




导 读
🚨 当数据开始「说谎」:这些场景正在发生
-
💸 金融市场:高频交易中0.1秒的异常波动,可能吞噬千万级资金
-
🏭 工业产线:温度传感器0.5℃的微妙偏移,或是设备爆炸的前奏
-
🏥 医疗监测:心电图上一个看似无害的波形畸变,可能预示致命性心律失常
但致命问题在于:这些异常往往不是简单的「离群点」,而是深藏在复杂时间模式中的**「变色龙」**——它们只在特定上下文(设备启动阶段、节假日流量高峰)现形,让传统检测方法难以检测!
🔥 传统方法为何沦为「工业瞎子」?三大死穴全解剖
| 检测维度 |
ARIMA |
孤立森林 |
3σ法则 |
| 非线性突变 |
完全失效 |
随机误报 |
连续误判 |
| 上下文感知 |
零感知能力 |
局部失效 |
全局盲区 |
| 多变量关联 |
单变量局限 |
维度灾难 |
孤立检测 |
💡 血泪教训:某风电集团因齿轮箱温度-振动-电流的耦合异常未被及时捕获,导致21台机组连环故障,直接损失超2.3亿!
⚡ KANs:一个数学定理掀起的工业革命
1957年埋下的种子:Kolmogorov-Arnold定理证明——任何复杂函数都可拆解为简单函数的组合,这一数学圣杯在66年后终于绽放工业光芒
三大破局利器:
-
动态函数乐高:每条神经网络连接独立学习激活函数,像拼乐高般动态重组检测逻辑
-
时空多尺度透镜:
-
浅层网络捕捉毫秒级毛刺(如传感器噪声)
-
深层网络解析设备生命周期曲线(如轴承磨损趋势)
-
可解释决策树:可视化函数组合路径,让「黑箱决策」变为可追溯的故障诊断报告
-
代码已开源,有需要的朋友关注公众号【小Z的科研日常】,获取更多内容。
01、技术背景
柯尔莫哥洛夫-阿诺德表示定理指出,任何多元连续函数都可以表示为单变量连续函数与加法的有限和与组合。KAN 可以表示为,对于任何连续函数,存在 q 和 ψpq 的连续函数 ϕ,使得:.
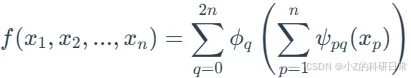
该定理为柯尔莫哥洛夫-阿诺德网络提供了理论基础,该网络通过组合和求和单变量函数来近似复杂的多变量函数。这使得 KAN 中的激活函数可以在网络边执行,从而使激活函数“可学习”并提高其性能。
为什么使用 KAN 进行时间序列异常检测?
以下是 KAN 适用于时间序列异常检测的几个原因:
1. 通用函数近似:KAN 可以近似任何连续函数,使其能够准确地模拟正常时间序列数据中的底层模式。
2.对异常的敏感性:异常是指与正常模式的偏差。KAN 能够精确模拟正常行为,因此对此类偏差非常敏感。
3. 分层特征学习:通过堆叠层,KAN 可以捕获局部和全局模式,这对于检测不同类型的异常(点、上下文和集体)至关重要。
02、数据准备与构建
本教程将展示如何对合成数据运行基于 KAN 的时间序列异常检测。
我们首先将连续时间序列分割成窗口,每个窗口捕获一个特定的数据点窗口,其中包含正常模式和潜在异常。
窗口化是一种将连续的时间序列数据分割成更小、更易于管理的块(称为窗口或段)的技术。
每个窗口捕获时间序列的特定部分,从而允许模型分析该部分内的模式和依赖关系
我们将使用重叠窗口,即窗口间隔重叠。这样可以更准确地检测异常,并有助于学习 KAN 跨越多个窗口的时间依赖性。
然后根据窗口中是否存在任何异常行为将这些窗口分为不同的类别。
类别定义:
-
正常窗口(类 0) :不包含任何异常的窗口。
-
异常窗口(第 1 类) :包含至少一个异常的窗口。
我们确保使用这些类标记窗口,以在我们的项目(训练、验证、测试)的每个数据集中保持异常窗口数量的平衡。
为了平衡每组数据的异常窗口数量,我们使用 SMOTE(合成少数类过采样技术)。该技术生成少数类(异常)的合成样本来平衡数据集,确保模型在训练期间收到两个类的足够示例。
为了有效地从这些数据中学习,模型处理每个窗口,通过多层基于傅里叶的变换提取复杂的时间特征,从而增强其识别预期模式的细微偏差的能力。
通过对这些结构化片段进行训练,KAN 模型学会区分典型序列和异常序列,从而能够准确识别新的、未见过的数据中的异常。
我们将使用这组库:
- PyTorch:用于构建和训练神经网络。
- NumPy:用于数值计算。
- Scikit-learn:用于评估指标和数据预处理。
- Matplotlib:用于数据可视化。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import random
from sklearn.metrics import (
precision_score,
recall_score,
f1_score,
roc_auc_score,
precision_recall_curve,
roc_curve,
auc,
)
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader以下是我们将针对该模型使用的参数。
关键参数:
-
window_size:时间序列上的滑动窗口的大小。 -
step_size:移动滑动窗口的步长。 -
anomaly_fraction:包含异常的数据窗口比例。 -
dropout:丢弃率,以防止过度拟合。 -
hidden_size:KAN 中隐藏层的大小。 -
grid_size:KAN层中使用的傅里叶频率的数量。 -
n_layers:模型中堆叠的 KAN 层数。 -
epochs:训练周期数。 -
early_stopping:训练期间提前停止的耐心参数。 -
lr:优化器的学习率。 -
batch_size:训练时每批的样本数量。
确保运行.seed()函数来验证此模型中使用的数字的随机性
class Args:
path = "./data/"
dropout = 0.3
hidden_size = 128
grid_size = 50
n_layers = 2
epochs = 200
early_stopping = 30 # Increased patience
seed = 42
lr = 1e-3 # Increased learning rate
window_size = 20
step_size = 10
batch_size = 32
anomaly_fraction = 0.1
args = Args()
args.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(args.seed)生成合成数据
我们的异常时间序列数据将按以下方式构建:
-
正弦波生成:我们使用创建正弦波
np.sin(x)。 -
异常注入:随机选择窗口中心并根据类型注入异常。
-
标记:创建一个标签数组来标记异常
我们将使用三种策略在正弦波时间序列中引入异常。
-
点异常:向单个数据点添加较大的随机噪声。
-
情境异常:特定 正弦值被随机因素放大。
-
集体异常:通过添加噪声来改变连续数据点的窗口 ,以模拟更大的群体级干扰。
将异常插入正弦波中随机选择的位置,并创建附带的标签数组,标记异常的位置。
生成具有异常的正弦波后,我们使用StandardScalerscikit-learn对时间序列进行规范化和缩放。
def generate_sine_wave_with_anomalies(
length=5000, anomaly_fraction=0.1, window_size=20, step_size=10
):
x = np.linspace(0, 100 * np.pi, length)
y = np.sin(x)
labels = np.zeros(length)
window_centers = list(range(window_size // 2, length - window_size // 2, step_size))
num_anomalies = int(len(window_centers) * anomaly_fraction)
anomaly_centers = np.random.choice(window_centers, num_anomalies, replace=False)
for center in anomaly_centers:
anomaly_type = np.random.choice(['point', 'contextual', 'collective'])
if anomaly_type == 'point':
y[center] += np.random.normal(0,&nb 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











