






一篇2023ICLR会议上的论文,看完之后接下来的工作就是对深度GNN、深度GNN模型性能以及过平滑问题三者关系进行总结论述。(虽然关于这里我的创新点还没有,但我要总结梳理我的工作)
所以12.6之前工作量:
1. 上次分享的论文的代码复现,以及再读,解决遗留问题
2. 本篇论文精读
3. 有关过平滑进行总结梳理。(12.5更新梳理中)
一、《Model Degradation Hinders Deep Graph Neural Networks》
之前汇报这篇论文的时候,总结文章的结论如下:
1. (过平滑与模型架构)巨大的Dp(传播深度)是过平滑出现的实际原因,非线性变换个数Dt的增大对过平滑问题的出现没有直接影响。
2. (模型性能下降与过平滑)考虑到即使在层数小于10的情况下,深度GNNs的性能下降也经常发生,过平滑问题可能并不是导致其性能下降的主要原因。
3. (模型性能下降与模型架构)较大的Dp会损害深度GNNs的分类精度,但下降幅度相对较小。相反,较大的Dt是导致深度GNN性能下降的主要原因。
为什么较大的Dt是导致深度模型性能下降的主要原因,如何导致的?为什么要堆叠多个Dt。(解决这个问题)
先明确这里的T操作:Transformation,先右乘W矩阵,再进行非线性激活
![]()
W是可学习的变换矩阵,σ是非线性激活函数
Dt的优势:
分析增大 Dt 时模型表现力的变化比增大 Dp 时更容易。众所周知,多层感知器(MLP)的表达能力严格随着层数的增加而增长。正如上一小节所介绍的,Dt 代表模型中包含的非线性变换的数量。因此,扩大 Dt ,即增加非线性变换的数量,也会增加模型的表达能力
在图神经网络中,如果只有 T操作,则模型退化为MLP网络。
二、《A NON-ASYMPTOTIC ANALYSIS OF OVERSMOOTHING IN GRAPH NEURAL NETWORKS》
摘要:
过平滑是构建更强大的图神经网络( Graph Neural Networks,GNNs )的核心挑战。虽然先前的工作仅证明了当图卷积的数量趋于无穷时,过度平滑是不可避免的,但在本文中,我们通过非渐近分析精确地刻画了现象背后的机制。具体来说,我们在应用图卷积时区分了两种不同的效果-——一种将不同类中的节点表示同质化的不良混合效果,以及一种将相同类中的节点表示同质化的理想去噪效果。通过量化这两种效应对从上下文随机块模型( CSBM )中采样的随机图的影响,我们证明了对于具有N个节点的足够稠密的图,一旦混合效应开始主导去噪效果,就会发生过度平滑,并且这种过渡所需的层数为O( log N / log ( log N) )。我们还将我们的分析扩展到研究个性化PageRank ( PPR )的影响,或者等价地,研究初始残差连接对过度平滑的影响。我们的结果表明,虽然PPR在较深的层上缓解了过度平滑,但基于PPR的架构在较浅的深度上仍然取得了最好的性能,并且在某些图上优于图卷积方法。最后,我们用数值实验来支持我们的理论结果,这进一步表明,在实践中观察到的过度平滑现象可以被优化深度GNN模型的难度放大。
先前观察:
对于较深的GNNs,重复的消息传递使得不同类中的节点表示不可区分,并导致较低的节点分类精——一种被称为过平滑的现象( oversmoothing)。通过图卷积可以被视为图信号上的低通滤波器的见解,先前的研究已经证实,当GNN的层数增加到无穷大( Li et al . , 2018 ; Oono & Suzuki , 2020)时,过度平滑是不可避免的。然而,这些渐近分析并不能完全解释当我们增加网络深度时过平滑现象的快速发生,更不用说对某些数据集来说,没有图卷积甚至是最优的。这些观察激发了以下关于GNNs中过度平滑的关键问题:
(1) 为什么在相对较浅的深度会发生过度平滑?
