







原文链接:https://arxiv.org/abs/2404.06892
1. 引言
自动驾驶系统包含检测、跟踪、在线建图、运动预测和规划步骤。传统模块化范式将该系统分解为单个任务,独立优化(下图)。这样的范式需要手工设计的后处理,且场景信息的有损压缩会导致误差积累。

因此,端到端自动驾驶方法以传感器数据为输入,并输出规划结果。早期方法跳过中间任务,直接预测规划结果,但其优化困难、性能较低、且可解释性差。另一方案则是将多个任务组成模块化的端到端模型,引入多维监督并进行多任务训练。

过去的模块化端到端模型中,场景的时空信息被表达为密集的BEV特征,这类方法称为以密集BEV为中心的范式(上图)。这类方法与单一任务方法的性能仍有较大差距,且多模态或多帧融合在密集BEV下进行,时空复杂度较高。
本文提出以稀疏查询为中心的范式(SparseAD),将时空元素表达为稀疏查询(下图),以实现更高效的端到端自动驾驶,且更容易扩展到更多模态和更多任务。
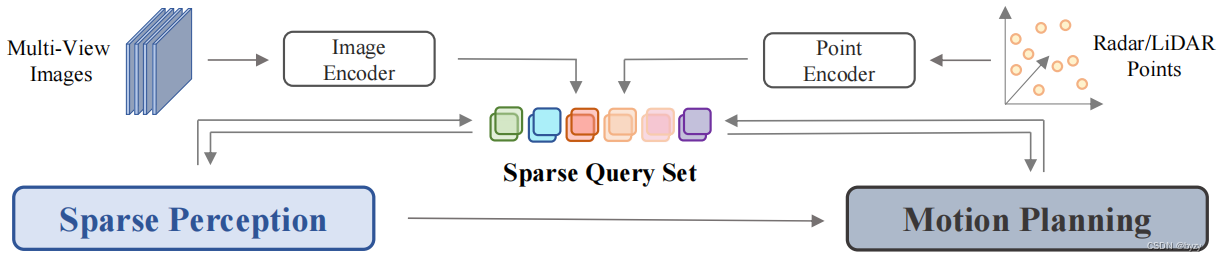
具体来说,本文将模块化端到端结构简化为稀疏感知和运动规划。在稀疏感知中,检测、跟踪和在线建图使用通用时间解码器进行统一,将多模态特征和历史记忆视为token,使用物体查询和地图查询表达障碍和道路元素。运动规划器使用稀疏感知查询作为环境表达,同时对自车和其余智能体进行多模态运动预测,得到自车的初始解,随后利用多维驾驶约束生成最终规划。
3. 方法
3.1 概述

模型结构如图所示。首先,传感器编码器将图像或点云编码为高维特征,作为传感器token,加入位置编码输入稀疏感知模块。稀疏感知模块会将token聚合为稀疏感知查询(如检测查询、跟踪查询和地图查询),并输入后续的下游任务。运动规划器会利用稀疏查询表达,并结合驾驶约束使轨迹满足安全性和运动学要求。此外,端到端多任务存储体会统一地存储时间信息,可进行时间聚合。
3.2 稀疏感知

稀疏感知模块有两个结构完全相同的时间解码器,分别用于障碍感知和在线建图。检测&跟踪头和贝塞尔地图头用于解码得到障碍和地图元素。随后,会进行更新过程过滤和存储当前帧高置信度的感知查询,并相应更新存储体,以便下一帧感知。
检测&跟踪:本文方法使用统一解码器联合进行检测与跟踪,无需手工后处理。
由于检测与跟踪查询的不平衡,会导致检测性能的下降。为减轻这一问题,本文引入两级存储机制,其中场景级别的存储保留查询信息,不进行跨帧关联,而实例级别的存储保持相邻帧跟踪物体的对应关系。此外,还对两种存储使用不同的更新策略,即通过MLN更新场景级别的存储,而通过对障碍的未来预测更新实例级别的存储。对跟踪查询的增广策略也能增加检测和跟踪性能。
最后,可从检测和跟踪查询中解码得到3D边界框和唯一ID,用于下游任务。
在线建图:初始时,带有先验类别的地图查询均匀分散在驾驶平面上。时间解码器会将这些地图查询与传感器token和历史存储token(对应过去帧高置信度的地图查询)交互,并使用更新后的地图查询更新存储体,用于后续帧或下游任务。该流程与障碍感知类似,因此本文将感知任务(检测、跟踪、在线建图)以通用的稀疏方式统一起来。
随后,使用分段贝塞尔地图头回归稀疏地图元素上的分段贝塞尔控制点,可方便地进行变换以满足下游任务要求。
3.3 运动规划器
多数运动预测方法没有考虑自车运动,会有潜在风险。本文同时预测自车和其余智能体的运动,并将自车运动预测结果作为规划的先验,结合其余方面的约束得到最终的轨迹规划结果。
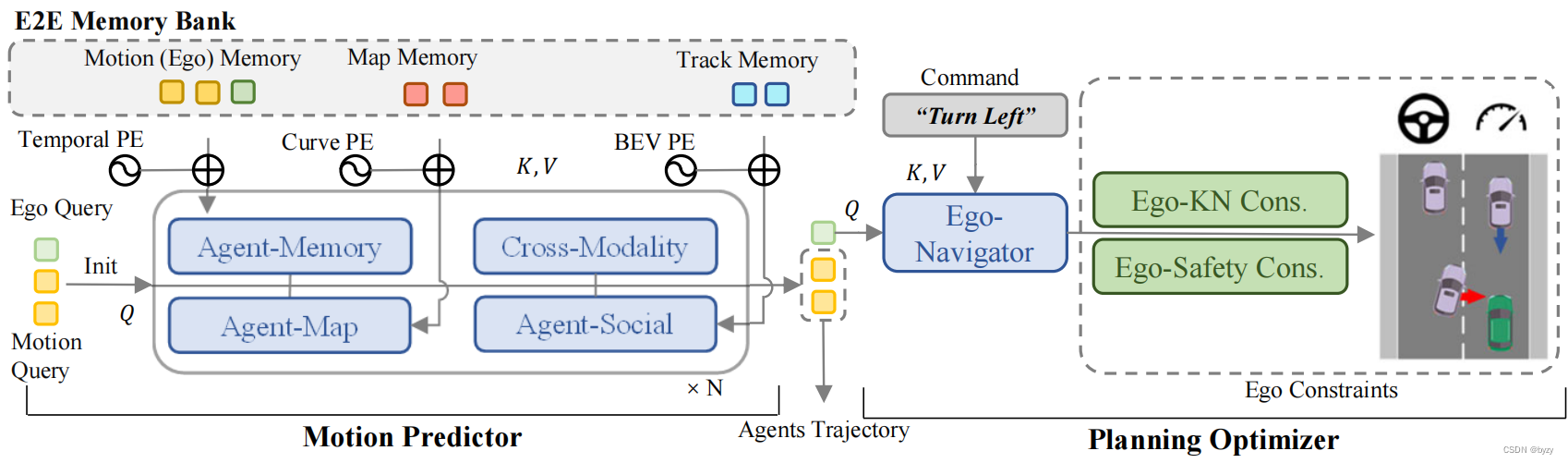
