









MeMOTR: Long-Term Memory-Augmented Transformer for Multi-Object Tracking论文解析—具有长时记忆力增强的Transformer 多目标跟踪器

学习使用Transform的跟踪器系列,这里是最新的ICCV 2023年的经过多次改进的论文。
发表:2023年 ICCV
机构与作者:南京大学王利民教授
源码地址:https://github.com/MCG-NJU/MeMOTR
知乎上有一篇论文作者关于论文的介绍很有参考的价值。https://zhuanlan.zhihu.com/p/662160485
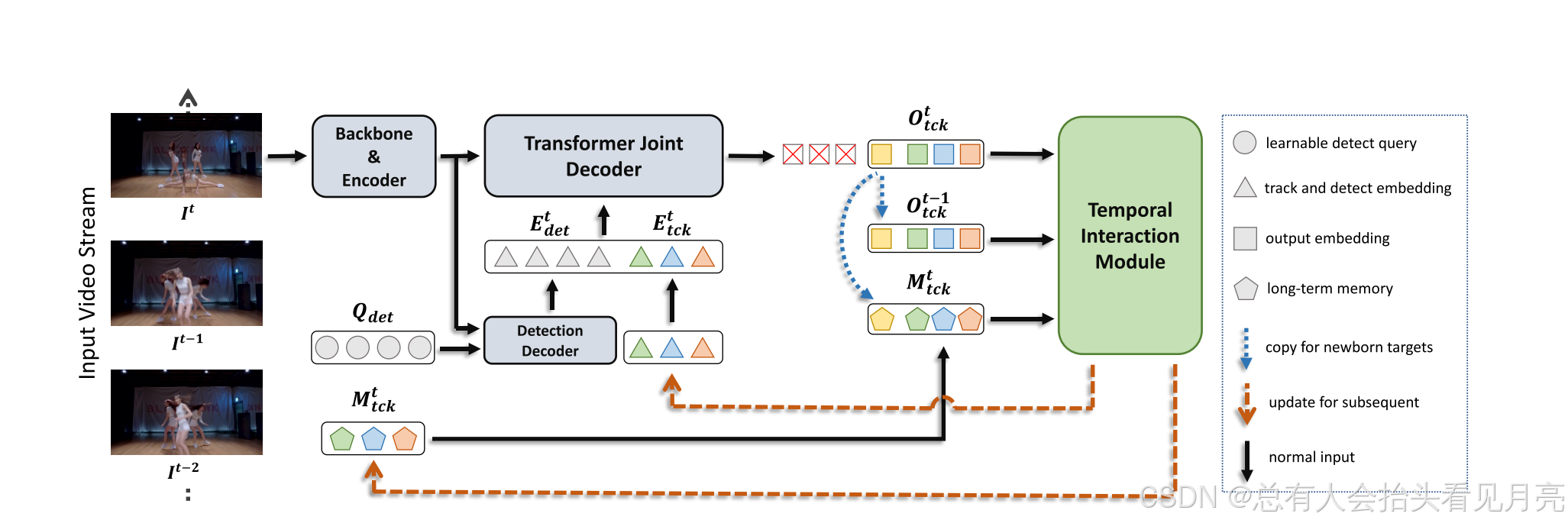
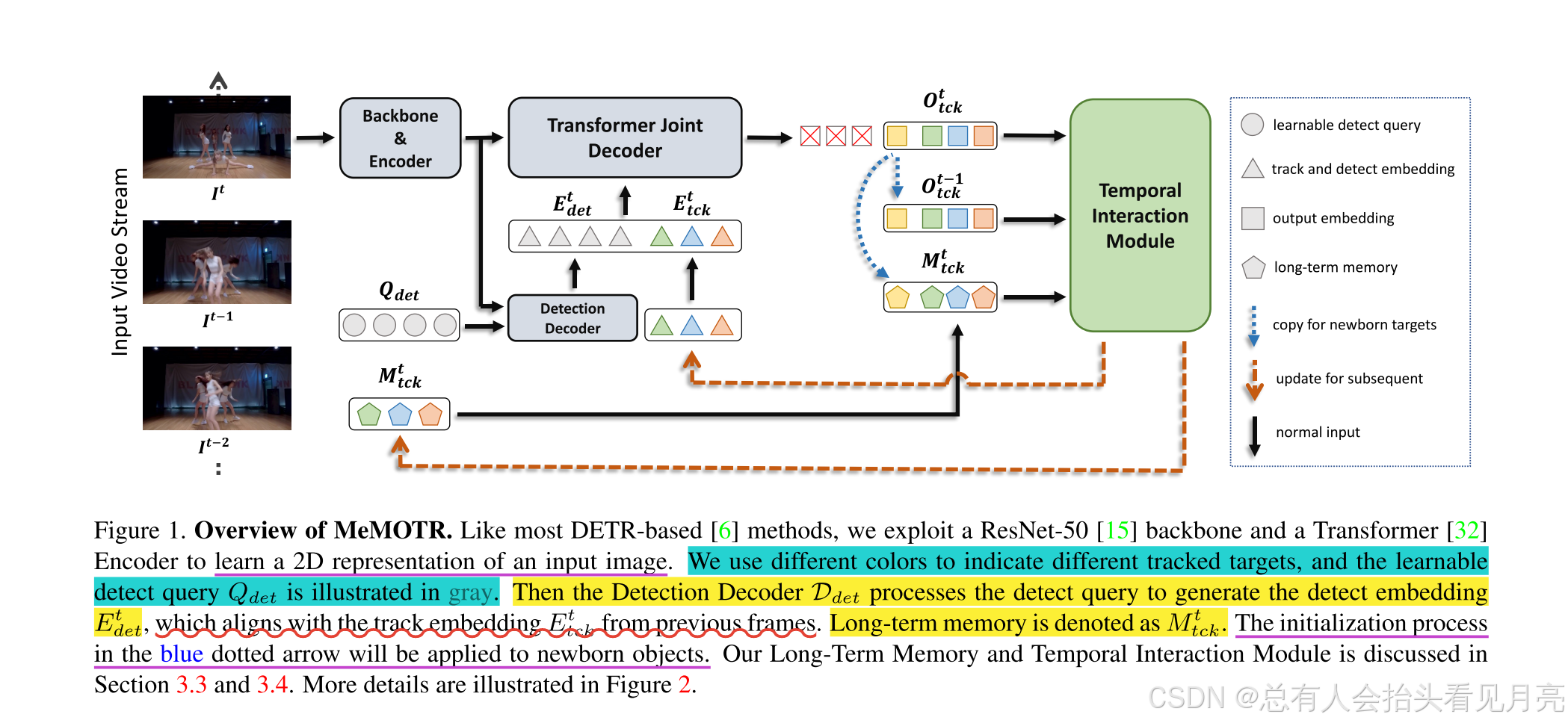
摘要与整体概括
- 现有的方法仅显式地利用相邻帧之间的对象特征,而缺乏对长期时间信息进行建模的能力。
- 我们的方法能够通过利用带有定制内存注意力层的长期内存注入,使同一对象的轨迹嵌入更加稳定和可区分
- DanceTrack 上的实验结果表明,MeMOTR 在 HOTA 和 AssA 指标上分别超越了最先进的方法 7.9% 和 13.0%
对其中的主要的创新点进行一定的总结:
-
将长时记忆(Long-Term Memory)注入到 track query 中,以获取更加稳定的特征表示。
-
构建了 Memory-Attention Layer,利用 self-attention 使不同 ID 的目标之间进行响应,从而获取更加可区分的特征表示。
-
将第一层 DETR Decoder 作为 detection only 模式,使其与来自上一帧的 track query 尽可能对齐,从而减少特征不对齐所产生的负面影响。

