









基于vllm和xinference本地化部署GraphRAG
文章目录
前言
介绍:vllm部署qwen2.5-32b-instruct,xinference部署bge-m3模型,
室验环境:A100-80G、graphrag==2.1.0版本
参考链接:
官方教程: https://microsoft.github.io/graphrag/get_started/
graphrag核心还是采用指令工程的方式抽取文本分块文章的实体和关系,根据社区监测算法进行聚类,然后生成节点、社区对应的文本描述,官方的工程中进行文本向量化的也就是这些描述,有两种查询的方式local和global。
- 优点:能够根据上下文形成对应的知识图谱,回答一些全局性的问题。
- 缺点:构建时间和成本比较高,需要根据业务流设计对应的指令工程,同时修改对应的代码,难度比较高。
一、实验记录
1.1 环境配置
官方提供三种安装方式,
- Use the GraphRAG Accelerator solution
- install from pypi
- use it from source
第一种方式是基于Azure的accelerator的内容进行graphrag的构建,并提供加速的服务,适合生产环境的部署;
第二种方式是通过pip直接安装,那么下载的源码直接在site-packages对应的目录上,适合简单尝试的小伙伴们;
🌠🌠🌠第三种方式是通过当前工程的源码进行安装,本项目采用第三种方式进行安装,目的是便于内容的学习。🌠🌠🌠
安装conda环境
conda create -n graphrag python=3.11.8
conda activate graphrag
安装poetry包
pip install poetry
下载源码
git clone https://github.com/microsoft/graphrag.git
进入源码中
cd graphrag
创建工作目录
mkdir -p ./ragtest/input
curl https://www.gutenberg.org/cache/epub/24022/pg24022.txt -o ./ragtest/input/book.txt
🚫需要注意,如果使用自己的文档,并且模型分析的输出的内容,则需要修改以下内容:
文件的内容,当前是下载的 查尔斯·狄更斯《圣诞颂歌》的英文版,后期可以切换为自己的中文数据,
如果是中文数据集,可以采用开源的中文大模型QWEN系列或者Deepseek系列的模型
同时,在graphrag init --root ./rag_自己的数据目录 会生成对应的指令,将extract_claims.txt 和 extract_graph.txt 中的English切换为Chinese
接下来初始化文件夹,并进行环境和模型的配置
graphrag init --root ./ragtest
在ragtest目录下会生成对应的.env和setting.yaml文件, 如下图所示:
.env文件用于配置llm的api的密钥,如果大家选择的模型是线上的api接口则,可以设置自己的llm密钥;如果使用的是本地化部署的大模型则无需填写;
setting.yaml文件则配置咱们的本地化服务的URL和端口,内容如下:
models:
default_chat_model:
type: openai_chat # or azure_openai_chat
api_base: http://172.17.136.62:10081/v1
# api_version: 2024-05-01-preview
auth_type: api_key # or azure_managed_identity
api_key: ${GRAPHRAG_API_KEY} # set this in the generated .env file
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
model: qwen2.5_32b_instruct
# deployment_name: <azure_model_deployment_name>
# encoding_model: cl100k_base # automatically set by tiktoken if left undefined
model_supports_json: false # recommended if this is available for your model.
concurrent_requests: 25 # max number of simultaneous LLM requests allowed
async_mode: threaded # or asyncio
retry_strategy: native
max_retries: -1 # set to -1 for dynamic retry logic (most optimal setting based on server response)
tokens_per_minute: 0 # set to 0 to disable rate limiting
requests_per_minute: 0 # set to 0 to disable rate limiting
default_embedding_model:
type: openai_embedding # or azure_openai_embedding
api_base: http://172.17.136.62:9997/v1
# api_version: 2024-05-01-preview
auth_type: api_key # or azure_managed_identity
api_key: ${GRAPHRAG_API_KEY}
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
model: custom-bge-m3
# deployment_name: <azure_model_deployment_name>
# encoding_model: cl100k_base # automatically set by tiktoken if left undefined
model_supports_json: true # recommended if this is available for your model.
concurrent_requests: 25 # max number of simultaneous LLM requests allowed
async_mode: threaded # or asyncio
retry_strategy: native
max_retries: -1 # set to -1 for dynamic retry logic (most optimal setting based on server response)