本文的运动规划器以感知查询(地图查询与跟踪查询)为输入,多模态运动查询为媒介实现驾驶场景的感知、智能体(含自车)的交互和不同未来可能性的博弈。自车的多模态运动查询会输入规划优化器,与高阶指令、驾驶约束结合,考虑安全性和运动学进行优化。
运动预测器:使用Transformer结构进行运动查询和场景表达之间的交互。
此外,本文引入跟踪查询的时间存储进行预测,作为运动查询的初始化,以利用上游任务的先验。还在智能体-存储聚合器中利用历史的跟踪查询信息。
自车运动预测会同时进行,且其结果会作为规划的先验。
规划优化器:代价函数是运动规划器的核心成分,影响甚至决定了结果的质量。本文主要考虑安全性和运动学。
安全性的考虑即自车与其余智能体的位置关系。例如,一个持续位于自车左前方的智能体会阻止自车向左运动,该智能体会被赋予“左”标签。这些约束被分为纵向约束(前、后、无)和横向约束(左,右,无)。本文从相应的查询中解码这些横向和纵向的约束,并使用focal损失作为自车-智能体关系(EAR)的代价函数:
L
EAR
=
−
∑
d
=
1
D
∑
i
=
1
A
∑
c
=
1
C
α
i
(
1
−
R
^
i
c
d
)
γ
log
(
R
^
i
c
d
)
L_\text{EAR}=-\sum_{d=1}^D\sum_{i=1}^A\sum_{c=1}^C\alpha_i(1-\hat R_{ic}^d)^\gamma\log(\hat R_{ic}^d)
LEAR=−d=1∑Di=1∑Ac=1∑Cαi(1−R^icd)γlog(R^icd)
其中 A A A为智能体数量, C C C为类别数, D D D为约束方向(横向、纵向)数; α i , γ \alpha_i,\gamma αi,γ为超参数。 R ^ i c d \hat R_{ic}^d R^icd为智能体 i i i在方向 d d d上有关系 c c c的概率。
由于规划的轨迹必须遵循运动学定律,本文还从自车查询
Q
ego
Q_\text{ego}
Qego学习自车的运动状态(速度、加速度、偏航角),并用运动学损失监督之:
L
LN
=
1
N
∑
i
=
1
N
(
Dec
(
Q
ego
)
i
−
status
i
)
L_\text{LN}=\frac1N\sum_{i=1}^N(\text{Dec}(Q_\text{ego})_i-\text{status}_i)
LLN=N1i=1∑N(Dec(Qego)i−statusi)
其中 N N N为自车状态的数量, status i \text{status}_i statusi为自车的第 i i i个真实状态。
4. 实验
4.1 综合性结果
与UniAD相比,SparseAD能以更快的速度和更小的内存消耗,达到更高的性能。感知任务上,本文方法的性能能提升超过50%。预测和规划任务上,本文方法的性能也有提升,这不仅仅是因为感知的性能提升,也是因为运动规划器的合理设计。
使用多模态输入或更换更大容量的模型时,性能均能得到提升。
4.2 多任务结果
障碍感知:本文方法的性能能超过大部分仅检测、仅跟踪或端到端多目标跟踪方法;且能与SotA达到相当的性能。
在线建图:SparseAD能超越大部分方法,但如何有效地与其余模态结合需要进一步探索。
运动预测:SparseAD在所有端到端方法中有最好的性能。
规划:SparseAD的性能能达到SotA。
4.3 消融
感知设计的作用:实验表明,引入场景级别的存储能有效提高检测和建图性能,但跟踪的性能因查询监督的不稳定性略有下降。两级存储的更新策略和增广策略使得不同查询的监督更加平衡,进一步提高感知性能。