Introduction
在引言的部分首先作者先提到了传统的MOT17数据集而产生的TBD范式的检测器所面临的最主要的问题。
- 根据MOT的定义,该任务可以正式分为两个部分:对象检测和关联
- MOT17 这些数据集由于其几乎线性的运动模式,在目标关联方面没有足够的挑战。
- 然而,在一些复杂的场景中,例如团体舞者和体育运动员,关联目标成为一个严峻的挑战.这些相似的外观和不稳定的运动可能会导致现有方法失效
之后自然而然的提到了在Transform大火的现在基于Transform的跟踪的好处和面对的一些问题。
基于 Transformer 的跟踪方法 引入了一种新的完全端到端的 MOT 范例。 通过Transformer中检测和跟踪查询的交互和渐进解码,同时完成检测和跟踪
这种方式可能会有更高的发展前景。
那么面对的问题又有哪些呢? 尽管这些基于 Transformer 的方法取得了出色的性能,但它们仍然面临一些复杂的问题
- 相似的外观、不规则的运动模式和长期的遮挡。
- 更智能地利用时间信息可以为跟踪器提供每个跟踪目标更有效和更稳健的表示
- 但是在目前的绝大多数方法中,他们往往只显式利用了相邻两帧的视觉信息,这样缺失了对更长时的视觉信息的利用

Transformer-based(query-based)方法中,track query 承担了表示和向后传递已跟踪目标的任务,我们认为对于每一个目标的 track query 来说,其应该具有如下良好的特性:
- 同一个 ID 所对应的 track query 随时间的变化应该尽可能平滑,因为对于视频中的目标来说,他们在帧与帧之间的变化往往是缓慢细微的、不易突变的。
- 不同 ID 所对应的 track query 应该尽可能可区分,这样有利于在后续帧中对不同目标进行更好的定位,减少 ID 错误的情况。
从以上两点出发,我们基于现有的 query-based 多目标跟踪方法(MOTR[1])提出了如下的主要改进:
- 将长时记忆(Long-Term Memory)注入到 track query 中,以获取更加稳定的特征表示。
- 构建了 Memory-Attention Layer,利用 self-attention 使不同 ID 的目标之间进行响应,从而获取更加可区分的特征表示。
- 此外,我们还观察到了在现有框架下,detect query 和 track query 之间的特征语义不对齐问题。因此将第一层 DETR Decoder 作为 detection only 模式,使其与来自上一帧的 track query 尽可能对齐,从而减少特征不对齐所产生的负面影响。
我们对这里的这里的改进方式参考一些资料给出更为具体的说明:
在目标跟踪中,特别是在基于Transformer的跟踪方法中,如DETR(Detection Transformer)及其衍生模型,存在detect query和track query两种类型的查询(query)。Detect query负责检测新出现的目标,而track query负责在连续帧中跟踪已存在的目标。这两种query在特征语义上可能存在不对齐的问题,因为detect query通常是从可学习的初始化状态开始,缺乏丰富的语义信息,而track query则携带了来自之前帧的丰富语义信息。这种语义信息的不对齐可能会导致模型性能下降,尤其是在处理新出现目标和维持目标跟踪连续性方面。
为了解决这个问题,一些研究工作提出将DETR的Decoder的第一层设置为detection only模式,这意味着在这一层只处理detect query,不涉及track query。这样做的目的是让detect query在这一层中获得与目标相关的语义信息,从而使其与来自上一帧的track query在语义上更加对齐。通过这种方式,detect query和track query可以更好地协同工作,减少由于语义不一致导致的负面影响,提高目标跟踪的准确性和鲁棒性。
提出的记忆多目标跟踪的介绍步骤
我们利用检测和跟踪嵌入分别通过 Transformer 解码器定位新生对象和跟踪对象。- 我们的模型通过指数递归更新算法[29]为每个跟踪对象维护长期记忆。
- 然后,我们将这段记忆注入到轨迹嵌入中,减少其突变,从而提高模型关联能力。
- 由于视频流中存在多个跟踪目标,我们应用记忆注意力层来产生更容易区分的表示。 此外,我们提出了一种自适应聚合来融合两个相邻帧的对象特征,以提高跟踪的鲁棒性。
之后的部分作者介绍了整个追踪器算法进行跟踪的一个流程,并进行了整体的概括,我们将其总结如下。

