










摘要
本文提出了一个通用的可训练框架用于杂乱场景的静态图像中的对象检测。我们开发的检测技术是基于派生的对象类的小波表示类实例的统计分析。通过学习以超完备子集表示的对象类字典的小波基函数,我们得出一个对象类的紧凑表示,它被用作支持向量机分类器的输入。这表现法克服了课堂上的问题可变性并在以下方面提供较低的错误检测率不受约束的环境。
我们在两个固有信息内容显著不同的领域中演示了该技术的能力。第一个系统是人脸检测,第二个系统是人的领域,与人脸相比,它在颜色、纹理和模式上差异很大。与以前的方法不同,该系统从例子中学习,并不依赖于任何先验的(手工制作的)模型或基于运动的分割。本文还提出了一种基于运动的扩展,以提高检测算法对视频序列的性能。这里提出的结果表明,这种架构很可能是相当普遍的
1 引言
本文提出了一种新的杂乱场景中的目标检测框架,基于使用一个过完整的基函数字典,并结合统计学习技术。对现实世界中感兴趣的物体的检测,如面孔和人,带来了具有挑战性的问题:这些物体很难建模,在颜色和纹理上有显著的变化,并且物体所在的背景是不受约束的。与模式分类的情况相比,我们需要在定义良好的类之间进行决定,检测问题要求我们区分对象类和世界上的其他部分。因此,类模型必须适应类内的可变性,而不影响在杂乱场景中区分对象的辨别能力。我们也不能假设在图像中有一定数量的物体,如果有的话;MAP或最大似然方法将不会工作,因为在一个图像中的每个模式的分类是独立完成的。本文还介绍了一种扩展,利用运动线索来提高对视频序列的检测精度。该运动模块是一种通用的运动模块,可以用于许多检测算法,并且不影响系统检测非移动物体的能力。
关于检测静态图像中的刚性物体的初步工作,如街道标志或面孔,贝克&Makris[l],Yuille,等。al.[2l],使用了模板匹配方法与一组刚性模板或手工制作的参数化曲线。这些方法很难扩展到更复杂的对象,如人,因为它们涉及到大量的先验信息和领域知识。在最近的研究中,与我们的系统更密切相关,检测问题是通过使用数据驱动的基于学习的技术来解决的。Sung&Poggio[lG]和Vaillant等人[l8]使用该方法来检测杂乱的场景中的正面面孔,莫加达姆和A.彭特兰[9],Rowley等人提出了类似的弧图。a1.[14]和Osuna等人。
以前大多数在视频序列中检测物体的系统都集中于使用运动和3D模型或约束来寻找人:筑山和白井1,Leung和杨[G],Hogg[4],Rohr[l3],Wren,等1。海塞勒等。a1.[3],McKenna和Gong[8]。这些系统在现场受到了限制性的假设。结构,例如,场景中的单个物体或固定的相机和一系列帧。在其中一些基于运动的系统中,重点是模型拟合、跟踪和运动解释。相比之下,我们的工作解决了在背景杂乱的无约束环境中对单个静态图像的检测问题,而没有对场景结构进行假设。
开发一个能够处理复杂对象类的系统的主要问题之一是找到一个合适的图像表示。为了说明适当的视觉编码的重要性,图1显示了人的图像及其相应的边缘地图。很明显,像素和基于边缘的表示都不充分;行人图像在颜色、纹理和边缘地图上差异很大缺乏一致性,有大量的虚假信息。使用这些 表示,如果不是不可能的话,将很难导出类模型。我们工作的一个重要特征是使用图像编码来绕过对象类中的可变性。

