






前言
本文结合笔者这段时间的学习、实践经验,对大模型的基础知识以及应用进行简单的介绍,文章偏向于信息整合
目录
大模型基础
-
基础知识
-
模型结构
-
位置编码
-
norm方法
-
分词器
-
注意力机制
-
激活函数
-
分布式技术
-
数据并行
-
模型并行
-
混合精度训练
-
激活重计算
-
推理加速
-
vllm
-
flash attention
-
meduse
大模型应用
-
SFT
-
RAG
-
agent
1、大模型基础
1.1 基础知识
(1)模型结构
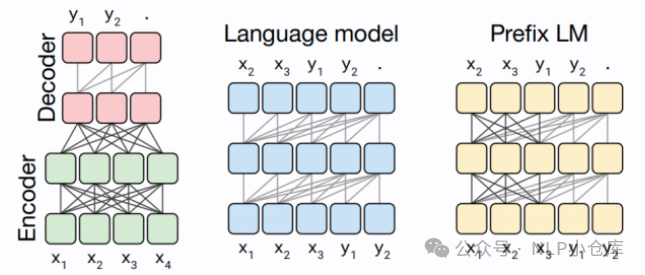
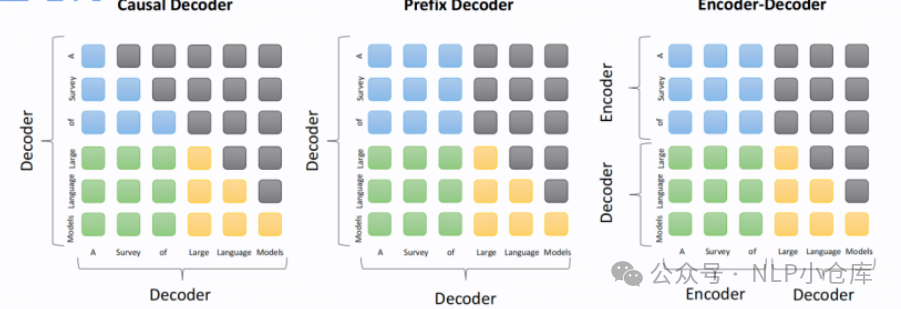
对于生成式模型,一般会有以上几种模型结构:
-
encoder-decoder
-
输入为双向注意力,输出为单向注意力,典型代表有T5、BART
-
在输入上采用了双向注意力,对问题的编码理解更充分,在NLU上效果较好;但在长文本生成任务上效果较差,训练效率低
-
causal decoder
-
单项注意力,典型代表GPT系列、LLAMA、BLOOM、OPT
-
自回归语言模型,预训练和下游应用是完全一致的,文本生成任务效果好,训练效率高
-
prefix decoder
-
输入双向注意力,输出单向注意力,典型代表GLM
-
encoder-decoder和causal decoder的折中,训练效率低
(2)位置编码
常用的位置编码有三角函数式位置编码、绝对位置编码、相对位置编码、旋转位置编码以及ALIBI(attention with linear biases)
0)三角函数式位置编码
三角函数式位置编码是指Transformer使用的位置编码,该编码有公式计算得到,不可训练
三角函数式位置编码由于其周期性,因此存在一定的外推性;并且可以提供相对位置信息。如下式所示,位置处的向量可以表示成位置和位置的向量组合
for pos in range(vocab_size): for i in range(depth // 2): embeddings_table[pos, 2 * i] = np.sin(pos / np.power(10000, 2 * i / depth)) embeddings_table[pos, 2 * i + 1] = np.cos(pos / np.power(10000, 2 * i / depth))
1)绝对位置编码
按照字出现在文本序列中的顺序给其编号,再求得其编码。简单来说,首先会初始化一个参数矩阵W,然后根据文字在句子中的位置[0,1,2,3,4,5,…],以look_up的方式从W取出对应的向量作为该字的初始化位置编码,然后在模型训练过程中不断更新W的值
绝对位置编码在速度上存在优势,缺点就是相对位置信息较少,而且外推性较差
if use_position_embeddings: assert_op = tf.assert_less_equal(seq_length, max_position_embeddings) with tf.control_dependencies([assert_op]): full_position_embeddings = tf.get_variable( name=position_embedding_name, shape=[max_position_embeddings, width], initializer=create_initializer(initializer_range)) position_embeddings = tf.slice(full_position_embeddings, [0, 0], [seq_length, -1]) num_dims = len(output.shape.as_list()) position_broadcast_shape = [] for _ in range(num_dims - 2): position_broadcast_shape.append(1) position_broadcast_shape.extend([seq_length, width]) position_embeddings = tf.reshape(position_embeddings, position_broadcast_shape) output += position_embeddings
2)相对位置编码
顾名思义,相对位置编码就是考虑每个字之间的相对位置,在建模时并没有建模每个输入的位置信息,而是在计算attention时考虑Q和K在位置上的相对距离
绝对位置编码的计算方式为:
计算可以得到:
在引入相对位置信息时,计算方式变为:
其中和表示位置和位置的相对位置信息
`attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True) relative_position_embeddings = None if use_relative_position_embeddings: assert from_seq_length == to_seq_length # `relations_key` = [F, T, H] relative_position_embeddings = self.get_relative_position_embeddings( from_seq_length, size_per_head, max_relative_position_embeddings=max_relative_position_embeddings, use_one_hot_embeddings=use_one_hot_embeddings, position_embedding_name=position_embedding_name) key_position_scores = tf.einsum("bnfh,fth->bnft", query_layer, relative_position_embeddings) attention_scores = attention_scores + key_position_scores # `context_layer` = [B, N, F, H] context_layer = tf.matmul(attention_probs, value_layer) if use_relative_position_embeddings: assert from_seq_length == to_seq_length value_position_scores = tf.einsum("bnft,fth->bnfh", attention_probs, relative_position_embeddings) context_layer = context_layer + value_position_scores `
3)旋转位置编码
旋转位置编码(ROPE)抛弃了位置编码常见的改进思路,以三角式位置编码公式为基础,调整自注意力计算偏置,通过旋转矩阵、复数乘法、欧拉公式等技巧,既能以自注意力矩阵偏置的形式反映两个token的相对位置信息,又能拆解到特征序列上,通过直接编码token的绝对位置实现,兼顾绝对位置编码和相对位置编码的优势。旋转位置编码的出发点就是,“通过绝对位置编码的方式实现相对位置编码”
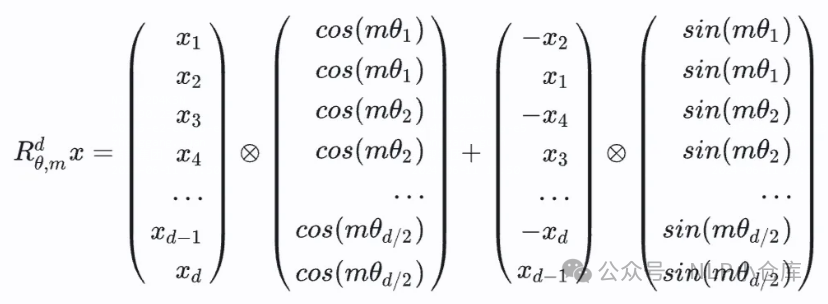 ROPE先将对应token的q和k以两两维度为一组进行切分,对切分后的每个二维向量旋转,旋转角的取值与三角式位置编码相同,旋转完将所有切分拼接,就得到了含有位置信息的特征向量
ROPE先将对应token的q和k以两两维度为一组进行切分,对切分后的每个二维向量旋转,旋转角的取值与三角式位置编码相同,旋转完将所有切分拼接,就得到了含有位置信息的特征向量
`# hugging face中LLaMA2的实现 class LlamaRotaryEmbedding(torch.nn.Module): def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None): super().__init__() # 计算词向量元素两两分组以后,每组元素对应的旋转角度 # arange生成[0,2,4...126] inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float().to(device) / dim)) self.register_buffer("inv_freq", inv_freq) # Build here to make `torch.jit.trace` work. self.max_seq_len_cached = max_position_embeddings # t: [0,1,2,...,max_position_embeddings] t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype) freqs = torch.einsum("i,j->ij", t, self.inv_freq) # Different from paper, but it uses a different permutation in order to obtain the same calculation emb = torch.cat((freqs, freqs), dim=-1) self.register_buffer("cos_cached", emb.cos()[None, None, :, :], persistent=False) self.register_buffer("sin_cached", emb.sin()[None, None, :, :], persistent=False) def forward(self, x, seq_len=None): # x: [bs, num_attention_heads, seq_len, head_size] return ( self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype), self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype), ) def rotate_half(x): """Rotates half the hidden dims of the input.""" x1 = x[..., : x.shape[-1] // 2] x2 = x[..., x.shape[-1] // 2 :] # x2取的是后半部分 return torch.cat((-x2, x1), dim=-1) # 