运动规划设计的作用:没有运动预测器的策略(运动查询初始化或智能体-存储交互)或规划优化器的约束(KN或EAR)时,规划的性能会下降。
附录
B. 任务定义
在线建图:本文将地图视为分割线的稀疏表达,其中每个道路元素对应一组分割线,如分隔带、人行横道、道路边界和车道线。
C. 实施细节
C.1 问题定义
概述:本文以图像为主要输入,雷达点云可作为额外输入。设输入
I
1
,
⋯
,
I
N
I_1,\cdots,I_N
I1,⋯,IN为多视图图像,联合记为
I
∈
R
N
×
H
×
W
×
3
I\in\mathbb R^{N\times H\times W\times 3}
I∈RN×H×W×3,其中
N
N
N为视图数。点云为
P
∈
R
N
p
×
C
p
P\in\mathbb R^{N_p\times C_p}
P∈RNp×Cp,其中
N
p
N_p
Np为点数,
C
p
C_p
Cp为原始通道数。通过编码器
E
i
E_i
Ei与
E
p
E_p
Ep,可将图像和点云编码为
C
C
C维特征,并进一步编码为传感器token
F
t
∈
R
(
N
H
W
+
N
p
)
×
C
F_t\in\mathbb R^{(NHW+N_p)\times C}
Ft∈R(NHW+Np)×C:
F
t
=
Concat
(
Flatten
(
F
I
)
,
Flatten
(
F
P
)
)
F_t=\text{Concat}(\text{Flatten}(F_I),\text{Flatten}(F_P))
Ft=Concat(Flatten(FI),Flatten(FP))
其中 F I = E i ( I ) , F P = E p ( P ) F_I=E_i(I),F_P=E_p(P) FI=Ei(I),FP=Ep(P)。
传感器token的位置编码(PE)会与token拼接,其中图像特征使用3D-PE(参考PETR),点云特征使用BEV-PE(CMT)。
本文的查询分为两类,初始化查询 Q i Q^i Qi(可学习权重,获取目标分布的先验特征)和端到端多任务存储体(EMMB)中的存储查询 Q m Q^m Qm(用于传播时间信息,或给下游任务传递上游信息)。
稀疏感知:可学习检测查询 Q d i ∈ R N d i × C Q^i_d\in\mathbb R^{N_d^i\times C} Qdi∈RNdi×C和地图查询 Q o i ∈ R N o i × C Q^i_o\in\mathbb R^{N_o^i\times C} Qoi∈RNoi×C分别表示障碍和地图元素。同时,EMMB中的时间信息作为存储查询,由场景级别的存储(检测查询 Q d m ∈ R N d m × C Q^m_d\in\mathbb R^{N_d^m\times C} Qdm∈RNdm×C和地图查询 Q o m ∈ R N o m × C Q^m_o\in\mathbb R^{N_o^m\times C} Qom∈RNom×C)和 T − 1 T-1 T−1时刻实例级别的存储(跟踪查询 Q t , T − 1 m ∈ R N i m × 1 × C Q^m_{t,T-1}\in\mathbb R^{N_i^m\times1\times C} Qt,T−1m∈RNim×1×C)。
稀疏感知模块会输出障碍的细节信息(坐标、大小、ID、速度)、地图元素的细节信息(贝塞尔控制点,采样点)和上下文丰富的查询。查询会送入下游运动规划器中;也会用于更新EMMB用于未来帧的感知。