图1:顶部的行显示了培训数据库中人员的图像示例。这些例子在颜色,纹理,视角(正面或后方)和背景上都不一样。下面一行显示行人的边缘检测。DGE的信息并不能很好地描述行人阶层的特征。
本工作提出了一种用表达性的、过完备的基函数集来定义对象类的结构的思想,我们使用Haar小波表示来捕捉对象类的实例之间的结构相似性。本文在[10]中引入了一种表示过度完备或冗余的概念,并以行人检测为基础,从实例中说明了该模型是如何学习的。在这里,我们扩展了原有的系统,并将其应用到另一个领域,Faces,并给出了很有希望的结果.
2 小波表示
Haar小波是一个自然集基函数,它编码不同区域间平均强度的差异;关于小波的深度描述,见[7]。为了达到检测所需的空间分辨率,提高模型的表现率,我们在[10]中引入了四重密度变换。二维Haar小波的扩展·(图2-1),它产生了一组过完备的基函数。对于尺寸为2的小波,标准的Haar变换将每个小波移动n,四重密度变换使小波在每个方向上移动2n,如图2-2所示。这种四重密度变换的使用导致了一个基函数的过完备字典,从而简化了对对象模式的复杂约束的定义。在[10]中,我们还证明了对于标准小波变换,我们没有损失效率。
3 学习类模型
给定一个对象类,中心问题是如何学习哪些是表达整个对象类共同结构的相关系数,以及哪些是定义该类的关系。学习到一个两阶段的过程:(1)识别
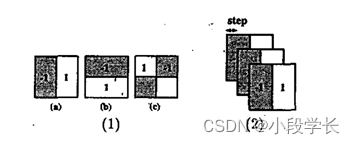
图2:(1)3种二维非标准Haar小波;(a)垂直,(b)水平,©对角线,(2)四重密度二维哈基。
一个小的基函数的子集,使用分类器捕获一个class,and(2)的结构,从基函数的子集获得一个精确的类模型。我们在两种不同的对象上说明这些技术:面孔和行人。
3.1第一阶段:学习重要的基础功能
为了开发我们的人脸类模型,我们使用了一组2429张大小为19x19的灰度图像,其中包括一组具有一些小角度旋转的核心面孔,以提高泛化效果;数据库中的典型图像如图3所示。这种大小和组成的数据库已经被扩展用于人脸检测[15][14][11][12],我们保留这种数据格式以进行比较。在系数分析中,我们使用了4x4像素和2x2像素尺度上的小波,因为它们的尺寸对应于这种大小的人脸图像的典型人脸特征。我们总共有1734名同事。
识别重要系数的基本分析包括两个步骤。由于

图3:用于训练的面孔示例。这些图像是灰度水平的,大小为19x19像素。

图4:使用颜色编码的人脸的小波系数的集合平均值。每个基函数在上面的图像中都显示为一个正方形。值接近于平均值1的系数用灰色编码,高于平均值的系数用红色编码,低于平均值的系数用蓝色编码。我们可以观察到眼睛区域和鼻子的强烈特征。此外,脸颊区域是一个强度几乎一致的区域。低于平均系数。 e):©人脸图像的垂直、水平和对角线系数为4x4。(d)-(f)垂直,水平尺度2x2人脸图像的2x2对角线系数

图5:通过我们的学习策略发现的对人脸检测的重要基函数,覆盖在一个人脸的示例图像上。
不同类型系数的功率分布可能不同,第一步是计算(垂直,水平,对角线)x[2,4]共8类的类平均,并将每个系数按其相应的类平均归一化。第二步是对整个样本集的归一化系数求平均。规格化具有 随机模式系数的平均值为 1. 如果一个系数的平均值更大 大于1,说明系数编码的是a 沿同一方向的两个地区之间的边界这个类的例子;同样,如果平均值 一个比1小得多的系数编码一个统一的区域。
为了说明这种分析,我们使用图4中的灰度对系数的值进行编码,其中每个系数或基函数在图像中被绘制成一个不同的正方形。正方形的排列对应于基函数的空间位置,其中强共系数(大平均值)由较深的灰色水平编码,弱系数(小平均值)由较浅的灰色水平编码。需要注意的是,在图4中,一个基函数对应于每个图像中的单个正方形,而不是整个图像。观察不同类型的小波——垂直、水平和对角线——如何捕捉各种面部特征,如眼睛、鼻子和嘴巴是很有趣的。 从这个统计分析中,我们得到了一组37个系数,从粗糙和更细的尺度上,捕捉了面部的显著特征。这些重要的基包括12个垂直、14个水平和3个对角系数4x4,3个垂直、2个水平和2个角系数2x2。图5显示了来自我们的训练数据库的一个典型的人脸,在适当的配置中绘制了显著的37个系数。
对于行人检测的任务,我们使用了一个包含924张彩色人物图像的数据库(图1)。对行人类的系数的平均值进行了类似的分析,图6显示了与图4相似的灰度编码。详情请向感兴趣的读者参考。有趣的是,对于行人类来说,没有像面部类那样强烈的内部模式;相反,重要的基函数是沿着类的外部边界,表明了一种不同类型的重要视觉信息。通过相同类型的分析,我们从1326个小波系数的初始的、过完备的集合中选择了29个显著系数。这些基函数显示在图7中的一个示例行人上。 需要注意的是,从分类任务的角度来看,我们可以使用整个系数集作为特征向量。然而,在行人