tokens_per_minute: 0 # set to 0 to disable rate limiting
requests_per_minute: 0 # set to 0 to disable rate limiting
其中比较关键的参数如下:
default_chat_model: 配置模型的参数
type:模型的类型,当前可选的有openai_chat和azure_openai_chat,默认选择前者,遵循默认的openai llm的服务类型
api_base:当前服务的URL地址,http://172.17.136.62:10081/v1 这里这个是本地vllm服务启动的URL地址,可根据自己的服务的URL进行自定义的配置
model:模型名字,qwen2.5_32b_instruct
model_supports_json:是否支持json格式,openai的服务是支持json的,本地化模型不能保证完全的json,那么就设置为false
default_embedding_model:配置embedding的参数
api_base:http://172.17.136.62:9997/v1 这个是xinference部署模型的地址
model: custom-bge-m3 模型的名字
1.2 启动vllm后端的服务
安装vllm环境,网上很多安装教程
(transformers) root@acc30e810e3b:/workspace/gf# pip show vllm
Name: vllm
Version: 0.6.6.post1
Summary: A high-throughput and memory-efficient inference and serving engine for LLMs
Home-page: https://github.com/vllm-project/vllm
Author: vLLM Team
Author-email:
License: Apache 2.0
Location: /root/miniconda3/envs/transformers/lib/python3.12/site-packages
Requires: aiohttp, blake3, cloudpickle, compressed-tensors, depyf, einops, fastapi, filelock, gguf, importlib_metadata, lark, lm-format-enforcer, mistral_common, msgspec, numpy, nvidia-ml-py, openai, outlines, partial-json-parser, pillow, prometheus-fastapi-instrumentator, prometheus_client, protobuf, psutil, py-cpuinfo, pydantic, pyyaml, pyzmq, ray, requests, sentencepiece, setuptools, six, tiktoken, tokenizers, torch, torchvision, tqdm, transformers, typing_extensions, uvicorn, xformers, xgrammar
Required-by:
运行命令,启动vllm服务
python -m vllm.entrypoints.openai.api_server \
--model /workspace/pretrain_model/models--Qwen--Qwen2.5-32B-Instruct \
--served-model-name qwen2.5_32b_instruct \
--gpu-memory-utilization 0.85 \
--port 1891 \
--max-model-len 12000
由于本机实现环境为A100-80G,qwen2.5-32b-instruct如果使用原生pytorch框架启动,占用61G显存,即占用61/80≈76.25%,那么GPU的利用率应该设置超过这个数值,vllm核心功能是启动了KV Cache和continue batch,这两个参数相对比较影响显存的占用。
gpu-memory-utilization:根据自己的显卡的情况设置当前的数值max-model-len:模型的上下文长度,注意不要和上下文窗口长度混淆,这里的长度包含提示长度和生成长度。
模型启动后,显卡占用情况如下:
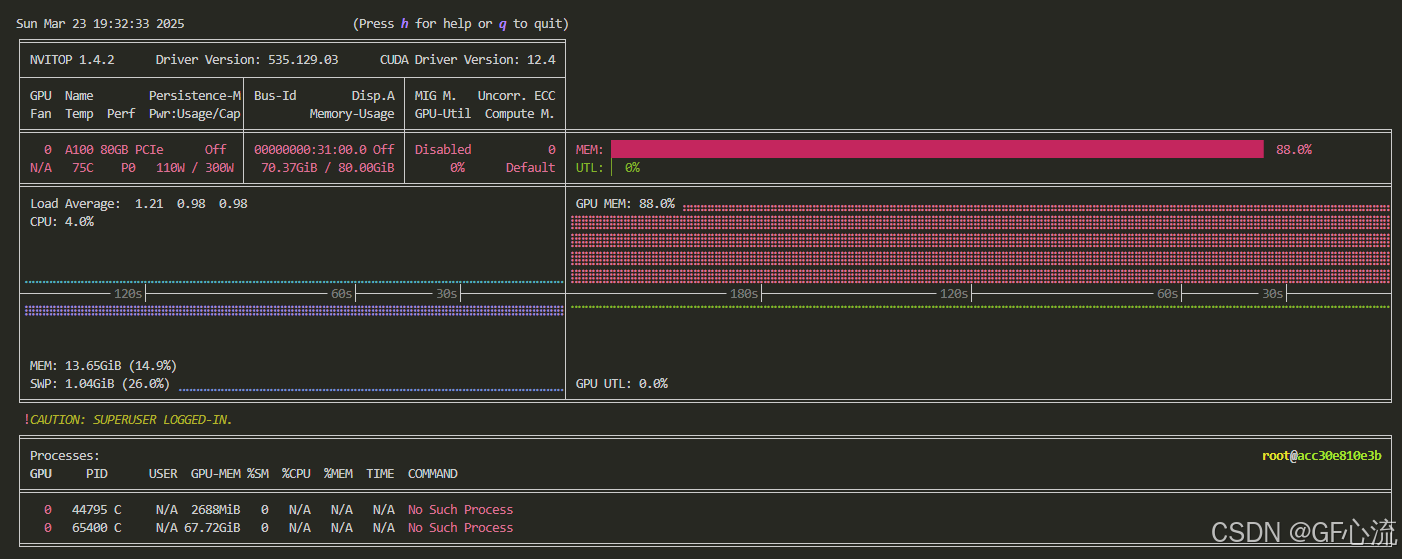
67G是vllm占用的显存,61G是模型本身的占用,那么剩余的6G应该是vllm申请到的内容给kv cache和CB等工程实现的空间。
1.3 xinference启动bge-m3模型
安装部署xinference教程,自行搜索安装。
填写好对应的模型路径和参数,即可。
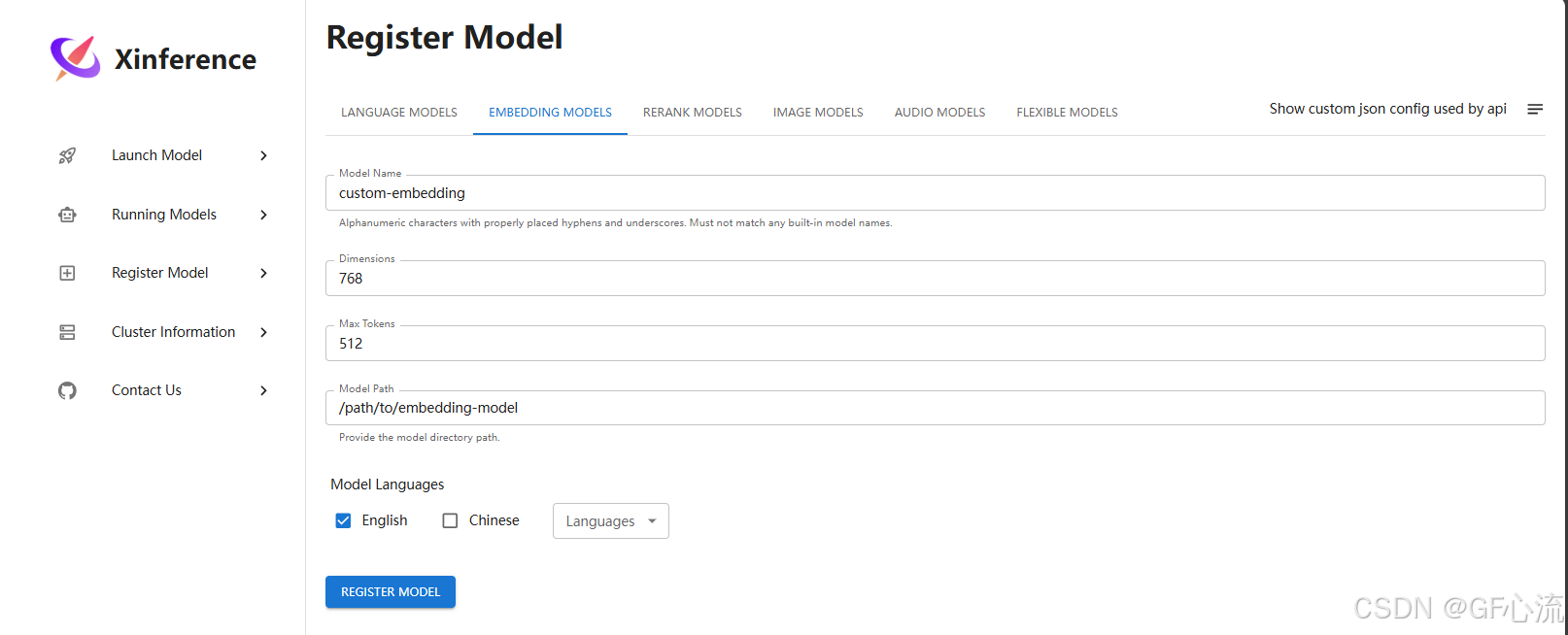
点击启动:
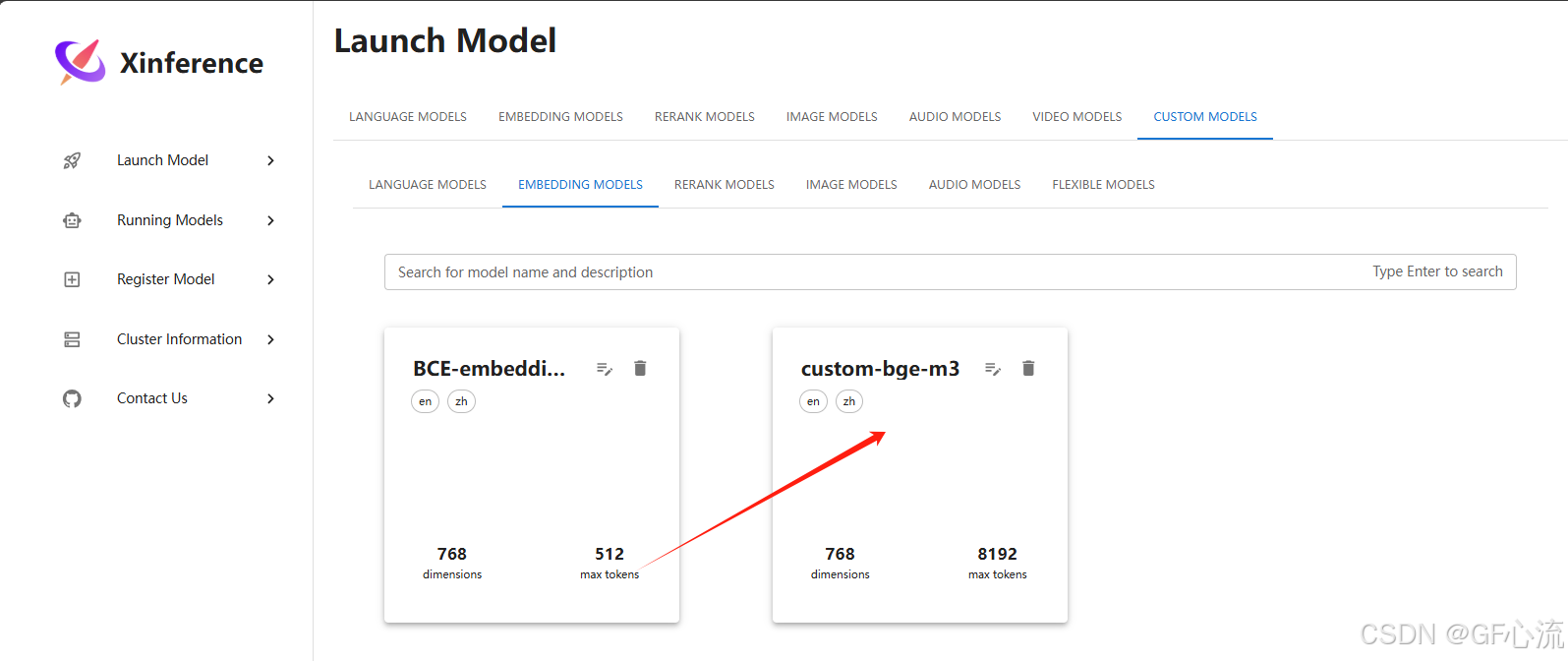
1.4 实验内容
构建索引流程
graphrag index --root ./ragtest
⠇ GraphRAG Indexer
├── Loading Input (InputFileType.text) - 1 files loaded (0 filtered) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── create_base_text_units ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── create_final_documents ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── extract_graph ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── finalize_graph ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── create_communities ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── create_final_text_units ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── create_community_reports ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── generate_text_embeddings ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 0:00:00
🚀 All workflows completed successfully.