注意这里有个负号 def apply_rotary_pos_emb(q, k, cos, sin, position_ids): # The first two dimensions of cos and sin are always 1, so we can `squeeze` them. cos = cos.squeeze(1).squeeze(0) # [seq_len, dim] sin = sin.squeeze(1).squeeze(0) # [seq_len, dim] cos = cos[position_ids].unsqueeze(1) sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim] q_embed = (q * cos) + (rotate_half(q) * sin) k_embed = (k * cos) + (rotate_half(k) * sin) return q_embed, k_embed class LlamaAttention(nn.Module): def __init__(self, config: LlamaConfig): self.wq = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.wk = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.wv = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False) self.wo = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False) self.rotary_emb = LlamaRotaryEmbedding(self.head_dim, max_position_embeddings=self.max_position_embeddings) #每个attn里面做这个rotary_emb def forward(self, x: torch.Tensor): bsz, seqlen, _ = x.shape xq, xk, xv = self.wq(x), self.wk(x), self.wv(x) xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim) xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim) xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim) # attention 操作之前,应用旋转位置编码,rotary_emb只用到了xv的type cos, sin = self.rotary_emb(xv, seq_len=kv_seq_len) xq, xk = apply_rotary_emb(xq, xk, cos, sin, position_ids) #... # 进行后续Attention计算 scores = torch.matmul(xq, xk.transpose(1, 2)) / math.sqrt(dim) scores = F.softmax(scores.float(), dim=-1) output = torch.matmul(scores, xv) # (batch_size, seq_len, dim) `
4)alibi(attention with linear bias)
计算完attention score后直接为注意力得分矩阵增加一个预设的偏置矩阵
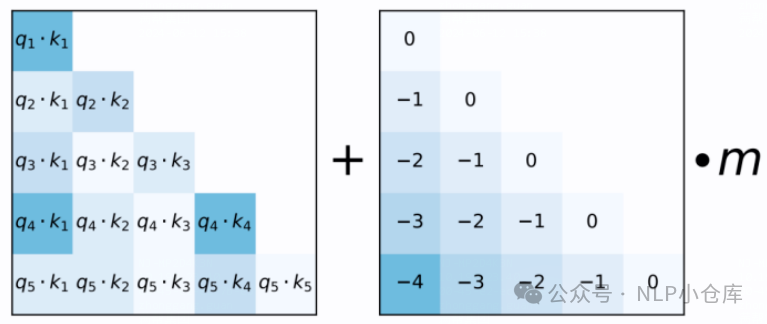 偏置矩阵根据qk的相对距离来惩罚注意力得分,相对距离越大,惩罚项越大
偏置矩阵根据qk的相对距离来惩罚注意力得分,相对距离越大,惩罚项越大
(3)norm方法
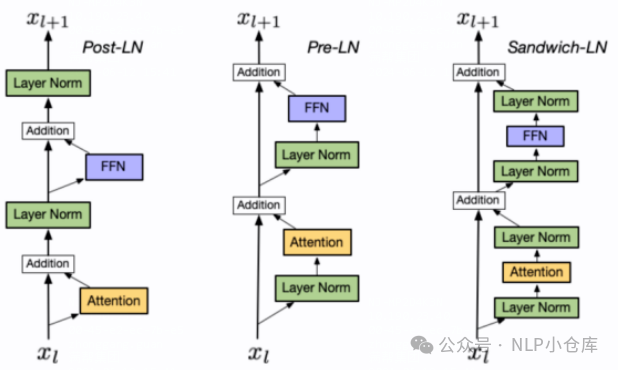
从norm块放置的位置可以分为:
-
post LN
-
LN出现在残差连接之后,当模型层数较深时,容易出现训练不稳定
-
pre LN
-
LN在每个模块(MHA\FNN)之前,训练更加稳定
-
sandwich LN
按照norm的实现方法可以分为:
-
layer norm
-
层归一化,针对同一条样本,所有网络层进行归一化
-
:可训练的再缩放参数;:可训练的再偏移参数
-
rms norm
-
简化了LN,分子上去掉了减去的均值部分,分母上使用了RMS
-
比LN速度更快
-
deep norm
-
缓解爆炸式模型更新的问题,把模型的更新限制在常数,使得模型训练过程更加稳定
-
在执行LN之前,放大了残差连接,并且在初始化阶段缩小了初始化值

-
batch norm
-
常用于图像领域
-
对同一批次样本的同一个神经元进行归一化
目前大模型中用的较多的是RMS归一化
(4)分词器
常见的分词方法有:
-
BPE(byte-pair encoding)
-
准备足够的训练语料,确定期望词表的大小
-
将单词拆分为字符粒度,在末尾添加后缀“”,统计单词词频
-
合并方式:统计每个连续/相邻字节对的出现频率,将最高频的连续字节对合并为新的子词
-
重复第三步,直到词表达到设定的大小,或者下一个最高频字节对出现频率为1