运动规划器:由于智能体数目不定,本文为所有运动查询定义共享的可学习嵌入 E n ∈ R 1 × C E_n\in\mathbb R^{1\times C} En∈R1×C,并将每个实例的历史轨迹 τ h \tau_h τh通过MLP和交叉注意力进行编码,以聚合实例的历史感知信息( Q t m ∈ R N i m × M × C Q_t^m\in\mathbb R^{N_i^m\times M\times C} Qtm∈RNim×M×C,其中 M M M为最大的历史帧数),并与可学习嵌入 E n E_n En组合作为初始化运动查询 Q n i ∈ R N i m × C Q_n^i\in\mathbb R^{N_i^m\times C} Qni∈RNim×C。
特别地,本文编码自车的历史轨迹 τ e h \tau_{eh} τeh,并与特殊的自车嵌入 E e ∈ R 1 × C E_e\in\mathbb R^{1\times C} Ee∈R1×C作为自车查询 Q e i ∈ R 1 × C Q_e^i\in\mathbb R^{1\times C} Qei∈R1×C的初始化。
还引入实例的存储运动查询 Q n m ∈ R N i m × M × C , Q e m ∈ R 1 × M × C Q_n^m\in\mathbb R^{N_i^m\times M\times C},Q_e^m\in\mathbb R^{1\times M\times C} Qnm∈RNim×M×C,Qem∈R1×M×C,并以来自稀疏感知的当前帧智能体和地图元素的稀疏表达 Q t , T m ∈ R N i m × 1 × C , Q o ∈ R N o i × C Q^m_{t,T}\in\mathbb R^{N_i^m\times 1\times C},Q_o\in\mathbb R^{N_o^i\times C} Qt,Tm∈RNim×1×C,Qo∈RNoi×C作为token,与运动查询和自车查询进行交互,生成高质量多模态运动预测轨迹 τ ^ \hat\tau τ^。
接着,自车查询被送入规划优化器,考虑安全性和运动学约束,生成安全可靠的自车轨迹规划 τ ^ e \hat\tau_e τ^e。
C.2 稀疏感知
参考StreamPETR,稀疏感知模块的时间解码器表达如下:
Q
c
=
Temporal_Decoder
(
Query
,
Tokens
,
Memory
)
Q^c=\text{Temporal\_Decoder}(\text{Query},\text{Tokens},\text{Memory})
Qc=Temporal_Decoder(Query,Tokens,Memory)
对于检测&跟踪任务,本文从场景级别的检测存储查询
Q
d
m
Q_d^m
Qdm中选择最近更新的前
K
d
K_d
Kd个查询
Q
d
k
m
∈
R
K
d
×
C
Q_{dk}^m\in\mathbb R^{K_d\times C}
Qdkm∈RKd×C,与可学习检测查询
Q
d
i
Q_d^i
Qdi和实例级别的跟踪查询
Q
t
,
T
−
1
m
Q^m_{t,T-1}
Qt,T−1m一起作为时间解码器的Query输入。所有检测存储查询
Q
d
m
Q_d^m
Qdm和传感器token
F
t
F_t
Ft分别作为Memory和Tokens输入。因此,检测&跟踪任务的解码器为
Q
d
c
=
Temporal_Decoder
(
Concat
(
Q
d
k
m
,
Q
d
i
,
Q
t
,
T
−
1
m
)
,
F
t
,
Q
d
m
)
Q^c_d=\text{Temporal\_Decoder}(\text{Concat}(Q^m_{dk},Q_d^i,Q^m_{t,T-1}),F_t,Q^m_d)
Qdc=Temporal_Decoder(Concat(Qdkm,Qdi,Qt,T−1m),Ft,Qdm)