图6:使用灰度编码的小波系数的集合平均值。值高于模板平均值的系数较暗,值低于平均值的系数较浅。(a)随机场景的垂直系数。(b)-(d垂直、水平和角系数32x32的人体图像。(e)-(g)人物图像的垂直、水平和角系数16x16

图7:通过我们的学习策略发现的行人检测的重要基础函数,覆盖在一个行人的示例图像上。
的情况下,使用所有描述128x64像素窗口的小波函数将产生非常高维的向量,即我们前面提到的r.s。训练一个具有如此高维的1000阶的分类器,反过来又需要一个太大的示例集。这个降维阶段用于选择与此任务相关的基函数,并显著减少它们的数量。
3.2第二阶段:学习课堂模式
一旦我们确定了重要的基函数,我们就可以使用各种分类技术来学习定义对象类的小波系数之间的关系。我们使用的分类技术是由Vapnik等人开发的支持向量机(SVM)。a1.[2][19].这种最近开发的技术具有一个吸引人的特点,即可调参数很少,并使用结构风险最小化,最小化泛化误差的界限(见[ll][12])
我们使用从室外和室内场景中收集到的积极例子数据库来训练我们的系统。训练数据库中最初的负面例子是来自不包含人或面孔的自然场景的模式。虽然目标类定义良好,但没有负类的典型示例。为了克服定义这个非常大的负类的问题,我们使用了“引导”训练的概念[16]。在行人检测系统的背景下,在初始训练后,我们在不包含任何人的任意图像上运行系统,将错误检测添加到训练集中作为负类的例子,并重新训练分类器(图8)。这种对决策曲面的增量细化被迭代,直到达到令人满意的性能。
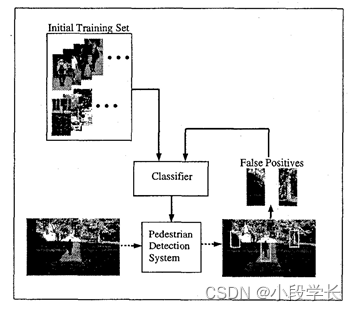
图8:增量式引导操作。以提高系统的性能。
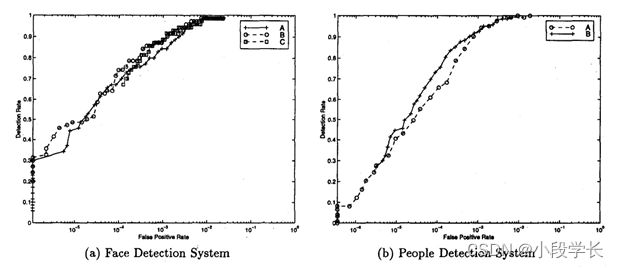
图9:检测系统的ROC曲线。检测率与错误检测率绘制,在对数尺度上测量。错误检出率定义为每个检查窗口的错误检测次数;(a)人脸检测:系统A对遗漏阳性样本和错误检测的处罚相同;系统B和C的处罚比错误检测的惩罚大1个和2个数量级,(b)人员检测:系统A对阳性和阴性样本的错误分类,系统B对错误分类的阳性样本的惩罚是阴性样本的5倍。
4实验结果
该系统可以检测到在图像中任意位置和不同尺度上的物体。一旦第3节中的训练阶段完成,系统就可以通过移动检测窗口来扫描图像中的所有可能的位置,从而检测到任意位置的物体。这与迭代调整图像的大小相结合,以实现多尺度检测。在我们的人脸实验中,我们检测到了最小尺寸为19x19到5倍的人脸,通过将新图像从0.2倍扩展到1.0倍,增量为0.1。对于行人,图像从其原始大小的0.2倍缩放到2.0倍,同样以0.1为增量。在任何给定的尺度下,我们不重新计算图像中每个窗口的小波系数,而是计算整个图像的变换,并在系数空间中进行位移。
4.1人脸检测
为了评估人脸检测系统的性能,我们从一个包含2429个阳性例子和1000个阴性例子的数据库开始。为了理解支持向量训练中不同惩罚的影响(见[ll][12]),我们使用不同的惩罚来训练错误分类。这些系统经历了第3节中详细介绍的引导周期,最终得到了4500到9500个负面的例子。样本外性能是通过一组131张面孔来评估的,而错误检测率是通过系统运行大约900,000张不包含面孔或人的自然场景图像来确定的。为了给出系统的完整表征,我们生成了ROC曲线来说明准确性/错误检测率的权衡,而不是给出单一的性能结果。这是通过改变支持向量机中的分类阈值来实现的。ROC曲线如图9a所示,表明对遗漏的积极例子的更高的惩罚可能导致更好的性能。我们可以看到,如果我们允许每7500个窗口检查一个错误的问题,正确检测到的面孔率达到75%。 在图10中,我们展示了通过示例图像运行人脸检测系统的结果。遗漏的检测是由于旋转程度比训练数据库中的旋转程度要高;通过对适当的旋转例子进行进一步训练,可以检测到这些类型的旋转。在右下角的图像中,有几个不正确的检测。同样,我们希望通过进一步的训练,这一点可以被消除。
4.2人员检测
前后行人检测系统从924个正例子和789个负例子开始,经过9个引导步骤,最后得到一组9726个模式。我们使用一组105张接近正面或后方的行人图像来衡量新数据的性能;需要强调的是,我们不选择完美的行人测试图像,而是许多测试图像代表行人的轻微旋转或步行视图。我们使用一组来自自然场景的280万种模式来测量错误检测率。我们在图9b中给出了行人检测系统的ROC曲线;与面孔一样,这些曲线表明,对于遗漏的积极例子,即使更大的惩罚项也可以显著提高准确性。从曲线中