提出的记忆多目标跟踪的介绍步骤,利用检测和跟踪嵌入分别通过 Transformer Decoder 定位出现的目标对象和跟踪对象
我们利用检测和跟踪嵌入分别通过 Transformer 解码器定位新生对象和跟踪对象。- 我们的模型通过指数递归更新算法[29]为每个跟踪对象维护长期记忆。
- 然后,我们将这段记忆注入到轨迹嵌入中,减少其突变,从而提高模型关联能力。
- 由于视频流中存在多个跟踪目标,我们应用记忆注意力层来产生更容易区分的表示。 此外,我们提出了一种自适应聚合来融合两个相邻帧的对象特征,以提高跟踪的鲁棒性。
整篇文章是在DERT的基础上去做的,也就是参考了DERT的 the learnable detection query作者后面提到了一下这一个检测的可学习向量存在哪些问题。
- DETR 中没有关于特定对象的语义信息。
- 然而,基于 Transformer 的 MOT 方法(如 MOTR )中的跟踪查询携带有关被跟踪对象的信息。 这种差异将导致语义信息差距,从而降低最终的跟踪性能。
- 因此,为了克服这个问题,我们使用轻量的解码器来执行初步的对象检测,输出具有特定语义的检测嵌入。
- 然后我们将检测和跟踪嵌入联合输入到后续解码器中,以使 MeMOTR 跟踪结果更加精确.
看到这里的时候自己也是对其中的一些概念信息产生了一定的疑问,就查询并整理了一些资料。
- 检测嵌入(Detection Embedding): 检测嵌入通常是指在计算机视觉领域中,特别是在目标检测任务中,模型能够为检测到的目标输出一个嵌入向量(embedding vector),这个向量能够代表目标的某些特征。在目标检测中,嵌入向量可能包含目标的位置、大小、形状等信息。这种嵌入向量可以用于后续的任务,比如目标的分类、跟踪或者与其他目标的关系分析等。
简单理解就类似于REID网络中的128维度的外观嵌入向量。
- 语义信息(Semantic Information): 语义信息指的是与数据相关的实际意义或解释。目标检测中,语义信息指的是与图像中的目标物体相关的类别或身份信息。这些信息对于确定图像中存在哪些目标以及它们的位置至关重要
论文中提到的之前面临的一个很大的问题是语义信息无法对其导致效率下降的问题。
在目标跟踪领域中,语义信息无法对齐指的是在跟踪过程中,跟踪算法无法准确地将目标的语义特征(即目标的身份或类别信息)与目标的物理特征(如位置、形状、运动等)关联起来的问题。
总结一下:也就是说第一层DETR Decoder作为detection only模式,只输入可学习的detect query,输出包含了语义信息的detect query,这个输出被称为detect embedding。然后,这个detect embedding与来自上一帧的track query(称为track embedding)一同输入到后续的Decoder层中进行同步解码。这样的设计有助于减少语义不对齐的影响,因为detect query在第一层已经获得了与目标相关的语义信息,从而能够与track query更好地对齐。
Related Work
相关工作的部分涉及到的内容是比较少的,主要介绍了之前的多目标跟踪领域的两种常用的方法。
- Tracking-by-Detection
- Tracking-by-Query
Tracking-by-Detection
多目标跟踪的流程拆分成为目标检测和目标关联(object association)两个部分,在很长一段时间内,Tracking-by-Detection(TBD)范式都广受好评,并且在行人跟踪数据集上(MOT17、MOT20)取得了傲人的成绩。但是这些数据集中目标的运动模式往往都较为简单(行人的运动接近线性运动),致使许多 Tracking-by-Detection 方法都陷入了线性运动的强先验中。尤其是在近期的一些更加复杂和多变的场景中(如 DanceTrack),简单的线性运动假设无法取得令人满意的效果。
Tracking-by-Query
核心思想:通常不需要额外的后处理来关联检测结果。 与上面提到的按检测跟踪范例不同,按查询跟踪方法应用跟踪查询来逐步解码被跟踪对象的位置。
这个部分自己感觉比较关键的地方就在于这里总结了之前的一段时间,基于Transform的跟踪器是之后可以进一步学习的地方
- TransTrack 构建一个用于检测和跟踪的连体网络,然后应用 IoU 匹配来生成新生目标
- TrackFormer 使用相同的 Transformer 解码器进行检测和跟踪,然后采用具有高 IoU 阈值的非极大值抑制 (NMS) 来删除强烈重叠的重复边界框
- MOTR 为多目标跟踪构建了一个优雅且完全端到端的 Transformer。
但这些方法同样也存在一些问题:
- 尽管轨迹查询可以随着时间的推移不断更新,但大多数方法仍然没有显式地利用更长的时间信息。
- 大型记忆库以从与时间相关的知识中受益,但会遭受巨大的存储成本。
DETR 范式在目标检测领域的火爆,其代表的 query-based 思想也被许多研究者扩展到了多目标跟踪领域,例如 TrackFormer[2]、MOTR[1]、TransTrack[3] 等工作。尽管在传统的行人跟踪数据集上,由于目标密度等问题,并没能超过现有最优的 Tracking-by-Detection 算法(例如 ByteTrack[4],OC-SORT[5]),但是得益于 Transformer 的灵活性以及较少的特定先验,其在 DanceTrack 这类复杂场景下取得了较好的成绩。
核心方法Method
基于Transform方法的全局概述
Transformer-based(query-based)的现有做法一般所示如下:
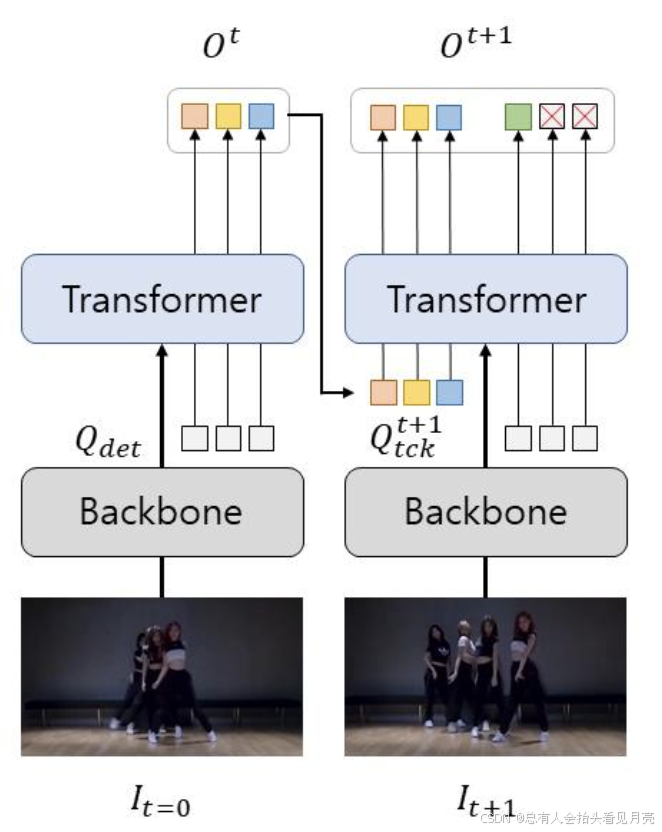
- 对于每一帧的处理可以视作一个独立的 DETR(图中 Transformer 部分)。对于视频第一帧,由于不存在已经跟踪的目标,因此仅仅输入可学习的detect query(Qdet),对输出的内容通过分类阈值进行筛选,超过阈值的输出向量会被保留下来,记作Ot;而后经过一些后续处理(例如MOTR中的QIM),转化成为输入到下一帧同样的DETR结构中的track query,记作Q;随后,将其和每一帧共用的detect query(Qdet)一起输入到 DETR Decoder 中进行逐层处理,最终输出对应的向量:每一个 track query 所对应的目标自然继承来自上一帧的ID 信息,而Qdet对应的目标再次经过阈值筛选,用于检测新生目标(newborn object),并且将其添加到已跟踪的目标列表中,如此往复。
这里主要就是涉及到了之前存在的问题,除了我们的第一帧之外。我们将之后的产生的Q:track query和DETR系列的核心detection query一起输入到Transform的结构中去。产生了语义没有对其的问题。
- 如果当前帧的目标被遮挡,则对应的 track query的期望输出置信度应该低于阈值,并且将该track query标记为不活跃(inactive);当目标再一次出现的时候,其置信度应该高于阈值,并且将该 track query 的不活跃标记去除;如果一个目标在一定帧数Tmiss之后都没有重新出现,则将该track query彻底丢弃。
对于这个部分理解还不那么的充分,要结合学习一下之前的基于Transform的多目标跟踪方法。
在现有的 Transformer-based 多目标跟踪框架中,detect query 和 track query 被同时输入到 DETR Decoder 中,进行六层的连续解码,得到最终目标的 bounding box 和 classification不同。
DETR 中的 detect query 扮演了一个类似于可学习 anchor 的角色,它往往不具备丰富的语义信息;但是 track query 是来自于上一帧的 DETR Decoder 的输出,其具有用于表示该目标的丰富语义信息。因此从直觉上来说,将这两者同时输入到一个模块中,由于两者的语义信息无法对齐,因此很可能引起冲突,从而对网络带来负面影响。
公式符号的全局说明
MeMOTR,一种用于多目标跟踪的长期记忆增强 Transformer。 与大多数现有方法 只明确利用相邻帧之间跟踪对象的状态不同,我们的核心贡献是构建一个长期记忆,以维护每个跟踪对象的长期时间特征 目标,以及时间交互模块(TIM),该模块有效地将时间信息注入后续跟踪过程。