其中 Q d c ∈ R ( K d + N d i + N i m ) × C Q^c_d\in\mathbb R^{(K_d+N^i_d+N^m_i)\times C} Qdc∈R(Kd+Ndi+Nim)×C。
在线建图任务解码器的输入类似,但由于无需分配ID,更加简单。本文从场景级别的地图存储查询
Q
o
m
Q_o^m
Qom中选择最近更新的前
K
o
K_o
Ko个查询
Q
o
k
m
∈
R
K
o
×
C
Q^m_{ok}\in\mathbb R^{K_o\times C}
Qokm∈RKo×C,与可学习在线建图查询
Q
o
i
Q_o^i
Qoi一起作为时间解码器的Query输入。所有地图存储查询
Q
o
m
Q_o^m
Qom和传感器token
F
t
F_t
Ft分别作为Memory和Tokens输入。因此,在线建图任务的解码器为
Q
o
c
=
Temporal_Decoder
(
Concat
(
Q
o
k
m
,
Q
o
i
)
,
F
t
,
Q
o
m
)
Q^c_o=\text{Temporal\_Decoder}(\text{Concat}(Q^m_{ok},Q_o^i),F_t,Q^m_o)
Qoc=Temporal_Decoder(Concat(Qokm,Qoi),Ft,Qom)
其中 Q o c ∈ R ( K o + N o i ) × C Q^c_o\in\mathbb R^{(K_o+N^i_o)\times C} Qoc∈R(Ko+Noi)×C。
对于
Q
d
c
Q_d^c
Qdc,本文使用基于DETR的检测&跟踪头将其解码为3D边界框;对于
Q
o
c
Q_o^c
Qoc,参考BeMapNet,本文将稀疏地图元素视为分段贝塞尔曲线,使用贝塞尔地图头回归贝塞尔曲线参数(显式控制点、隐式控制点、段数和置信度等)。本文基于解码的贝塞尔曲线参数,在每个地图元素上均匀采样
S
S
S个点,采样任意点的公式如下:
p
(
t
)
=
∑
i
=
0
n
b
i
,
n
(
t
)
c
i
,
t
∈
[
0
,
1
]
p(t)=\sum_{i=0}^nb_{i,n}(t)c_i,t\in[0,1]
p(t)=i=0∑nbi,n(t)ci,t∈[0,1]
其中
c
c
c为贝塞尔曲线段的系数,且
b
i
,
n
(
t
)
=
(
n
i
)
t
i
(
1
−
t
)
n
−
i
,
i
=
0
,
⋯
,
n
b_{i,n}(t)=\begin{pmatrix}n\\i\end{pmatrix}t^i(1-t)^{n-i},i=0,\cdots,n
bi,n(t)=(ni)ti(1−t)n−i,i=0,⋯,n
其中 n n n为贝塞尔曲线的阶数。通过采样,可得地图曲线点 P o c ∈ R ( K o + N o i ) × S × 2 P_o^c\in\mathbb R^{(K_o+N_o^i)\times S\times2} Poc∈R(Ko+Noi)×S×2。
C.3 运动规划器
本文将对应 Q d c ∈ R ( K d + N d i + N i m ) × C Q^c_d\in\mathbb R^{(K_d+N^i_d+N^m_i)\times C} Qdc∈R(Kd+Ndi+Nim)×C的 K d + N d i + N m i K_d+N_d^i+N_m^i Kd+Ndi+Nmi个障碍视为实例,故运动规划器的实例数为 N i c = K d + N d i + N m i N_i^c=K_d+N_d^i+N_m^i Nic=Kd+Ndi+Nmi。对新出现的 K d + N d i K_d+N_d^i Kd+Ndi个实例,本文为其生成虚拟历史信息。与 N m i N_m^i Nmi个存储实例统一视为存储实例。