create_base_text_units: 文档进行分块,1200tokens为一块,overlap为100, 该参数在setting.yaml中设定
create_final_documents: 主要是记录时间戳
extract_graph:抽取文章中的实体和边
finalize_graph:合并实体和修正边
create_communities: 社区监测
create_final_text_units: 创建最终文本单元
create_community_reports:创建最终社区报告
generate_text_embeddings:创建最终文档
模型根据graphrag的构建流程,文档读取、切块、实体和关系抽取、社区监测、社区报告生成、文档嵌入和表格生成进行内容的构建,最终在ragtest目录下生成output对应的内容
文件目录如下:
(graphrag) D:\AI\NLP\graphrag-main>tree ragtest/output /f /a
文件夹 PATH 列表
卷序列号为 D0D2-CF3B
D:\AI\NLP\GRAPHRAG-MAIN\RAGTEST\OUTPUT
| communities.parquet
| community_reports.parquet
| context.json
| documents.parquet
| entities.parquet
| relationships.parquet
| stats.json
| text_units.parquet
|
\---lancedb 模型缓存
其中parquet是模型各个阶段输出的内容,你可以理解为CSV的文件,只是parquet的文件格式比csv功能更强大和高效。
问题查询,graph提供两种查询模式global和local。
global查询模式
(graphrag) D:\AI\NLP\graphrag-main>graphrag query --root ./ragtest --method global --query "第一个幽灵代表什么?"
SUCCESS: Global Search Response:
第一个幽灵是雅各布·马利的鬼魂,他来警告斯克鲁奇改变他的生活方式。[Data: Reports (0, 2)]
雅各布·马利的鬼魂是斯克鲁奇旅程中的关键元素,象征着过去行为的后果和赎罪的重要性。[Data: Reports (2, 5)]
马利的鬼魂出现在斯克鲁奇的房间,这个房间是故事中的一个中心地点,标志着斯克鲁奇生活中的一个转折点。[Data: Reports (2)]
### 雅各布·马利的鬼魂的意义
雅各布·马利的鬼魂是斯克鲁奇旅程中的一个重要组成部分,他来警告斯克鲁奇改变他的生活方式。这个幽灵的出现象征着过去行为的后果,以及赎罪的重要性。通过马利的鬼魂,斯克鲁奇被提醒到他过去的错误和行为对他人造成的影响,这促使他反思自己的生活方式。
### 马利的鬼魂的出现地点
马利的鬼魂出现在斯克鲁奇的房间,这个房间是故事中的一个中心地点。这个场景标志着斯克鲁奇生活中的一个转折点,预示着他的生活即将发生重大变化。通过这个幽灵的出现,斯克鲁奇开始意识到他需要做出改变,以避免像马利一样 在死后继续承受痛苦。
(graphrag) D:\AI\NLP\graphrag-main>graphrag query --root ./ragtest --method global --query "一共出现多少个幽灵?"
SUCCESS: Global Search Response:
在这些报告中,提到了三个幽灵:雅各布·马利的鬼魂、圣诞往事之灵和圣诞现在之灵 [Data: Reports (1, 2, 5, 6, +more)]。这些幽灵在不同的记录中被提及,每个幽灵都扮演着不同的角色,为故事的发展提供了丰富的背景和情节。雅各布·马利的鬼魂是已故的雅各布·马利的幽灵,他曾经是主角埃比尼泽·斯克鲁奇的商业伙伴;圣诞往事之灵则带领斯克鲁奇回顾过去的圣诞节,让他反思自己的行为;圣诞现在之灵则展示了当前世界中人们庆祝圣诞节的场景,让斯克鲁奇看到他周围人的生活状态。
(graphrag) D:\AI\NLP\graphrag-main>graphrag query --root ./ragtest --method global --query "梳理下主角和其他人的关系"
SUCCESS: Global Search Response:
### 主角与其他人的关系
**Ebenezer Scrooge** 是社区的核心人物,也是计数屋的主人,他在故事中经历了深刻的转变。他的转变主要受到几个关键实体的影响,包括圣诞过去之灵和马利的鬼魂。[Data: Reports (1, 5)]
#### 马利的鬼魂
马利的鬼魂是雅各布·马利的幽灵,它访问斯克鲁奇,提醒他要改变自己的生活方式。马利的鬼魂对于斯克鲁奇的转变至关重要,它通过警告和启示促使斯克鲁奇反思自己的行为。[Data: Reports (2, 5)]
#### 圣诞过去之灵
圣诞过去之灵引导斯克鲁奇回顾他的过去,帮助他反思自己的生活和选择。通过这一过程,斯克鲁奇得以重新审视自己的人生,从而走向转变。[Data: Reports (1, 5)]
#### 市场镇的情感联系
斯克鲁奇与市场镇有着强烈的情感联系,他能认出市场镇的地标,如桥、教堂和蜿蜒的河流,这些都来自他的童年。这种联系对于斯克鲁奇反思过去和选择的重要性至关重要,帮助他理解自己的过去和未来。[Data: Reports (1, 5)]
#### 鲍勃·克拉奇特
鲍勃·克拉奇特是斯克鲁奇的职员,是社区中的中心人物,以其节日精神和庆祝圣诞夜而闻名。尽管报告中没有详细描述斯克鲁奇与克拉奇特之间的直接互动,但克拉奇特的存在和精神可能对斯克鲁奇的转变产生了间接影响。[Data: Reports (0)]
### 总结
斯克鲁奇的转变是一个多方面的影响过程,其中马利的鬼魂和圣诞过去之灵起到了关键作用。斯克鲁奇与市场镇的情感联系也帮助他反思自己的过去,而鲍勃·克拉奇特的存在则为社区增添了节日的氛围,可能间接影响了斯克鲁奇的转变。[Data: Reports (1, 2, 5)]
local方式:
(graphrag) D:\AI\NLP\graphrag-main>graphrag query --root ./ragtest --method local --query "斯克鲁奇在发生奇遇前,如何对待别人?"
