






利用chatgpt学习论文
原论文地址:https://arxiv.org/pdf/2306.15667.pdf
参考
参考文章1
文章目录
摘要
解决的问题:相机姿态估计,这是计算机视觉中的一个经典问题。
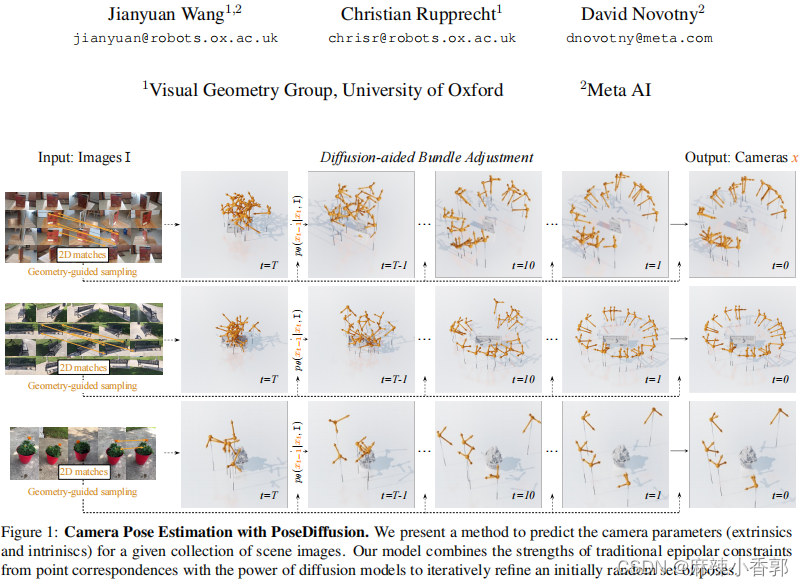
提出的方法:一种新的方法,PoseDiffusion,它将Structure from Motion(SfM,从运动中构建结构)问题整合到概率扩散框架中。
优势:此方法提供了多个好处:
· 模拟捆绑调整的迭代过程。
· 整合来自极线几何的几何约束。
· 在具有挑战性的场景中(如视角稀疏、基线宽的情况)表现良好。
· 能够为多张图片预测内外参。
结果:在现实世界数据集上,PoseDiffusion超越了经典的SfM管道和学习型方法,在不同数据集上具有跨数据集的泛化能力,无需进一步训练。
1. 引言部分:
论文指出相机姿态估计是一个具有悠久历史的计算机视觉问题,提取相机的内外参数是其主要目标。传统的相机姿态估计方法通常采用经典的手工设计方法,如关键点匹配、RANSAC和束调整。作者提出了一种新的方法,将结构运动问题置于概率扩散框架中,通过建模条件下相机姿态的概率分布来解决姿态估计问题。
1.1 相机姿态估计问题:
相机姿态估计是计算机视觉中的基础问题,它涉及从多个视图中推断出相机的位置和方向。这一问题在许多应用中都非常重要,如增强现实、三维重建和机器人导航。
1.2 传统方法:
传统的相机姿态估计方法通常依赖于特征点匹配、几何约束以及一系列优化技术。这些方法包括结构从运动(Structure from Motion, SfM)和多视图几何等技术。尽管传统方法在许多情况下都很有效,但它们在处理具有挑战性的数据时(如图像质量不佳、特征点稀疏、视角变化大等)常常会遇到困难。
1.3 PoseDiffusion的创新:
近年来,深度学习在相机姿态估计中得到了广泛的应用。这些方法试图通过学习大量数据来直接估计相机的姿态,而不是依赖于传统的几何方法。虽然深度学习方法在某些情况下显示出良好的性能,但它们通常需要大量的训练数据,并且可能在新的或未见过的数据集上表现不佳。针对这些挑战,论文提出了PoseDiffusion,这是一种新的方法,将深度学习与传统的几何方法相结合。为了解决传统方法的局限性,提出了将结构运动问题置于概率扩散框架中的思路。该框架通过建模给定输入图像条件下相机姿态的概率分布来解决姿态估计问题。这种概率建模的方法可以提供更准确的姿态估计结果,并且具有更好的鲁棒性和稳定性。这种方法利用了扩散模型来估计相机的姿态,同时考虑了几何约束,旨在提高估计的准确性并改善对新场景的泛化能力。
2. 已做相关工作(方法):
PoseDiffusion方法利用扩散模型学习已知相机姿态样本的概率分布,该样本来自于大规模图像数据集。在给定新的图像序列时,通过从概率分布中采样来估计相机姿态。为了提高估计的准确性,方法结合了传统的极线约束来引导采样过程,以满足几何一致性要求。
2.1 传统几何姿态估计方法:
定义:SfM是一种利用多幅图片来重建三维结构和估计相机位置与方向的技术。
工作原理:通过检测和匹配图像间的特征点,SfM能够重建出这些特征点在三维空间中的位置,并估计每张图片相对于这些点的相机姿态。
优点:能够从一系列静态图像中重建复杂的三维场景。
局限性:对特征点的质量和数量有较高的要求,而且在特征稀疏或重复纹理的场景中可能无法有效工作。
2.2 学习姿态估计方法:
定义:这些方法通常指利用深度学习网络直接从图像数据中学习和预测相机姿态。
工作原理:通过训练神经网络识别图像中的模式和特征,然后直接输出相机的位置和方向。
优点:在处理复杂和变化多端的场景时表现出色,能够从大量数据中学习丰富的视觉表示。
局限性:需要大量标记数据进行训练,可能在未见过的环境或数据分布不同的场景中泛化能力不足。
2.3 几何约束与深度学习的结合:
定义:结合了传统几何方法的稳定性和深度学习的强大数据拟合能力。
工作原理:一些方法利用神经网络来预测特征点匹配,然后应用几何方法(如极线约束)来估计相机姿态。
优点:兼具了深度学习的自动特征学习能力和传统几何方法的鲁棒性。
局限性:需要恰当的方法设计来有效结合两种技术的优势。
2.4 PoseDiffusion:
定义:PoseDiffusion是一种新的方法,将深度学习和几何约束结合,并引入扩散模型来提高姿态估计的准确性和泛化能力。
工作原理:通过训练一个扩散模型在已知相机姿态的数据集上,然后通过概率采样估计新图像序列的相机姿态。
创新点:结合了深度学习和几何约束的优势,并通过扩散模型增强了泛化能力和处理挑战性场景的能力。
优点:特别适合处理质量不高或视角变化大的图像,提高了准确性和泛化能力。
局限性:作为一种新的方法,可能需要进一步的研究和实验来验证其在各种条件下的效果和可靠性。
3. 实验设计:
在两个真实世界的数据集上进行了实验,讨论了模型的设计选择,并与之前的工作进行了比较。
选择COLMAP作为密集姿态估计基线。除了利用RANSAC匹配的SIFT的经典版本外,还对COLMAP+SPG进行了基准测试,它建立在与SuperGlue匹配的SuperPoints的基础上,还与RelPose进行了比较,RelPose是当前稀疏姿态估计的最先进技术。最后为了理解几何引导采样的影响,在没有GGS的情况下实现了学习去噪器。
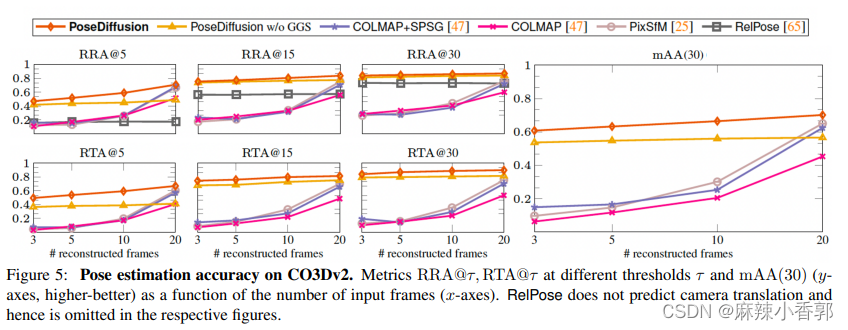
3.1 CO3Dv2
考虑了两个具有不同统计数据的数据集。第一个是CO3Dv2,其中包含50个MS-COCO类别中的物体的大约37k个视频。

