






《Model Degradation Hinders Deep Graph Neural Networks》——KDD2022
摘要:
图神经网络( Graph Neural Networks,GNNs )在各种图挖掘任务中取得了巨大的成功。然而,当一个GNN由许多层堆叠时,通常会观察到严重的性能下降。因此,大多数GNN仅具有浅层结构,这限制了其表达能力和对深层邻域的利用。最近的研究大多将深度GNN的性能下降归因于过平滑问题。在本文中,我们将传统的图卷积操作解耦为两个独立的操作:传播( P )和转化( T )。这样,一个GNN的深度可以拆分为传播深度( Dp )和变换深度( Dt )。通过大量实验,我们发现导致深度GNN性能下降的主要原因是Dt较大导致的模型退化问题,而不是Dp较大导致的过平滑问题。进一步地,我们提出了自适应初始残差( Adaptive Initial Residual,AIR )模块,该模块是一个即插即用的模块,可以兼容各种GNN架构,以同时缓解模型退化问题和过平滑问题。在6个真实数据集上的实验结果表明,搭载AIR的GNN性能优于大多数浅层结构的GNN,这得益于较大的Dp和Dt,但时间开销也较大。
关键词:empirical analysis, graph neural networks, plug-and-play module
代码:https://github.com/pku-dair/air
1 介绍:
由图卷积网络( Graph Convolutional Network,GCN )提出的图卷积操作逐渐成为大多数GNN模型图层设计的规范形式。具体来说,GCN中的图卷积操作可以拆解为两个独立的操作:传播( Propagation,P )和转换( Transformation,T )。P操作可以看作是拉普拉斯平滑的一种特殊形式[在此之后,邻近节点的表示将变得相似。P操作极大地降低了下游任务的难度,因为大多数现实世界的图都遵循同质性假设,即连接的节点倾向于属于相似的类。T操作对节点表示进行非线性变换,从而使模型能够捕获训练样本的数据分布。解纠缠后,GNN的深度被拆分为传播深度( Dp )和变换深度( Dt )。具有较大Dp的GNN可以使每个节点从更深的邻域中挖掘信息,而较大的Dt则赋予模型更高的表达能力。
在本文中,我们对深度GNN中的过平滑问题进行了全面的分析,并试图找出导致深度GNN性能下降的主要原因。我们发现,经过数十次P运算后,确实出现了过平滑问题,但深度GNNs的性能退化观察到早于过度平滑问题的出现。因此,过平滑问题并不是导致深度GNN性能下降的主要原因。
实验结果表明性能下降的主要原因是大Dt (也就是说,堆叠许多T运算)引起的模型退化问题。模型退化问题自文献[ 15 ]讨论以来就为社会各界所熟知。它是指当网络的层数增加时,训练精度和测试精度都下降的现象。虽然两者都是由增加层数引起的,但模型退化问题不同于过拟合问题,因为后者的训练精度仍然很高。
为了帮助GNNs同时享受大Dp和Dt带来的好处,我们提出了自适应初始残差( Adaptive Initial Residual,AIR ),一种即插即用的模块,可以很容易地与各种GNN架构相结合。AIR在P和T操作之间引入自适应跳跃连接,同时缓解了模型退化问题和过平滑问题。
2 前言
我们首先对问题的提出进行说明。然后我们将GCN中的图卷积操作分解为两个独立的操作:传播( P )和变换( T )。这种解缠将GNN模型的深度分解为传播深度( Dp )和变换深度( Dt )。之后,将简要讨论增大Dp和Dt的理论好处。最后,我们根据P和T操作的顺序将现有的GNN架构分为三类。
2.1 问题