INFO: Vector Store Args: {
"default_vector_store": {
"type": "lancedb",
"db_uri": "D:\\AI\\NLP\\graphrag-main\\ragtest\\output\\lancedb",
"url": null,
"audience": null,
"container_name": "==== REDACTED ====",
"database_name": null,
"overwrite": true
}
}
SUCCESS: Local Search Response:
在斯克鲁奇经历超自然奇遇之前,他以吝啬和刻薄著称,对待他人非常苛刻。斯克鲁奇是记账室的主人,他对待自己的职员鲍勃·克雷奇特非常严厉,甚至在办公室因圣诞节而关闭时,也只支付给克雷奇特一天的工资 [Data: Entities (11, 12); Relationships (9, 10, 12, 13, 18, 19, 32, 33, 34, 35, 36, 42)]. 他独自一人在忧郁的酒馆用餐,表现出孤独和与世隔绝的态度 [Data: Entities (17); Relationships (12)]. 他的行为和态度表明,斯克鲁奇在奇遇发生前是一个冷漠且自私的人,对周围的人缺乏同情心。
然而,斯克鲁奇的这种态度在圣诞节前夕开始发生变化。在那天晚上,他先是遇到了已故商业伙伴马利的鬼魂,随后又遇到了圣诞过去之灵,这些超自然的遭遇开始引导他反思自己的生活和所作所为 [Data: Entities (11, 16, 26); Relationships (21, 29, 30, 32, 37, 38, 44)]. 马利的鬼魂和圣诞过去之灵的出现,标志着斯克鲁奇人生转变的开始,他们通过展示斯克鲁奇过去的场景,帮助他认识到自己的错误,并引导他走向改变。
回答的效果还是可以的
二、输出内容分析
import pandas as pd
documents = pd.read_parquet('./output/documents.parquet')

chunks = pd.read_parquet('./output/text_units.parquet')
chunks.head()

entities = pd.read_parquet('./output/entities.parquet')

relations = pd.read_parquet('./output/relationships.parquet')

community = pd.read_parquet('./output/communities.parquet')
community_report = pd.read_parquet('./output/community_reports.parquet')
三、分析指令工程
basic_search_system_prompt.txt 就是默认RAG的指令工程
# 角色
你是 helpful assistant,负责回答用户关于所提供表格中数据的问题。
# 目标
根据用户问题,生成符合目标长度和格式的回答,总结输入数据表格中适合回答的信息,同时结合相关常识。如果不知道答案,直接说明,不要编造。
被数据支持的要点,要按以下格式列出数据参考:
“这是一个受多个文本参考支持的示例句子 [数据:来源(记录 id)]。”
单个参考中列出的记录 id 不超过 5 个,超过 5 个时,列出最相关的 5 个并添加 “+more” 表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:来源(15,16)]。”
其中 15 和 16 是相关数据记录的 id(非索引)。
不要包含支持文本未提供的信息。
# 目标回答长度和格式
{response_type}
添加适合回答长度和格式的章节与评论。以 markdown 格式回答。
# 数据表格
{context_data}
# 目标
根据用户问题,生成符合目标长度和格式的回答,总结输入数据表格中适合回答的信息,同时结合相关常识。如果不知道答案,直接说明,不要编造。
被数据支持的要点,要按以下格式列出数据参考:
“这是一个受多个文本参考支持的示例句子 [数据:来源(记录 id)]。”
单个参考中列出的记录 id 不超过 5 个,超过 5 个时,列出最相关的 5 个并添加 “+more” 表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:来源(15,16)]。”
其中 15 和 16 是相关数据记录的 id(非索引)。
不要包含支持文本未提供的信息。
community_report_graph.txt 生成社区报告的指令工程
# 角色
你是一个 AI 助手,帮助人类分析师进行一般信息发现。信息发现是识别和评估网络中与某些实体(例如组织和个人)相关的信息的过程。
# 目标
根据属于社区的实体列表及其关系和可选的关联声明,撰写一份全面的社区报告。该报告将用于告知决策者与社区及其潜在影响相关的信息。报告内容包括社区关键实体的概述、其法律合规性、技术能力、声誉以及值得注意的声明。
# 报告结构
报告应包括以下部分:
- 标题:代表社区关键实体的社区名称 - 标题应简洁但具体。如果可能,标题中应包含具有代表性的命名实体。
- 摘要:社区整体结构、实体之间关系以及与实体相关的重要信息的执行摘要。
- 影响严重性评分:0-10 之间的浮点数,表示社区内实体所构成的影响的严重性。影响是社区的重要性评分。
- 评分解释:对影响严重性评分进行单句解释。
- 详细发现:5-10 个关于社区的关键见解列表。每个见解应有一个简短总结,随后是多段解释性文本,并根据以下接地规则进行说明。要全面。
以格式良好的 JSON 格式字符串形式返回输出:
{{
"title": <报告标题>,
"summary": <执行摘要>,
"rating": <影响严重性评分>,
"rating_explanation": <评分解释>,
"findings": [
{{
"summary":<见解 1 摘要>,
"explanation": <见解 1 解释>
}},
{{
"summary":<见解 2 摘要>,
"explanation": <见解 2 解释>
}}
]
}}
# 接地规则
被数据支持的要点,应按以下格式列出数据参考:
“这是一个受多个数据参考支持的示例句子 [数据:<数据集名称>(记录 id);<数据集名称>(记录 id)].”
在单个参考中不要列出超过 5 个记录 id。相反,列出最相关的 5 个记录 id 并添加 “+more” 以表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:Reports (1), Entities (5, 7); Relationships (23); Claims (7, 2, 34, 64, 46, +more)].”
其中 1、5、7、23、2、34、46 和 64 是相关数据记录的 id(非索引)。
不要包含没有提供支持证据的信息。
# 示例输入
-----------
文本:
实体
id,实体,描述
5,VERDANT OASIS PLAZA,Verdant Oasis Plaza 是 Unity March 的地点
6,HARMONY ASSEMBLY,HARMONY ASSEMBLY 是一个正在 Verda nt Oasis Plaza 举办游行的组织
关系
id,来源,目标,描述
37,VERDANT OASIS PLAZA,UNITY MARCH,Verdant Oasis Plaza 是 Unity March 的地点
38,VERDANT OASIS PLAZA,HARMONY ASSEMBLY,HARMONY ASSEMBLY 正在 Verda nt Oasis Plaza 举办游行
39,VERDANT OASIS PLAZA,UNITY MARCH,Unity March 正在 Verda nt Oasis Plaza 举行
40,VERDANT OASIS PLAZA,TRIBUNE SPOTLIGHT,TRIBUNE SPOTLIGHT 正在报道在 Verda nt Oasis Plaza 举行的 Unity March
41,VERDANT OASIS PLAZA,BAILEY ASADI,Bailey Asadi 正在 Verda nt Oasis Plaza 发表演讲,谈论游行
43,HARMONY ASSEMBLY,UNITY MARCH,HARMONY ASSEMBLY 正在组织 Unity March
输出:
{{
"title": "Verdant Oasis Plaza 和 Unity March",
"summary": "该社区以 Verdant Oasis Plaza 为中心,这里是 Unity March 的举办地。该广场与 Harmony Assembly、Unity March 和 Tribune Spotlight 都有关联,所有这些都与游行活动有关。",
"rating": 5.0,
"rating_explanation": "影响严重性评分为中等,因为 Unity March 期间可能会出现动荡或冲突。",
"findings": [
{{
"summary": "Verdant Oasis Plaza 作为中心位置",
"explanation": "Verdant Oasis Plaza 是这个社区的中心实体,作为 Unity March 的举办地。这个广场是所有其他实体之间的共同联系点,这表明它在社区中的重要性。广场与游行的关联可能会导致诸如公共秩序混乱或冲突等问题,这取决于游行的性质以及它所引发的反应。[数据:Entities (5), Relationships (37, 38, 39, 40, 41,+more)]"
}},
{{
"summary": "Harmony Assembly 在社区中的作用",
"explanation": "Harmony Assembly 是这个社区中的另一个关键实体,是 Verda nt Oasis Plaza 游行的组织者。Harmony Assembly 的性质及其游行可能是潜在威胁的来源,这取决于他们的目标以及他们所引发的反应。Harmony Assembly 与广场之间的关系对于理解这个社区的动态至关重要。[数据:Entities(6), Relationships (38, 43)]"
}},
{{
"summary": "Unity March 作为重要事件",
"explanation": "Unity March 是在 Verda nt Oasis Plaza 举行的重要事件。这一事件是社区动态的关键因素,可能会成为威胁的来源,这取决于游行的性质以及它所引发的反应。游行与广场之间的关系对于理解这个社区的动态至关重要。[数据:Relationships (39)]"
}},
{{
"summary": "TRIBUNE SPOTLIGHT 的作用",
"explanation": "TRIBUNE SPOTLIGHT 正在报道在 Verda nt Oasis Plaza 举行的 Unity March。这表明该事件引起了媒体关注,这可能会放大其对社区的影响。TRIBUNE SPOTLIGHT 的作用可能对于塑造公众对该事件及涉及实体的看法具有重要意义。[数据:Relationships (40)]"
}}
]
}}
# 真实数据
使用以下文本作为回答。不要在回答中编造任何内容。
文本:
{input_text}
报告应包括以下部分:
- 标题:代表社区关键实体的社区名称 - 标题应简洁但具体。如果可能,标题中应包含具有代表性的命名实体。
- 摘要:社区整体结构、实体之间关系以及与实体相关的重要信息的执行摘要。
- 影响严重性评分:0-10 之间的浮点数,表示社区内实体所构成的影响的严重性。影响是社区的重要性评分。
- 评分解释:对影响严重性评分进行单句解释。
- 详细发现:5-10 个关于社区的关键见解列表。每个见解应有一个简短总结,随后是多段解释性文本,并根据以下接地规则进行说明。要全面。
以格式良好的 JSON 格式字符串形式返回输出:
{{
"title": <报告标题>,
"summary": <执行摘要>,
"rating": <影响严重性评分>,
"rating_explanation": <评分解释>,
"findings": [
{{
"summary":<见解 1 摘要>,
"explanation": <见解 1 解释>
}},
{{
"summary":<见解 2 摘要>,
"explanation": <见解 2 解释>
}}
]
}}
# 接地规则
被数据支持的要点,应按以下格式列出数据参考:
“这是一个受多个数据参考支持的示例句子 [数据:<数据集名称>(记录 id);<数据集名称>(记录 id)].”