-
wordpiece
-
本质为BPE,区别在于:如何选择两个子词合并
-
BPE选择频次最大的相邻子词合并,wordpiece选择能够提升语言模型概率最大的相邻子词合并
-
sentencepiece
-
把空格也当作一种特殊字符来处理,再用BPE或者wordpiece来构造词表
(5)注意力机制
在基于自回归的大语言模型中,常见的注意力方法有:
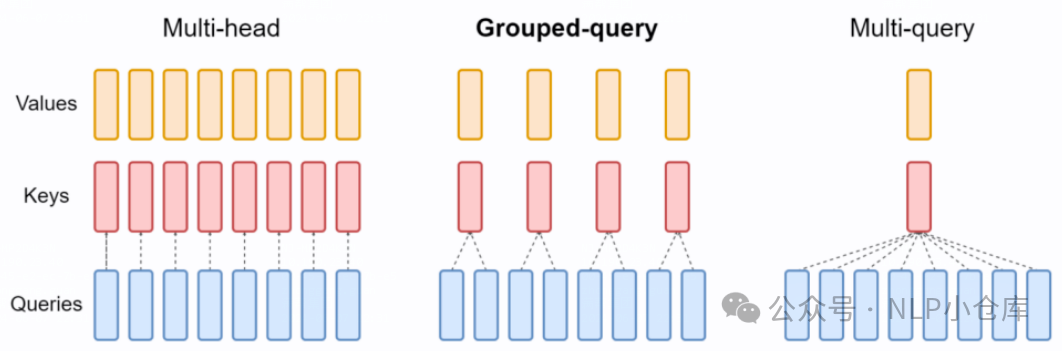
-
MHA(multi-head attention)
-
每个注意力头都有各自的QKV
-
MQA(multi-query attention)
-
所有注意力头共享KV
-
GQA(grouped-query attention)
-
介于上面两者之间
(6)激活函数
激活函数主要用于FNN模块,常用的激活函数:
-
GELU:
-
SWIGLU:
使用GLU线性门控单元的FNN模块:
-
GEGLU:
-
SwiGLU:
1.2 分布式技术
(1)数据并行
数据并行的核心思想是在各个GPU上都拷贝一份完整的模型,各自一份数据,算一份梯度,最后对梯度进行累加来更新整体的模型
一般数据并行可以分为DP(data parallelism)和DDP(distributed data parallelism),其中DP是早期的数据并行模式,多用于单机多卡,一般采用parameters server模式
1)DP
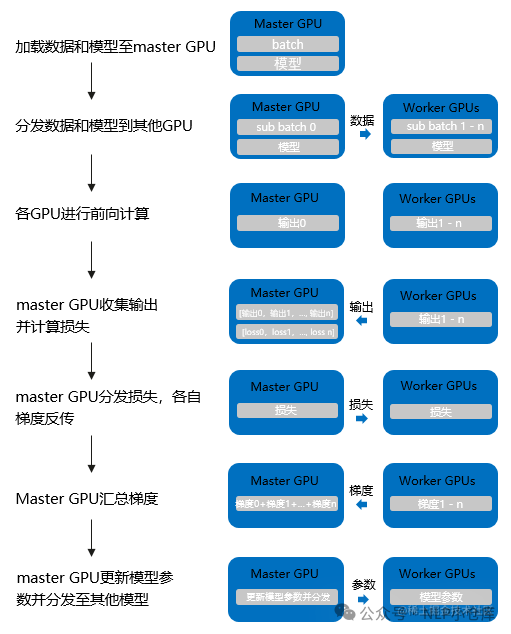
结合上图,数据并行的过程如下:
-
将输入从主GPU分发到所有GPU
-
将model从主GPU分发到所有GPU
-
每个GPU分别独立进行前向传播,得到输出
-
将每个GPU的输出发回主GPU
-
在主GPU上,通过损失函数计算loss,对loss求导得到梯度
-
将得到的梯度分发到所有GPU
-
反向传播计算参数梯度
-
将所有梯度回传主GPU,通过梯度更新模型参数
-
重复
缺点:
-
存储开销大。每块GPU都存了一份完整的模型,存在冗余
-
通讯开销大。主GPU需要和所有的GPU进行梯度传递,当两者不在同一台机器上时,主GPU的带宽将成为整个系统的计算效率瓶颈
代码:
net = torch.nn.DataParallel(model, device_ids=[0, 1, 2]) output = net(input_var) # input_var can be on any device, including CPU
2)DDP
DDP解决的就是通讯效率问题,将主GPU的通讯压力均衡转移到各个GPU上。比较典型的方法就是ring-allreduce
 如上图所示,allreduce的目标就是让每块GPU上的数据变成右边的形式,ring-allreduce则是将该步分两次进行reduce-scatter和all-gather。
如上图所示,allreduce的目标就是让每块GPU上的数据变成右边的形式,ring-allreduce则是将该步分两次进行reduce-scatter和all-gather。
reduce-scatter:定义网络拓扑关系,使得每个GPU只和其相邻的两块GPU通讯,每次发送对应位置的数据数据累加,每次累加更新都会形成一个拓扑环,因此被称为ring
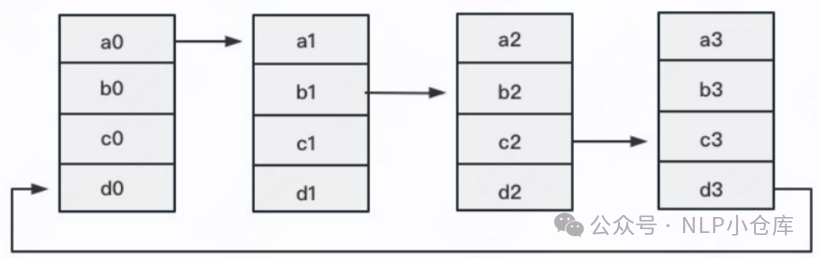
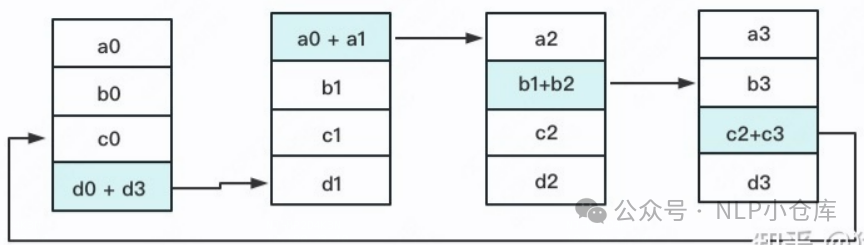
流程:
-
首先将rank=0进程中的模型参数广播到进程组中的其他进程
-
每个DDP进程都会创建一个local reducer来负责梯度同步
-
在训练过程中,每个进程从磁盘加载数据,并将其传递到GPU,每个GPU都有自己的前向过程,完成前向传播后,梯度在各个GPU间进行all-reduce,每个GPU都收到其他GPU的梯度,从而可以独自进行反向传播和参数更新
-
每一层梯度不依赖于前一层,所以梯度的all-reduce和后向过程同时计算
-
在后向过程的最后,每个节点都得到了平均梯度,各个GPU中模型参数保持同步
代码:
import torch import t dist import torch.multiprocessing as mp import torch.nn as nn import torch.optim as optim from torch.nn.parallel import DistributedDataParallel as DDP def example(rank, world_size): # create default process group dist.init_process_group("gloo", rank=rank, world_size=world_size) # create local model model = nn.Linear(10, 10).to(rank) # construct DDP model ddp_model = DDP(model, device_ids=[rank]) # define loss function and optimizer loss_fn = nn.MSELoss() optimizer = optim.SGD(ddp_model.parameters(), lr=0.001) # forward pass outputs = ddp_model(torch.randn(20, 10).to(rank)) labels = torch.randn(20, 10).to(rank) # backward pass loss_fn(outputs, labels).backward() # update parameters optimizer.step() def main(): world_size = 2 mp.spawn(example, args=(world_size,), nprocs=world_size, join=True) if __name__=="__main__": # Environment variables which need to be # set when using c10d's default "env" # initialization mode. os.environ["MASTER_ADDR"] = "localhost" os.environ["MASTER_PORT"] = "29500" main()
3)DP与DDP的区别
进程问题:DP是基于单进程多线程实现,只用于单机情况,DDP是多进程实现,每个GPU对应一个进程,适合单机和多机的情况
参数更新:DDP在各进程梯度计算完成后,各进程需要将梯度进行汇总平均,然后再由rank=0的进程将其广播到所有进程后,各进程用该梯度来独立更新参数,而DP是梯度汇总到GPU0,反向传播更新参数,再广播参数给其他剩余GPU
模型并行:DDP支持模型并行,DP不支持
数据传输:
-
DP的数据传输
-
前向传播得到的输出结果gather到主GPU计算loss
-
scatter上述loss到各个GPU
-
各个GPU反向传播计算得到梯度后gather到主GPU后,主GPU参数被更新
-
主GPU将模型参数广播到其他GPU设备上,完成权重参数的同步
-
DDP的数据传输
-
前向传播的输出和loss的计算都是在每个GPU独立计算的,梯度all-reduce到所有的GPU
4)ZeRO
一般情况下,在模型训练过程中,GPU需要进行存储的参数包括了模型本身的参数、优化器状态、激活函数的输出值、梯度以及一些零碎的buffer,各种数据的参数如下:
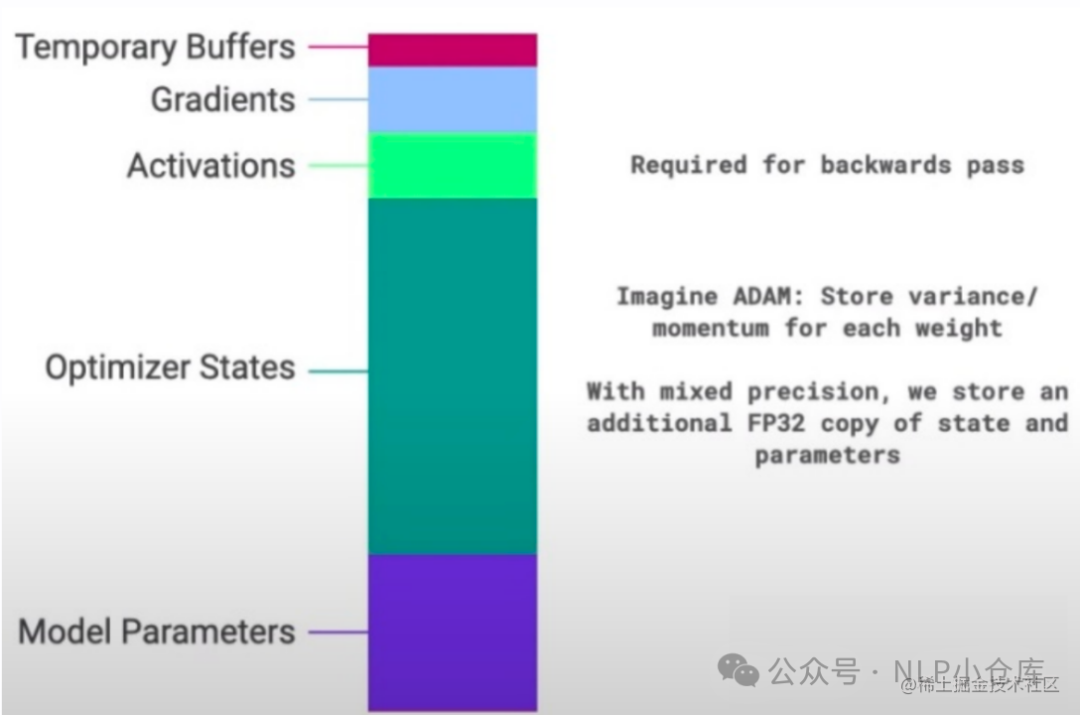 可以看到,在模型进行训练时,模型状态参数(优化器状态、梯度、模型参数)占到了大部分,在进行多卡的分布式训练时,每张卡上都会保存所有的参数,但是其中用到的参数仅仅是一部分,因此会存在大量的冗余数据
可以看到,在模型进行训练时,模型状态参数(优化器状态、梯度、模型参数)占到了大部分,在进行多卡的分布式训练时,每张卡上都会保存所有的参数,但是其中用到的参数仅仅是一部分,因此会存在大量的冗余数据
针对模型状态的存储优化,deepspeed提出了ZeRO,该方法的核心就是分片,即每张卡仅存1/N的模型状态量
ZeRO对模型状态参数进行了不同程度的分割:
-
ZeRO1:优化器状态分片
-
ZeRO2:优化器状态和梯度分片
-
ZeRO3:优化器状态、梯度、模型参数分片
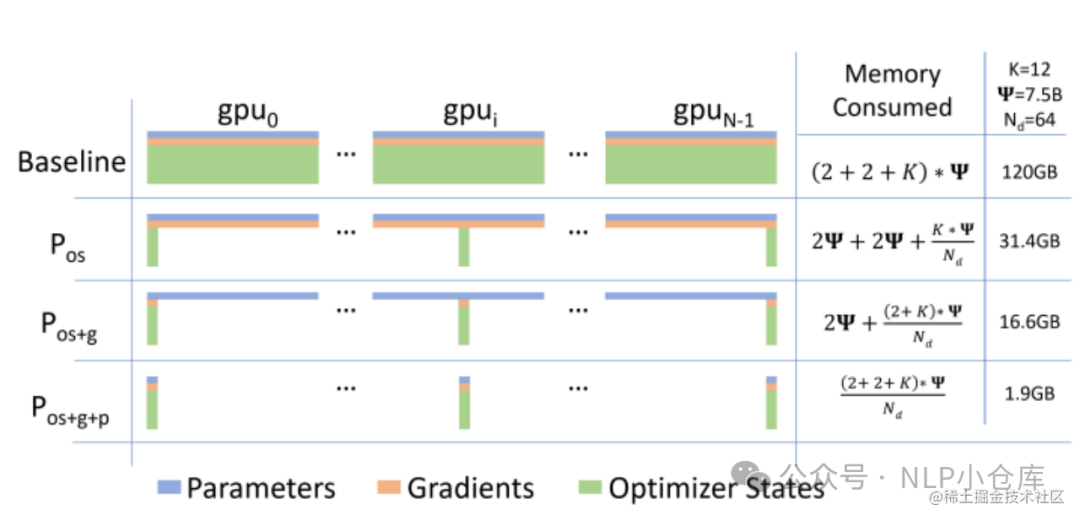
ZeRO1:
训练过程与DDP类似:
-
FWD时,由每个rank的GPU独立完整的完成,然后BWD,梯度通过allreduce同步
-
优化器基于贪心策略对参数进行分片,确保每个rank的参数量几乎一致
-
每个rank只负责更新当前优化器分片的部分
-
更新后,通过allgather的方式确保所有的rank都收到最新更新过后的模型参数
ZeRO2:
增加了对梯度的切分,在BWD过程中,梯度被reduce操作到对用的rank中,取代了allreduce,减少了通讯开销
ZeRO3:
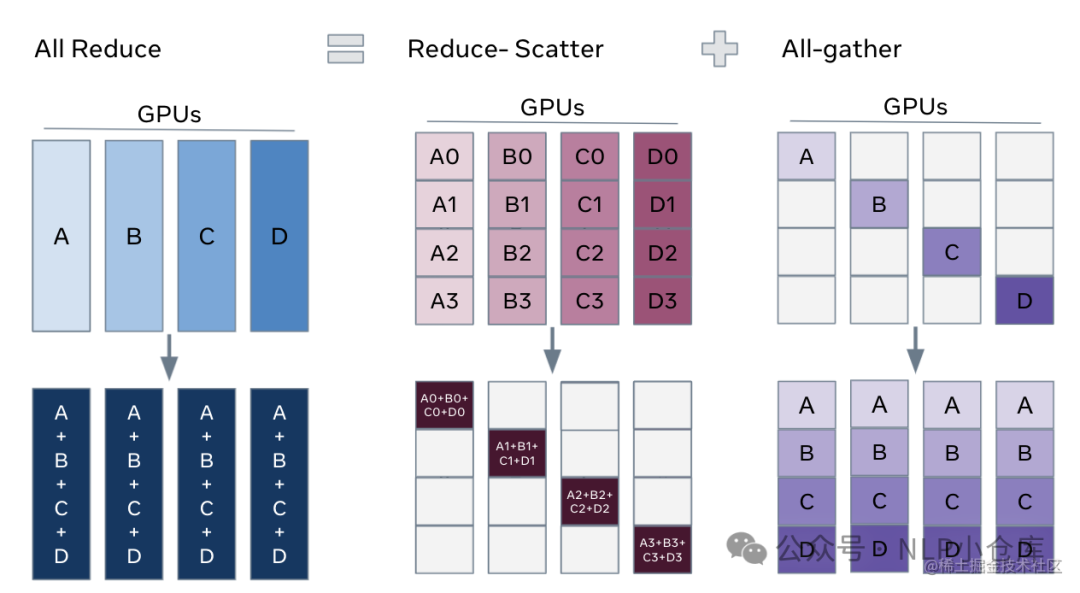
增加了对模型参数的切分,可以进行参数切分的原因:
-
allreduce可以被拆分为reduce和allgather操作
-
模型的每一层拥有该层的完整参数,并且整个层能够直接被一个GPU装下,所以FWD的时候,除了当前rank需要的层之外,其余层的参数可以抛弃
(2)模型并行
模型并行分为张量并行和流水线并行,张量并行为层内并行,流水线并行为层间并行
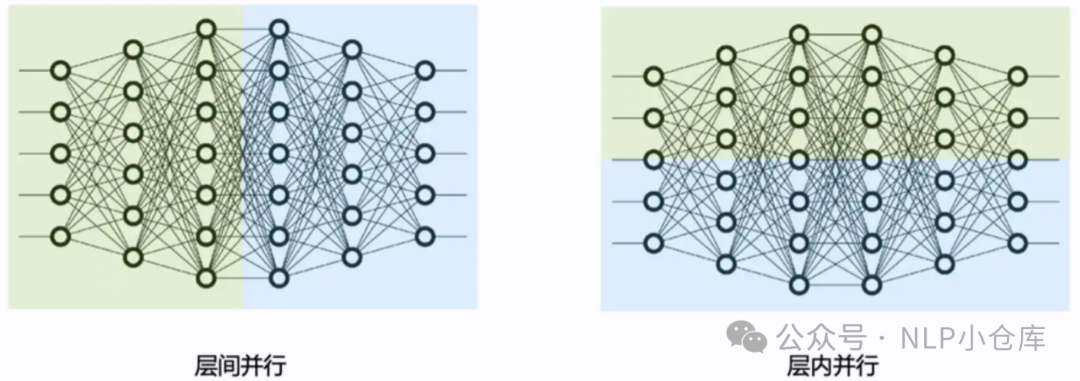
1)张量并行
将计算图中层内的参数切分到不同设备,每个设备只拥有模型的一部分,从数学角度,对于linear层,张量并行就是将矩阵分块计算,然后把结果合并,对于非linear层则不做额外设计
张量的切分可以按列和按行:
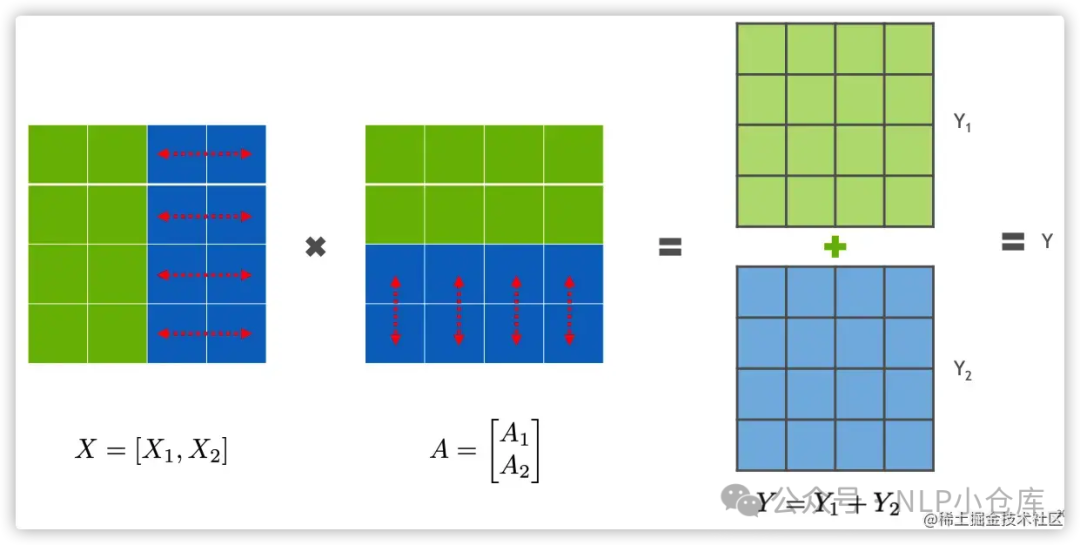
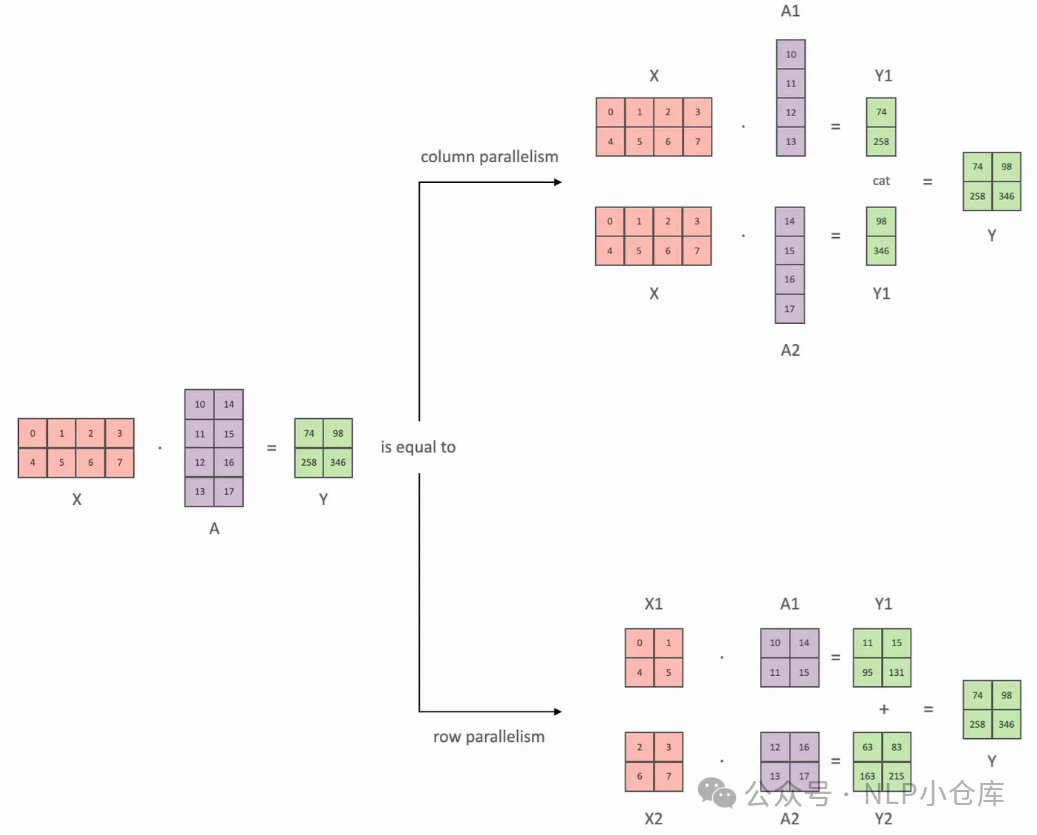 行并行就是把权重A按照行切分为两部分:
行并行就是把权重A按照行切分为两部分:
如上式,X1和A1可以放在GPU1计算出Y1,X2和A2可以放在GPU2计算出Y2,两者相加得到Y
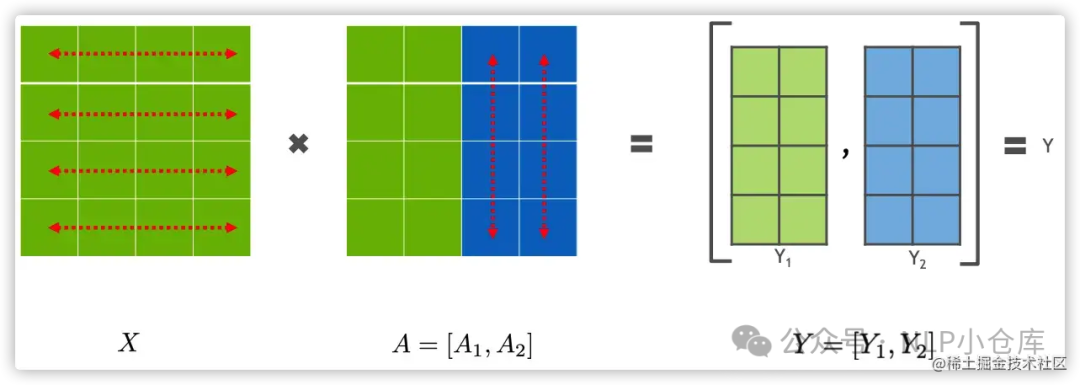
列并行,将A按列进行切分:
以transformer层为例,其网络结构主要由自注意力和MLP组成,对于MLP层主要有GELU激活函数和线性层组成,如下图所示,先对A采用列切割,再对B采用行切割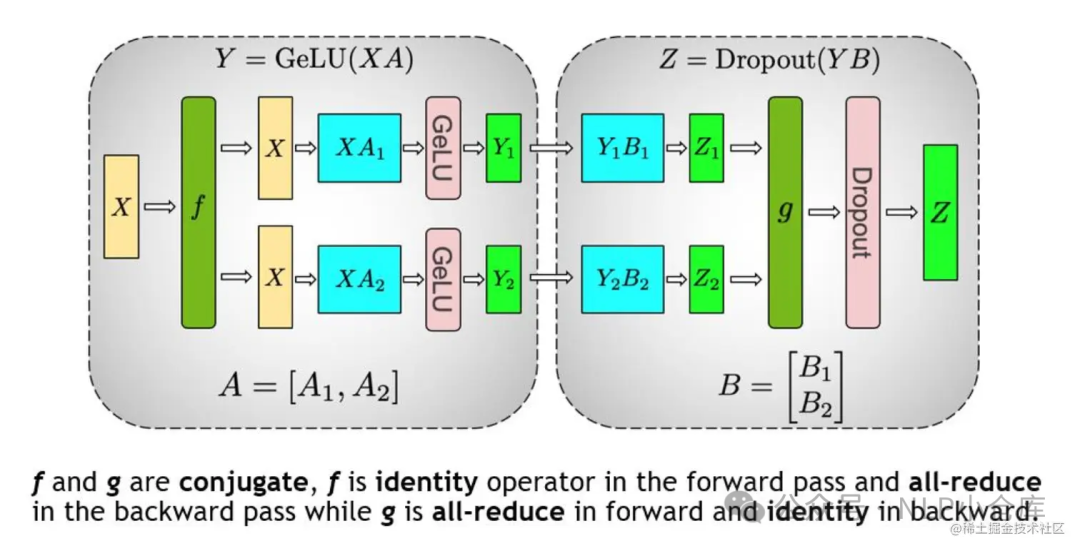