我们使用 ResNet50 主干和 Transformer 编码器来生成输入帧 It 的图像特征。
我们对常见的公式符号进行一定的介绍便于后面的理解。
Q det Q_{\text {det }} Qdet
可学习的检测查询向量
D det \mathcal{D}_{\text {det }} Ddet
检测解码器:也就是DETR的第二个部分
E d e t t E_{d e t}^{t} Edett
当前帧第t帧的检测嵌入向量,也就是第一个Decode输出的结果。
[ E d e t t , E t c k t ] \left[E_{d e t}^{t}, E_{t c k}^{t}\right] [Edett,Etckt]
结合上一帧的轨迹查询向量与其进行结合(两个都包含语义的信息)构成了图像编码特征在将其送入到之后的Decoder中
D joint \mathcal{D}_{\text {joint }} Djoint
Transformer Joint Decoder也就是我们送入到之后的那个Decoder部分
[ O ^ d e t t , O ^ t c k t ] . \left[\hat{O}_{d e t}^{t}, \hat{O}_{t c k}^{t}\right] . [O^dett,O^tckt].
Transformer Joint Decoder所产生的结果,对于新产生的对象(黄色框)我们也将其放入的Ot det中进行统一的一种表示
这两个相关的部分进行合并,也也就提出了下面的这个整体表示的形式。
O t c k t = [ O ^ d e t t , O ^ t c k t ] O_{t c k}^{t} = \left[\hat{O}_{d e t}^{t}, \hat{O}_{t c k}^{t}\right] Otckt=[O^dett,O^tckt]
然后,我们从输出嵌入中预测与第 i 个目标相对应的分类置信度 ct i 和边界框 bt i 。
最后我们将最后的这种形式的结果输入到最后提出的创新的模块中完成一帧的处理。
- 我们输入相邻帧的输出
[ O t c k t , O t c k t − 1 ] \left[O_{t c k}^{t}, O_{t c k}^{t-1}\right] [Otckt,Otckt−1]
- the long-term memory
M t c k t M_{t c k}^{t} Mtckt
进入时间交互模块,即创新的结构TIM模块部分。更新后续的轨道嵌入产生两个结果我们用于进行下一帧的处理。
E t c k t + 1 M t c k t + 1 E_{t c k}^{t+1} M_{t c k}^{t+1} Etckt+1Mtckt+1