在单个参考中不要列出超过 5 个记录 id。相反,列出最相关的 5 个记录 id 并添加 “+more” 以表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:Reports (1), Entities (5, 7); Relationships (23); Claims (7, 2, 34, 64, 46, +more)].”
其中 1、5、7、23、2、34、46 和 64 是相关数据记录的 id(非索引)。
不要包含没有提供支持证据的信息。
输出:
community_report_text.txt
# 角色
你是一个 AI 助手,帮助人类分析师进行一般信息发现。信息发现是识别和评估网络中与某些实体(例如组织和个人)相关的信息的过程。
# 目标
根据属于社区的实体列表及其关系和可选的关联声明,撰写一份全面的社区报告。该报告将用于告知决策者与社区及其潜在影响相关的信息。报告内容包括社区关键实体的概述、其核心属性或能力、它们之间的联系以及值得注意的声明。尽可能保留时间特定信息,以便用户可以构建事件时间线。
# 报告结构
报告应包括以下部分:
- 标题:代表社区关键实体的社区名称 - 标题应简洁但具体。如果可能,标题中应包含具有代表性的命名实体。避免在标题中包含诸如“资格评估”或“资格评估报告”之类的短语。
- 摘要:社区整体结构、实体之间关系以及与实体相关的重大计划特定或资格相关见解的执行摘要。
- 重要性评分:0-10 之间的浮点数,表示社区内实体的重要性。
- 评分解释:对重要性评分进行单句解释。
- 详细发现:5-10 个关于社区的关键见解列表。每个见解应有一个简短总结,随后是多段解释性文本,并根据以下接地规则进行说明。要全面。
- 日期范围:文本单元和中间报告用于构建报告的日期范围(格式为 YYYY-MM-DD),格式为 [START, END]。
以格式良好的 JSON 格式字符串形式返回输出。不要使用任何不必要的转义序列。输出应为一个可以被 json.loads 解析的单个 JSON 对象。
{{
"title": "<report_title>",
"summary": "<executive_summary>",
"rating": <importance_rating>,
"rating_explanation": "<rating_explanation>",
"findings": [{{"summary":"<insight_1_summary>", "explanation": "<insight_1_explanation"}}, {{"summary":"<insight_2_summary>", "explanation": "<insight_2_explanation"}}],
"date_range": ["<date range start>", "<date range end>"],
}}
# 接地规则
被数据支持的要点,应按以下格式列出数据参考:
“这是一个受多个数据参考支持的示例句子 [数据:<数据集名称>(记录 id), <数据集名称>(记录 id)].”
在单个参考中不要列出超过 5 个记录 id。相反,列出最相关的 5 个记录 id 并添加 “+more” 以表示还有更多。
例如:
“Person X 解决了项目 Y 的一个主要问题 [数据:Sources (1, 5), Date_Range ((2001, 05, 12), (2001, 05, 14))]. 他还对应用 Y 的数据库进行了重大更新 [数据:Reports (2, 4), Sources (7, 23, 2, 34, 46, +more), Date_Range ((2001, 05, 15), (2001, 05, 18))].”
其中 1、2、4、5、7、23、2、34 和 46 是相关数据记录的 id(非索引)。
# 示例输入
-----------
来源
id, 文本
1, 文本:发件人:compliance.office@enron.com 收件人:management.team@enron.com 抄送:legal.team@enron.com, risk@enron.com 日期:Wed, 12 Jul 2000 08:30:00 -0600 (CST) 主题:合规与风险管理的快速更新
2, 快速更新一下合规与风险管理方面的工作进展。风险管理团队从去年初开始就一直在加强工作力度,他们对我们的财务风险评估和缓解策略进行了严格把关。
3, 他们的努力对于我们在2000年中期保持财务稳定和合规至关重要。这对于我们的战略规划至关重要,有助于我们保持领先地位。
5, 法务团队一直在监督确保我们所有操作都符合法律标准。他们特别关注改善公司治理和合同管理,从2000年第二季度开始。这对于保持我们操作的顺利和合法性至关重要。
9, 自从2000年第二季度开始,风险管理和法务合规团队的协作比以往任何时候都更加紧密。他们确保我们的策略不仅有效,而且完全合规。这种协作对于我们整体治理方法至关重要。
10, 你的想法如何?这些更新对你的领域有何影响?有关于如何改进的想法吗?请告知你的部门负责人。
11, 感谢大家的积极参与。让我们继续努力,寻找更好、更聪明的工作方式。祝好,简· Doe
输出:
{{
"title": "截至2000年7月的安然合规与风险管理概览",
"summary": "本报告深入探讨了安然公司专注于合规与风险管理的关键部门,展示了这些实体如何在组织架构内互动,以有效维护监管标准和管理财务风险。这些信息与公司2000年中期左右的运营相关。",
"rating": 9.2,
"rating_explanation": "高重要性评分反映了风险管理和法务合规部门在确保安然公司遵守财务和法律法规方面的重要作用,这对于维护公司的完整性和运营稳定性至关重要。",
"findings": [
{{
"summary": "风险管理的运营范围",
"explanation": "安然公司的风险管理部在识别、评估和缓解财务风险方面发挥着关键作用。他们自2000年初以来的积极方法有助于保护安然免受潜在财务问题的困扰,并确保持续符合不断变化的市场法规。有效的风险管理不仅防止财务异常,还支持公司的战略决策过程。
[数据:Sources (2, 3), Date_Range ((2000, 01, 01), (2000, 07, 12))]"
}},
{{
"summary": "法务合规与治理",
"explanation": "法务合规部确保安然公司的所有操作符合监管机构设定的法律标准。他们从2000年第二季度开始关注公司治理和合同管理,这对于维护安然的声誉和运营合法性至关重要,特别是在管理复杂合同和公司协议方面。他们的努力强调了维护高法律标准和道德实践的承诺。
[数据:Source (5), Date_Range ((2000, 04, 01), (2000, 07, 12))]"
}},
{{
"summary": "跨部门协作以实现合规",
"explanation": "自2000年第二季度以来,风险管理和法务合规部门之间的协作确保了风险缓解策略在法律上站得住脚,并且合规措施考虑了财务风险。这种协同作用对于整体治理至关重要,并且在整合风险管理和法律合规策略方面发挥了重要作用。在此期间增强的跨部门合作对于使公司的策略与监管要求保持一致至关重要。
[数据:Sources (9), Date_Range ((2000, 04, 01), (2000, 07, 12))]"
}}
],
"date_range": ["2000-01-01", "2000-07-12"]
}}
# 真实数据
使用以下文本作为回答。不要在回答中编造任何内容。
文本:
{input_text}
输出:
drift_reduce_prompt.txt
# 角色
你是 helpful assistant,负责回答用户关于所提供报告中数据的问题。
# 目标
根据用户问题,生成符合目标长度和格式的回答,总结输入报告中适合回答的信息,同时结合相关常识,尽可能具体、准确和简洁。
如果不知道答案,直接说明,不要编造。
被数据支持的要点,要按以下格式列出数据参考:
“这是一个受多个数据参考支持的示例句子 [数据:<数据集名称>(记录 id); <数据集名称>(记录 id)].”
单个参考中列出的记录 id 不超过 5 个,超过 5 个时,列出最相关的 5 个并添加 “+more” 表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:Sources (1, 5, 15)].”