在本文中,我们关注于半监督的节点分类任务,其中V中只有部分节点被标记。Vl表示已标记的节点集合,Vu表示未标记的节点集合。其中该任务的目标是在V1中节点标签的有限监督下,预测Vu中节点的标签。
2.2 Graph Convolution Operation
GCN中的图卷积操作表述为:
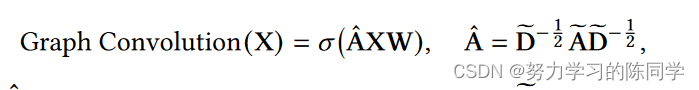
从直观上看,GCN中的图卷积操作首先将每个节点的表示传播到其邻域,然后通过非线性变换将传播的表示变换到特定维度
2.3 Propagation (P) and Transformation (T) Operations
图卷积操作可以分解为实现不同功能的两个连续操作:传播( P )和转换( T )。它们对应的公式形式如下:
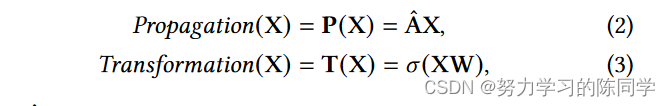
进行图卷积运算等价于先进行P运算再进行T运算,可表示为如下形式:
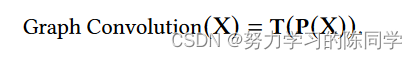
通过两个新的度量来更精确地描述GNNs的深度:传播深度( Dp )和转换深度( Dt )
2.4 深度GNN的理论优势
我们将简要讨论深度GNNs的理论好处,并说明增大Dp和Dt都会提高模型的表达能力。
2.4.1 扩大Dp的好处
增大Dp相当于扩大了每个节点的感受野。文献[ 29 ]证明了GCN与一阶Weisfeiler - Lehman图同构测试具有相同的表达能力。因此,扩大每个节点的感受野使得模型更容易区分两个不同的节点,因为它们具有高度不同的感受野的可能性更大。有文献证明了一旦模型训练得当,由于感受野的扩大,GCN的表达能力随着层数的增加而严格增长。总的来说,增大Dp可以提高模型的表达能力,这可以从Weisfeiler - Lehman检验的角度得到证明。
2.4.2 扩大Dt的好处
众所周知,多层感知器( Multi-Layer感知器,MLP )的表达能力随着层数的增加而严格增长。如前一节介绍的,Dt表示模型中包含的非线性变换的个数。因此,增大Dt,即增加非线性变换的个数,也可以提高模型的表达能力。
2.5 三大类GNN架构
根据模型安排P和T操作的顺序,我们将现有的GNN架构大致分为三类:PTPT、PPTT和TTPP。
3 过平滑问题的经验分析
我们首先定义了平滑度,并在节点和图层面引入度量指标对其进行度量。然后,我们回顾了过度平滑问题及其产生的原因。本节其余部分是实证分析,试图弄清过度平滑问题是否是导致深度GNN性能下降的主要原因。
平滑度衡量了图中节点对之间的相似程度。具体来说,较高的平滑度水平表明从给定的节点集合中随机选择的两个节点相似的概率较高。
定义节点i的节点平滑度NSLi为:

The Graph Smoothing Level of the whole graph, 𝐺𝑆𝐿, is defined as:
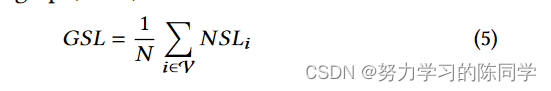
NSLi度量了图中节点i与其他节点之间的平均相似度。与N SLi相对应,GSL衡量的是图中节点对之间的平均相似度。值得注意的是,这两个指标都与平滑度水平正相关。
3.2 审视过平滑问题
过平滑问题[ 23 ]描述了节点的输出表示在GNN模型输出之后变得不可区分的现象。而当GNN模型堆叠层数较多时,往往会出现过平滑的问题。
在GCN采用的传统PTPT架构中,Dp和Dt被限制为具有相同的值。然而,在本文对图卷积操作进行解纠缠后,只分析放大Dp或Dt所引起的各自效应是可行的。在下面的分析中,我们将表明一个巨大的Dp是过度平滑问题出现的实际原因。
过平滑问题与Dp,Dt的关系:巨大的Dp是过平滑出现的实际原因(理论分析),非线性变换个数Dt的增大对过平滑问题的出现没有直接影响(实证分析)
为什么扩大Dp模型容易出现过平滑?