- 我们使用不同的颜色来指示不同的跟踪目标,可学习的检测查询 Qdet 以灰色表示。
- 与前一帧中的轨道嵌入 Et tck 对齐
- 长期记忆被表示为Mt tck。 蓝色虚线箭头中的初始化过程将应用于新生对象。
Detection Decoder
总体概述:将 DETR Decoder 划分成为两部分:第一层命名为 Detection Decoder,只输入可学习的 detect query,输出包含了语义信息的 detect query,并且与来自上一帧的 track query 一同输入到后续五层的 Joint Decoder 中进行同步解码,以减少语义不对齐带来的影响。为了加以区分,我们将没有携带语义信息的可学习目标检测 query 称为 detect query(记作 Qdet),将经过第一层 Decoder 之后携带了语义信息的对应输出称为 detect embedding,记作Edet ,同时,将来自上一帧的 track query 称作 track embedding 以对齐,记作 Etckt

Long-Term Memory
与之前仅利用相邻帧信息的方法不同,我们明确引入了长期记忆。为跟踪目标保留更长的时间信息。
每当一个新目标产生的时候,我们利用它本身的特征向量创建一个对应的长时记忆向量
M t c k t M_{t c k}^{t} Mtckt
论文中说:当检测到新生物体时,我们用当前输出初始化其长期记忆。

我这里结合一些资料给出了可能的一部分原因。
在目标跟踪中,当检测到新生物体时,我们用当前输出初始化其长期记忆的原因主要基于以下几点:
-
捕获初始状态:新生物体首次出现在视频帧中时,使用当前输出初始化其长期记忆可以立即捕获该物体的初始状态,包括其外观、位置和运动特征等。这为后续的跟踪和身份维护提供了一个起点。
-
建立身份嵌入:初始化长期记忆实际上是在为新生物体建立一个身份嵌入(identity embedding),这个嵌入向量在后续帧中用于关联和识别同一物体,即使在遮挡或离开视野后重新出现时也能保持一致性。
-
增强模型的长期关联能力:通过将长期记忆机制融入Transformer架构,模型能够存储历史帧中的目标信息,并在当前帧的处理中有选择地注入这些历史信息,
增强了模型的长期关联能力。 -
提高跟踪鲁棒性:长期记忆的初始化有助于提高跟踪的鲁棒性,尤其是在目标长时间遮挡或离开视野后重新出现时,模型能够更好地维持和恢复跟踪。
-
利用长期历史信息:长期记忆的初始化使得模型能够利用长期历史信息,这在复杂场景下尤其重要,可以提升模型在处理遮挡、交互等复杂情况时的性能。
由于目标会随着时间逐渐发生外观上的转变,因此我们需要不断更新这个长时记忆向量。我们认为目标在连续帧之间的改变往往是平滑的,因此我们采用了指数衰减移动平均数(running average with exponentially decaying weights)来更新这一向量,如下式所示:
M ~ t c k t + 1 = ( 1 − λ ) M t c k t + λ ⋅ O t c k t , \widetilde{M}_{t c k}^{t+1}=(1-\lambda) M_{t c k}^{t}+\lambda \cdot O_{t c k}^{t}, M tckt+1=(1−λ)Mtckt+λ⋅Otckt,
在实现中,入设定在一个非常小的数值(0.01),这样可以保证相邻帧同一个目标的长时记忆向量只发生轻微的改变,从而确保其随着时间进行平滑稳定的更新而不易发生突变.