(2) 能否对应用有限数量的图卷积的效果进行定量建模,并从理论上预测深度选择的"甜点"。
本文贡献:
我们发现,图卷积的加入在增强去噪效果的同时也加剧了混合效应。过度平滑发生的原因是混合效应在超过一定深度的去噪效果中占主导地位。对于具有N个节点的充分稠密的CSBM图,发生这种情况所需的层数为O( logN / log ( logN) )。
我们应用我们的框架严格地刻画了PPR对过度平滑的影响。我们证明了PPR降低了消息传递的混合效应和去噪效应,因此并不一定提高节点分类性能。
我们在实验中验证了我们的理论结果。通过理论和实验的对比,我们发现在深度GNN架构中优化权重的难度往往会加剧过平滑。
知识点补充:
1. Contextual Stochastic Block Model (CSBM)
Contextual Stochastic Block Model (CSBM)是一种网络分析方法,用于对具有上下文信息的网络进行建模和推断。传统的随机块模型(Stochastic Block Model,SBM)假设网络中的节点可以分为几个块,每个块内的节点具有相似的连接模式,而不同块之间的连接模式不同。然而,SBM没有考虑节点的上下文信息,即节点之间的连接可能受到其他节点的影响。CSBM在SBM的基础上引入了上下文信息,以更好地描述网络的结构和节点之间的连接方式。CSBM考虑到节点的特征或环境,并将其纳入模型中。具体而言,CSBM假设节点的连接概率不仅取决于节点所属的块,还取决于节点的上下文信息。上下文信息可以是节点的特征向量,或者是节点周围的邻居节点的特征向量。CSBM的核心目标是通过观察网络的拓扑结构和节点的上下文信息,推断出模型中的参数,例如块之间的连接概率和上下文信息对连接概率的影响。这种建模方法可以帮助我们更好地理解网络的结构和节点之间的关系,并在社交网络分析、生物信息学、推荐系统等领域中发现隐藏的模式和结构。
Analysis of GNNs on CSBMs
随机块模型及其上下文模型在节点分类问题中具有优势,能够考虑节点的相似性和上下文信息,灵活地建模网络结构,并提供有效的参数估计方法。这使得它成为研究节点分类问题的有力工具。
2. 渐进分布与非渐进分布
渐进分布(asymptotic distribution)是概率论和统计学中的一个概念。它描述了在样本量趋向无穷大时,统计量的分布的极限行为。换句话说,渐进分布是指当样本量足够大时,统计量的分布将趋近于某个特定的分布。
非渐进分布(non-asymptotic distribution)是指在有限样本量情况下,统计量的分布。与渐进分布不同,非渐进分布考虑的是样本量有限的情况下,统计量的分布特征。
理论分析框架
CSBM 生成的图表示:G(A, X) ∼ CSBM(N, p, q, μ1, μ2, σ2)
将重点关注 CSBM 由大小相等的两类 C1 和 C2 节点组成的情况,总共有 N 个节点
- N:表示网络中的节点数量。
- p:表示同一块内两个节点之间的连接概率。块内的节点具有相似的连接模式。
- q:表示不同块之间两个节点之间的连接概率。不同块之间的连接模式可能不同。
- μ1:表示节点上下文信息对连接概率的影响。它是一个均值参数,用于模拟节点的上下文信息对连接概率的影响。
- μ2:表示节点上下文信息对连接概率的影响。它是另一个均值参数,用于模拟节点的上下文信息对连接概率的影响。
- σ2:表示节点上下文信息对连接概率的影响的方差。它是一个方差参数,用于模拟节点的上下文信息对连接概率的影响。
函数 G(A, X) 是在给定网络结构 A 和节点上下文信息 X 的情况下,根据 CSBM 模型生成的结果。它可以用于模拟或推断网络中节点之间的连接情况,考虑到节点的块结构和上下文信息的影响
CSBM 假设:
假设1:p, q = ω(log N/N ) and p > q > 0.
