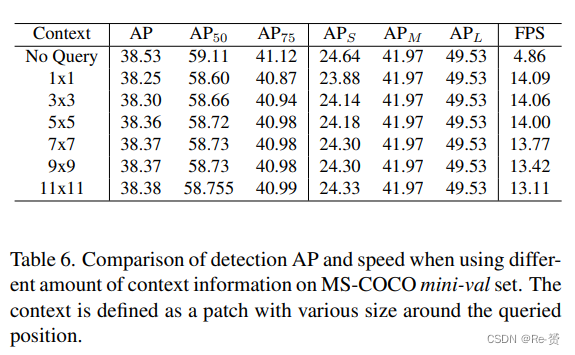
How much context do we need? 为了应用我们的CSQ,我们需要构建一个sparse feature map,其中只有小目标的位置被激活。我们还需要激活小目标周围的context area,以避免降低准确性。然而,在实践中,我们发现太多的上下文不能提高检测的准确率,只会减慢检测速度;另一方面,太少的上下文会严重降低检测的准确率。在这一节中,我们探讨了为了平衡速度和准确性而需要多少上下文。这里,上下文被定义为围绕queried position的各种大小的区域,在这个区域内,我们的稀疏检测头部也会处理特征。结果如表6所示。从表中可以得出结论:一个5x5的区域足以为我们检测小目标提供足够的上下文。虽然更多的上下文会带来小幅度的AP改善,但我们的CSQ的加速效果会受到负面影响,而更少的上下文无法保证高的检测AP。
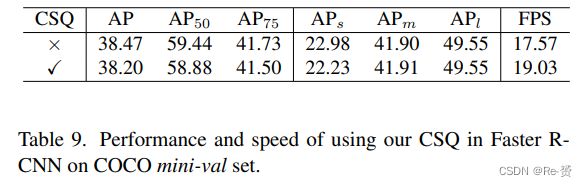
Effectiveness on Two-stage Detectors 我们的CSQ也可以应用于基于FPN的两阶段检测器,以减少RPN中高分辨率层的计算成本。为了验证这一点,我们将CSQ应用于Faster R-CNN检测器 。在我们的实现中,RPN的输入来自P2到P6,我们从P4开始进行查询。我们修改了RPN的结构,使其具有3个卷积层,而不是常规实现中的1个层,后面跟着3个分支,用于目标性分类、边界框回归和查询键计算。前两个分支遵循常规做法进行训练,而查询分支通过Focal Loss进行训练,其中γ = 1.2,α = 0.25。在推理过程中,我们将查询阈值设为0.15。如表9所示,我们的Faster R-CNN在整体AP上达到38.47,APS为22.98,FPS为17.57。当使用CSQ时,推理速度提高到19.03 FPS,APs有轻微损失。结果验证了我们的方法在加速两阶段检测器方面的有效性。
需要注意的是,在两阶段检测器中,我们的CSQ不仅可以节省在RPN中进行的密集计算时间,还可以减少传送到第二阶段的RoI数量。
5. Conclusion
We propose QueryDet that uses a novel query mechanism Cascade Sparse Query (CSQ) to accelerate the inference of feature pyramid-based dense object detectors. QueryDet enables object detectors the ability to detect small objects at low cost and easily deploy, making it practical to deploy them on real-time applications such as autonomous driving. For future work, we plan to extend QueryDet to the more challenging 3D object detection task that takes LiDAR point clouds as input, where the 3D space is generally sparser than 2D image, and computational resources are more intense for the costly 3D convolution operations.
















 2216
2216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