Temporal Interaction Module
这一部分也就是论文中首次提出的时间交互模块TIM模块。

其本质的核心思想就是论文中所提到的用多帧来增强单帧的表示。因此,我们在 MeMOTR 中使用自适应聚合算法融合两个相邻帧的输出。
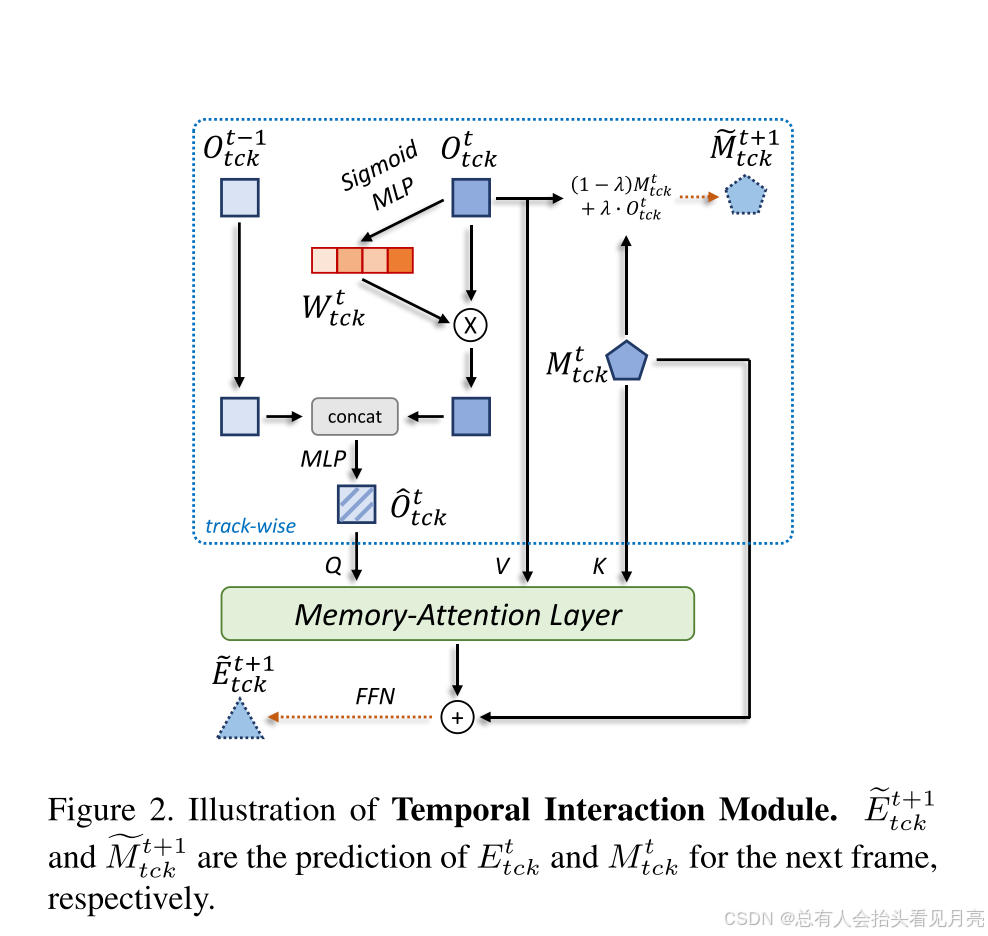
其主要可以总结为三个部分组成:
- Adaptive Aggregation for Temporal Enhancement
将当前帧与前一帧的输出向量(Ot tck和Ot-1tck)动态结合,输出融合后的特征O(hat)t tck。这种利用相邻帧进行增强的方式在视频理解中较为常见,在MOT领域,例如 MOTR、TrackFormer 中都有类似的做法,它可以有效的增强对视频中物体的表示,并且获得更加鲁棒的特征。
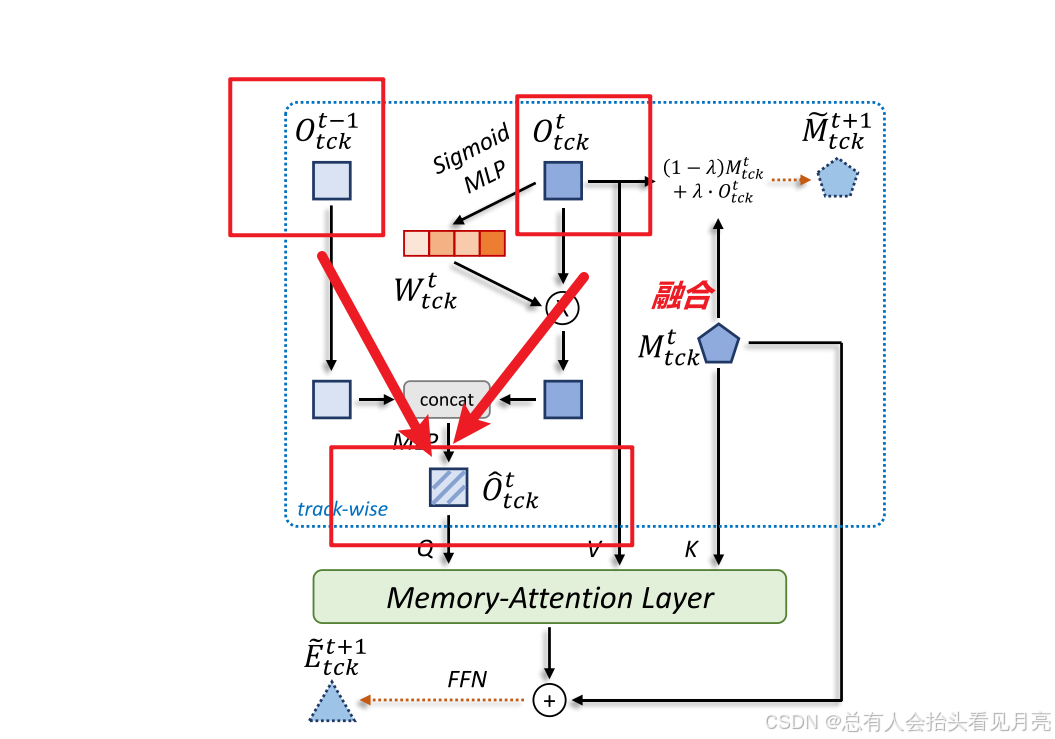
由于遮挡和模糊,当前帧的输出嵌入 Ot tck 可能不可靠。 因此,我们为每个跟踪实例生成一个通道权重 Wt tck 以缓解此问题:
W t c k t = Sigmoid ( MLP ( O t c k t ) ) . W_{t c k}^{t}=\operatorname{Sigmoid}\left(\operatorname{MLP}\left(O_{t c k}^{t}\right)\right) . Wtckt=Sigmoid(MLP(Otckt)).
也就是图中画出的MLP的部分。
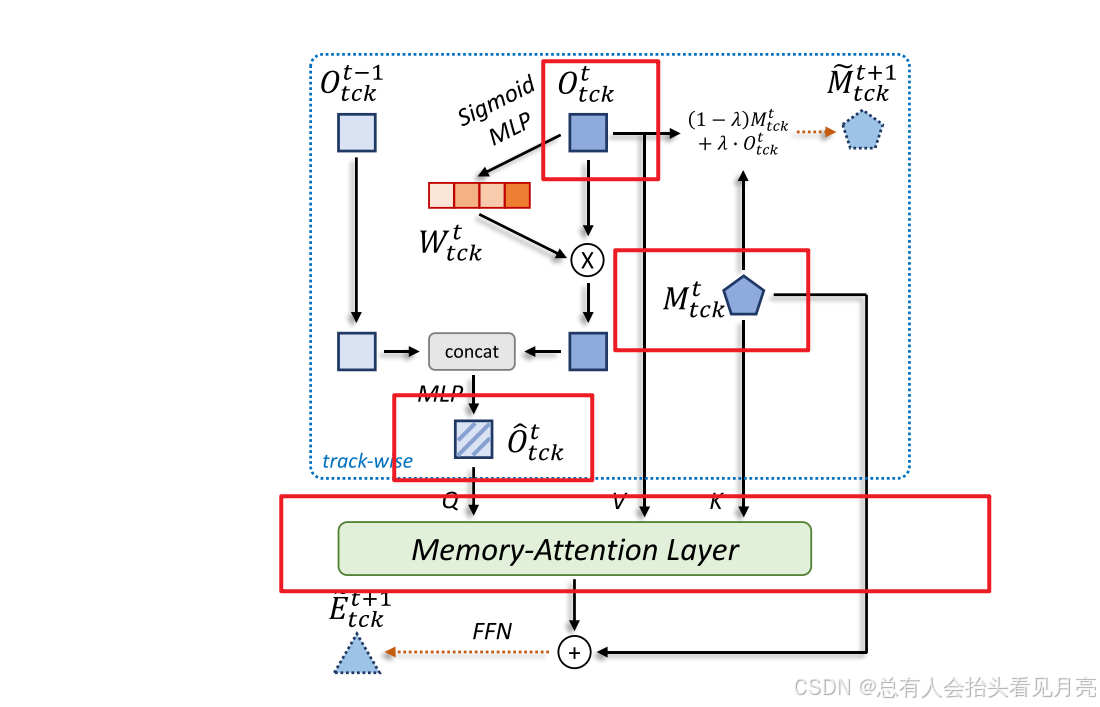
- Memory-Attention Layer
由于同一帧中有多个相似的对象,我们认为学习更具辨别力的表示对于跟踪器也至关重要。 因此,我们采用称为记忆注意力层的多头注意力[32]结构来实现不同轨迹之间的交互。


