







我学校学子创立的外卖平台,有个长期的活动,连续签到七天,就可以领无门槛6块钱优惠劵,但是嫌麻烦的我,开始琢磨利用python实现自动签到,这也是我第一次利用技术解决生活上的问题,成就感满满的,从此,极少订外卖的我,开始我的肥宅生活…
实现思路
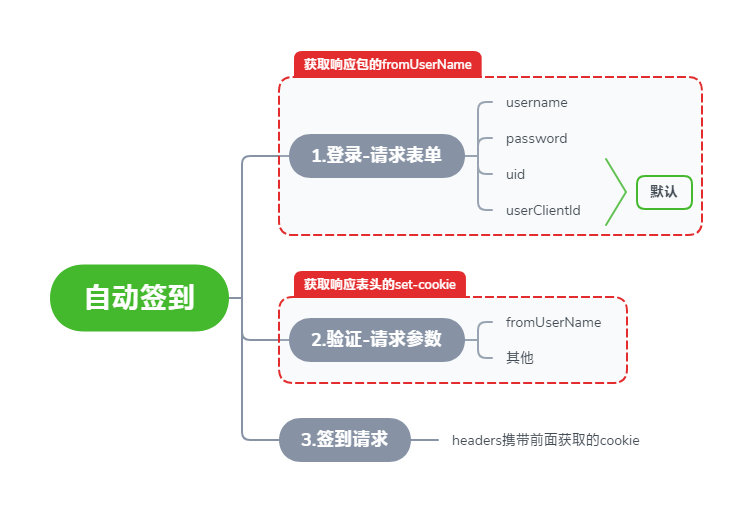
整体代码
import requests
import json
import time
import re
import logging
logging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(levelname)s - %(message)s')
class NineZeroGoSign:
def __init__(self,username,password):
##初始化类中私有属性
self.__username = username
self.__password = password
self.__fromUserName = ""
self.__cookie = ""
self.__session = requests.session()
self.__LoginUrl = "https://xxx/app/buyer/account/login.jhtml"
self.__AuthUrl = "https://xxx/wx/auth/login.jhtml?"
self.__SignWebUrl = "https://xxx/wx/customer/sign/index.wx"
self.__SignBtnUrl = "https://xxx/wx/customer/signin.wx"
self.__form = {
"userName": self.__username,
"password": self.__password,
"uid": "95626",
"userClientId": ""
}
self.__params = {
"id": "87652",
"userId": "95626",
"firstShop": "Y",
"gotoUrl": "/wx/weimei/customer/index.wx?ftTemplateId=27868&iconIndex=3",
"fromWechatAuth": "Y",
"clientInitURL": "Y",
"fromApp": "Y",
}
self.__headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Mobile Safari/537.36 Edg/85.0.564.44",
"X-Requested-With": "XMLHttpRequest"
}
##登录获取fromUserName
def GetFromUserName(self):
while True:
res = requests.post(url=self.__LoginUrl,data=self.__form)
if res.status_code == 200:
logging.info("获取FromUserName"+res.text)
resJson = json.loads(res.text)
if resJson["ret"] == 1:
logging.warning("账号错误")
quit()
elif resJson["ret"] == 2:
logging.warning("密码错误")
quit()
else:
if resJson["u"] != "":
logging.info("获取FromUserName成功,等待5秒")
self.__fromUserName = resJson["u"]
self.__params["fromUserName"] = self.__fromUserName
time.sleep(5)
break
else:
continue
else:
logging.warning("获取FromUserName失败")
def GetCookie(self):
while True:
res = self.__session.get(url = self.__AuthUrl,
params = self.__params,
headers = self.__headers)
if res.status_code == 200:
##获取响应标头的set-cookie
##session.cookies是CookieJar类型,requests.utils.dict_from_cookiejar可以把cookiejar类型转换成dict类型
set_cookie = requests.utils.dict_from_cookiejar(self.__session.cookies)
logging.info("获取set-cookie"+str(set_cookie))
for i in set_cookie:
self.__cookie += i + "=" + set_cookie[i] + ";"
self.__cookie = self.__cookie[:-1]
logging.info("已整理cookie,等待5秒")
self.__headers["Cookie"] = self.__cookie
time.sleep(5)
break
else:
logging.warning("获取cookie失败")
continue
##签到
def Sign(self):
while True:
##进入签到页面
signweb = self.__session.get(url = self.__SignWebUrl,
headers = self.__headers)
if signweb.status_code == 200:
logging.info("进入签到页面,等待3秒")
time.sleep(3)
signweb.encoding == "utf-8"
signwebtext = signweb.text
if "当前链接已失效,请重新进入" in signwebtext:
logging.warning("Cookie失效")
continue
elif "未签到" in signwebtext:
logging.info("今日未签到")
totalSignCount = re.findall('<a class="id" id="totalSigninCount">(.*?)</a>',signwebtext)[0]
signday = re.findall('已连续签到 (.*?) 天', signwebtext)[0]
##签到请求
sign = self.__session.get(url = self.__SignBtnUrl,
headers = self.__headers)
if sign.status_code == 200:
logging.info("签到成功")
else:
logging.warning("签到错误")
logging.info("累计签到天数:"+totalSignCount + " +1")
logging.info("已连续签到天数:"+signday + " +1")
break
elif "已签到" in signwebtext:
logging.info("今日已签到")
totalSignCount = re.findall('<a class="id" id="totalSigninCount">(.*?)</a>',signwebtext)[0]
signday = re.findall('已连续签到 (.*?) 天', signwebtext)[0]
logging.info("累计签到天数:"+totalSignCount)
logging.info("已连续签到天数:"+signday)
break
else:
logging.warning("进入签到页面错误")
continue
if __name__ == "__main__":
try:
##初始化类的属性
s = NineZeroGoSign("username","password")
s.GetFromUserName()
s.GetCookie()
s.Sign()
except Exception as error:
logging.warning("运行错误:" + error)
功能效果

结尾
-
本项目仅供爬虫学习交流,如作他用所承受的任何直接、间接法律责任一概与作者无关
-
本项目所访问的网站robots协议是允许所有爬虫的
-
如果此项目侵犯了您或者您公司的权益,请联系作者删除


















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









