







目录
信息论
1、信息量
用概率描述信息量的重要性质:
(1)事件发生的概率越低,信息量越大
(2)事件发生的概率越高,信息量越小
(3)多个事件同时发生的概率是多个事件概率相乘,总信息量是多个事件信息量相加(确定为对数关系)
则信息量与概率之间一定是减函数的关系。
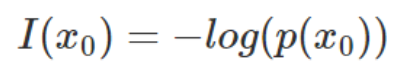
为什么是对数呢?
x1和x2同时发生的概率:P(x1,x2)=P(x1)×P(x2)
x1和x2的总信息量:I( x1x2 )=I( x1 )+I( x2 ) --> log( P(x1x2) )=log( P(x1) )+log( P(x2) )
为什么加上负号?
为了保证信息熵是正数
为什么要取均值?
随机变量有多个状态值,P(xi)只代表随机变量X取xi的概率,我们用熵来评价整个随机变量平均的信息量,而平均最好的量度就是随机变量的期望。
2、熵
信息量是对单个事件来说,但是实际情况一件事有很多种发生的可能,比如掷骰子有可能出现6种情况,明天的天气可能晴、多云或者下雨等等。熵是表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望。(熵表示所有信息量的期望)
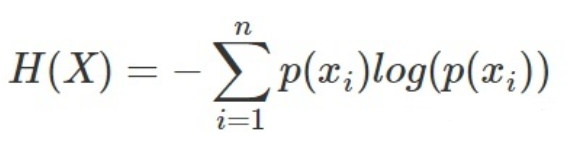
例如: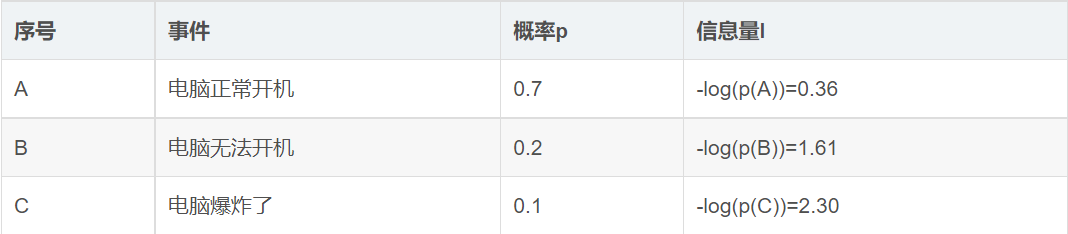
该事件的熵为:
=0.7*0.36+0.2*1.61+0.1*2.30=0.804
对于0-1分布问题,熵的计算方法可以简化为
3、相对熵(KL散度)
相对熵,用于衡量对于同一个随机变量x的两个分布p(x)和q(x)之间的差异。
p(x)常用于描述样本的真实分布,例如[1,0,0,0]表示样本属于第一类。
q(x)常用于表示预测的分布,例如[0.7,0.1,0.1,0.1]。
显然使用q(x)来描述样本不如p(x)准确,q(x)需要不断地学习来拟合准确的分布p(x)。
计算公式为:
的值越小,表示q分布和p分布越接近。
4、交叉熵
讲KL散度公式变形得到:
交叉熵:
相对熵=交叉熵-信息熵
机器学习中的交叉熵
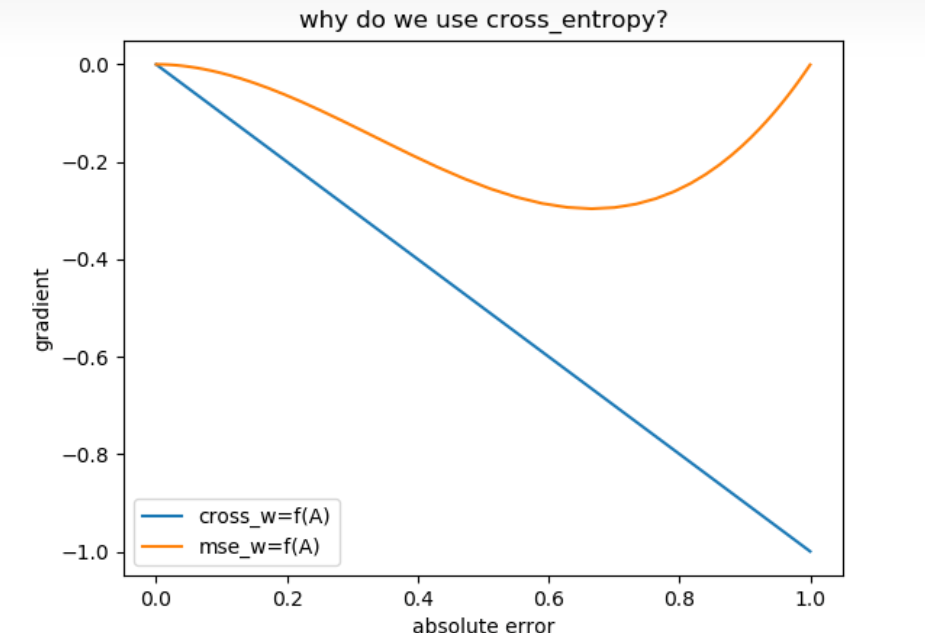
1、为什么要用交叉熵做loss函数?
在机器学习中,我们希望模型在训练数据上学到的预测数据分布与真实数据分布越相近越好,上面讲过了,用相对熵,但是为了简便计算使用交叉熵就可以了。
为什么使用交叉熵作为损失函数 - 知乎 (zhihu.com)
- 平方损失的“罪魁祸首”是sigmoid函数求导之后变成 y1′(1−y1′)∝(1−A)×A2 ,平白无故让曲线变得非常复杂,如果前面能够产生一个 1y1′ 把后面多余项“吃掉”多好
- 交叉熵的优势就是:它求导之后只提供了一个 1y1′ 去中和后面的导数
2、梯度下降的原理,为什么要这样更新参数?
3、batch对随机梯度下降的影响?
















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