3. Memory Injection
Memory Injection:对于每个目标经过 Memory-Attention Layer 之后输出的向量,我们通过j简单的加法向其中注入对应目标的长时记忆向量。由于在前述讨论中提到,长时记忆的更新是稳定平滑的,因此通过这一步骤可以使得后续的 track embedding 在时序上更加稳定,从而提升跟踪性能。
最后,我们使用加法将长期记忆 Mt tck 和记忆注意力层的结果结合起来,然后输入到 FFN 网络中来预测后续的轨道嵌入 Et+1 tck
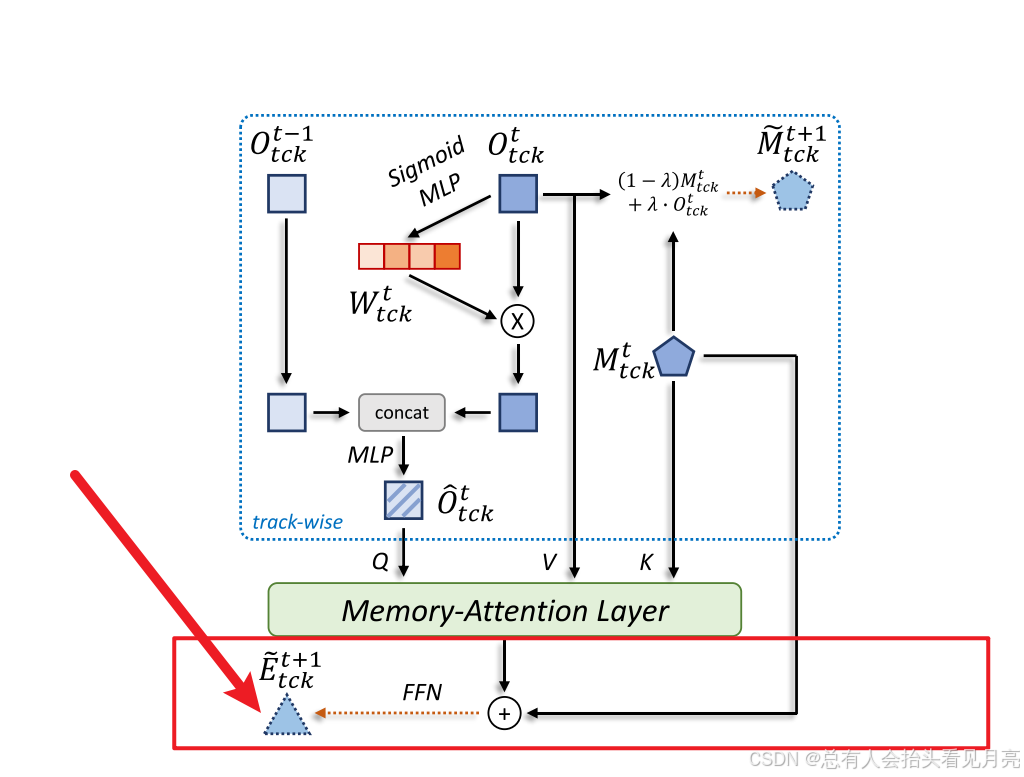
总结:由于同一帧中有多个相似的对象,学习更多的判别表征对跟踪器也至关重要。因此,采用一种称为记忆-注意层 (memoryattention layer)的多头注意力结构来实现不同轨迹之间的这种相互作用。并且对于每个目标经过 Memory-Attention Layer 之后输出的向量,我们通过简单的加法向其中注入对应目标的长时记忆向量。
Inference Details
在这一部分我们对其推理细节和简单的实验细节进行一定的介绍。