可从EMMB中获取智能体和自车的历史位置信息 P i m ∈ R N i c × M × 3 P_i^m\in\mathbb R^{N_i^c\times M\times 3} Pim∈RNic×M×3和 P e m ∈ R 1 × M × 3 P_e^m\in\mathbb R^{1\times M\times 3} Pem∈R1×M×3,并使用共享的MLP编码历史轨迹,得到历史轨迹嵌入 H i ∈ R N i c × C H_i\in\mathbb R^{N_i^c\times C} Hi∈RNic×C和 H e ∈ R 1 × C H_e\in\mathbb R^{1\times C} He∈R1×C。
进一步利用多头交叉注意力(MHCA)聚合历史感知信息:
H
p
i
=
MHCA
(
H
i
,
Q
t
m
)
H_{pi}=\text{MHCA}(H_i,Q_t^m)
Hpi=MHCA(Hi,Qtm)
其中
H
p
i
∈
R
N
i
c
×
C
H_{pi}\in\mathbb R^{N_i^c\times C}
Hpi∈RNic×C为实例的历史嵌入。智能体的可学习运动查询的初始化是共享的,而自车查询是单独的可学习嵌入。可按下式得到运动查询和自车查询:
Q
n
i
=
H
p
i
+
E
n
,
Q
e
i
=
H
e
+
E
e
Q_n^i=H_{pi}+E_n,Q_e^i=H_e+E_e
Qni=Hpi+En,Qei=He+Ee
在模型预测中,自车查询与运动查询等价,因此统一记为 Q n i Q_n^i Qni,相应的存储运动查询统一记为 Q n m Q_n^m Qnm。
本文首先将训练集中智能体的未来轨迹通过K均值方法生成 K K K个共享的轨迹锚,并映射为高维特征嵌入,与运动查询组合得到多模态运动查询 Q m n i ∈ R N i c × K × C Q_{mn}^i\in\mathbb R^{N_i^c\times K\times C} Qmni∈RNic×K×C(后续仍记为 Q n i Q_n^i Qni)。
模型预测器包含
N
N
N层Transformer层,每层包括3种交互:智能体-存储,智能体-地图,智能体-社会。 即运动查询
Q
n
i
Q_n^i
Qni会与存储运动查询
Q
n
m
Q_n^m
Qnm、当前帧的检测跟踪查询
Q
d
c
Q_d^c
Qdc和当前帧的在线建图查询
Q
o
c
Q_o^c
Qoc交互:
Q
n
c
=
MHCA
(
MHSA
(
Q
n
i
)
,
Q
n
m
/
Q
d
c
/
Q
o
c
)
Q_n^c=\text{MHCA}(\text{MHSA}(Q_n^i),Q_n^m/Q_d^c/Q_o^c)
Qnc=MHCA(MHSA(Qni),Qnm/Qdc/Qoc)
其中 Q n c ∈ R N i c × C Q_n^c\in\mathbb R^{N_i^c\times C} Qnc∈RNic×C为更新后的运动查询;类似的 Q e c ∈ R 1 × C Q_e^c\in\mathbb R^{1\times C} Qec∈R1×C为更新后的自车查询。
对于智能体和存储运动查询的交互,本文还设计时间PE将同一智能体的预测轨迹跨时间关联,记智能体
i
i
i在
T
T
T时刻的未来
L
L
L步中的预测轨迹为
F
T
i
=
{
v
1
,
⋯
,
v
L
}
F_T^i=\{v_1,\cdots,v_L\}
FTi={v1,⋯,vL},其中
v
∈
R