每次归一化的邻接矩阵( A与输入矩阵X相乘,每个节点可以获得多一跳的信息。然而,如果对同一连通分支施加无限次的P操作,则同一连通分支内的节点表示将达到一个稳定的状态,从而导致不可区分的输出。
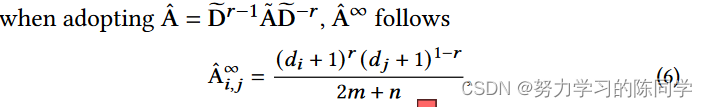
这表明,当Dp趋近于∞时,节点j对节点i的影响仅由其节点度决定。相应地,每个节点的独特信息被充分平滑,从而导致不可区分的表示,即过度平滑问题。
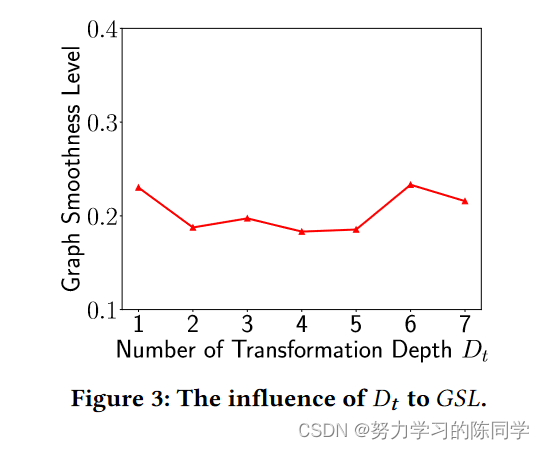
Dt的增大对过平滑问题的出现没有直接影响
在cora数据集上,运用SGC模型,保持Dp不变的情况下,增大Dt,观察GSL
3.3 过平滑问题是否是模型性能下降的主要原因
大多数先前的研究声称过度平滑问题是导致深度GNNs失效的主要原因。针对深度GNNs的设计,已经有了一系列的工作。例如,DropEdge在训练时随机删除边,Grand在传播前随机丢弃节点的原始特征。尽管他们能够在保持甚至达到更好的预测准确性的同时更深入地进行研究,但对其有效性的解释却存在一定的误导性。作者通过实证分析证明
3.3.1 Dp与GSL的关系
当Dp从一个相对较小的值增长时,过度平滑问题(即图的GSL )出现的风险的变化趋势并没有被揭示。为了评估放大Dp对图的GSL的单一影响,我们在PPTT GNN模型SGC [ 39 ]中放大Dp,并测量所有P操作后中间节点表示的GSL。
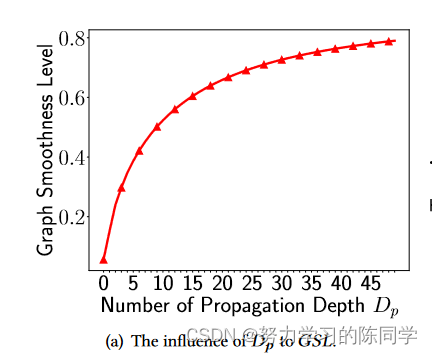
结论:随着Dp的增大,出现过度平滑问题的风险增大。
3.3.2 过平滑问题与模型性能的关系
GCN及修改后的GCN模型,pubmed数据集
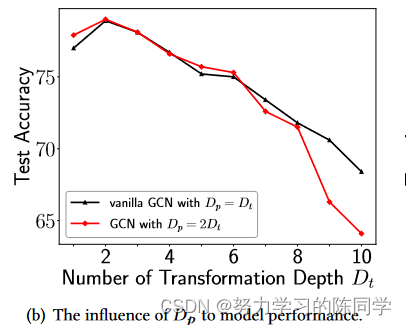
假设过平滑问题是导致深度GNN性能下降的主要原因,则Dp = 2Dt的GCN的分类精度应远低于原始GCN的分类精度。
即使具有较大的Dp (也就是说,更高的平滑程度),当Dt从1到8时,Dp = 2Dt的GCN始终具有与原始GCN ( Dp = Dt)相似的分类精度,而当Dp超过16 ( 2 × 8 )时,过多的P操作似乎开始主导性能下降。然而,当Dp超过2时,原始GCN的性能开始急剧下降,远小于16 (图2 ( b )中出现了性能差距) )。