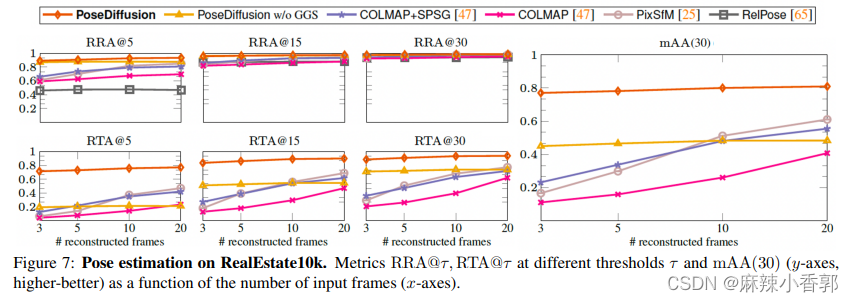
3.2 RealEstate10k
其次,对RealEstate10k进行了评估,它包括捕捉房地产内部和外部的80k YouTube剪辑视频。

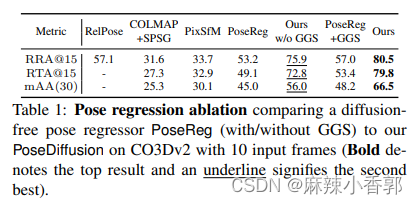
在 CO3Dv2 上使用无扩散姿态回归器 PoseReg(带/不带 GGS)与我们的 PoseDiffusion(带/不带 GGS)进行姿态回归消融比较。
泛化报告 10 个输入帧的 mAA(30)帧。我们首先对 41 个 CO3Dv2 已见类别进行训练。测试在 11 个未见类别(上行)和
RealEstate10k(下)

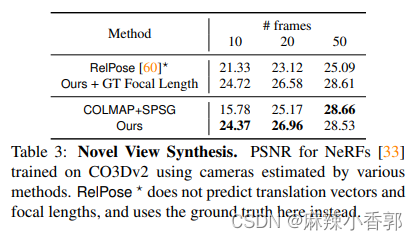
3.3 NeRF
在用于监督NeRF训练时,PoseDiffusion方法也优于传统的结构运动(SfM)方法,表明该方法在外参和内参估计方面更准确。

总结
通过这篇论文,作者提出了一种新颖的方法,将相机姿态估计问题转化为概率扩散框架下的建模和采样问题。该方法结合了传统的几何约束和扩散模型,以提高姿态估计的准确性。实验证明,PoseDiffusion方法在不同数据集上取得了优于传统方法的结果,表明该方法在相机姿态估计领域具有潜在的应用前景。















 1214
1214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









