









神经网络基础
二分分类
如果检测一张6464的图片是否为猫,是就返回1,不是就返回0
那么这张图片就是由三张6464的图片组成的

表示输入的特征向量X为用这三个图片的亮度值组成

而该特征向量的维度则为nx=64643=12288
在二分分类问题中目标就是训练出一个分类器,他以图片的特征向量x作为输入,预测输出的结果标签y 是1还是0
(x,y)表示一个单独的样本 x是一个nx(n)维的特征向量 标签y值为0或者1
训练集由m个训练样本构成(x(1),y(1))表示样本一
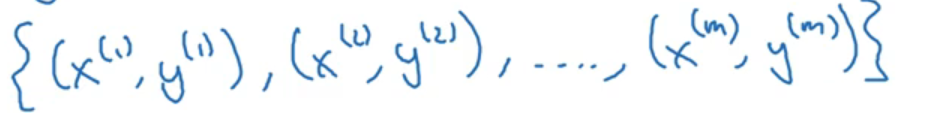
m表示样本数
mtrain表示训练集的样本数

X∈Rn*m 在python中X.shape=(nx,m)

logistic回归
logistic回归模型简单介绍
logistic回归的参数是w和b

另一种表示方式(不常用)

logistic回归损失函数
为了训练logistic回归模型的参数w和b,需要定义一个成本函数
损失函数或者叫误差函数,是衡量单一训练样例的效果,他们可有用来衡量算法的运行情况
我们通过定义这个损失函数L来衡量你的预算输出值y帽和y的实际值有多接近

根据上面的推导可以看出
当y=1时,损失函数会让y帽尽可能大,接近1
当y=0时,损失函数会让y帽尽可能小,接近0
损失函数是在单个训练样本中定义的,它衡量了在单个训练样本上的表现
成本函数,它衡量的是在全体训练样本上的表现,用于衡量参数w和b的效果
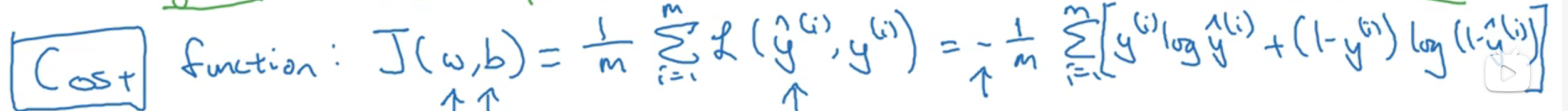
这个成本函数J是由前面的w和b推导而出,1/m乘以损失函数加和
这个成本函数基于参数的总成本,所以在训练logistic训练模型时我们要找到适合的参数w和b,让成本函数J尽可能地小
梯度下降法

J(w,b)是在水平轴w和b上的曲面
曲面的高度表示J(w,b)在某一点的值
要做的就是要找到这样的w和b使其对应的成本函数J值是最小值。
可以看出成本函数J是一个凸函数,不像下面的函数一样有许多局部最优解,这个特性是使用logistic回归的这个特定成本函数J的重要原因之一

梯度下降法所做的就是 从初始点开始朝最陡的下坡方向走一步,在梯度下降一步后或许会在那停下,因为它正试图沿着最快下降的方向往下走,或者说,尽可能快地往下走。这是梯度下降的一次迭代,在几次迭代下在图上的曲线下很有希望收敛到这个全局最优解,或者接近全局最优解
假如有个函数如下图(先忽略b )

多次根据下面的公式进行梯度下降的迭代进行查找新w,慢慢会像图中所示找到最优解或者接近最优解(α为学习率)

实际的成本函数包含w和b,公式如下

在编程中想要更新w的值,在上面图中α后面的dJ/dw 用dw来表示,同样dJ/db 用db来表示
logistic回归中的梯度下降法




- 向上面那样求出dz
- 求出dw1和dw2…和db
- 通过下列公式更新w1、w2…和b。然后就完成了单个样本实例的一次梯度更新步骤
更新w1的公式:
w1=w1-αdw1
w2=w2-αdw2
b=b-αdb
以上为单个样本实例的一次梯度更新步骤
多个像本的梯度下降请看下面代码
m个样本的梯度下降

上面可以看出这种方法要用到显示for循环会使算法很低效,同时在深度学习中会有越来越大的数据集,完全不用显示for循环的话会帮助你处理更大的数据集。 所以有一门向量化技术可以帮助摆脱for循环
向量化-vectorization
np.dot( )用于矩阵的乘法运算

结果如下:
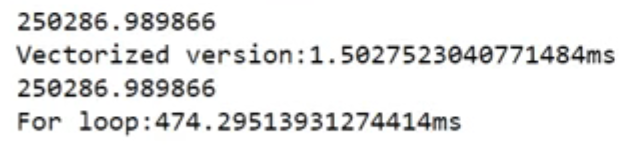
非向量化时间花费了474毫秒
向量化时间花费了1.5毫秒
向量化之后运行速度会大幅度上升
所以:只要有其他可能就不要使用显式for循环
要运用循环的时候要想想numpy里面有没有内置函数

向量化logistic回归

广播
下面第三个红框里的b其实是一个一行一列的元素,但是把他和数组相加之后就用到了python中的广播的性质,变成了一个一行m列的数组。
比如下面,100加上一个四行一列的数组,100也就会被广播成为四行一列的数组。然后进行相加



总结logistic回归的梯度输出:
















 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









