







文章目录
- Cross-X Learning for Fine-Grained Visual Categorization(by end-to-end)
- Learning a Mixture of Granularity-Specific Experts for Fine-Grained Categorization(by localization-classification subnetwork)
- Looking for the Devil in the Details:Learning Trilinear Attention Sampling Network for Fine-grained Image Recognition(TASN)(by localization-classification subnetwork)
- Learning Deep Bilinear Transformation for Fine-grained Image Representation(by end-to-end)
- Selective Sparse Sampling for Fine-grained Image Recognition(by localization-classification subnetwork)
- Weakly Supervised Complementary Parts Models for Fine-Grained Image Classification from the Bottom Up(by localization-classification subnetwork)
Cross-X Learning for Fine-Grained Visual Categorization(by end-to-end)
Abstract
目前的工作以一种弱监督的方式解决细粒度图像分类问题:首先检测对象部分,然后提取相应的部分特定特征以进行细粒度分类。
然而,这些方法通常孤立地处理每个图像的部分特定特征,而忽略他们之间的关系。
本文提出了Cross-X学习,这是一种简单而有效,它利用不同图像之间的关系以及不同网络层之间的关系来实现鲁棒的多尺度特征学习。
本文的方法包括两个新的组成部分:
- 一个跨类别的跨语义正则化器,它引导提取的特征来表示语义部分;
- 一个通过匹配多个层的预测分布来提高多尺度特征鲁棒性的跨层正则化器;
Introduction
弱监督FGVC主要有两种方法,其一是利用细粒度标签之间的关系来调整特征学习;其二是定位有区分度的局部来进行特征的提取。
与基于标签关系的方法相比,基于定位的方法具有从局部提取细粒度特征的优点。
