







0. 资源
本篇论文的官网(包含简介和PDF文件,但代码还未上传):StructDiffusion
1. 内容和结论
简介和结论
- 工作环境中,机器人需要根据语义排列对象,这些对象可能是机器人不认识的
- 本篇关注的方向是:在没有逐步指导的情况下排列对象
- 本篇提出了StructDiffusion,它结合了 diffusion model和object-centric transformer(也是multi-modal transformer),可以根据如“Make a tower in the center of the table”的语言从单个深度图像中构建结构。
- 与现有的 multi-modal transformer 模型相比,使用不认识的物体组装有效结构的成功率提高了16%
- 与很多baseline进行了比较,包括之前的最好的和条件变分自动编码器,这些baseline的端到端策略的性能并不好,因为无法细化正确的放置姿势。
- 使用diffusion model采并加入进过训练的鉴别器来细化对象姿态后,性能显著提高。
- 不足是没有考虑最佳运动规划。
介绍
- 本文的结构指的是,桌子摆好,家具组装好等。要捕捉这些关系,需要对两种物体的几何图形进行推理,针对没见过的物体还要考虑物理有效性。
- 使用未见过的对象构建结构需要满足两个约束:一是放在正确的位置,二是保证不碰撞并且结构合理
- 本文处理约束的办法:
- 首先,训练一个以语言为条件的,以对象为中心的扩散模型,从中我们可以同时对多个对象的目标姿势进行采样;
- 其次,训练一个鉴别器模型,它观察想象的场景,以拒绝不现实的样本。
- 之前的基于语言的重排任务,要不就是基于2D,要不就是对新对象泛化有限,要不只能回归到单一的解决方案。
- 整体流程:
- 使用“未知对象实例分割”将场景分割为对象
- 使用multi-modal transformer组合单词标记和来自 Point Cloud Transformer 的对象编码,以便进行6自由度目标姿态预测
- 这些预测都是通过扩散迭代细化的,并使用鉴别器模型进行选择
- 本文的三大关键思想:
- object-centric transformer学习如何通过对新对象和语言指令的观察来构建不同类型的多对象结构;
- diffusion model捕捉语义结构的不同分布,有助于细化和规划
- 鉴别器模型,通过拒绝违反物理和上述约束的样本来提高性能
2. 方法、模型或数据
核心组件
- transformers1,这个应该都知道,不再赘述。
- Diffusion Models,去噪扩散模型是一类生成模型(公式复杂看不懂),这个模型已经用于运动和抓取规划,但需要已知的对象模型,并且不以可变的语言目标为条件。
StructDiffusion详细结构
模型结构如图1:
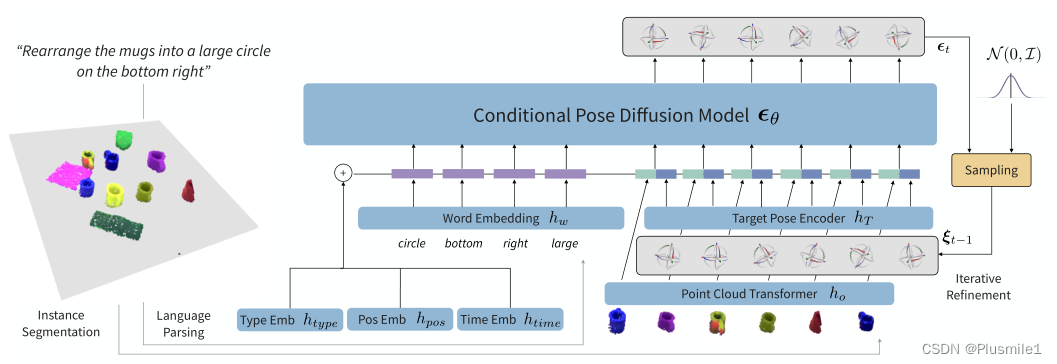
- 任务目标:给定包含对象{o1,…,oN}的初始场景的单个视图和包含单词标记{w1,……,wM}的语言规范,重新排列对象以达到满足语言目标的目标场景。
- 一些假设:物体刚性;有包含用于标识对象的点的分段标签的部分点云视图。
- 可以获得的数据:从场景中提取出对象点云{x1,…,xN},从点云中提取出对象的初始姿态{ξ1pc,…,ξNpc}
- 设定的参数:各自的目标姿态ξigoal,抓取{g1,…,gM},夹爪移动ξiee
A. Encoders
- 利用modality-specific encoders将多模态输入转换为潜在tokens,随后由transformer 处理,下面说明各个编码器。
- 对象编码:训练一个编码器获取对象的潜在表示ho(xi)。Point Cloud Transformer (PCT)处理中心点云+MLP编码原始点云的平均位置的编码被串联起来,得到了ho(xi),语义、几何和空间推理的对象的潜在表示。
- 语言编码:将来自语言指令的每个唯一单词标记分别映射到embedding hw(wi),有助于建立语言与结构细粒度的对应关系
- Diffusion 编码:由于对象的目标姿态由扩散模型迭代优化,并且需要反馈到模型,因此使用MLP来编码对象的目标姿势hT(ξgoal i),为了计算逆扩散的时间相关高斯后验,通过学习time embedding, htime(t)来组合特征信道中t的latent code