对于MHA,每个自注意力头可以独立计算,最后再拼接,也就是说可以把每个头的参数放到不同的GPU上,对MHA的张量切分如下:
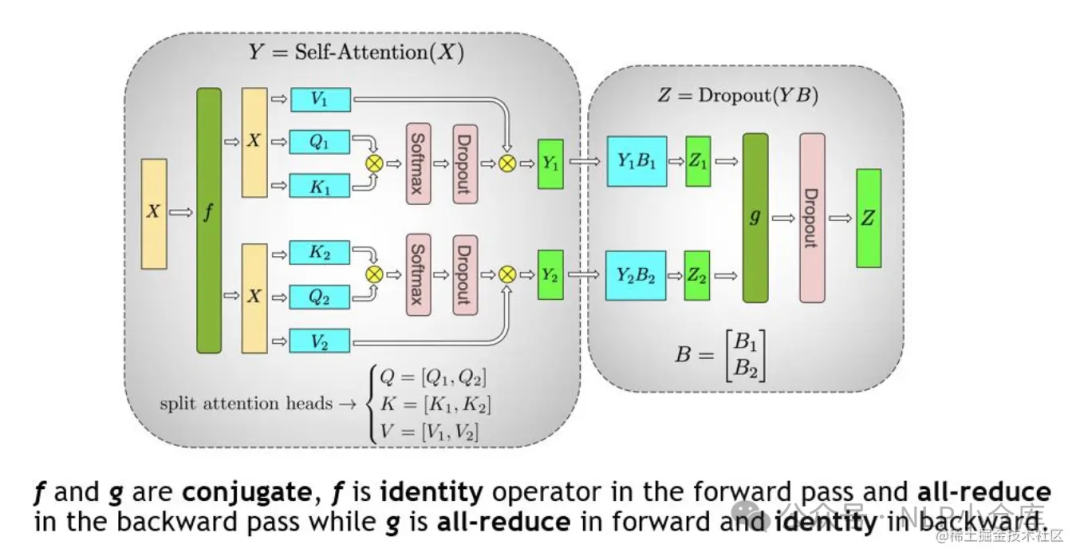 整个transformer层的张量并行如下:
整个transformer层的张量并行如下:
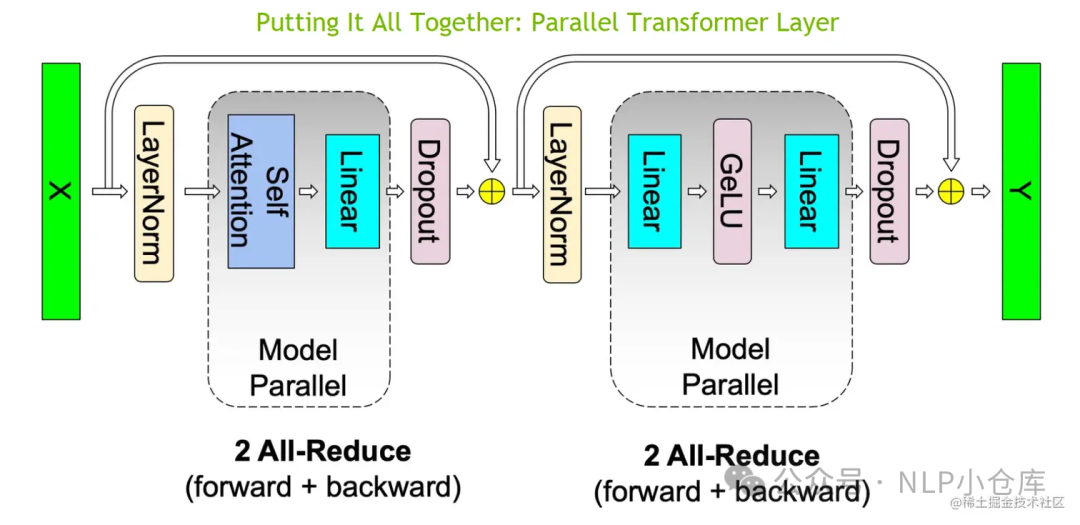
对于embedding层,则可以按照词的维度切分,每张卡只存储部分词向量表,然后通过allgather汇总各个设备上的部分词向量结果,从而得到完整的词向量结果
多维张量并行(Colossal-AI)
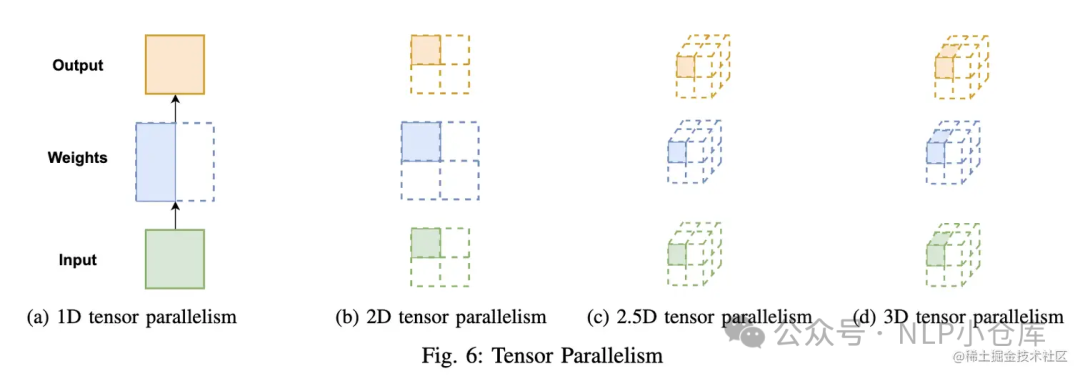
2)流水线并行
流水线并行就是将模型的不同层放置在不同的GPU。在FWD时,输入数据首先在设备0上通过第一层网络,得到中间结果,并将中间结果传递给设备1,然后在设备1上计算再往下一层传递,反向传播类似。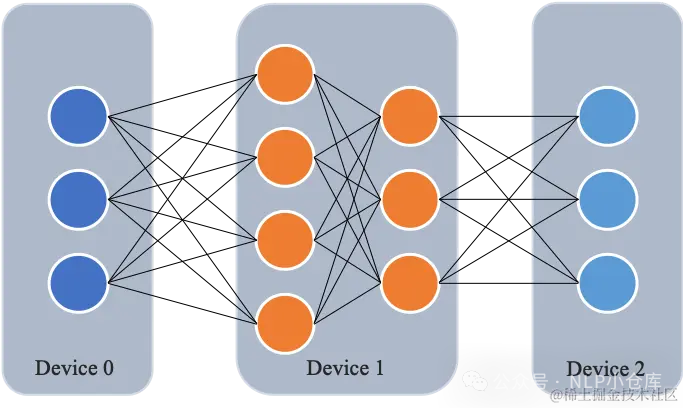
朴素流水线并行
实现流水线并行的最直接的方法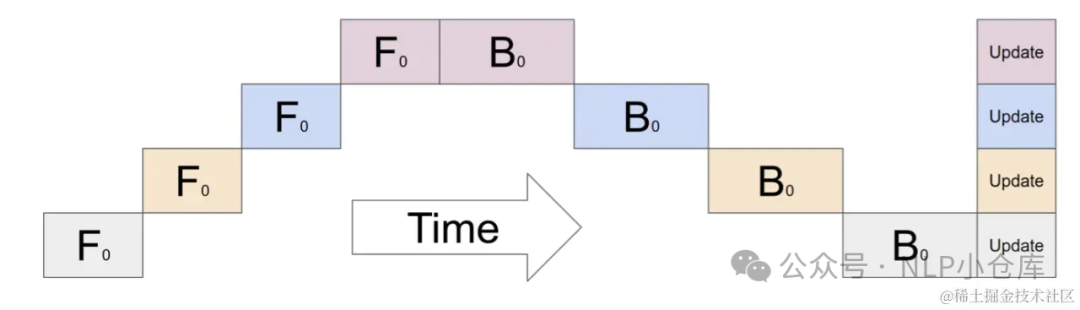 下面是朴素流水线并行实现训练的流程:
下面是朴素流水线并行实现训练的流程:
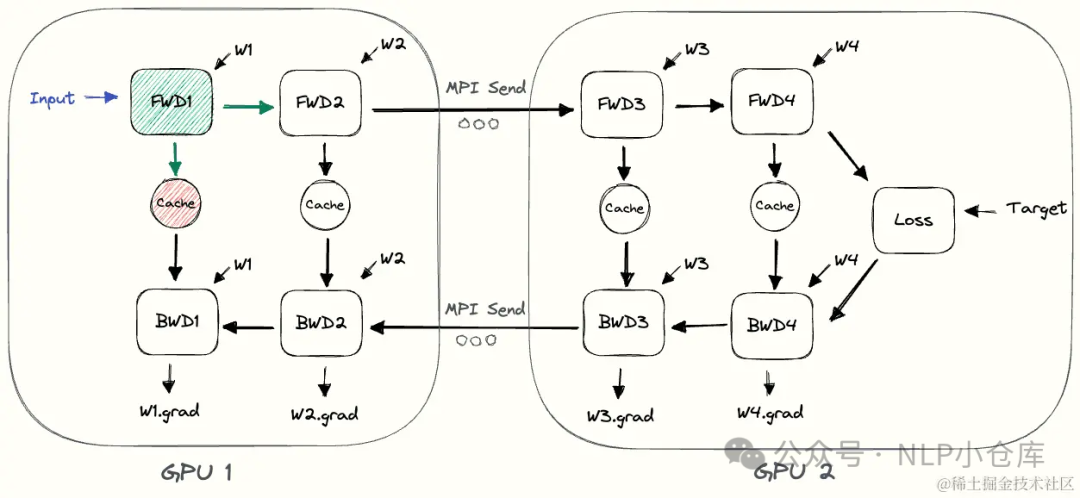 缺点:
缺点:
-
GPU利用率不足
-
通信耗时。设备之间复制数据的通信开销,通信和计算没有交错
-
内存问题。先执行前向传播的GPU将保留整个小批量缓存的所有激活,直到最后,当批量很大时,存在内存问题
微批次流水线并行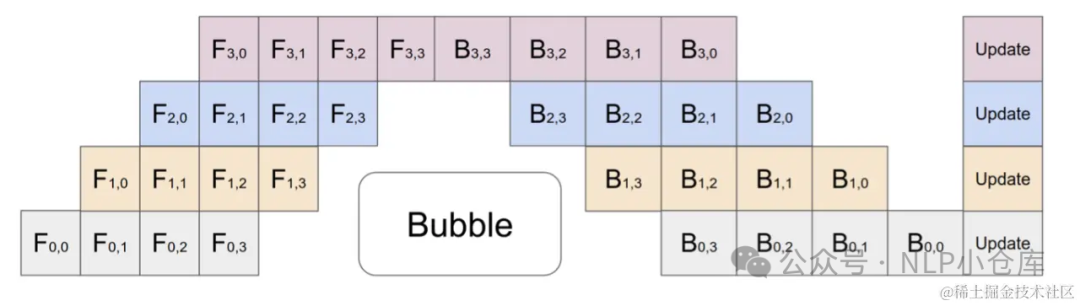 将传入的小批次分块为微批次,人为创建流水线来解决GPU空闲问题,从而允许不同的GPU同时参与计算过程,显著提高GPU利用率。
将传入的小批次分块为微批次,人为创建流水线来解决GPU空闲问题,从而允许不同的GPU同时参与计算过程,显著提高GPU利用率。
如上图所示,在计算完后,将值传递给下一层,当计算的时候,下一层的就可以并行执行。以此来提高GPU的利用率
(3)混合精度训练
模型的参数都是用浮点数来表示,精度指的就是表示一个浮点数所需要的位数。混合精度训练就是指在训练模型时,将某些参数转化为FP16的格式,来进行后面的计算,这样在模型训练中就会同时出现FP32和FP16的混合数据类型。FP32占用4个字节,FP16占用2个字节,因此可以节省显存。
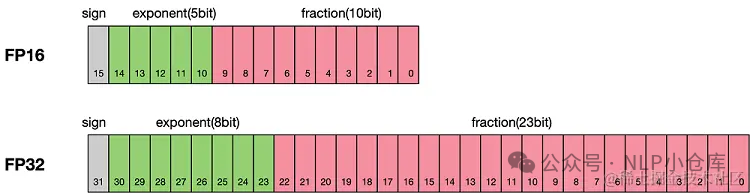
下图是FP16和FP32的表示范围对比,灰色部分为符号位,绿色部分为指数位,粉色部分为小数位。
-
FP16的最大范围是 [-65504 - 66504]
-
FP16能表示的精度是,超过这个数会直接置0
FP16的缺点:
-
下溢。模型的更新通常是G*LR,随着模型的训练这个值往往非常小,可能会超过FP16可以表示的精度,进而导致大多数模型权重都不在更新,模型难以收敛
-
舍入误差。模型权重和梯度相差太大,通过梯度更新权重并进行舍入时,可能导致更新前后模型权重无差别

为了利用FP16的优点,避开FP16的缺点,提出了混合精度训练。混合精度训练的核心就是,在内存中用FP16做存储和乘法进而加速计算,用FP32做累加避免舍入误差。即使用了混合精度训练还是会存在无法收敛的情况,因为存在下溢,可以使用损失放大的方式进行优化。损失放大思路:
-
反向传播前,将损失手动增大倍
-
反向传播后,将权重梯度缩小倍
混合精度训练中模型权重、梯度使用FP16,优化器参数使用FP32,此外,优化器还需要备份一份FP32的权重
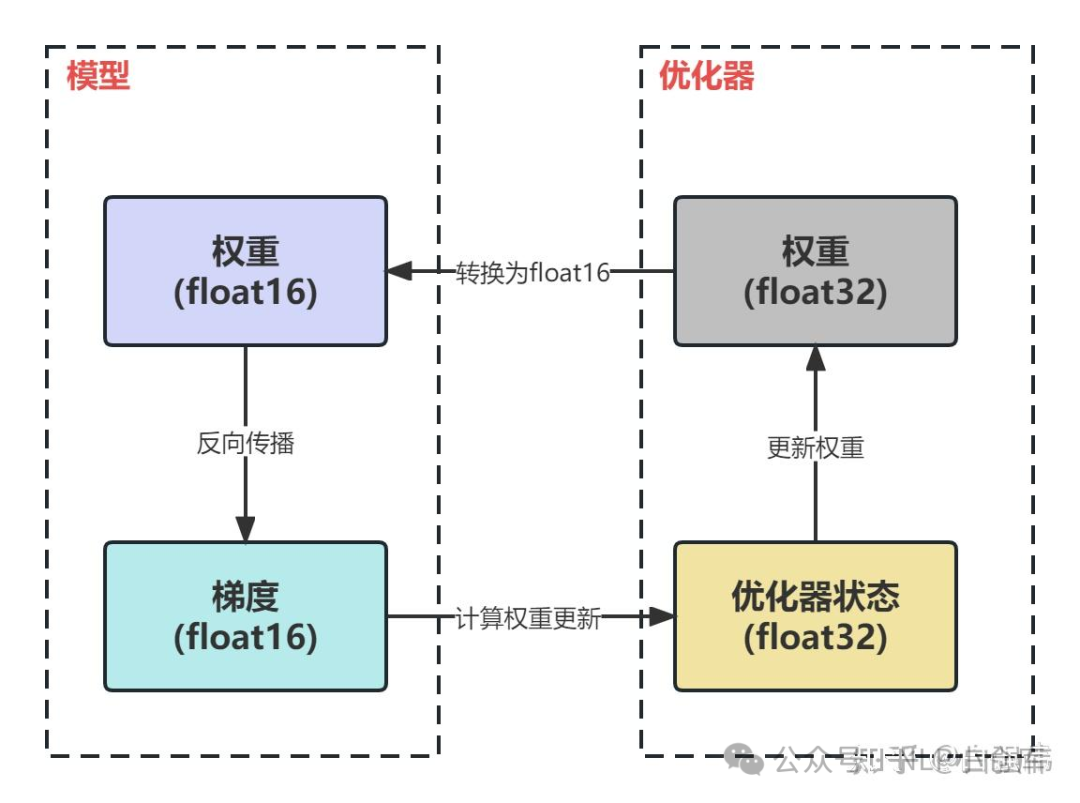 混合精度的训练过程:
混合精度的训练过程:
-
使用FP16进行FWD
-
BWD得到FP16的梯度
-
优化器计算出FP32权重的更新量
-
更新FP32权重
-
将FP32权重转化为FP16
混合精度下的显存计算方式:
模型在训练过程中的显存占用分为:主要显存消耗和剩余显存消耗
主要显存消耗:
 上图中表示参数量为的模型,比如llama-7b,参数量就是7B,对应的.根据上图可知,使用混合精度的模型主要显存占用为
上图中表示参数量为的模型,比如llama-7b,参数量就是7B,对应的.根据上图可知,使用混合精度的模型主要显存占用为
剩余显存消耗:
-
激活。模型在训练过程中激活值的保存
-
临时缓存区。用于存储中间结果
-
显存碎片。在进程发出显存请求时,如果没有连续的显存来满足请求,即使总的显存足够,请求也会失败,极端情况下可能会导致30%的显存碎片
BF16。BF16是对FP32的截断,用8BIT表示指数位,7BIT表示小数位,FP16用5BIT表示指数位,用10BIT表示小数位。BF16可表示的整数范围更广、尾数精度较小;FP16表示的整数范围较小,尾数精度较高
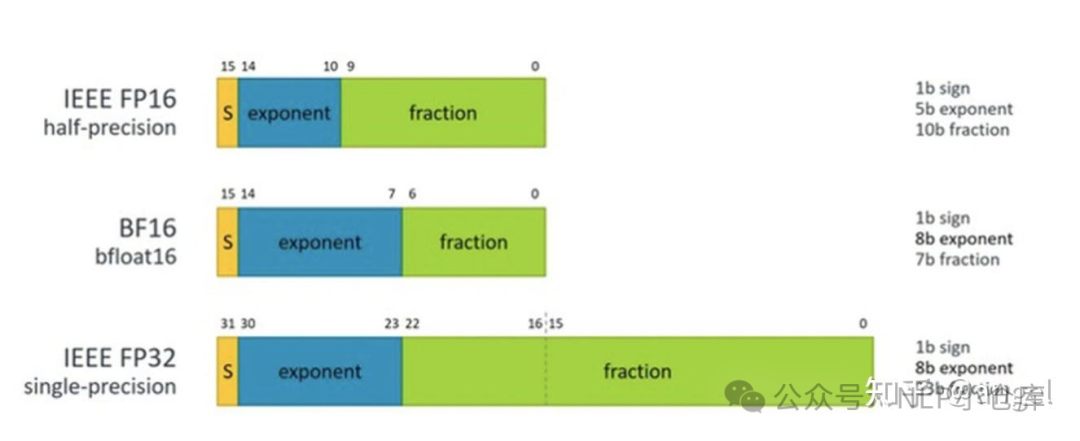 BF16可以表示的最小正值为,相比于FP16的最小正值,可以更好的避免下溢问题。最小正值的计算方式如下:
BF16可以表示的最小正值为,相比于FP16的最小正值,可以更好的避免下溢问题。最小正值的计算方式如下:

(4)激活重计算
激活重计算是一种降低激活值显存占用的方法。在训练模型时,通常会将所有前向传播时的激活值保存下来,消耗大量的显存。另一种方法是,在前向传播时丢掉激活值,在计算梯度时需要哪部分的激活值就重新计算哪部分的激活值,这样解决了显存的问题,但是加大了计算量