早期的基于定位的方法为了获得局部检测器,一般先训练DCNN特征获得用DCNN的隐式表示,然后提取局部的特征进行细粒度分类。
目前的方法将这两个阶段合并为一个端到端的学习框架,利用最终的目标同时优化局部定位和细粒度分类。
但是这些方法在每幅图像独立地定义语义部分而忽略了来自不同图像的局部特定的特征之间的关系。虽然《Multi-attention multi-class constraint for fine-grained image recog-nition》这篇文章提出基于soft attention的模型来探索局部之间的关系。
本文提出了交叉X学习,他利用不同图像之间以及不同网络层之间的关系来实现鲁棒的细粒度识别。与《·》类似的是,本文的方法首先通过多个激励模块生成attention region features,但是它进一步涉及了两个新的组件:cross-category cross- semantic regularizer(C3S)和cross-layer regularizer(CL)。
C3S来引导来自不同激发模块的注意力特征来表示不同的语义部分。
具体来说,理想情况下,相同语义部分的注意力特征应该比不同语义部分的注意力特征更相关,效果如橘色框所示。

于是C3S的工作原理就是最大化由同一激励模块提取的注意力特征之间的相关性,同时去相关由不同激励模块提取的注意力特征。
同时,本文利用不同网络层之间的关系进行鲁棒的多尺度特征学习。
为了进一步提高多尺度特征的鲁棒性,本文引入了CL正则化器,它通过最小化中层特征和高层特征的KL散度来匹配他们的预测分布。
Approach
Cross X learning包含两个部分,分别为C3S:利用不同图像之间的相关性来学习语义零件特征和CL:通过匹配不同层之间的预测分布来学习鲁棒特征。
总揽如下所示:
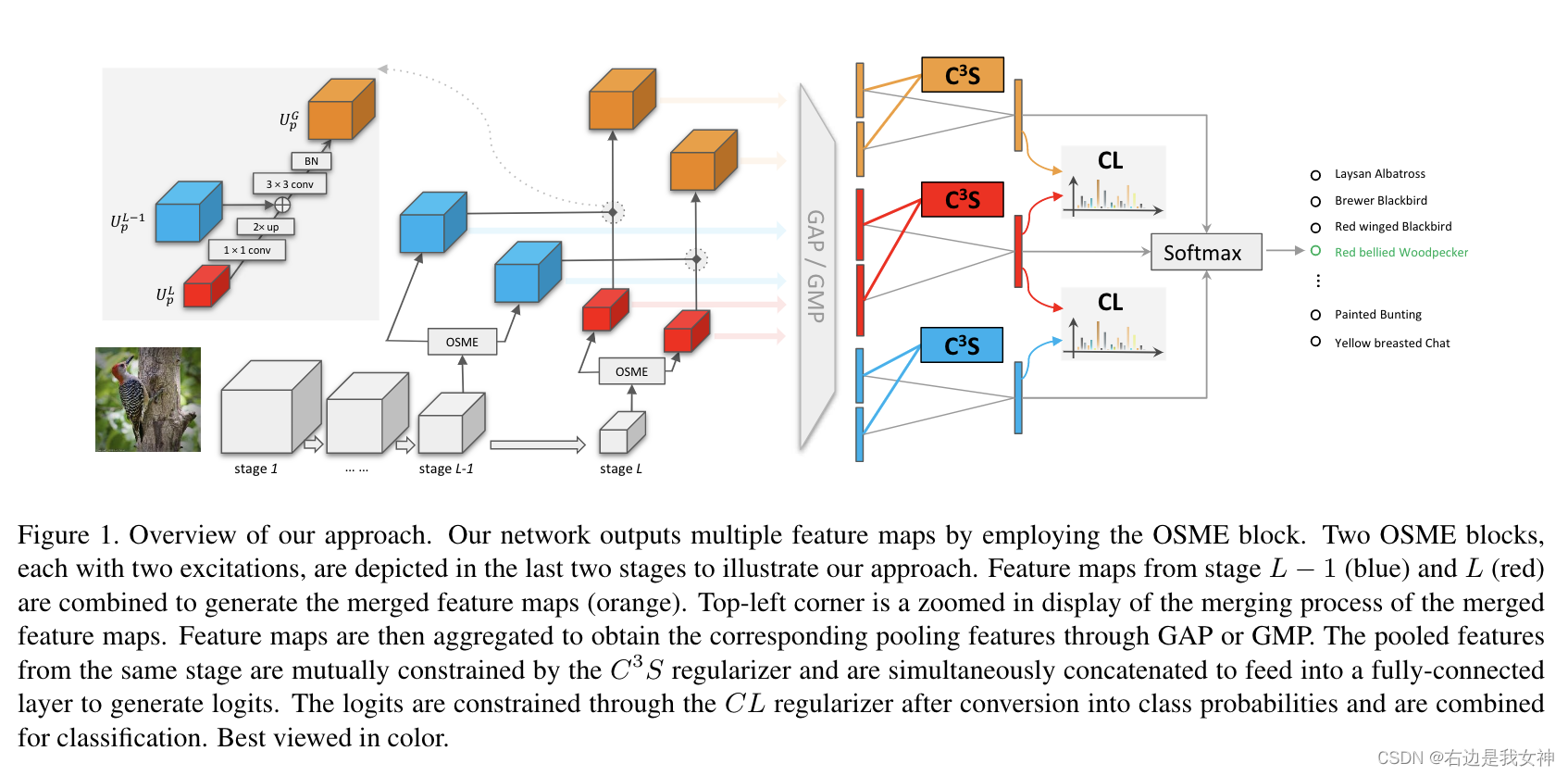
Preliminaries
OSME部分不再赘述。
虽然OSME部分可以生成attention- specific features,但是引导这些特征具有语义却是一个挑战。
原文通过优化度量损失来解决这个问题,将来自相同branch的attention feature拉近,来自不同branch的attention feature拉远。然而,优化这样的损失仍然是一个挑战,并且涉及到样本选择过程。
Cross- Category Cross-Semantic Regularizer
本文并不优化度量损失,而是提出通过探索不同图像和不同提取模块的特征图之间的相关性来学习语义特征。