- 位置编码:为了区分多模态数据,使用learned position embedding,hpos(i) 指示输入序列中单词和对象的位置,使用learned type embedding,htype(vi)区分对象点云(vi=1)和单词标记(vi=0)。
B. Conditional Pose Diffusion Model
-
同时优化所有对象的姿态
-
扩散模型从反向扩散过程的最后一个时间步骤中的目标姿态(ξT ~ N(0,I)(这个为高斯噪声)),预测所有对象的目标姿态 ξ0 ={ξi}iN
-
使用transformer model 来构建 场景的(以对象为中心)表示,并解释多个对象之间的高阶交互。
-
这种方法允许我们考虑对象之间的全局约束和局部交互
-
利用attention masks,单个 transformer model还可以学习重新排列不同数量的对象。
-
扩散模型的使用有助于我们捕获不同的结构,因为当我们从ξT到目标ξ0时,我们从一系列不同尺度的高斯噪声中进行采样。因此,得到的样本在不同的粒度级别上是不同的(例如,结构的不同位置和单个对象的不同方向),在处理语言指令中固有的歧义时,多样性也是至关重要的
-
条件反向过程建模为
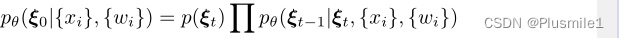
-
考虑到A中的所有输入,使用transformer作为主干为每个物体预测条件噪声
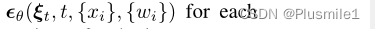
-
语言部分和对象部分的transformer输入:
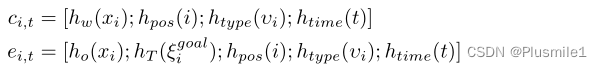
-
整个模型采用序列 {c1,t, …, cM,t, e1,t, …, eN,t},并为物体姿态预测
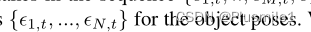
-
然后对姿态目标进行参数化,直接预测6自由度机械臂姿态
C. Discriminators
- 训练一个鉴别器模型来进一步过滤预测以获得真实性。
- 鉴别器在imagined scenes上工作,其中对象的点云被严格地变换为各自的目标姿势,直接进行点级别的推理,为了保持区分每个单独对象的能力,为每个点特征添加了一个one-hot编码
- scene-level collision model比以object-centric model具有更强的辨别能力
- 探索了两种鉴别器,一种碰撞鉴别器从两个物体的局部点云预测两个物体之间的成对碰撞;一种结构鉴别器来对整个多目标结构进行分类,此鉴别器进行了条件调整,以便鉴别器能学习特定于结构的约束来对样本进行评分。
- 最后发现当只需要预测是否满足局部约束时,结构鉴别器工作得更好
- 因此最后作者选择规范化场景点云,并删除语言指令中指定全局约束的部分,使用理论结构鉴别器。
D. Planning and Inference
- 初始化带有随机噪声的目标姿态
- 在GPU上使用批处理来执行不用样本的多个对象的扩散和变换点云
- 对于鉴别器,还在扩散过程之后生成对象的组合点云,并对其进行分批评分,最后返回评分排序好的样本
- 每个样本对应于一个物理和语义上有效的多对象结构,该结构可以由操纵流水线上(???)的其他组件用于规划
训练细节
- 扩散模型,batch-size为128,在3090上训练了12小时
- 测试集使用来自不同对象集中的对象,这些对象不会出现在训练数据中。
- 碰撞鉴别器,随机采样了10万个对象配置
- 对于结构鉴别器,通过随机扰动地面真实目标姿态来生成反例
真实世界配置
- 七自由度JACO+华硕Xion RGB-D相机
- Point Cloud Library,通过表面检测和欧几里德距离聚类来识别感兴趣的簇,从而获得分割的对象点云
- RRTConnect进行运动规划
3. 启发与思考
- 整体看下来只能懂它大概干啥了,具体细节看不懂,等待代码发布,可以再看看
- transformer使用范围好广,可以在我的项目上看看能不能用
- 识别语义然后指挥机械臂对我来说还是太遥远了,我先能抓起来再说吧
- 本篇论文不适合我的研究方向
详见论文attention is all your need ↩︎















 594
594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