梯度重计算在上述两种方式中取得了一个平衡,具体来说,其采用了一种策略选择计算图上一部分激活值保存下来,其余部分丢弃,被丢弃的那部分激活值需要在计算梯度时重新计算
1.3 推理加速
(1)VLLM
vllm的核心技术是paged attention,吞吐量比huggingface transformer高出最多24倍,比text generation inference高出最多3.55倍,具有出色的推理吞吐量、对注意力KV内存的高效管理、动态批处理、优化的CUDA内核等特点
paged attention其优势主要体现在:
-
减少显存占用。用分块内存和共享内存优化了KV cache的存储
-
增大吞吐量:减少了单个序列的显存,从而增大了batch size,获得了更大的吞吐量
paged attention允许在非连续的内存空间中存储连续的key和value将每个序列的KV cache划分成块,每个块包含固定数量的token的键和值。因为块在内存中不需要连续,因而可以用一种更加灵活的方式管理key和value,就像在操作系统的虚拟内存中一样,将块视为页面,将token视为字节,将序列视作进程。内存浪费只会发生在最后一个块中,理想情况下,内存浪费不到4%
(2)flash attention
优点:
-
加快计算。从IO感知出发,减少了HBM(high bandwidth memory)的访问次数,进而减少了计算时间
-
节省显存。通过引入统计量,改变了注意力机制的计算顺序,避免了实例化注意力矩阵,将显存的复杂度从降低到

- 精确注意力。不同于稀疏注意力,FA是分块计算,而不是近似计算,与原生注意力等价
(3)MEDUSA
为了解决语言模型在每个解码步骤生成单个候选延续的方法导致了可接受长度受限和计算资源的低效使用,medusa使用增加head的方式,来生成多个候选延续,并通过注意力掩码的调整来进行验证。同时,使用温度系数作为阈值来管理原始模型预测的偏差,为拒绝采样提供了一种有效的替代方案,这种方法有效地解决了拒绝采样的局限性,比如在较高温度下的速度降低。
核心思想是在正常的LLM的基础上,增加几个解码头,并且每个头预测的偏移量不同,比如:原始头预测第i个token,新增的medusa头分别预测第i+1、i+2…个token,(这也是medusa可以加速的原因),每个头可以指定topk个结果,然后将所有的topk组装成一个个的候选结果,最后选择最优的结果。
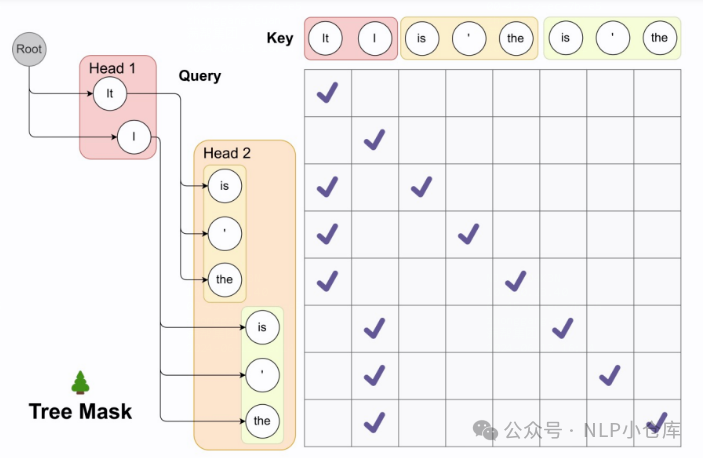
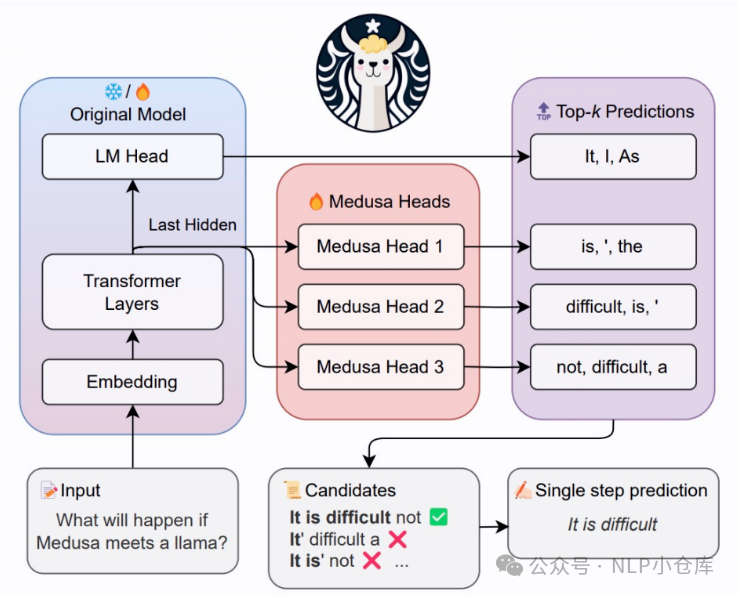 在计算每个候选的最优解的时候,作者设计了一种tree attention的机制,可以做到只走一次模型来达到目的,如下图所示。假设原始的LLM输出是[0],第一个头为[1,2],第二个头为[3,4,5],这时就会组合为[0,1,2,3,4,5,3,4,5]输入到模型,再配合位置id计算每条路径的得分
在计算每个候选的最优解的时候,作者设计了一种tree attention的机制,可以做到只走一次模型来达到目的,如下图所示。假设原始的LLM输出是[0],第一个头为[1,2],第二个头为[3,4,5],这时就会组合为[0,1,2,3,4,5,3,4,5]输入到模型,再配合位置id计算每条路径的得分
medusa head构建代码:
class CustomizedTrainer(Trainer): def compute_loss(self, model, inputs, return_outputs=False): # DDP will give us model.module if hasattr(model, "module"): medusa = model.module.medusa else: medusa = model.medusa logits = model( input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"] ) labels = inputs["labels"] # Shift so that tokens < n predict n loss = 0 loss_fct = CrossEntropyLoss() log = {} for i in range(medusa): medusa_logits = logits[i, :, : -(2 + i)].contiguous() medusa_labels = labels[..., 2 + i :].contiguous() medusa_logits = medusa_logits.view(-1, logits.shape[-1]) medusa_labels = medusa_labels.view(-1) medusa_labels = medusa_labels.to(medusa_logits.device) loss_i = loss_fct(medusa_logits, medusa_labels) loss += loss_i not_ignore = medusa_labels.ne(IGNORE_TOKEN_ID) medusa_labels = medusa_labels[not_ignore] # Add top-k accuracy for k in range(1, 6): _, topk = medusa_logits.topk(k, dim=-1) topk = topk[not_ignore] correct = topk.eq(medusa_labels.unsqueeze(-1)).any(-1) log[f"medusa{i}_top{k}"] = correct.float().mean().item() log[f"medusa{i}_loss"] = loss_i.item() self.log(log) return (loss, logits) if return_outputs else loss