结论:考虑到即使在层数小于10的情况下,深度GNNs的性能下降也经常发生,过平滑问题可能并不是导致其性能下降的主要原因。
3.3.3 Dt与模型性能的关系(较大的Dt主导了性能退化)。
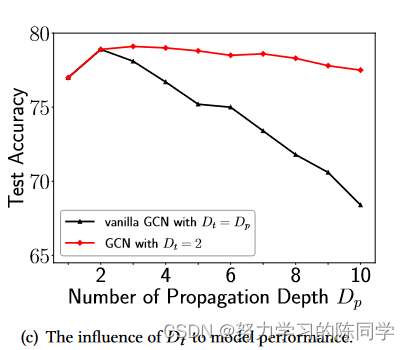
单独增大Dp会增加出现过度平滑问题的风险,但对性能的影响很小。
较大的Dp会损害深度GNNs的分类精度,但下降幅度相对较小。相反,较大的Dt是导致深度GNN性能下降的主要原因。
4 较大Dt背后得到了什么
作者探究了Dt与MLP之间的关系,当Dt增大时,MLP的分类精度也急剧下降。因此,大Dt引起的性能退化在MLP中同样存在。这提醒我们,缓解深度MLPs训练的方法也可能有助于缓解深度GNNs中大Dt导致的性能下降。
为此:
增加剩余或密集连接可以有效缓解深层MLPs中Dt较大导致的性能退化问题。同样该两种方法也适用深度GNN上。
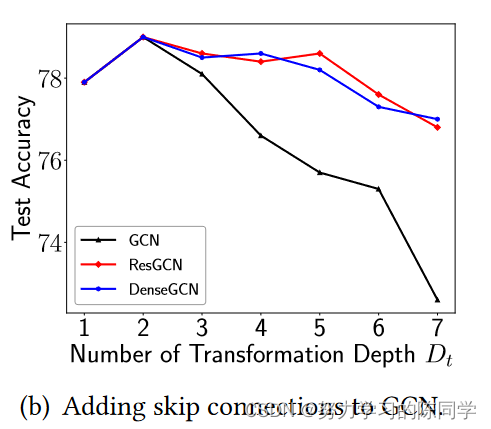
4.4 跳跃式连接在这里有什么帮助? -- 为什么Dt过大导致模型的性能下降
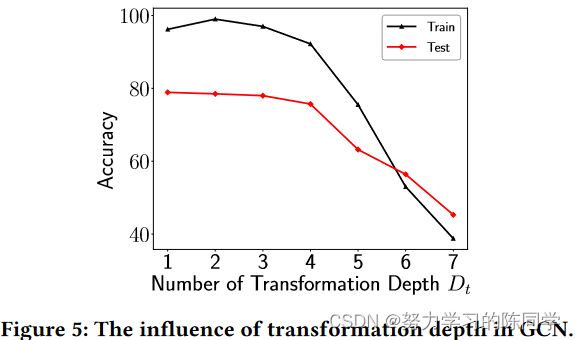
模式退化问题指随着模型深度的增加,模型性能达到饱和并迅速退化的现象。与过拟合问题不同的是,训练精度和测试精度都大幅下降,而不仅仅是测试精度的大幅下降。文献没有解释模型退化问题出现的原因,只是给出了一个简单的解决方案- -跳跃连接。最近的许多研究都在试图探索什么是导致模型退化问题的主要原因,并且大多从梯度的角度来研究这个问题[ 1 ]。在这里坐着的实验,深度GCN的训练精度和测试精度的变化趋势恰好与模型退化问题所指的现象一致。
结论:大Dt背后的模型退化问题是导致深度GNN性能下降的主要原因。此外,在层与层之间加入跳跃连接可以有效缓解深度GNN的性能下降。
5 自适应初始残差
作者提出了一个即插即用的自适应初始残差( Adaptive Initial Residual,AIR )模块,在P和T操作之间添加自适应初始残差连接。P操作之间的自适应初始残差连接旨在缓解过平滑问题并以节点自适应的方式利用更深层的信息,而T操作之间的自适应跳跃连接的主要目的是缓解模型退化问题。
