







行人检测数据集CrowdHuman简介,odgt标注格式转为yolo格式
一、引言
当前业内针对行人检测的数据集有很多,但针对实际场景中的遮挡目标的检测精度仍有待进一步提升。
二、CrowdHuman数据集简介
于是就找到了旷世公开的CrowdHuman数据集。地址:https://www.crowdhuman.org/。该数据集的中文摘要如下:
**近年来,人类检测技术取得了显著进展。然而,在高度拥挤的环境中,人体检测仍面临遮挡问题,且现有的人体检测基准在代表人群场景方面仍显不足。为了解决这一问题,本文介绍了一个新的数据集——CrowdHuman1,以便更好地评估人群场景中的检测器。CrowdHuman数据集规模庞大,注释丰富,具有高度的多样性。该数据集包含47万个人体实例,训练和验证子集中每张图片平均有22.6个人,且包含各种遮挡情况。每个人体实例都配有头部边界框、可见区域边界框和全身边界框的注释。
本文还介绍了基于CrowdHuman数据集的基线性能,展示了最先进的检测框架。在跨数据集泛化的实验中,CrowdHuman在多个之前的数据集(如加州理工学院数据集、CityPersons和Brainwash)上表现出色,取得了领先的性能,无需复杂的特征工程。我们希望CrowdHuman数据集能够作为一个坚实的基准,推动人类检测任务的未来研究。**
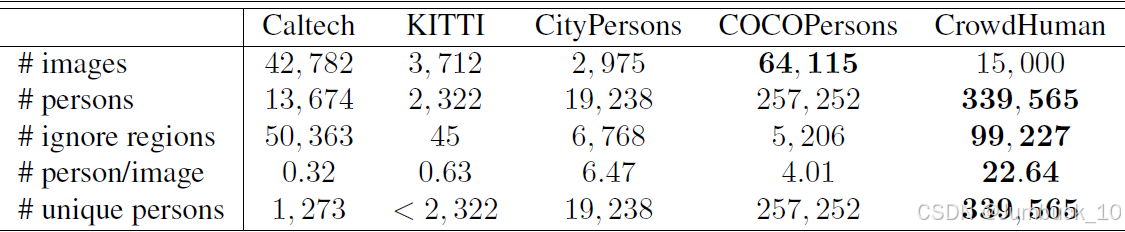
该数据集的图像样本数和图像中的遮挡目标很多,比较适用于实际场景。


三、odgt格式转成yolo格式
但是该数据集的标注格式是odgt的,找了很多文章但是都没法解决,要么是转化格式出错,要么是转成的yolo格式的标注数据没有归一化,网上目前开源的转换源码都没法用。
因为我这边只需要检测人员(person),所以干脆就自己写了一个,直接把odgt的标注数据转化到一个文件夹下,生成对应的txt标注数据,
代码如下:
(
大家只需要改这三处路径即可
odgt_path = odgt后缀的文件位置;
output_dir = 输出的txt文件夹的位置;
img_path = 图像文件夹位置(需要找到原图的尺寸以此计算txt文件归一化后的值)
)
import os
import json
from PIL import Image
def load_func(fpath):
"""
Load and parse ODGT file
"""
assert os.path.exists(fpath), f"File not found: {
fpath}"
with open(fpath, 'r') as fid:
lines = fid.readline 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