2、大模型应用
当前大模型的应用多集中在api调用、SFT、RAG和agent这几块。其中SFT指有监督微调、RAG指检索增强生成、agent则是指智能体的概念
2.1 SFT
一般包括全量参数微调和参数高效微调。其中,参数高效微调包括prompt tuning、prefix tuning、adpter、lora等
(1)prompt tuning
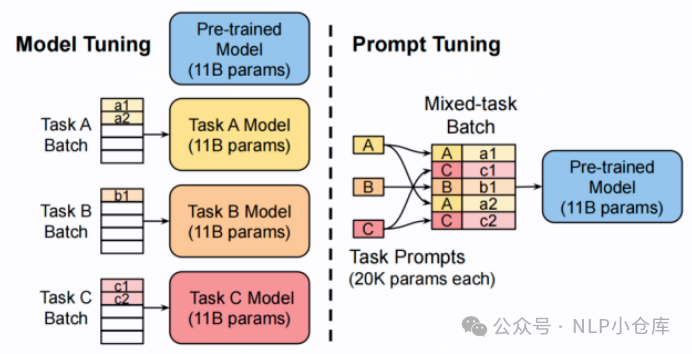
prompt tuning可以分为hard prompt和soft prompt。其中hard prompt是指将一段文本描述加在原始文本前面;soft prompt则是将指定维度的向量拼接在输入embedding上,在模型训练时仅训练prompt部分的参数,原始模型参数保持不变
(2)prefix tuning
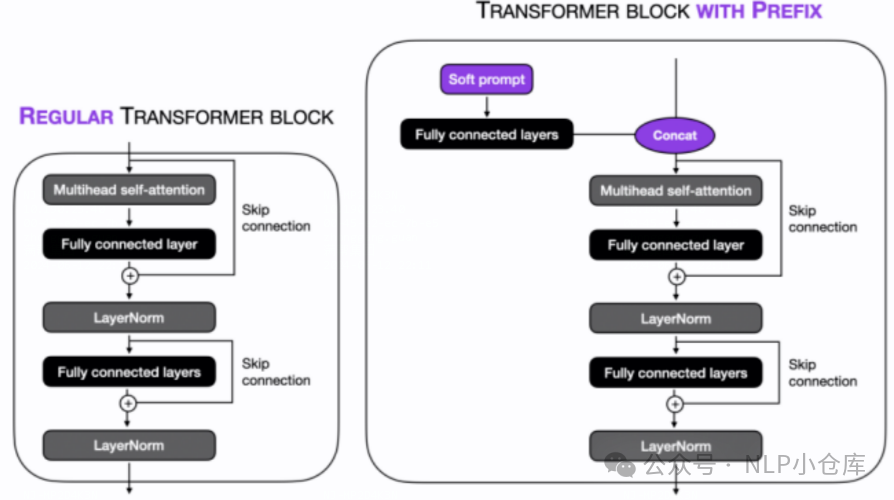
与prompt tuning的soft prompt类似,不过在prompt tuning中,将可训练向量添加到输入embedding,而prefix则是将可训练向量添加到所有的transformer层,与K/V拼接
(3)adpter
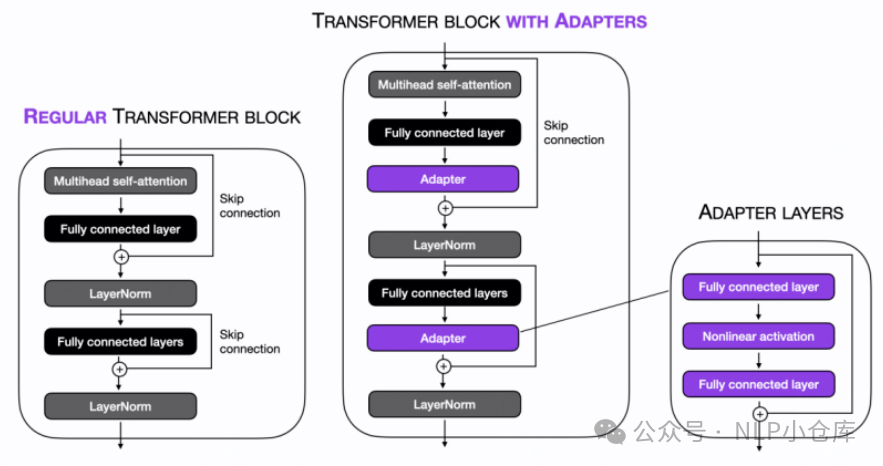 在每个transformer层中加入了两个adapter,adapter以多层MLP实现,在训练时可以仅训练adapter的参数
在每个transformer层中加入了两个adapter,adapter以多层MLP实现,在训练时可以仅训练adapter的参数
(4)lora
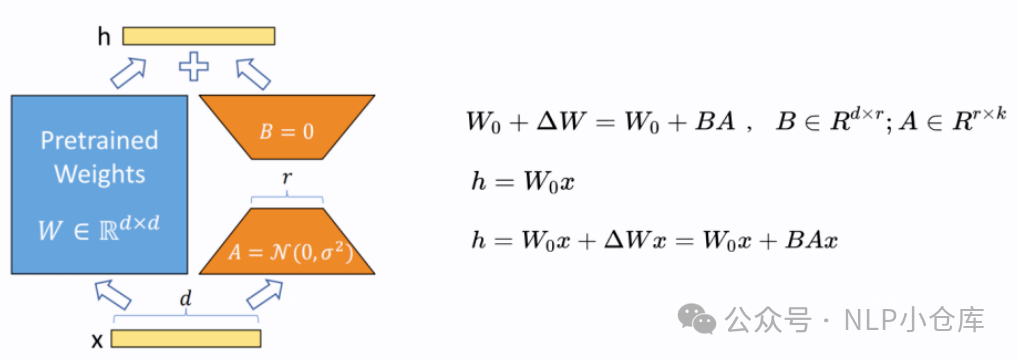 lora就是在原始网络层上增加一个旁路,在模型训练时仅对旁路的参数进行训练。值得一提的是,这个旁路由AB两个矩阵组成,其中A矩阵使用随机初始化,B矩阵使用0初始化,这样可以保证在初始化状态下,未引入其他信息。同时,AB的初始化方式也可以互换。目前,针对lora也有很多改进,如qlora、lora+等,感兴趣的可以了解一下。
lora就是在原始网络层上增加一个旁路,在模型训练时仅对旁路的参数进行训练。值得一提的是,这个旁路由AB两个矩阵组成,其中A矩阵使用随机初始化,B矩阵使用0初始化,这样可以保证在初始化状态下,未引入其他信息。同时,AB的初始化方式也可以互换。目前,针对lora也有很多改进,如qlora、lora+等,感兴趣的可以了解一下。
2.2 RAG
RAG概括起来就是结合外部知识库,来完善输入文本,主要可以解决大模型的幻觉问题,从而提升大模型在某个垂直领域的能力。目前,大模型的落地大多数都是SFT+RAG的模式。
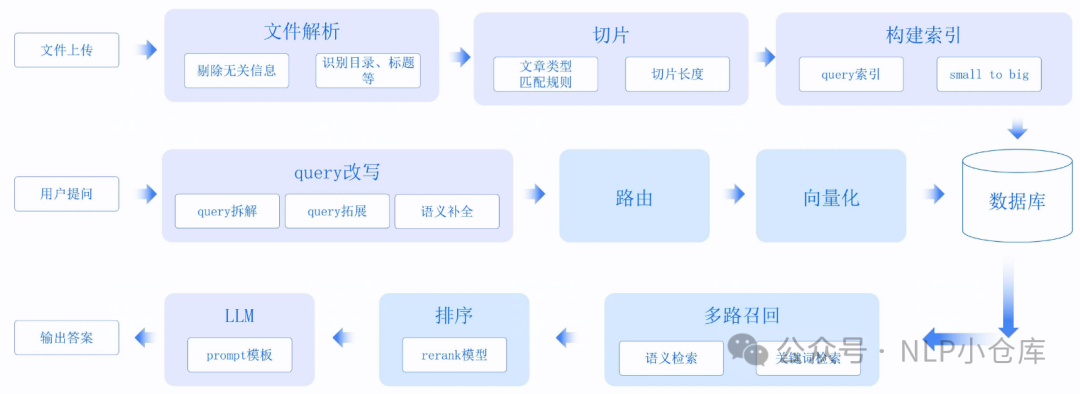
下面是货拉拉大模型对RAG技术的使用,可以看到其分两路召回,一路是向量,一路是货名,然后对召回的文本块进行排序,选择top10作为外部信息放入prompt,再输入大模型。
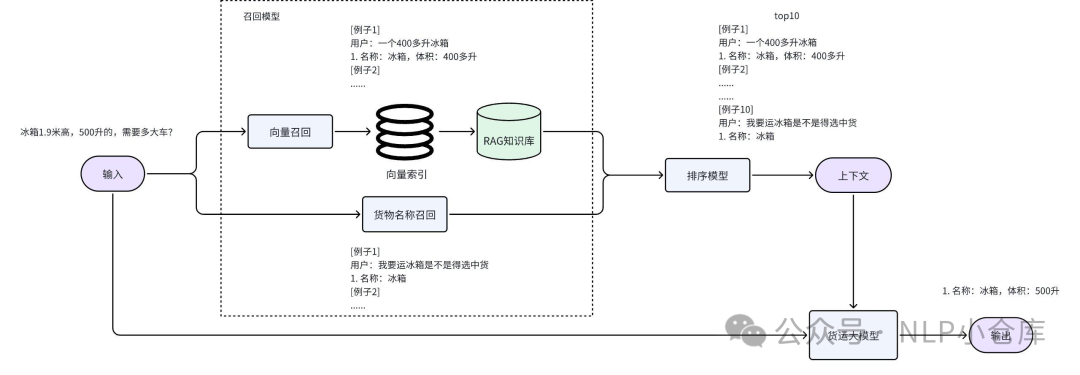
针对RAG技术,其可做的点有很多,主要可以分为数据侧、召回侧、模型侧。其中数据侧就是指外部数据的处理,包括文档的解析、切分以及编码方式;召回侧就是对外部文本块的召回方式,如果有排序模型的话,这部分可做的事更多;模型侧主要就是prompt和模型的训练,比如召回的文本块以怎样的方式加入到prompt
2.3 agent
agent一般指将大模型与工具结合,来实现复杂任务。其核心概念是利用语言模型来选择一系列要执行的动作,与传统的硬编码动作链不同,agent使用语言模型作为推理引擎来确定要执行哪些动作以及它们的执行顺序。
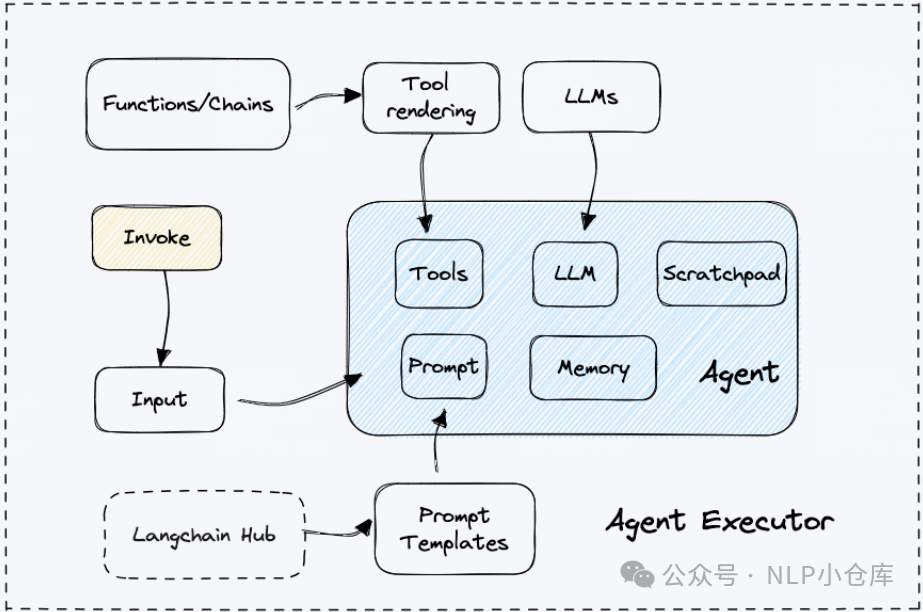
agents有以下几个组成部分:
-
模式:一组规则和结构,定义了如何与外部工具进行交互,执行动作以及管理任务状态,从而实现智能的多步骤推理和决策
-
代理:负责决策下一个动作的实体。代理使用语言模型、提示和输出解析器来支持其决策过程
-
代理执行器:负责运行代理并管理其与外部工具的交互
-
工具:代理可以调用的函数或者服务
-
工具包:工具的集合,用于完成特定任务
下面是货拉拉大模型的实践,可以看到其对agent的使用分为了NLG agent和NLU agent,其中,NLG agent负责问题的回答、工具的调用和流程引导;NLU agent负责对货物信息的提取。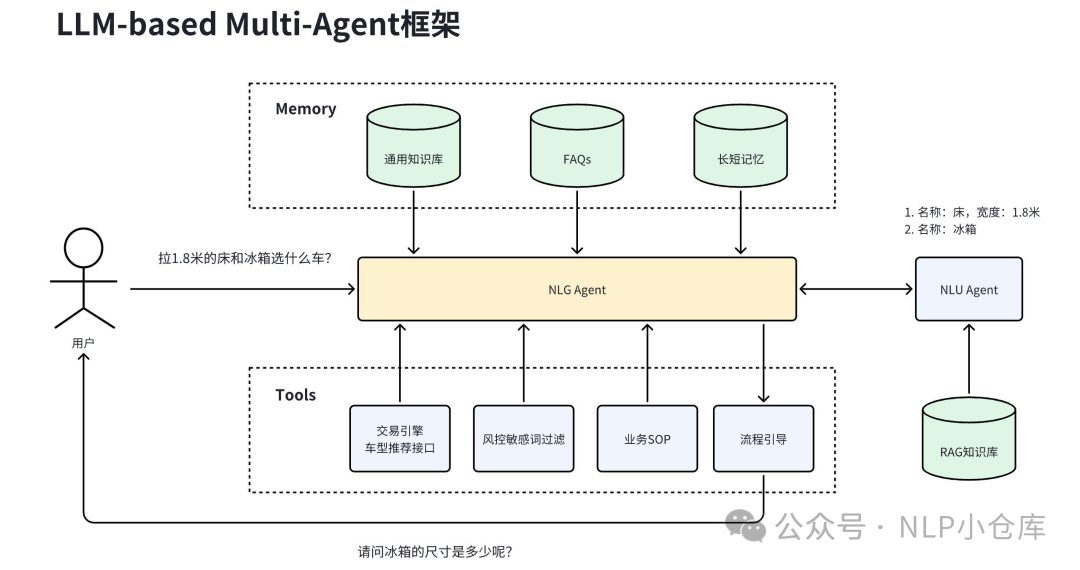
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