3
v_\in\mathbb R^3
v∈R3为3D位置。存储中的历史预测轨迹为
{
F
T
−
1
i
,
⋯
,
F
T
−
M
i
}
\{F_{T-1}^i,\cdots,F_{T-M}^i\}
{FT−1i,⋯,FT−Mi},其中
M
M
M为存储的最大长度。假定历史预测轨迹已被转换到当前自车坐标系下,则存储运动查询的时间PE
E
n
m
E_n^m
Enm和当前运动查询的时间PE
E
n
c
E_n^c
Enc为
E
n
m
=
∑
k
=
1
N
MLP
k
(
Cat
(
{
v
j
−
v
k
∣
j
≥
k
,
v
∈
F
T
−
k
i
}
)
)
E
n
c
=
∑
k
=
1
N
MLP
k
(
Cat
(
{
v
j
−
v
0
∣
j
≤
M
−
k
,
v
∈
F
T
i
}
)
)
E_n^m=\sum_{k=1}^N\text{MLP}_k(\text{Cat}(\{v_j-v_k|j\geq k,v\in F_{T-k}^i\}))\\ E_n^c=\sum_{k=1}^N\text{MLP}_k(\text{Cat}(\{v_j-v_0|j\leq M-k,v\in F_T^i\}))
Enm=k=1∑NMLPk(Cat({vj−vk∣j≥k,v∈FT−ki}))Enc=k=1∑NMLPk(Cat({vj−v0∣j≤M−k,v∈FTi}))
对于智能体和在线建图查询的交互,本文设计了曲线PE以精确描述稀疏地图元素的位置信息:
E
o
c
=
∑
k
=
1
J
MLP
(
Flatten
(
P
o
c
)
)
E_o^c=\sum_{k=1}^J\text{MLP}(\text{Flatten}(P_o^c))
Eoc=k=1∑JMLP(Flatten(Poc))
其中 P o c P_o^c Poc为前文介绍的采样点。
对于智能体和社会(即跟踪查询)的交互,本文使用BEV PE描述智能体的位置信息(见CMT文章)。
更新后的运动查询 Q n c Q_n^c Qnc会用于解码多模态轨迹。本文仅监督与真值最接近的轨迹。
进行自车查询与驾驶指令的交互后,规划优化器考虑自车-地图约束、自车-智能体约束和自车-运动学约束。本文利用其余智能体和自车的未来轨迹描绘横向和纵向的相互约束。自车-智能体约束标签的生成见下面的算法。

使用生成的约束标签,按3.3节的方法监督规划优化器,得到最终的规划输出。
C.4 框架总结
进行稀疏感知和运动规划的推断后,SparseAD会将多任务信息更新到EMMB中,为未来帧提供先验。这些信息包括更新后的查询(检测&跟踪查询 Q d c Q_d^c Qdc,在线建图查询 Q o c Q_o^c Qoc,运动查询 Q n c Q_n^c Qnc和自车查询 Q e c Q_e^c Qec),以及相应的解码信息(3D边界框、贝塞尔曲线控制点、采样点、多模态预测轨迹、自车规划轨迹等)。注意当EMMB的存储查询被传播到下一帧时,需要对位置信息进行自车变换,以消除自车运动的影响。
具体来说,本文在EMMB中存储置信度最高的
K
d
K_d
Kd个
Q
d
c
Q_d^c
Qdc查询
Q
d
k
c
∈
R
K
d
×
C
Q_{dk}^c\in\mathbb R^{K_d\times C}
Qdkc∈RKd×C作为场景级检测查询。同时,根据阈值
T
T
T选择
Q
d
c
Q_d^c
Qdc中置信度高的查询,作为实例级跟踪查询
Q
t
c
Q_t^c
Qtc,并为相应的实例分配唯一ID,且相应的下游查询(即运动查询)会被存储为实例级的存储(对应无ID检测查询的运动查询被丢弃)。