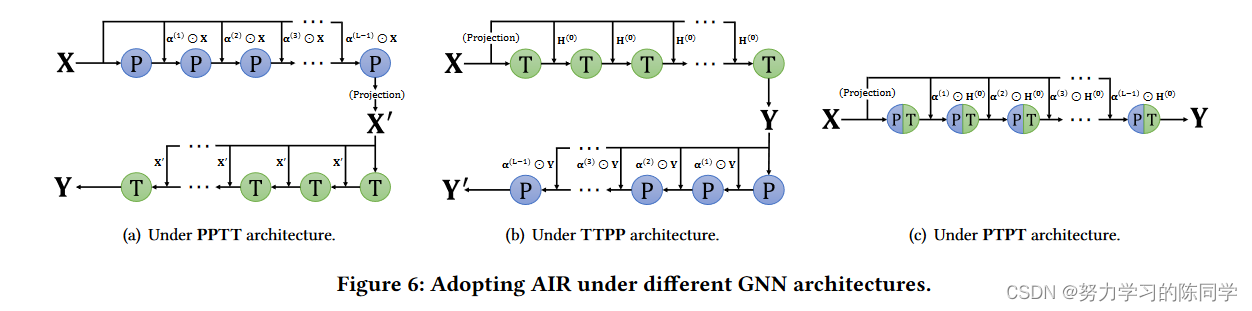
5.1. 1对于连续的P个操作序列,我们在每个P个操作处拉取节点i的输入特征H ( 0 ) i = Xi的自适应分数。


5.1.2 对于连续的T操作
T操作之间的连接排除了输入特征的可学习系数,取而代之的是固定的连接,因为这两种方式在该场景下几乎等价。

总结:配备AIR的P操作直接从原始输入中拉取自适应量,并将其与前一个P操作生成的表示矩阵进行融合。融合后的矩阵被认为是第l个P操作的新输入。配备了AIR的T操作将前一个T操作的输出和固定数量的原始输入相加。
6 实验
详情看论文吧
之后想看的论文
《ORDERED GNN: ORDERING MESSAGE PASSING TO DEAL WITH HETEROPHILY AND OVER-SMOOTHING》
ICLR2023的文章,有关图神经网络过平滑与异质的问题
代码:
https://github.com/LUMIA-Group/OrderedGNN
摘要:
大多数图神经网络遵循消息传递机制。然而,它在对图进行多次消息传递时面临着过度平滑的问题,导致无法区分节点表示,并阻止模型有效地学习较远节点之间的依赖关系。另一方面,具有不同标签的邻居节点的特征很可能被错误地混合,从而产生异构性问题。在这项工作中,我们提出将传递到节点表示中的消息进行排序,其中特定的神经元块用于特定跳数内的消息传递。这是通过将中心节点的根树的层次结构与其节点表示中的有序神经元对齐来实现的。在大量数据集上的实验结果表明,我们的模型可以在没有任何针对性设计的情况下,同时在同质性和异质性设置中达到最先进的水平。而且,在模型变得很深的同时,其性能也保持得很好,有效地防止了过平滑问题。最后,可视化门控向量表明我们的模型在同质性和异质性设置之间学习到了不同的行为,提供了一个可解释的图神经模型。

















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









