






64B/66B
64B/66B编码技术是IEEE 802.3工作组为10G以太网提出的,目的是减少编码开销,降低硬件的复杂性,并作为8B/10B编码的另一种选择,以支持新的程序和数据。当前,64B/66B编码主要应用于Fiber Channel 10GFC和16GFC、10G以太网、100G以太网、10G EPON、InfiniBand、Thunderbolt和Xilinx的Aurora协议。
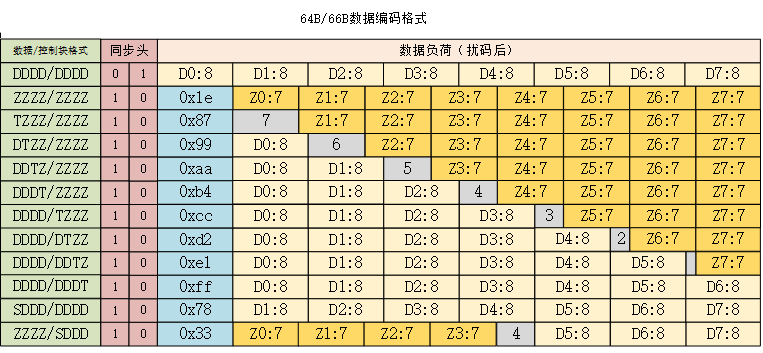
64B/66B编码将64bit数据或控制信息编码成66bit块传输,66bit块的前两位表示同步头,主要由于接收端的数据对齐和接收数据位流的同步。同步头有“01”和“10”两种,“01“表示后面的64bit都是数据,“10”表示后面的64bit是数据和控制信息的混合,其中紧挨着同步头的8b是类型域,后面的56bit是控制信息或者数据或者两者的混合。64B/66B编码格式图如下图所示,其中D表示数据编码,每个数据码8bit;Z表示控制码,每个控制码7bit;S表示包的开始,T表示包的结束。S只会出现在8字节中的第0和第4字节,T能够出现在任意的字节。除同步码外,64bit的数据必须经过扰码以后才能进行传输。64B/66B编码所使用的 扰码器为X58+X39+1.
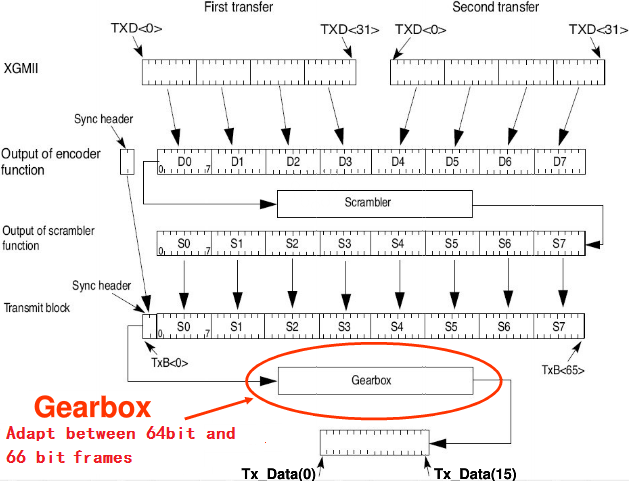
一个18 bytes的数据块的传输过程如下图所示:

2. 扰码传输技术
扰码是一种将数据重新排列或者进行编码以使其随机化的发布方法,主要作用是将数字通信中的"0"和"1"分布随机化,从而使比特信息模式被随机化,进一步减轻了抖动个码间串扰,提高了通信的可靠性。从本质上讲,扰码正是为了达到上述目的而在待传输数据进入信道传输之前,对其进行的比特层的随机化处理过程,与扰码过程相对应的解随机化过程称之为解扰。
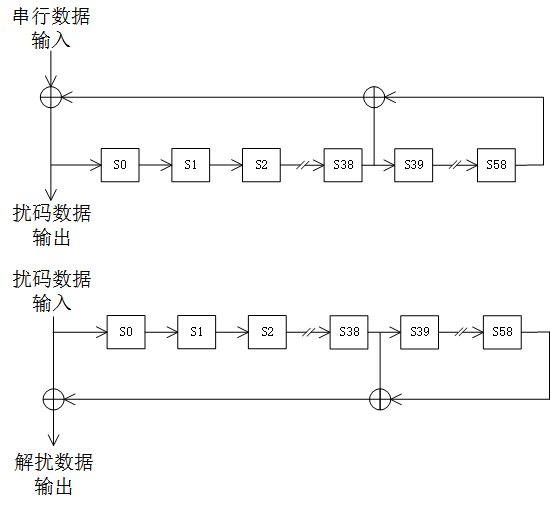
扰码的数学原理使用了多项式,多项式的选择通常是基于扰码的特性,包括生成数据的随机度,以及打乱连0和连1的能力。一个简单的扰码器包含一组排列好的触发器,用于移位数据流。大部分的触发器只需要简单地输出下一个比特流即可,但是在某些复杂的扰码电路中,触发器需要与数据流中的历史比特进行逻辑运算(与和或运算)。基本的扰码电路如下所示:
64B/66B编码过程如下图所示:
8B/10B
1、编码技术基础理论
在高速的串行数据传输中,传送的数据被编码成自同步的数据流,就是将数据和时钟组合成单一的信号进行传送,使得接收方能容易准确地将数据和时钟分离,而且要达到令人满意的误码率,其关键技术在于串行传输中数据的编码方法。
目前, 高速接口正在被广泛应用于包括 SATA、 SAS、 高速 PCI 等多种标准中。 这些接口的速率甚至可以达到并超过每线 10Gbits/s。 同时, 所有主流 ASIC 和 FPGA 平台也都支持这些高速接口技术。 从结构上看, 这些高速接口主要包括三个组成部分:
1) 电路部分(串行/解串行)
2) 物理部分(实现编码)
3) 链路与协议部分(高层)
支持多速率、 多协议的串行/解串行器已经实现。 以 OIF(光互联论坛) 为例, 他们已经为两组速率制定了电路规范, 分别为 5Gbits/s- 6.375Gbits/s 和 10Gbits/s-11Gbits/s。 OIF 同样为两种应用距离制定了规范, 分别为短距离(采用一个连接器, 8 英寸) 和长距离(采用两个连接器, 40 英寸)。 串行/解串行器还可以被设计用来满足更多的规范, 包括不同的速率、距离、 电路规格等等。
物理部分的主要任务是对数据进行编码, 以保证串行/解串行器的正常运行。 这些编码的目的包括: 确保必须的变换(“1” 到“0” 和“0” 到“1” 的变换), 保证稳定的直流均衡(“0” 码与“1” 码的个数相当), 以及满足其它标准的要求(最大化信道带宽利用率, 提高对误差的容忍能力等等)。
在光纤通信中, 线路编码是必要的, 因为电端机输出的数字信号是适合电缆传输的双极性码, 而光源不能发射负脉冲, 只能用光脉冲的“有” 和“无” 来表示二进制码中的“1”和“0"。 该方法虽然简单, 却存在三个问题:
1)遇到数字序列中出现长连“0” 或长连“1” 时, 将给光纤线路上再生中继器和终端光接收机的定时信息提取工作带来困难;
2)简单的单极性码中含有直流分量。 由于线路上光脉冲中“1” 和“0” 是随机变化的,这将导致单极性码的直流成分也作随机性的变化。 这种随机性变化的直流成分, 可以通过光接收机的交流耦合电路引起数字信号的基线漂移, 给数字信号的判决和再生带来困难;
