






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
一、无人机边缘数据处理的关键技术与实现
1. 边缘计算的核心架构
无人机边缘数据处理通过将计算资源下沉至靠近数据源的网络边缘节点(如无人机本地或邻近基站),实现“边飞行-边传输-边处理”的实时模式。其技术要点包括:
- 初步数据处理:在边缘节点进行数据筛选、压缩和去噪,减少传输至云端的数据量(例如图像识别中仅传输关键特征而非原始图像)。
- 低延迟与实时性:边缘节点需保证数据处理延迟≤20ms,响应时间≤100ms,通过本地化计算减少云端依赖,满足农业监测、灾害救援等场景的实时需求。
- 多任务并发处理:单个边缘设备需支持至少5个实时数据流的并行处理(如同时执行图像识别、环境感知和通信中继任务)。
2. 技术实现与优化
- 资源管理:采用分布式任务分配机制,例如无人机与无人船协同作业时,通过边缘计算平台动态调度算力资源(如任务优先级划分)。
- 安全性保障:结合AES-256加密算法和区块链技术,确保数据传输的隐私性与完整性。
- 存储与带宽优化:边缘设备需配置≥1TB存储容量,并采用低延迟通信协议(如MQTT、WebSocket)控制带宽利用率在30%以下。
3. 典型应用场景
- 农业监测:实时分析遥感数据,检测作物病虫害,准确率提升30%以上。
- 城市交通管理:处理多路视频流数据,动态优化交通信号灯控制。
- 海上协同作业:无人机与无人船通过边缘计算共享环境数据,实现避障与路径协同。
二、基于DQN的无人机路径规划原理与优化
1. DQN算法核心机制
DQN(深度Q网络)通过结合深度神经网络与Q-learning算法,解决了传统路径规划在高维状态空间下的维度灾难问题。其关键技术包括:
- 经验回放(Experience Replay) :存储历史状态-动作对至记忆池,打破样本相关性,提升训练稳定性。
- 目标网络(Target Network) :独立更新目标Q值,缓解Q值过估计问题,提高算法收敛性。
- 探索-利用平衡:采用ε-贪婪策略(初始ε=0.9,逐步衰减至0.1),动态调整随机探索与经验利用的比例。
2. 路径规划中的改进策略
- 奖励函数优化:
- 设置目标点势能奖励与危险区域惩罚,引导无人机快速避障(如文献[17]中路径长度缩短1.9%,拐点减少62.5%)。
- 引入范数约束确保奖励单调性,避免局部最优陷阱。
- 网络结构创新:
- 分层DQN:分离激励层与动作层,提升Q值准确性,收敛速度提高40%。
- 结合MLP(多层感知机):替代传统CNN,降低过拟合风险,适用于复杂地形规划。
3. 应用案例对比
| 算法 | 路径长度优化 | 拐点数量减少 | 收敛速度提升 |
|---|---|---|---|
| 传统DQN | - | - | - |
| 改进DQN | 1.9% | 62.5% | 30% |
| A*算法 | 0% | 0% | - |
| 分层DQN | 2.5% | 70% | 40% |
| 数据来源: |
三、边缘计算与DQN的协同优化
1. 技术互补性分析
- 实时决策支持:边缘计算提供低延迟数据处理(如障碍物检测结果),DQN基于实时状态更新路径。
- 资源协同调度:边缘节点动态分配计算资源,优先处理DQN所需的特征数据(如激光雷达点云),降低端到端决策延迟。
- 案例:在无人机辅助MEC系统中,DQN规划轨迹时结合边缘计算的能耗预测,使系统总奖励提升25%,同时服务用户数增加15%。
2. 典型联合应用框架
传感器数据 → 边缘节点预处理 → DQN状态输入 → 动作决策 → 路径执行
│ │
↓ ↓
数据压缩/加密 奖励函数计算
- 海上协同控制:无人机通过边缘计算共享海洋环境数据,DQN实时调整多无人机编队路径。
- VR实时渲染:边缘服务器处理图像数据,DQN优化无人机飞行轨迹以降低传输延迟,渲染完成率提升至92%。
四、关键挑战与未来方向
1. 技术挑战
- 多目标优化冲突:需平衡路径长度、能耗与安全性(如动态障碍物避让)的权重分配。