该假设确保生成的图 G 几乎肯定是连通的;该机制还保证了G具有较小的直径。众所周知,现实世界的图表现出“小世界”现象——即使节点数量 N 非常大,图的直径仍然很小。
选择 p > q 确保图结构具有同质性,这意味着来自同一类的节点比来自不同类的节点更有可能连接。
引理1:
假设标签 y 是从 {1, 2} 统一抽取的,并且给定 y, x ∼ N (μ(n) y , (σ(n))2)。然后,贝叶斯最优分类器最小化所有分类器之间的误分类概率,其决策边界 D = (μ1 + μ2)/2,并预测 y = 1(如果 x ≤ D)或 y = 2(如果 x > D)。相关的贝叶斯错误率为 1 − Φ(z(n)),其中 Φ 表示标准高斯分布的累积分布函数,z(n) = 1 2 (μ(n) 2 − μ(n) 1 )/σ (n) 是 D 相对于 N (μ(n) 1 , (σ(n))2) 的 z 分数。
解释:
这个引理描述了一个基于贝叶斯最优分类器的情景,其中标签 y 从 {1, 2} 中均匀抽取,同时给定 y,特征 x 是从正态分布 N(μ(n)y, (σ(n))^2) 中抽取的。
在这种情况下,贝叶斯最优分类器旨在最小化所有分类器之间的误分类概率。它使用决策边界 D = (μ1 + μ2)/2 来进行预测,其中 μ1 和 μ2 分别是标签为 1 和标签为 2 的正态分布的均值。
对于给定的特征 x,如果 x ≤ D,则预测 y = 1;如果 x > D,则预测 y = 2。这个决策边界 D 位于两个正态分布的均值之间的中点。
贝叶斯错误率是分类器在最优情况下的错误率,可以用 1 − Φ(z(n)) 表示。其中,Φ 表示标准高斯分布的累积分布函数,z(n) = (1/2) * (μ(n)2 − μ(n)1)/σ(n) 是决策边界 D 相对于标签为 1 的正态分布 N(μ(n)1, (σ(n))^2) 的 z 分数。
该引理指出,通过计算决策边界相对于标签为 1 的正态分布的 z 分数,可以得到与之相关的贝叶斯错误率。z 分数表示决策边界 D 与标签为 1 的正态分布之间的差异程度,而贝叶斯错误率则表示分类器在最优情况下的错误率,即将观测值分配给错误的类别的概率。
通过使用 z 分数和标准高斯分布的累积分布函数,我们可以计算贝叶斯错误率,以评估分类器在给定数据分布的条件下的性能。
引理1指出我们可以通过 z 分数来估计 n 层线性 GNN 的最佳性能,z 分数越高,表示贝叶斯错误率越小,因此节点分类的预期性能越好。
在下一节中,通过估计 μ(n) 2 − μ(n) 1 和 (σ(n))2,我们量化图卷积的两个抵消效应,并获得 z 分数 z(n) 的界限作为n 的函数,它使我们能够定量地表征过度平滑。
两个抵消效应:
-
μ(n)2 - μ(n)1 抵消效应:μ(n)2 和 μ(n)1 分别表示标签为 2 和标签为 1 的正态分布的均值。在图卷积中,这些均值反映了不同类别节点特征的中心位置。当两个类别的均值之间的差异较大时,意味着它们在特征空间中的分离程度较高,有利于分类任务。而当两个类别的均值之间的差异较小时,它们在特征空间中的分离程度较低,可能会导致分类性能下降。因此,μ(n)2 - μ(n)1 抵消效应表示两个类别均值之间的差异对图卷积的影响,当差异较小时可能会抵消分类性能的提升。
-
(σ(n))^2 抵消效应:(σ(n))^2 表示数据集中的方差。在图卷积中,方差反映了节点特征的分布广度或变化程度。当方差较大时,意味着节点特征在特征空间中的分布较广,可能包含更多的信息,有利于分类任务。而当方差较小时,节点特征的分布较为集中,可能会限制分类性能。因此,(σ(n))^2 抵消效应表示数据集中特征分布的变化程度对图卷积的影响,当变化程度较小时可能会抵消分类性能的提升。