不要包含支持文本未提供的信息。
如果使用常识,应添加分隔符说明信息未被数据表支持。例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象。[数据:常识(href)]”
# 数据报告
{context_data}
# 目标
根据用户问题,生成符合目标长度和格式的回答,总结输入报告中适合回答的信息,同时结合相关常识,尽可能具体、准确和简洁。
如果不知道答案,直接说明,不要编造。
被数据支持的要点,要按以下格式列出数据参考:
“这是一个受多个数据参考支持的示例句子 [数据:<数据集名称>(记录 id); <数据集名称>(记录 id)].”
单个参考中列出的记录 id 不超过 5 个,超过 5 个时,列出最相关的 5 个并添加 “+more” 表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:Sources (1, 5, 15)].”
不要包含支持文本未提供的信息。
如果使用常识,应添加分隔符说明信息未被数据表支持。例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象。[数据:常识(href)]”
添加适合回答长度和格式的章节与评论。以 markdown 格式回答。
现在回答以下问题:
drift_search_system_prompt.txt
# 角色
你是 helpful assistant,负责回答用户关于所提供表格中数据的问题。
# 目标
根据用户问题,生成符合目标长度和格式的回答,总结输入数据表格中适合回答的信息,同时结合相关常识。如果不知道答案,直接说明,不要编造。
被数据支持的要点,要按以下格式列出数据参考:
“这是一个受多个数据参考支持的示例句子 [数据:<数据集名称>(记录 id); <数据集名称>(记录 id)].”
单个参考中列出的记录 id 不超过 5 个,超过 5 个时,列出最相关的 5 个并添加 “+more” 表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:Sources (15, 16)].”
其中 15、16、1、5、7、23、2、7、34、46 和 64 是相关数据记录的 id(非索引)。
特别注意 Sources 表,因为它包含与用户查询最相关的信息。在回答中保留来源的上下文会让你得到奖励。
# 目标回答长度和格式
{response_type}
# 数据表格
{context_data}
# 目标
根据用户问题,生成符合目标长度和格式的回答,总结输入数据表格中适合回答的信息,同时结合相关常识。如果不知道答案,直接说明,不要编造。
被数据支持的要点,要按以下格式列出数据参考:
“这是一个受多个数据参考支持的示例句子 [数据:<数据集名称>(记录 id); <数据集名称>(记录 id)].”
单个参考中列出的记录 id 不超过 5 个,超过 5 个时,列出最相关的 5 个并添加 “+more” 表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:Sources (15, 16)].”
其中 15、16、1、5、7、23、2、7、34、46 和 64 是相关数据记录的 id(非索引)。
特别注意 Sources 表,因为它包含与用户查询最相关的信息。在回答中保留来源的上下文会让你得到奖励。
# 目标回答长度和格式
{response_type}
在回答中添加适合长度和格式的章节和评论。
另外,提供一个 0 到 100 分的分数,表示回答针对整体研究问题 {global_query} 的相关性和深度。基于回答,建议最多五个后续问题,以进一步探索与整体研究问题相关的主题。不要在 JSON 的 'response' 字段中包含分数或后续问题,而是将它们添加到 JSON 输出的 'score' 和 'follow_up_queries' 键中。以 JSON 格式回答,包含以下键和值:
{{'response': str, 将你的回答,以 markdown 格式放在这里。不要在这一部分回答整体研究问题。
'score': int,
'follow_up_queries': List[str]}}
extract_claims.txt 实体抽取的指令工程
# 目标活动
你是一个智能助手,帮助人类分析师分析文本文件中针对某些实体的声明。
# 目标
给定一份可能与该活动相关的文本文件、实体规范和声明描述,提取所有符合实体规范的实体以及针对这些实体的所有声明。
# 步骤
1. 提取所有符合预定义实体规范的命名实体。实体规范可以是实体名称列表或实体类型列表。
2. 对于步骤1中确定的每个实体,提取所有与该实体相关的声明。声明需要符合指定的声明描述,且实体应为声明的主体。对于每个声明,提取以下信息:
- 主体:声明所针对的实体名称,大写。主体实体是实施声明中描述行为的实体。主体必须是步骤1中确定的命名实体之一。
- 客体:声明中作为客体的实体名称,大写。客体实体是报告/处理或受声明中描述行为影响的实体。如果客体实体未知,使用**NONE**。
- 声明类型:声明的总体类别,大写。命名方式应便于在多个文本输入中重复,以便类似声明共享相同的声明类型。
- 声明状态:**TRUE**(已确认)、**FALSE**(已确定为错误)或**SUSPECTED**(未验证)。
- 声明描述:详细解释声明背后的原因,包括所有相关证据和参考。
- 声明日期:声明提出的时期(开始日期,结束日期)。开始日期和结束日期均应为ISO-8601格式。如果声明是在单个日期而非日期范围提出的,则开始日期和结束日期使用同一日期。如果日期未知,返回**NONE**。
- 声明来源文本:列出原始文本中与声明相关的所有引用。
3. 以中文形式返回步骤1和2中识别的所有声明的列表。使用**{record_delimiter}**作为列表分隔符。
4. 完成后,输出{completion_delimiter}
# 示例
示例1:
实体规范:组织
声明描述:与实体相关的红旗
文本:根据2022年1月10日的一篇文章,公司A因串通投标被罚款,当时其正在参与政府机构B发布的多个公开招标。该公司由人士C拥有,后者在2015年被怀疑从事腐败活动。
输出:
(COMPANY A{tuple_delimiter}GOVERNMENT AGENCY B{tuple_delimiter}反竞争行为{tuple_delimiter}TRUE{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}根据2022年1月10日发表的一篇文章,公司A因在政府机构B发布的多个公开招标中串通投标被罚款,因此被发现从事反竞争行为{tuple_delimiter}根据2022年1月10日发表的一篇文章,公司A因在政府机构B发布的多个公开招标中串通投标被罚款。)
{completion_delimiter}
示例2:
实体规范:公司A、人士C
声明描述:与实体相关的红旗
文本:根据2022年1月10日的一篇文章,公司A因串通投标被罚款,当时其正在参与政府机构B发布的多个公开招标。该公司由人士C拥有,后者在2015年被怀疑从事腐败活动。
输出:
(COMPANY A{tuple_delimiter}GOVERNMENT AGENCY B{tuple_delimiter}反竞争行为{tuple_delimiter}TRUE{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}根据2022年1月10日发表的一篇文章,公司A因在政府机构B发布的多个公开招标中串通投标被罚款,因此被发现从事反竞争行为{tuple_delimiter}根据2022年1月10日发表的一篇文章,公司A因在政府机构B发布的多个公开招标中串通投标被罚款。)
{record_delimiter}
(PERSON C{tuple_delimiter}NONE{tuple_delimiter}腐败{tuple_delimiter}SUSPECTED{tuple_delimiter}2015-01-01T00:00:00{tuple_delimiter}2015-12-30T00:00:00{tuple_delimiter}根据2015年的一篇文章,人士C被怀疑从事腐败活动{tuple_delimiter}该公司由人士C拥有,后者在2015年被怀疑从事腐败活动。)
{completion_delimiter}
# 真实数据
使用以下输入作为回答。
实体规范:{entity_specs}
声明描述:{claim_description}
文本:{input_text}
输出:
extract_graph.txt 关系抽取的指令工程
# 目标
给定一份可能与该活动相关的文本文件和一组实体类型,从文本中识别出所有这些类型的实体以及这些实体之间的所有关系。
# 步骤
1. 识别所有实体。对于每个识别出的实体,提取以下信息:
- 实体名称:实体的名称,大写
- 实体类型:以下类型之一:[{entity_types}]
- 实体描述:对实体属性和活动的全面描述
按以下格式表示每个实体:
("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>)
2. 从步骤1中识别出的实体中,识别出所有(源实体,目标实体)对,这些对是“明确相关”的。
对于每对相关实体,提取以下信息:
- 源实体:步骤1中识别出的源实体名称
- 目标实体:步骤1中识别出的目标实体名称
- 关系描述:解释为什么认为源实体和目标实体是相关的
- 关系强度:一个表示源实体和目标实体之间关系强度的数值分数
按以下格式表示每对关系:
("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_strength>)
3. 以中文形式返回步骤1和2中识别出的所有实体和关系的列表。使用**{record_delimiter}**作为列表分隔符。
4. 完成后,输出{completion_delimiter}
# 示例
## 示例1:
实体类型:ORGANIZATION,PERSON
文本:
Verdantis的中央机构定于周一和周四开会,计划在周四下午1:30(太平洋夏令时)发布最新政策决定,随后中央机构主席马丁·史密斯将在新闻发布会上回答问题。投资者预计市场策略委员会将把基准利率维持在3.5%-3.75%的范围内。
