







优化参数设置
与传统神经网络的优化类似,通常使用批次梯度下降算法来进行模型参数的
调优。同时,通过调整学习率以及优化器中的梯度修正策略,可以进一步提升训练的稳定性。为了防止模型对数据产生过度拟合,训练中还需要引入一系列正则化方法。
1、基于批次数据的训练
在大模型预训练中,采用了动态批次调整策略,即在训练过程中逐渐增加批次大小,最终达到百万级别。相关研究表明,动态调整批次大小的策略可以有效地稳定大语言模型的训练过程。因为较小的批次对应反向传播的频率更高,训练早期可以使用少量的数据让模型的损失尽快下降;而较大的批次可以在后期让模型的损失下降地更加稳定,使模型更好地收敛。
2、学习率
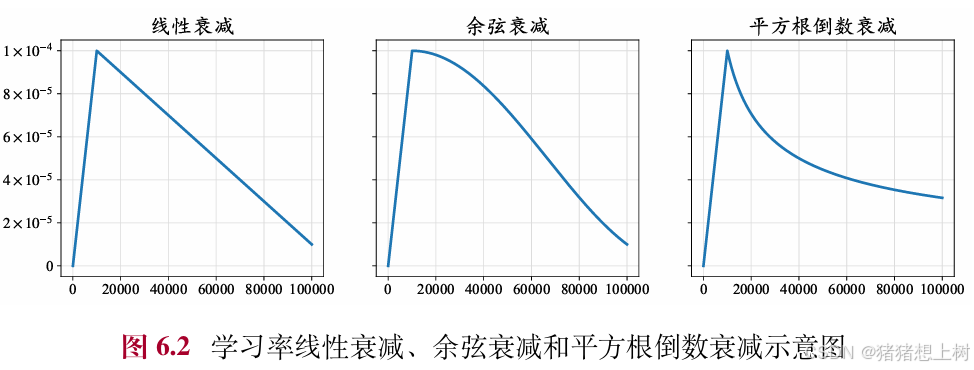
现有的大语言模型在预训练阶段通常采用相似的学习率调整策略,包括预热阶段和衰减阶段。。在模型训练的初始阶段,由于参数是随机初始化的,梯度通常也比较大,因此需要使用较小的学习率使得训练较为稳定。训练中通常采用线性预热策略来逐步调整学习率。学习率将从一个非常小的数值(例如0或者1×10−8)线性平稳增加,直到达到预设的最大阈值。达到最大阈值之后学习率会开始逐渐衰减,以避免在较优点附近来回震荡。最后,学习率一般会衰减到其最大阈值的10%。
3、优化器
大语言模型的训练通常采用Adam及其变种AdamW作为优化器。Adam优化器使用梯度的“动量”作为参数的更新方向,它使用历史更新步骤中的梯度加权平均值来代替当前时刻的梯度,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2727
2727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