图11:来自行人检测系统的结果。这些都是用来测试系统的相对复杂场景的典型图像。错过的行人的例子通常是由于人物与背景合并
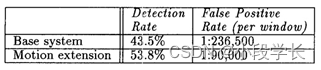
表1:采用motion-b.ased-扩展的行人检测系统与基础系统相比的性能。
6结论
在本文中,我们描述了一个过完全小波表示的想法,并演示了如何学习和用于杂乱场景中的物体检测。这种表示不仅产生了一个计算效率高的算法,而且还产生了一种有效的学习方案。 我们已经将一个对象类的学习分解为一个两阶段的学习过程。在第一阶段,我们执行一个降维方法,其中我们从一个原始的过完备基函数集合中识别出最重要的基函数。在第二阶段,使用支持向量机(SVM)学习定义支持向量模型的基函数之间的关系。如果没有这个降维阶段,对原始过完整集的训练将是困难的,如果不是棘手的话。原始完整集合中的大多数基函数不一定传达关于我们正在学习的对象类的相关信息,但是,从一个大的过完整字典开始,我们不会牺牲细节或空间准确性。学习步骤提取了最突出的特征,并导致了显著的降维。
我们还提出了一个扩展,使用运动线索来提高行人检测精度的视频序列。这个模块的吸引力在于,与大多数系统不同,它并不完全依赖于运动来完成检测;相反,它利用了一种先验知识,即移动对象的类别是有限的,而不影响检测非移动行人的性能。
我们的系统的优势来自于过完整的基函数集的表达能力——这种表示有效地编码了定义复杂对象类的某些模式区域的强度关系。我们的系统在人脸和人这两个不同的领域取得了令人鼓舞的结果,这表明本文中描述的方法可以很好地推广到其他几个目标检测任务。

