







一.概述
1.概念:
"基于密度的聚类"(Density-based Clustering)认为:在整个样本空间中,各目标簇均由一群稠密的样本点组成,而这些稠密样本点被低密度
区域(即噪声)分割从而形成不同的簇;而算法的目的就是要过滤低密度区域并发现稠密样本点.具体来说,如果算法发现某个区域的密度超过了某个
阈值,就将该区域合并到相邻的簇中
2.优缺点
(1)优点:
①可发现任意形状的簇
②对噪声和初始值不敏感
③以数据集在空间中的稠密度为依据进行聚类,无需预先指定簇的数量,因此特别适合对未知数据集进行聚类
④聚类结果通常不依赖于遍历顺序
(2)缺点:
①时间复杂度较大,需建立空间索引来降低计算量
②结果受阈值影响较大,阈值过大容易分割同一聚类,阈值过小则容易合并不同聚类
③固定阈值对稀疏程度不同的数据不具有适应性,容易导致密度小的区域的同一聚类被分割,而密度大的区域的不同聚类被合并
④调参过程较复杂,密度阈值难以确定
⑤对高维数据,容易发生维度灾难
⑥不适用于整体密度基本相同的情况
二.常见算法
1.DBSCAN
(1)概述:
"具有噪声的基于密度的空间聚类"(Density-Based Spatial Clustering of Application with Noise;DBSCAN)将簇定义为高密度数
据点构成的最大集合.其核心思想是先发现数据点密度较高的区域,然后把相近的高密度区域全部连接到一起,从而生成各个簇
(2)一些概念:
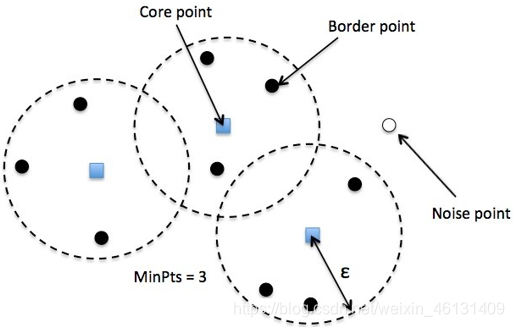
①"ε-邻域"(ε-Neighbourhood):以指定样本x为中心,ε为半径而形成的区域,记为N(ε;x)
在DBSCAN算法中,数据点被分为3类:
①"核心点"(Core Point):对指定正整数m,如果指定样本的ε-邻域中包含的样本数不少于m,就称其为核心点
②"边界点"(Border Point):对指定正整数m,如果指定样本的ε-邻域中包含的样本数少于m,但其包含在某核心点的ε邻域内,就称其为边界点
③"噪声点"(Noise):除核心点和边界点外的其他样本(不包含在任何簇中的样本)
在DBSCAN算法中,还定义了如下一些概念:
①"直接密度可达"(Directly Density-Reachable):如果满足p∈N(ε;q)∧|N(ε;q)|≥mp,则称样本p从样本q对参数{
ε,mp}直接密度可达(即
p属于核心点q的ε-邻域)
②"密度可达"(Density-Reachable):如果存在样本p1=q,p2...pn=p,使得p(i+1)从pi对参数{
ε,mp}直接密度可达(1≤i≤n−1),则称p从q对
参数{
ε,mp}密度可达
③"密度相连"(Density-Connected):如果存在样本o,p,q,使得p,q均从o对参数{
ε,mp}密度可达,则称p,q对参数{
ε,mp}是密度相连的
最后定义簇:
①"簇"(Cluster):最大的又密度连接的样本构成的集合
(3)步骤:
①如果样本x的ε-邻域这包含至少m个样本,则创建1个以x作为核心点的新簇
②将 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 153
153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