3)不能实现不中断通信业务下的误码检测;
为解决以上问题, 通常对于由电端机输出的信号码流, 在未对 LED(或 LD)调制以前,一般要先进行码型变换使调制后的光脉冲码流由简单的单极性码,转换为适合于数字光纤传输系统传输的线路码。 适合于光纤通信的线路码型有多种, 但都要满足以下要求:
1)能保证比特序列独特性。
2)能提供足够的定时信息。
由于在光纤数字传输系统的传输中, 只传送信码, 而不传送时钟, 因此在接收端, 必须从收到的码流中提取出定时信息, 以利于上述的定时提取。 必须限制线路码流中同符号连续数不能过大, 也就是说, 应避免长连“0” 及长连“1” 的出现, 提高电平跳变的密度, 使定时提取较为简单。
3)减少功率密度中的高低频分量。
线路码的功率谱密度中的低频分量是由码流中的“0”、“1” 分布状态来决定的, 低频分量小, 说明“0”、 “1”分布比较均匀, 直流电平比较恒定, 也就是信号基线浮动小, 有利于接收端判决电路的正常工作。 高频分量是由线路码的速率决定的, 这在带宽(色散)限制系统中特别值得注意, 在这种系统中, 中继距离主要由光纤线路的总带宽(总色散)决定, 如果线路码速率提高的太多, 会使中继距离大大缩短。
4)要有利于减少码流的基线漂移, 即要求码流中的“1"、 "0” 码分布均匀, 否则不利于接收端的的再生判决。
5)码率增加要少, 光功率代价要低。
6)接收端将线路码还原后, 误码增殖要小。
线路传输中发生的一个误码, 往往使接收端的解码(反变换)发生多个错误, 这就是误码倍增, 也叫做误码扩展或误码增值。 由于误码倍增, 使光接收机要达到原要求的误码性能指标, 必须付出光功率代价, 即光接收机灵敏度劣化。 因此误码倍增系数越小越好。
7)能提供适当的冗余度。
8)低的对称抖动。
传输的比特序列必须保持低的码型相关的抖动。
9)易于实现。
数字光纤通信系统中常用的线路码型有:加扰二进码、 插入比特码和 mBnB 码。
2、8B/10B 编解码原理
8B/10B编码最初由IBM公司的Albert X.Widemer和Peter A.Franaszek发明,并应用于ESCON(200M互连系统)中。 它是mBnB编码中的一个特例。
8B/10B编码方法是把8bit代码组合编码成10bit代码,代码组合包含256个数据字符编码和12个控制字符编码,分别记为Dx. y和Kx.y。 通过仔细选择编码方法可以获得不同的优化特性。 这些特性包括满足串行/解串行器功能必须的变换; 确保“0” 码元与“1” 码元个数的一致, 又称为直流均衡; 确保字节同步易于实现(在一个比特流中找到字节的起始位); 以及对误码率有足够的容忍能力和降低设计复杂度。
8B/10B编码方案是把8bit数据分成2个子分组: 3个最高有效位(y)和5个最低有效位( x)。 代码字按顺序排列,从最高有效位到最低有效位分别记为H、 G、 F和E、 D、 C、 B、 A。 3bit的子分组编码成4 bit,记为j、 h、 g、 f; 5 bit的子分组编码成6bit,记为i、 e、 d、 c、 b、a,其映射关系如图1所示,4bit和6bit的子分组再组合成10bit的编码值。