- 计算资源限制:无人机边缘设备的算力(10 GFLOPS)难以支持复杂DQN模型,需模型轻量化。
- 动态环境适应性:传统DQN在障碍物突变场景下响应延迟≥500ms,需引入元学习增强泛化能力。
2. 未来研究方向
- 边缘-云协同计算:将DQN训练任务卸载至云端,边缘端仅执行推理,降低本地负载。
- 异构网络集成:结合5G/6G网络切片技术,为不同任务分配专属通信资源,确保实时性。
- 仿生算法融合:探索麻雀搜索算法(SSA)与DQN的混合架构,提升三维路径搜索效率。
结论
无人机边缘数据处理与DQN路径规划的结合,通过本地化计算降低延迟、强化学习优化动态决策,显著提升了复杂环境下的任务效率。未来需进一步解决多目标优化与资源约束问题,推动算法轻量化与异构网络协同,以扩展其在智慧城市、应急救援等领域的应用深度。
📚2 运行结果
部分代码:
#init plt
plt.close() #clf() # 清图 cla() # 清坐标轴 close() # 关窗口
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
plt.xlim((0,600))
plt.ylim((0,400))
plt.grid(True) #添加网格
plt.ion() #interactive mode on
X=np.zeros([num_UAV])
Y=np.zeros([num_UAV])
fg=1
for t in range(Ed): #move first, get the data, offload collected data
gp.gen_datarate(averate,region_rate)
# print(t)
if t%T==0 and t>0:
Center.epsilon=ep0
Center.save("./save/center-dqn.h5")
if t%pl_step==0:
pre_feature=[]
aft_feature=[]
act_note=[]
for i in range(num_UAV):
pre_feature.append(UAVlist[i].map_feature(region_rate,UAVlist,E_wait)) #record former feature
act=Center.act(pre_feature[i],fg) # get the action V
act_note.append(act) #record the taken action
for i in range(num_UAV):
OUT[i]=UAVlist[i].fresh_position(vlist[act_note[i]],region_obstacle) #execute the action
UAVlist[i].cal_hight()
X[i]=UAVlist[i].position[0]
Y[i]=UAVlist[i].position[1]
UAVlist[i].fresh_buf()
prebuf[i]=UAVlist[i].data_buf #the buf after fresh by server
gp.list_gama(g0,d0,the,UAVlist,P_cen)
for i in range(num_sensor): #fresh buf send data to UAV
sensorlist[i].data_rate=region_rate[sensorlist[i].rNo]
sensorlist[i].fresh_buf(UAVlist)
cover[t]=cover[t]+sensorlist[i].wait
cover[t]=cover[t]/num_sensor
print(cover[t])
for i in range(num_UAV):
reward[i]=reward[i]+UAVlist[i].data_buf-prebuf[i]
Mentrd[i,t]=reward[i]