图12:基于运动的模块中的步骤序列,从左到右显示静态检测结果、运动不连续性、全运动区域和改进的检测结果。
参考文献
[l] M. Betke and N. Makris. Fast object recognition in noisy images using simulated annealing. In Proceedings of the Fifth Internatzonal Conference on Computer Vision, pages 523-20, 1995.
[2] B. Boser, I. Guyon, and V. Vapnik. A training algorithm for optim margin classifier. In Proceedzngs of the Fifth Annual ACM Workshop on Computatzonal Learning Theory, pages 144-52. ACM, 1992.
[3] B. Heisele, U. Kressel, and W. Ritter. Tracking nonrigid, moving objects based on color cluster flow. In CVPR '97, 1997. to appear.
[4] D. Hogg. Model- based vision : a program to see a walking person. Image and Vision Computing,1(1):5-20, 1983.
[5] M. Leung and Y.-H. Yang. Human body. motion segmentation in a complex scene. Pattern Recognition,20(1):55- 64, 1987.
[6] M. Leung and Y.-H. Yang. A region based approach for human body analysis. Pattern Recognition,20(3):321-39, 1987.
[7] S. Mallat. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Transactions on Pattern Analysis and Machine Intelligence,11(7):674- 93, July 1989.
[8] S. McKenna and S. Gong.Non- intrusive person authentication for access control by visual tracking and face recognition. In J. Bigun, G. Chollet, and G. Borgefors, editors, Audio- and Video-based Biometric Person A uthentication, pages 177-183. IAPR,Springer, 1997.
[9] B. Moghaddam and A. Pentland. Probabilistic visual learning for object detection. Technical Report 326,Media Laboratory, Massachusetts Institute of Technology, 1995.
[10] M. Oren, C. Papageorgiou, P. Sinha, E. Osuna, andT. Poggio. Pedestrian detection using wavelet templates. In Computer Vision and Pattern Recognition,pages 193-99, 1997.
[11] E. Osuna, R. Freund, and F. Girosi.Support vector machines: Training and applications. A.I. Memo1602, MIT A. I. Lab., 1997.
[12] E. Osuna, R. Freund, and F. Girosi. Training support vector machines:An application to face detection.In Computer Vision and Pattern Recognition, pages130-36, 1997.
[13] K. Rohr.Incremental recognition of pedestrians from image sequences. Computer Vision and Pattern Recognition, pages 8-13, 1993.
[14] H. Rowley, S. Baluja, and T. Kanade. Human face detection in visual scenes. Technical Report CMU-CS-95-158, School of Computer Science, Carnegie MellonU niversity, July /November 1995.
[15] K.-K. Sung. Learning and Example Selection for Object and Pattern Detection.PhD thesis, Artificial Intelligence Laboratory, M assachusetts Institute of Technology, December 1995.
[16] K.-K. Sung and T. Poggio.Example- based learning for view- based human face detection. A.I.Memo 1521, Artificial Intelligence Laboratory, Mas-sachusetts Institute of Technology, December 1994.
[17] T. Tsukiyama and Y. Shirai. Detection of the movements of persons from a sparse sequence of tv images.Pattern Recognition, 18(3/4):207-13, 1985.
[18] R. Vaillant, C. Monrocq, and Y. L. Cun:Original approach for the localisation of objects in images. IEE Proc.- Vis. Image Signal Processing, 141(4), August1 994.
[19] V. Vapnik. The Nature of Statistical Learning Theory.Springer Verlag, 1995.
[20] C. Wren, A. Azarbayejani, T. Darrell, and A. Pentland.Pfnder: Real-time tracking of the human body. Technical Report 353, Media Laboratory, Massachusetts Institute of Technology, 1995.
[21] A. Yuille, P. Hallinan, and D. Cohen. Feature Extraction from F aces using Deformable Templates. International Journal of Computer Vision, 8(2):99-111,1992.
















 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