EMMB如图所示。本文使用两种不同策略保留场景级和实例级存储。对于场景级存储,将存储视为帧单元,并以FIFO原则存取,即总是存储过去
M
M
M帧的感知信息。实例级存储作为实例单元,对属于同一实例存储的存取遵循FIFO原则。若有新障碍被检测到,则为实例级存储添加新的实例并存储相应信息。当实例在连续帧中未被检测到,实例及其相应的历史信息会被移除。两级存储设计可使模型利用全局(场景)和局部(实例)的时间信息,实现端到端自动驾驶的高性能。
D. 实验
D.2 配置细节
稀疏感知:对每个存储的跟踪查询,本文设置丢弃概率和引入近似负样本的概率,以平衡实例级跟踪查询和场景级检测查询的监督。
训练和推断:训练分为3个阶段。第一阶段训练稀疏感知模块;第二阶段引入两级存储以优化跟踪性能;第三阶段冻结主干和稀疏感知模块,训练运动规划器。前两个阶段也可合并,以微小的性能下降换取更快的训练。
D.4 补充实验
测试集上的评估:本文方法与其余检测/跟踪方法性能相当,但仍低于SotA的单一任务方法。增加主干模型容量可略微超过SotA方法的性能。
端到端梯度优化:训练阶段3并未进行端到端梯度优化,但当进行端到端梯度优化后,运动预测和规划的性能会略微上升,且带来的存储提升可接受,但感知的性能略有下降。
D.5 运行时间分析
实验表明,稀疏感知为主干网络外模型的主要耗时部分。
E. SparseAD的变体
E.1 动机和方法
动机:检测和跟踪查询会有监督不平衡问题,会导致检测性能下降并影响跟踪性能。本文发现来自过去帧的场景级的检测存储查询可在一定程度上作为跟踪查询。场景级检测存储查询不会通过ID与真实实例绑定,因此不会受监督不平衡的影响。因此,可能仅依靠场景级检测存储查询实现端到端跟踪,而不会降低检测性能。
方法:训练时,丢弃实例级存储跟踪查询,从而可省略训练阶段2。同时,调整可学习检测查询和场景级检测存储查询的比例,以保证跟踪的一致性。为替换跟踪查询,本文将匹配同一真值的检测查询拼接作为新实例(即实例的历史信息可能来自不同检测查询)。
推断时,对应场景级检测存储查询的边界框会继承上一帧的ID,而对应可学习检测查询的边界框会被分配新的ID。同样拼接ID相同的查询得到新实例,用于下游任务。
其余细节与附录C.3中一致。
E.2 验证实验
上述无硬关联的SparseAD在感知任务的某些指标上有明显性能提升(但IDS也有所提升),且预测和规划任务的性能相当。
F. 对碰撞率指标的讨论
本文认为,目前常用的碰撞率计算有两个模型不足之处:首先,传统指标没有考虑自车朝向变化,如在转弯场景中边界框的朝向保持朝前,如同车辆在直行(下左图)。其次,由于需要平衡效率和精度,占用网格的分辨率有限,其大小远超过最小安全距离(下右图)。
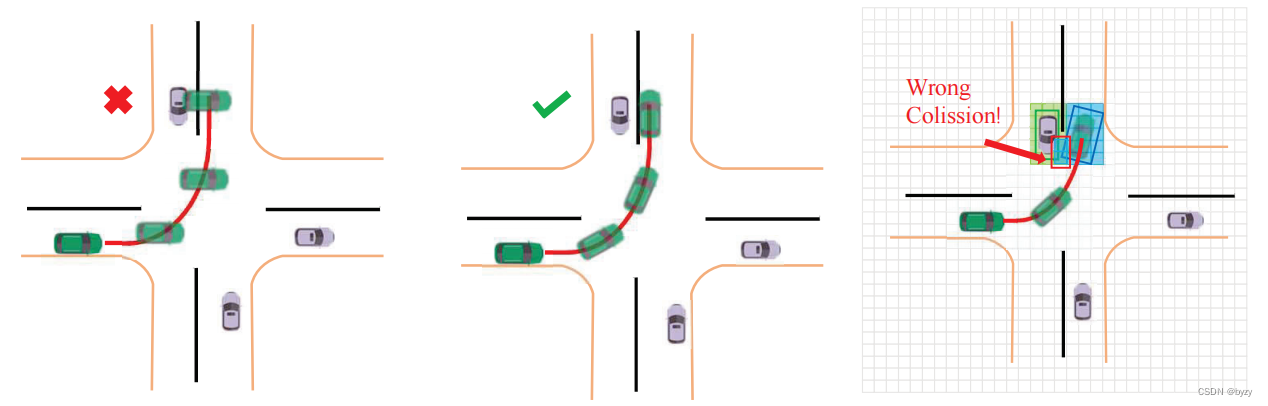
由于IMU的不精确性,自车的位置可能有微小偏移,从而与其余智能体碰撞。智能体的真实轨迹应该是无碰撞的,但按照传统指标计算,碰撞率会超过10%,即便考虑IMU的误差,这也是不可能且不可接受的结果。
多数误判的碰撞情况属于困难案例,是规划评估的关键。本文提出基于稀疏的方法计算真实而精确的碰撞状态,以进行可靠评估。具体来说,计算每一帧的碰撞时,需要考虑每个障碍的位置和朝向,并通过规划轨迹当前帧和未来帧的位置比较近似自车朝向。该方法无需依赖占用网格,仅在自车边界框与其余障碍的边界框出现重叠时计算碰撞率。
实验表明,改用上述方法计算后,真实轨迹的碰撞率下降到接近0的值。UniAD的碰撞率也大幅下降。
















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