将8bit数据分成3bit和5bit两组,分别对应10bit中的4bit和6bit,直流平衡代码的不平衡度就是通过“0” 的个数减去“1” 的个数来计算得到的。 如果4bit和6bit的各分组中“0”和“1” 的个数相等,称为完美平衡代码,或称为完美的直流平衡代码,无需补偿,但是这种情况是不可能的。 因为在4bit的子分组中,16种编码中只有6 种是完美平衡的,这对于3bit的8种编码值是不够的。 同时,在6bit的子分组中也只有20种编码是完美平衡的,对于5bit的32种编码值也是不够的。 由于4 bit和6bit的两个子分组都是偶数个位数,而不平衡度不可能是“+1” 或“-1”,因此,在8B/10B编码方案中还要使用不平衡度为“+2” 和“-2” 的值。 在编码过程中,用一个极性偏差( running disparity,RD)参数表示不平衡度,在不平衡时用2个10 bit字符表示一个8位字符,其中一个称为RD- ,表示“1” 的个数比“0” 的个数多2个,另一个称为RD+ ,表示“0” 的个数比“1” 的个数多2个。如下图所示:

8B/10B编码中将K28.1、K28.5和K28.7作为K码的控制字符,称为“comma”。在任意数据组合中,comma只作为控制字符出现,而在数据负荷部分不会出现,因此可以用comma字符指示帧的开始和结束标志,或始终修正和数据流对齐的控制字符。
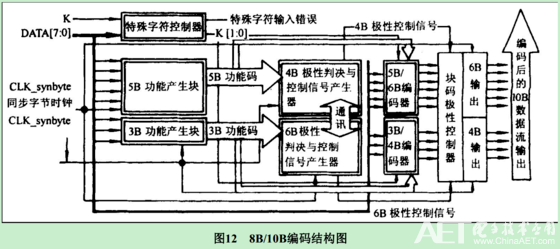
编码时,低5bit原数据 EDCBA经过5B/6B编码成为6bit码abcdei,高3bit原数据HGF经3B/4B成为4bit码fghj,最后再将两部分组合起来形成一个10bit码abcdeifghj。10B码在发送时,按照先发送低位在发送高位的顺序发送。

5B/6B编码和3B/4B编码的映射有标准化的表格,可以通过基于查找表的方式实现。使用 “不一致性(Disparity)”来描述编码中"1"的位数和"0"的位数的差值,它仅允许有"+2"( "0"比"1"多两个)、"0"( "0"与"1"个数相等)以及"-2"("1"比"0"多两个)这三种状况。 由于数据流不停地从发送端向接收端传输,前面所有已发送数据的不一致性累积产生的状态被称为“运行不一致性(Runing Disparity,RD)”。RD仅会出现+1与-1两种状态,分别代表位"1"比位"0"多或位"0"比位"1"多,其初始值是-1。Next RD值依赖于Current RD以及当前6B码或者4B码的Disparity。根据Current RD的值,决定5B/4B和 3B/4B编码映射方式,如下图所示。



这样,经过8B/10B编码以后,连续的“1”和“0”基本上不会超过5bit,只有在使用comma时,才会出现连续的5个0或1。接收端的数据解码过程如下图所示:

3、8B/10B 码的优势
8B/10B编码技术编码之所以能得到广泛应用,主要在于它较好地解决了以下问题。
(1) 转换密度:
保证数据流中有足够的信号转换。 采用8B/10B编码方法,数据流中连续的“1” 或连续的“0”不超过5个,使接收端锁相环( PLL)能正常工作,避免接收端时钟漂移或同步丢失而引起数据丢失。 保证了1和0的相对平衡组合,而与数据值无关,简化了时钟恢复,降低了接收机成本。
(2)DC补偿:
在高速的数据传输线路中,一般采用差分信号,需要直流分量尽量小,而8B/10B有DC补偿功能,即链路中不会随着时间推移而出现DC偏移。
(3)检错:
8B/10B编码采用冗余方式,将8位的数据和一些特殊字符按照特定的规则编码成10位的数据,根据这些规则,能检测出传输过程中单个和多个比特误码。
(4)特殊字符:
8B/10B编码规定了一些特殊字符,可用作帧同步字符和其他的分隔符或控制字符, 有助于比特流的码组定位和信息识别。 许多独立标准都以这个公共字符集为基础,定义更高的协议层:

(5)链路灵活性:
由于采用 8B/10B 编码, 链路可以是交流(AC)耦合的, 这样就给任一端的设备厂商提供了更大的灵活性。
4、8B/10B 码的实现与应用
进行编解码设计时通大体下面几种方法。
第一种是用查找表直接将8位信号映射成10位信号,该方法用存储器存储所有可能出现的码组,再将输入码组转换为存储地址,找出对应的编解码。 方法逻辑简单,开发时间很短,但是编解码电路的工作速度受到FPGA内部存储器读取时间的限制,同时不可避免地增加了芯片的面积和功耗。
第二种是通过逻辑运算直接完成编解码功能对,该方法的优点是可以明显减小内部使用面积,难点在于逻辑关系复杂。如果采用卡诺图直接化简则会产生大扇入逻辑表达式,大大限制电路的最高工作速度,同时对逻辑电路的驱动也将加大电路功耗。
第三种是,8B/10B编码模块化实现,较好地反映了8B/10B编码的特点,实现流程清楚。 实现步骤:
①判断是特殊字符还是数据;
②若是特殊字符,根据RD极性直接取值;
③若是数据,把一节8位字节拆成3bit和5bit,然后在RD控制器的控制下以并列的方式编/译码。 RD控制器的原则是: 系统设定的RD默认初始值为RD-, RD的初值作为选择信号用以决定5B/6B编码模块中6B码的选取, 同时由所选取的6B码计算出新的RD值作用于3B/4B编码模块。 4B编码所得到的RD值又作为下一组编码的RD输入值, 由此完成了全部的8B/10B编码。
这种方法的组合逻辑实现可以简化码表、 减小电路板的面积、 有效提高编码工作速度。同时由于电路板的面积减小,功耗也显著降低。
目前大多数高速串行标准都采用8B/10B编码方案,例如串行连接SCSI、 串行ATA、 光纤链路、 吉比特以太网、 XAUI(1吉比特接口)、 PCI Express总线、 InfiniBand、 Serial RapidIO、HyperTransport总线、 DVB-ASI以及IEEE1394b接口(火线) 技术中。
LDPC
LDPC代表“低密度奇偶校验码”(Low-Density Parity-Check)。它是一种错误检测和纠正编码技术,用于提高数据传输的可靠性。
LDPC码是由Robert G. Gallager于1962年提出的,但在近年来得到了更广泛和深入的研究和应用。
LDPC码是一种线性块码,具有良好的纠错性能和低的编码和译码复杂度。它通过在数据包中添加冗余位来实现错误检测和纠正功能。在编码过程中,数据被与校验位异或运算,产生一组冗余位,与原始数据一起发送。在接收端,使用迭代解码算法进行译码,以纠正传输过程中引入的错误。
LDPC码由一个稀疏随机校验矩阵描述,其中1表示校验位与数据位之间存在连接,0表示没有连接。校验矩阵的稀疏性是LDPC码的一个重要特点,这意味着大部分校验位与数据位之间是没有连接的,从而降低了解码的复杂度。
LDPC码具有优异的纠错性能,可以接近或达到香农极限,即通过适当选择码的参数,可以接近理论上的信道容量。它广泛应用于许多通信和存储系统中,如数字广播、无线通信、卫星通信、光通信、硬盘驱动器等。
尽管LDPC码具有较低的译码复杂度和良好的纠错性能,但其设计和实现仍然面临一些挑战,如选择合适的码长和码率、编码和解码算法的改进等。不过,由于LDPC码的优点,它已成为一种重要且常用的错误检测和纠正编码技术。
CRC
一个完整的数据帧通常由以下部分构成:

校验位是为了保证数据在传输过程中的完整性,采用一种指定的算法对原始数据进行计算,得出的一个校验值。接收方接收到数据时,采用同样的校验算法对原始数据进行计算,如果计算结果和接收到的校验值一致,说明数据校验正确,这一帧数据可以使用,如果不一致,说明传输过程中出现了差错,这一帧数据丢弃,请求重发。
常用的校验算法有奇偶校验、校验和、CRC,还有LRC、BCC等不常用的校验算法。
以串口通讯中的奇校验为例,如果数据中1的个数为奇数,则奇校验位0,否则为1。
例如原始数据为:0001 0011,数据中1的个数(或各位相加)为3,所以奇校验位为0。这种校验方法很简单,但这种校验方法有很大的误码率。假设由于传输过程中的干扰,接收端接收到的数据是0010 0011,通过奇校验运算,得到奇校验位的值为0,虽然校验通过,但是数据已经发生了错误。