基于 z 分数的过度平滑的两种可能解释:
主要结论
引理2:估计平均值 μ(n) 2 − μ(n) 1 之间相对于层数 n 的差距:(混合效应)
测量在 n 个 GNN 层之后不同类中的节点表示有多少同质化,这是不良的混合效应。
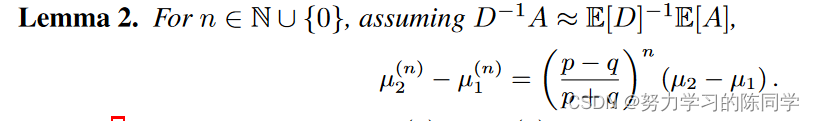
引理 2 表明,当我们执行消息传递时,具有较高社区间密度 (q) 或较低社区内密度 (p) 的图预计会遭受较高的混合效应。我们为 μ(n) 2 − μ(n) 1 的估计提供了以下浓度范围,其中表明估计集中于 O(1/pN (p + q)) 的速率。
引出定理1:
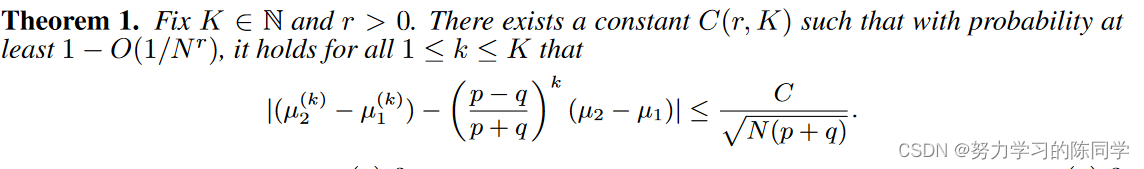
引理3:(方差上下限)

引理 3 意味着对于给定的图,即使层数 n 趋于无穷大,方差 (σ(n))2 也不会收敛到零,这意味着去噪效果存在固定的下界。有关 n 趋于无穷大时方差 (σ(n))2 的准确理论极限,请参阅附录 K.2。现在,我们在以下技术引理中针对层数 n 建立一组更精确的方差 (σ(n))2 上限和下限。
引理4:(更精确的方差上下限)
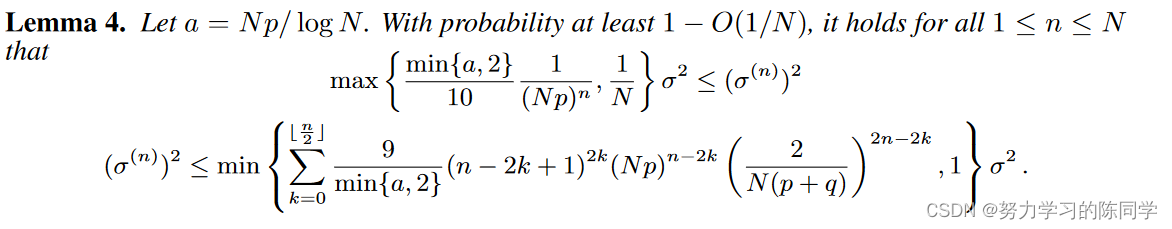
由引理4导出定理2
定理2:(去噪效果)
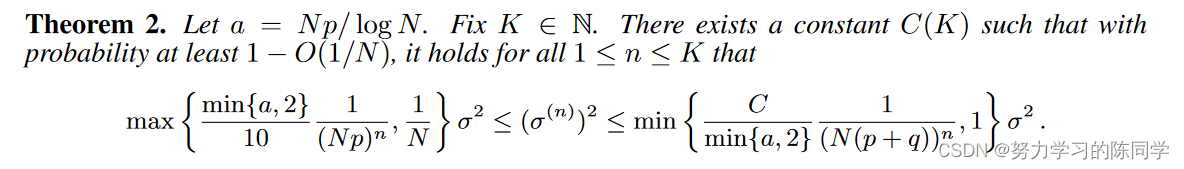
指出对于较大的图或更密集的图,每个高斯分布的方差 (σ(n))2 减少得更多。此外,上限意味着方差 (σ(n))2 在达到引理 3 建议的固定下限 σ2/N 之前至少会以 O(1/ log N ) 的指数速率下降。这意味着在 O(log N/ log(log N )) 层之后,同一类中理想的去噪效果均质化节点表示将饱和,并且不良的混合效果将开始占主导地位。
为什么在浅深度会发生过度平滑?
文章读到这里云里雾里的,作者主要的思想是上面的理论分析框架,下面第二个贡献便是将该理论分析框架应用到了PPNP消息传递里面。第三个贡献呢是实验。
12.4号回看我都没有意识到这篇论文我读过。。。
引用中有关过平滑的论文:
1. Aseem Baranwal, Kimon Fountoulakis, and Aukosh Jagannath. Effects of graph convolutions in deep networks. ArXiv, abs/2204.09297, 2022.
2. Wenbing Huang, Yu Rong, Tingyang Xu, Fuchun Sun, and Junzhou Huang. Tackling oversmoothing for general graph convolutional networks. arXiv preprint arXiv:2008.09864, 2020.
3. Nicolas Keriven. Not too little, not too much: a theoretical analysis of graph (over)smoothing. In NeurIPS, 2022.
4. Understanding non-linearity in graph neural networks from the bayesian-inference perspective. ArXiv, abs/2207.11311, 2022.















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