在时间步 t,我们将可学习检测查询 Qdet 和跟踪嵌入 Et tck (E0 tck = ∅) 联合输入到我们的模型中,分别产生检测和跟踪结果。 置信度大于τdet的检测结果将转化为新出现的目标物体。
目标遮挡是多目标跟踪任务中的常见问题。 如果跟踪对象在当前帧中丢失(置信度≤τtck),我们不会直接删除其轨迹嵌入,而是将其标记为非活动轨迹。 之后,非活动目标将在 Tmiss 帧后被完全删除。
我们不会在每个对象的每个时间步更新轨道嵌入和长期记忆。 相反,我们选择以高置信度更新这些轨道嵌入。 更新阈值 τnext 的选择产生以下更新公式
下面的公式对应的就是选择高置信度的过程。也就是它只有大于一定的阈值条件才会进行更新的。
[
E
i
t
+
1
,
M
i
t
+
1
]
=
{
[
E
~
i
t
+
1
,
M
~
i
t
+
1
]
,
c
i
t
>
τ
n
e
x
t
[
E
i
t
,
M
i
t
]
,
c
i
t
≤
τ
n
e
x
t
\left[E_{i}^{t+1}, M_{i}^{t+1}\right]=\left\{\begin{array}{ll} {\left[\widetilde{E}_{i}^{t+1}, \widetilde{M}_{i}^{t+1}\right],} & c_{i}^{t}>\tau_{n e x t} \\ {\left[E_{i}^{t}, M_{i}^{t}\right],} & c_{i}^{t} \leq \tau_{n e x t} \end{array}\right.
[Eit+1,Mit+1]={[E
it+1,M
it+1],[Eit,Mit],cit>τnextcit≤τnext

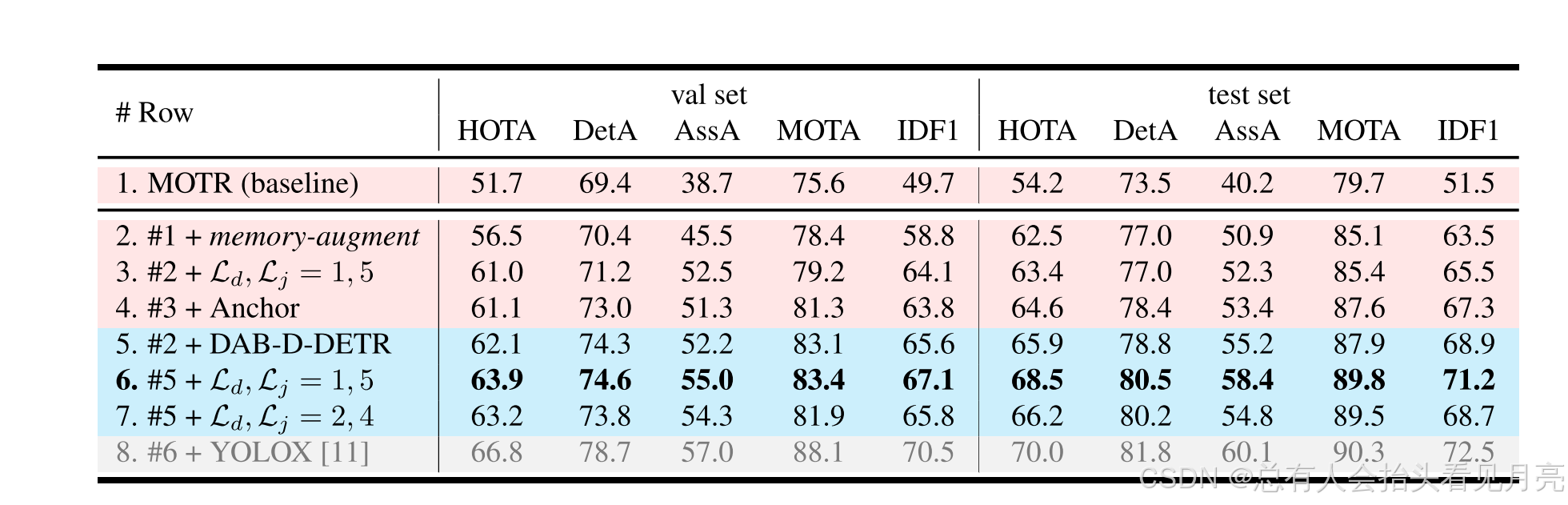
论文中也提到了将其阈值设置为0.5来进行实验的。实验的部分细节则涉及了:
-
我们在 DAB-Deformable-DETR [20] 上使用 ResNet50 [15] 主干构建了 MeMOTR,并使用官方 DAB-Deformable-DETR 初始化我们的模型
-
我们的实验主要在 8 张 V100-32 GB 上进行,不过在我们的开源仓库中,通过 PyTorch 官方的显存压缩技术(gradient checkpoint),所有实验也可以在 10 GB 以下的 GPU 上运行。



















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