校验和同理也会有类似的错误:

一个好的校验校验方法,配合数字信号编码方式,如(差分)曼彻斯特编码,(不)归零码等对数据进行编码,可大大提高通信的健壮性和稳定性。例如以太网中使用的是CRC-32校验,曼彻斯特编码方式。本篇文章介绍CRC校验的原理和实现方法。
CRC算法简介
循环冗余校验(Cyclic Redundancy Check, CRC)是一种根据网络数据包或计算机文件等数据产生简短固定位数校验码的一种信道编码技术,主要用来检测或校验数据传输或者保存后可能出现的错误。它是利用除法及余数的原理来作错误侦测的。
CRC校验计算速度快,检错能力强,易于用编码器等硬件电路实现。从检错的正确率与速度、成本等方面,都比奇偶校验等校验方式具有优势。因而,CRC 成为计算机信息通信领域最为普遍的校验方式。常见应用有以太网/USB通信,压缩解压,视频编码,图像存储,磁盘读写等。
CRC参数模型
不知道你是否遇到过这种情况,同样的CRC多项式,调用不同的CRC计算函数,得到的结果却不一样,而且和手算的结果也不一样,这就涉及到CRC的参数模型了。计算一个正确的CRC值,需要知道CRC的参数模型。
一个完整的CRC参数模型应该包含以下信息:WIDTH,POLY,INIT,REFIN,REFOUT,XOROUT。
- NAME:参数模型名称。
- WIDTH:宽度,即生成的CRC数据位宽,如CRC-8,生成的CRC为8位
- POLY:十六进制多项式,省略最高位1,如 x8 + x2 + x + 1,二进制为1 0000 0111,省略最高位1,转换为十六进制为0x07。
- INIT:CRC初始值,和WIDTH位宽一致。
- REFIN:true或false,在进行计算之前,原始数据是否翻转,如原始数据:0x34 = 0011 0100,如果REFIN为true,进行翻转之后为0010 1100 = 0x2c
- REFOUT:true或false,运算完成之后,得到的CRC值是否进行翻转,如计算得到的CRC值:0x97 = 1001 0111,如果REFOUT为true,进行翻转之后为11101001 = 0xE9。
- XOROUT:计算结果与此参数进行异或运算后得到最终的CRC值,和WIDTH位宽一致。
通常如果只给了一个多项式,其他的没有说明则:INIT=0x00,REFIN=false,REFOUT=false,XOROUT=0x00。
常用的21个标准CRC参数模型:

CRC校验在电子通信领域非常常用,可以说有通信存在的地方,就有CRC校验:
- 美信(MAXIM)的芯片DS2401/DS18B20,都是使用的CRC-8/MAXIM模型
- SD卡或MMC使用的是CRC-7/MMC模型
- Modbus通信使用的是CRC-16/MODBUS参数模型
- USB协议中使用的CRC-5/USB和CRC-16/USB模型
- STM32自带的硬件CRC计算模块使用的是CRC-32模型
至于多项式的选择,初始值和异或值的选择,输入输出是否翻转,这就涉及到一定的编码和数学知识了。感兴趣的朋友,可以了解一下每个CRC模型各个参数的来源。至于每种参数模型的检错能力、重复率,需要专业的数学计算了,不在本文讨论的范畴内。
CRC计算
好了,了解了CRC参数模型知识,下面手算一个CRC值,来了解CRC计算的原理。
问:原始数据:0x34,使用CRC-8/MAXIN参数模型,求CRC值?
答:根据CRC参数模型表,得到CRC-8/MAXIN的参数如下:
POLY = 0x31 = 0011 0001(最高位1已经省略)
INIT = 0x00
XOROUT = 0x00
REFIN = TRUE
REFOUT = TRUE有了上面的参数,这样计算条件才算完整,下面来实际计算:
0.原始数据 = 0x34 = 0011 0100,多项式 = 0x31 = 1 0011 0001
1.INIT = 00,原始数据高8位和初始值进行异或运算保持不变。
2.REFIN为TRUE,需要先对原始数据进行翻转:0011 0100 > 0010 1100
3.原始数据左移8位,即后面补8个0:0010 1100 0000 0000
4.把处理之后的数据和多项式进行模2除法,求得余数:
原始数据:0010 1100 0000 0000 = 10 1100 0000 0000
多项式:1 0011 0001
模2除法取余数低8位:1111 1011
5.与XOROUT进行异或,1111 1011 xor 0000 0000 = 1111 1011
6.因为REFOUT为TRUE,对结果进行翻转得到最终的CRC-8值:1101 1111 = 0xDF
7.数据+CRC:0011 0100 1101 1111 = 34DF,相当于原始数据左移8位+余数。模2除法求余数:

验证手算结果:

可以看出是一致的,当你手算的结果和工具计算结果不一致时,可以看看INIT,XOROUT,REFINT,REFOUT这些参数是否一致,有1个参数不对,计算出的CRC结果都不一样。
CRC校验
上面通过笔算的方式,讲解了CRC计算的原理,下面来介绍一下如何进行校验。
按照上面CRC计算的结果,最终的数据帧:0011 0100 1101 1111 = 34DF,前8位0011 0100是原始数据,后8位1101 1111 是 CRC结果。
接收端的校验有两种方式,一种是和CRC计算一样,在本地把接收到的数据和CRC分离,然后在本地对数据进行CRC运算,得到的CRC值和接收到的CRC进行比较,如果一致,说明数据接收正确,如果不一致,说明数据有错误。
另一种方法是把整个数据帧进行CRC运算,因为是数据帧相当于把原始数据左移8位,然后加上余数,如果直接对整个数据帧进行CRC运算(除以多项式),那么余数应该为0,如果不为0说明数据出错。

而且,不同位出错,余数也不同,可以证明,余数与出错位数的对应关系只与CRC参数模型有关,而与原始数据无关。
CRC计算的C语言实现
无论是用C还是其他语言,实现方法网上很多,这里我找了一个基于C语言的CRC计算库,里面包含了常用的21个CRC参数模型计算函数,可以直接使用,只有crcLib.c和crcLib.h两个文件。
GitHub地址:https://github.com/whik/crc-lib-c
使用方法非常简单:
#include <stdio.h>
#include <stdlib.h>
#include "crcLib.h"
int main()
{
uint8_t LENGTH = 10;
uint8_t data[LENGTH];
uint8_t crc;
for(int i = 0; i < LENGTH; i++)
{
data[i] = i*5;
printf("%02x ", data[i]);
}
printf("\n");
crc = crc8_maxim(data, LENGTH);
printf("CRC-8/MAXIM:%02x\n", crc);
return 0;
}计算结果:

CRC计算工具
下面这几款工具都可以自定义CRC算法模型,而且都有标准CRC模型可供选择。如果自己用C语言或者Verilog实现校验算法时,非常适合作为标准答案进行验证。
- 在线计算:http://www.ip33.com/crc.html
- 离线计算工具:CRC_Calc v0.1.exe或者GCRC.exe
格西CRC计算器:

总结
CRC校验并不能100%的检查出数据的错误,非常低的概率会出现CRC校验正确但数据中有错误位的情况。这和CRC的位数,多项式的选择等等有很大的关系,所以在实际使用中尽量选择标准CRC参数模型,这些多项式参数都是经过理论计算得出的,可以提高CRC的检错能力。CRC校验可以检错,也可以纠正单一比特的错误,你知道纠错的原理吗?















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