# if sum(OUT)>=num_UAV/2:
# fg=0
# if np.random.rand()>0.82 and fg==0:
# fg=1
if t%pl_step==0:
E_wait=gp.W_wait(600,400,sensorlist)
rdw=sum(sum(E_wait))
print(t)
for i in range(num_UAV): #calculate the reward : need the modify
# aft_feature.append(UAVlist[i].map_feature(region_rate,UAVlist,E_wait)) #recode the current feature
rd=reward[i]/1000
reward[i]=0
# UAVlist[i].reward=reward
# reward=get_data/(pre_data[i]+1)
# if OUT[i]>0:
# rd=-200000
# if get_data<700:
# reward=-1
# pre_data[i]=get_data
UAVlist[i].reward=rd
# l_queue[t]=l_queue[t]+UAVlist[i].data_buf
# print("%f, %f, %f, %f"%(rd,UAVlist[i].data_buf,UAVlist[i].D_l,UAVlist[i].D_tr))
# if UAVlist[i].data_buf>jud:
# reward=reward/(reward-jud)
# if t>0:
# Center.remember(pre_feature[i],act_note[i],rd,aft_feature[i],i) #record the training data
# if t>1000:
# Center.epsilon=ep0
# Center.epsilon_decay=1
# if t>batch_size*pl_step and t%pl_step==0:
# for turn in range(num_UAV):
## Center.replay(batch_size,turn,t%reset_p_T)
# Center.replay(batch_size,turn,t-batch_size*pl_step)
if t>0:
ax.clear()
plt.xlim((0,600))
plt.ylim((0,400))
plt.grid(True) #添加网格
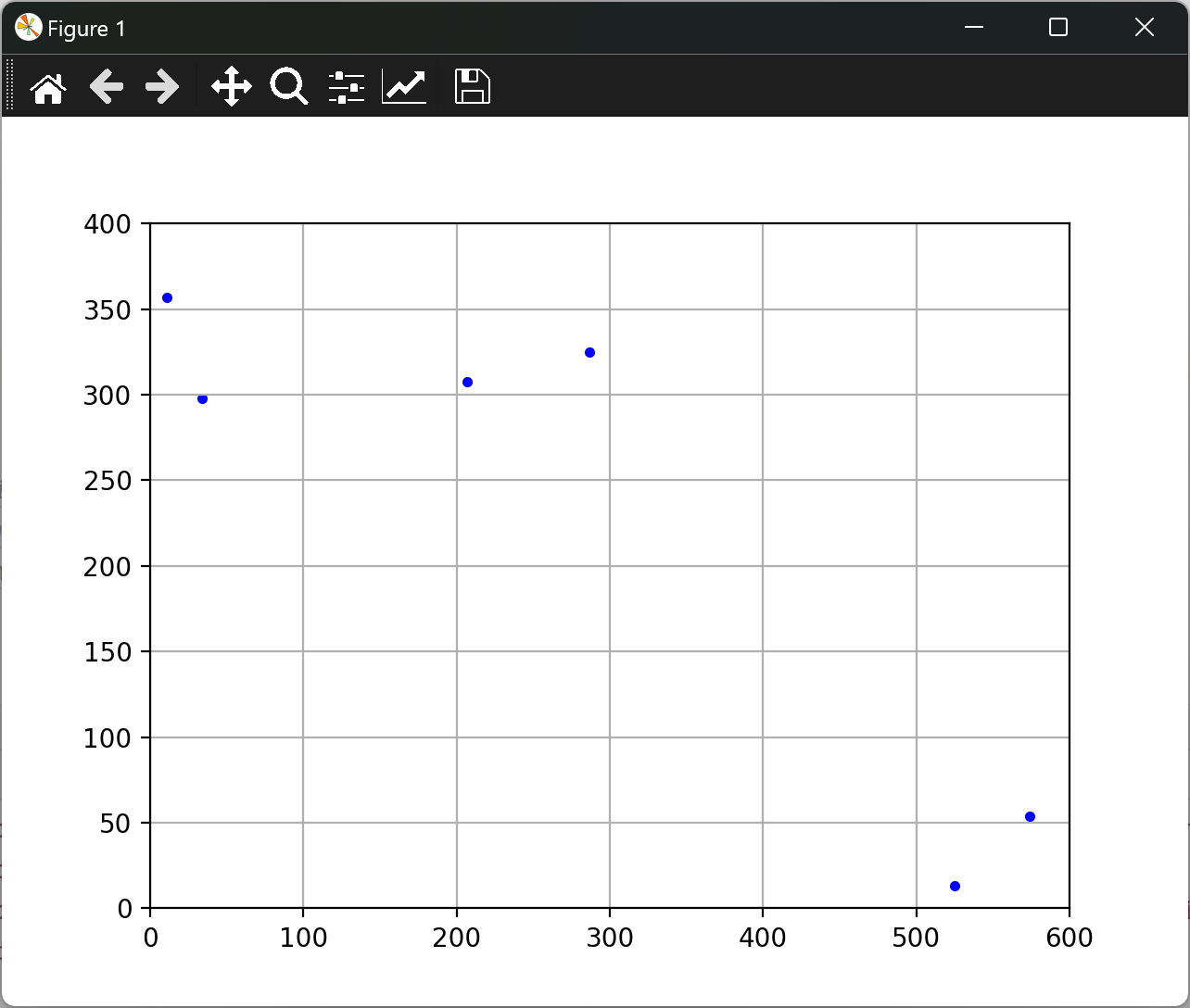
ax.scatter(X,Y,c='b',marker='.') #散点图
# if t>0:
plt.pause(0.1)
#np.save("record_rd3",Mentrd)
np.save("cover_hungry_10",cover)
fig=plt.figure()
plt.plot(cover)
plt.show()
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]王杰,王高攀,孙天杨.基于DQN算法的无人机校园安全监控路径自动规划模型[J].自动化与仪器仪表, 2024(4):193-196.
[2]赵恬恬,孔建国,梁海军,等.未知环境下基于Dueling DQN的无人机路径规划研究[J].现代计算机, 2024, 30(5):37-43.
[3]李延儒,左铁东,王婧.基于DQN深度强化学习的无人机智能航路规划方法研究[J].电子技术与软件工程, 2022(18):5-8.
🌈4 Python代码实现
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取




















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