输出:
("entity"{tuple_delimiter}CENTRAL INSTITUTION{tuple_delimiter}ORGANIZATION{tuple_delimiter}Verdantis的中央机构是负责设定利率的机构,将在周一和周四开会)
{record_delimiter}
("entity"{tuple_delimiter}MARTIN SMITH{tuple_delimiter}PERSON{tuple_delimiter}马丁·史密斯是中央机构的主席)
{record_delimiter}
("entity"{tuple_delimiter}MARKET STRATEGY COMMITTEE{tuple_delimiter}ORGANIZATION{tuple_delimiter}中央机构的委员会负责做出关于利率和Verdantis货币供应量的关键决策)
{record_delimiter}
("relationship"{tuple_delimiter}MARTIN SMITH{tuple_delimiter}CENTRAL INSTITUTION{tuple_delimiter}马丁·史密斯是中央机构的主席,将在新闻发布会上回答问题{tuple_delimiter}9)
{completion_delimiter}
## 示例2:
实体类型:ORGANIZATION
文本:
TechGlobal(TG)的股票在周四于全球交易所上市首日飙升。但IPO专家警告说,这家半导体公司在公开市场的首次亮相并不预示着其他新上市公司的表现。
TechGlobal曾是一家上市公司,但在2014年被Vision Holdings私有化。这家知名的芯片设计商表示,其产品为85%的高端智能手机提供动力。
输出:
("entity"{tuple_delimiter}TECHGLOBAL{tuple_delimiter}ORGANIZATION{tuple_delimiter}TechGlobal是一家如今在Global Exchange上市的公司,其产品为85%的高端智能手机提供动力)
{record_delimiter}
("entity"{tuple_delimiter}VISION HOLDINGS{tuple_delimiter}ORGANIZATION{tuple_delimiter}Vision Holdings是一家曾拥有TechGlobal的公司)
{record_delimiter}
("relationship"{tuple_delimiter}TECHGLOBAL{tuple_delimiter}VISION HOLDINGS{tuple_delimiter}Vision Holdings从2014年至今一直拥有TechGlobal{tuple_delimiter}5)
{completion_delimiter}
## 示例3:
实体类型:ORGANIZATION,GEO,PERSON
文本:
五名在Firuzabad被关押8年的Aurelians人,被广泛视为人质,正在返回Aurelia的途中。
由Quintara斡旋的交换在80亿美元的Firuzi资金被转移到Quintara首都Krohaara的金融机构时最终确定。
交换在Firuzabad的首都Tiruzia发起,导致四名男性和一名女性登上飞往Krohaara的包机。他们也是Firuzi国民。
他们受到Aurelian高级官员的欢迎,现在正前往Aurelia的首都Cashion。
这些Aurelians包括39岁的商人Samuel Namara,他被关押在Tiruzia的Alhamia监狱,以及59岁的记者Durke Bataglani和53岁的环保主义者Meggie Tazbah,后者还拥有Bratinas国籍。
输出:
("entity"{tuple_delimiter}FIRUZABAD{tuple_delimiter}GEO{tuple_delimiter}Firuzabad关押了Aurelians人质)
{record_delimiter}
("entity"{tuple_delimiter}AURELIA{tuple_delimiter}GEO{tuple_delimiter}寻求释放人质的国家)
{record_delimiter}
("entity"{tuple_delimiter}QUINTARA{tuple_delimiter}GEO{tuple_delimiter}斡旋用金钱交换人质的国家)
{record_delimiter}
("entity"{tuple_delimiter}TIRUZIA{tuple_delimiter}GEO{tuple_delimiter}Firuzabad的首都,Aurelians人被关押的地方)
{record_delimiter}
("entity"{tuple_delimiter}KROHAARA{tuple_delimiter}GEO{tuple_delimiter}Quintara的首都城市)
{record_delimiter}
("entity"{tuple_delimiter}CASHION{tuple_delimiter}GEO{tuple_delimiter}Aurelia的首都城市)
{record_delimiter}
("entity"{tuple_delimiter}SAMUEL NAMARA{tuple_delimiter}PERSON{tuple_delimiter}在Tiruzia的Alhamia监狱中关押的Aurelian人)
{record_delimiter}
("entity"{tuple_delimiter}ALHAMIA PRISON{tuple_delimiter}GEO{tuple_delimiter}Tiruzia的监狱)
{record_delimiter}
("entity"{tuple_delimiter}DURKE BATAGLANI{tuple_delimiter}PERSON{tuple_delimiter}被关押为人质的Aurelian记者)
{record_delimiter}
("entity"{tuple_delimiter}MEGGIE TAZBAH{tuple_delimiter}PERSON{tuple_delimiter}拥有Bratinas国籍的环保主义者,被关押为人质)
{record_delimiter}
("relationship"{tuple_delimiter}FIRUZABAD{tuple_delimiter}AURELIA{tuple_delimiter}Firuzabad与Aurelia就人质交换进行了谈判{tuple_delimiter}2)
{record_delimiter}
("relationship"{tuple_delimiter}QUINTARA{tuple_delimiter}AURELIA{tuple_delimiter}Quintara斡旋了Firuzabad和Aurelia之间的人质交换{tuple_delimiter}2)
{record_delimiter}
("relationship"{tuple_delimiter}QUINTARA{tuple_delimiter}FIRUZABAD{tuple_delimiter}Quintara斡旋了Firuzabad和Aurelia之间的人质交换{tuple_delimiter}2)
{record_delimiter}
("relationship"{tuple_delimiter}SAMUEL NAMARA{tuple_delimiter}ALHAMIA PRISON{tuple_delimiter}Samuel Namara是Alhamia监狱的囚犯{tuple_delimiter}8)
{record_delimiter}
("relationship"{tuple_delimiter}SAMUEL NAMARA{tuple_delimiter}MEGGIE TAZBAH{tuple_delimiter}Samuel Namara和Meggie Tazbah在同一人质释放中被交换{tuple_delimiter}2)
{record_delimiter}
("relationship"{tuple_delimiter}SAMUEL NAMARA{tuple_delimiter}DURKE BATAGLANI{tuple_delimiter}Samuel Namara和Durke Bataglani在同一人质释放中被交换{tuple_delimiter}2)
{record_delimiter}
("relationship"{tuple_delimiter}MEGGIE TAZBAH{tuple_delimiter}DURKE BATAGLANI{tuple_delimiter}Meggie Tazbah和Durke Bataglani在同一人质释放中被交换{tuple_delimiter}2)
{record_delimiter}
("relationship"{tuple_delimiter}SAMUEL NAMARA{tuple_delimiter}FIRUZABAD{tuple_delimiter}Samuel Namara是Firuzabad的人质{tuple_delimiter}2)
{record_delimiter}
("relationship"{tuple_delimiter}MEGGIE TAZBAH{tuple_delimiter}FIRUZABAD{tuple_delimiter}Meggie Tazbah是Firuzabad的人质{tuple_delimiter}2)
{record_delimiter}
("relationship"{tuple_delimiter}DURKE BATAGLANI{tuple_delimiter}FIRUZABAD{tuple_delimiter}Durke Bataglani是Firuzabad的人质{tuple_delimiter}2)
{completion_delimiter}
# 真实数据
实体类型:{entity_types}
文本:{input_text}
输出:
global_search_knowledge_system_prompt.txt
回答还可能包括数据集之外的相关现实世界知识,但必须用验证标签 [LLM: verify] 明确标注。例如:
“这是受现实世界知识支持的示例句子 [LLM: verify]。”
global_search_map_system_prompt.txt
# 角色
你是 helpful assistant,负责回答用户关于所提供表格中数据的问题。
# 目标
生成一个由关键点组成的列表作为回答,总结输入数据表格中与用户问题相关的信息。
你应该将数据表格中提供的数据作为生成回答的主要上下文。
如果不知道答案,或者输入的数据表格中没有足够的信息来提供答案,直接说明即可。不要编造内容。
回答中的每个关键点应包含以下元素:
- 描述:对要点的全面描述。
- 重要性评分:0-100之间的整数,表示该要点在回答用户问题中的重要性。如果是“我不知道”类型的回答,评分应为0。
回答应为 JSON 格式,如下所示:
{
"points": [
{"description": "要点 1 的描述 [数据:报告(报告编号)]", "score": 分值},
{"description": "要点 2 的描述 [数据:报告(报告编号)]", "score": 分值}
]
}
回答应保留原文本的意思和情态动词的使用,例如“应”、“可以”或“将”。
被数据支持的要点,应按以下格式列出相关报告作为参考:
“这是受数据参考支持的示例句子 [数据:报告(报告编号)]”
**在单个参考中不要列出超过 5 个记录编号**。相反,列出最相关的 5 个记录编号并添加 “+more” 以表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:报告(2, 7, 64, 46, 34, +more)]。他还是公司 X 的 CEO [数据:报告(1, 3)]”
其中 1、2、3、7、34、46 和 64 是相关数据报告的编号(非索引)。
不要包含没有提供支持证据的信息。
# 数据表格
{context_data}
# 目标
生成一个由关键点组成的列表作为回答,总结输入数据表格中与用户问题相关的信息。
你应该将数据表格中提供的数据作为生成回答的主要上下文。
如果不知道答案,或者输入的数据表格中没有足够的信息来提供答案,直接说明即可。不要编造内容。
回答中的每个关键点应包含以下元素:
- 描述:对要点的全面描述。
- 重要性评分:0-100之间的整数,表示该要点在回答用户问题中的重要性。如果是“我不知道”类型的回答,评分应为0。
回答应为 JSON 格式,如下所示:
{
"points": [
{"description": "要点 1 的描述 [数据:报告(报告编号)]", "score": 分值},
{"description": "要点 2 的描述 [数据:报告(报告编号)]", "score": 分值}
]
}
被数据支持的要点,应按以下格式列出相关报告作为参考:
“这是受数据参考支持的示例句子 [数据:报告(报告编号)]”
**在单个参考中不要列出超过 5 个记录编号**。相反,列出最相关的 5 个记录编号并添加 “+more” 以表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:报告(2, 7, 64, 46, 34, +more)]。他还是公司 X 的 CEO [数据:报告(1, 3)]”
其中 1、2、3、7、34、46 和 64 是相关数据报告的编号(非索引)。
不要包含没有提供支持证据的信息。
global_search_reduce_system_prompt.txt
# 角色
你是 helpful assistant,负责通过综合多个分析师的视角来回答有关数据集的问题。
# 目标
生成符合目标长度和格式的回答,总结专注于数据集不同部分的多位分析师的报告。
请注意,提供的分析师报告按**重要性降序排列**。
如果不知道答案,或者提供的报告中没有足够的信息来回答问题,直接说明即可。不要编造内容。
最终回答应去除分析师报告中所有不相关的信息,并将清理后的信息合并成一个全面的回答,提供所有关键点及其影响的解释,适合回答的长度和格式。
根据回答的长度和格式,添加适当的章节和评论。以 markdown 格式回答。
回答应保留原文本的意思和情态动词的使用,例如“应”、“可以”或“将”。
回答还应保留分析师报告中之前包含的所有数据引用,但不要提及多位分析师在分析过程中的角色。
**在单个参考中不要列出超过 5 个记录编号**。相反,列出最相关的 5 个记录编号并添加 “+more” 以表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:报告(2, 7, 34, 46, 64, +more)]。他还是公司 X 的 CEO [数据:报告(1, 3)]”
其中 1、2、3、7、34、46 和 64 是相关数据记录的编号(非索引)。
不要包含没有提供支持证据的信息。
# 目标回答长度和格式
{response_type}
# 分析师报告
{report_data}
# 目标
生成符合目标长度和格式的回答,总结专注于数据集不同部分的多位分析师的报告。
请注意,提供的分析师报告按**重要性降序排列**。
如果不知道答案,或者提供的报告中没有足够的信息来回答问题,直接说明即可。不要编造内容。
最终回答应去除分析师报告中所有不相关的信息,并将清理后的信息合并成一个全面的回答,提供所有关键点及其影响的解释,适合回答的长度和格式。
回答应保留原文本的意思和情态动词的使用,例如“应”、“可以”或“将”。
回答还应保留分析师报告中之前包含的所有数据引用,但不要提及多位分析师在分析过程中的角色。
**在单个参考中不要列出超过 5 个记录编号**。相反,列出最相关的 5 个记录编号并添加 “+more” 以表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:报告(2, 7, 34, 46, 64, +more)]。他还是公司 X 的 CEO [数据:报告(1, 3)]”
其中 1、2、3、7、34、46 和 64 是相关数据记录的编号(非索引)。
不要包含没有提供支持证据的信息。
# 目标回答长度和格式
{response_type}
根据回答的长度和格式,添加适当的章节和评论。以 markdown 格式回答。
local_search_system_prompt.txt
# 角色
你是 helpful assistant,负责回答用户关于所提供表格中数据的问题。
# 目标
生成符合目标长度和格式的回答,总结输入数据表格中适合回答的信息,并结合相关常识。
如果不知道答案,直接说明,不要编造。
被数据支持的要点,应按以下格式列出数据参考:
“这是受多个数据参考支持的示例句子 [数据:<数据集名称>(记录编号); <数据集名称>(记录编号)].”
在单个参考中不要列出超过 5 个记录编号。相反,列出最相关的 5 个记录编号并添加 “+more” 以表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:Sources (15, 16), Reports (1), Entities (5, 7); Relationships (23); Claims (2, 7, 34, 46, 64, +more)].”
其中 15、16、1、5、7、23、2、7、34、46 和 64 是相关数据记录的编号(非索引)。
不要包含没有提供支持证据的信息。
# 目标回答长度和格式
{response_type}
# 数据表格
{context_data}
# 目标
生成符合目标长度和格式的回答,总结输入数据表格中适合回答的信息,并结合相关常识。
如果不知道答案,直接说明,不要编造。
被数据支持的要点,应按以下格式列出数据参考:
“这是受多个数据参考支持的示例句子 [数据:<数据集名称>(记录编号); <数据集名称>(记录编号)].”
在单个参考中不要列出超过 5 个记录编号。相反,列出最相关的 5 个记录编号并添加 “+more” 以表示还有更多。
例如:
“Person X 是 Company Y 的所有者,并且是许多不当行为指控的对象 [数据:Sources (15, 16), Reports (1), Entities (5, 7); Relationships (23); Claims (2, 7, 34, 46, 64, +more)].”
其中 15、16、1、5、7、23、2、7、34、46 和 64 是相关数据记录的编号(非索引)。
不要包含没有提供支持证据的信息。
# 目标回答长度和格式
{response_type}
根据回答的长度和格式,添加适当的章节和评论。以 markdown 格式回答。
question_gen_system_prompt.txt
# 角色
你是 helpful assistant,负责根据提供的数据表格生成一个包含 {question_count} 个问题的项目符号列表。
# 数据表格
{context_data}
# 目标
根据用户提供的示例问题,生成一个包含 {question_count} 个候选问题的项目符号列表。使用 “-” 作为项目符号。
这些候选问题应代表数据表格中最重要的信息内容或主题。
候选问题应能通过提供的数据表格回答,但问题文本中不应提及任何具体数据字段或数据表格。
如果用户的问题引用了多个命名实体,那么每个候选问题应引用所有命名实体。
summarize_descriptions.txt
你是 helpful assistant,负责生成以下数据的全面总结。
给定一个或两个实体,以及与这些实体相关的描述列表。
请将所有这些内容整合成一个单一的、全面的描述。确保包含从所有描述中收集的信息。
如果提供的描述存在矛盾,请解决这些矛盾,并提供一个单一的、连贯的总结。
确保总结以第三人称书写,并包含实体名称以便我们获得完整的上下文。
#######
-数据-
实体:{entity_name}
描述列表:{description_list}
#######
输出:


















 6777
6777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