我们希望从同一个激励模块中提取出的特征具有相同的语义,即使它们来自具有不同类别标签的不同图像。并且从不同激励模块提取的特征应该具有不同的语义,即使它们来自相同图像。
我们从OSME中得到了attention feature U p U_p Up。之后我们对其进行全局平均池化获得相应的池化特征 f p ∈ R C f_p\in R^C fp∈RC。然后进行l2归一化。接着对所有成对的激励模块形成一个矩阵:
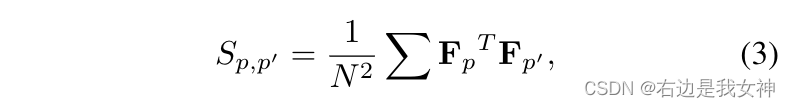
其中 F p = [ f p , 1 , . . . , f p , N ] ∈ R C × N F_p=[f_{p,1},...,f_{p,N}]\in R^{C\times N} Fp=[fp,1,...,fp,N]∈RC×N。N是样本的数量。
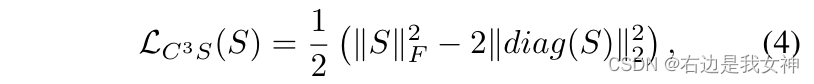
这里感觉怪怪的,如果两个F矩阵来自不同的激励模块,对角线应该表示的是同一样本在不同激励模块的特征,为了让不同激励模块的特征有不同的语义,不应该让他们的相关性小一些吗???
Cross-Layer Regularizer
利用CNN中不同卷积层的的语义特征是一个不错的选择。这在细粒度识别任务中最直接的策略是组合不同层的预测作为最终预测。这在本文的实验中被证明是不行的。
本文认为这其中的原因有两个:
- 中级特征对输入变化更为敏感,这使得它们在类内变化较大的情况下,对细粒度识别的鲁棒性较差;
- 没有利用特征预测之间的关系。
本文采用了特征金字塔(FPN)来整合不同层的特征,并提出了CL,通过匹配不同层之间的预测分布来学习鲁棒的特征。
其操作如图1所示,其中的 U G U^G UG集成了中间层精细空间分辨率的特性和顶层丰富的高级语义。
之后,采用KL散度,通过不同层的分布影响特征预测之间的关系:

U L U^L UL和 U G U^G UG之间也可以这么操作。
CL正则化器可以被视为一种知识蒸馏,其使用了来自 U L U^L UL的soft target来影响 U L − 1 U^{L-1} UL−1和 U G U^G UG。
Optimization
我们的最终预测通过组合三个feature maps 得到:
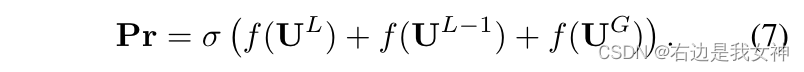
损失函数的话,除了对激励模块的损失和对不同层输出的蒸馏,我们还有对数据的分类损失,具体如下所示:
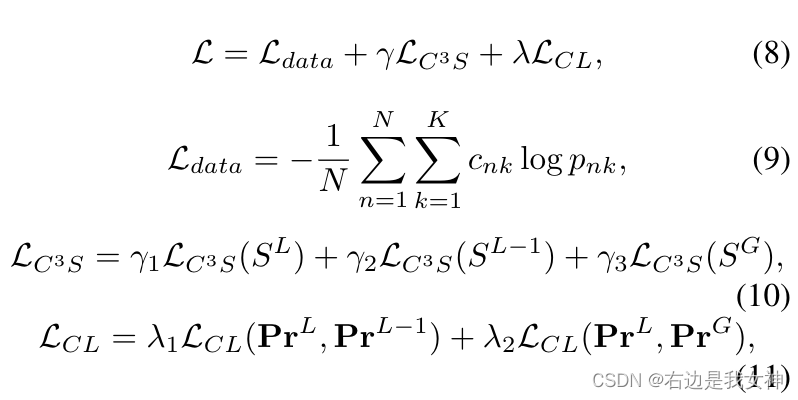
Learning a Mixture of Granularity-Specific Experts for Fine-Grained Categorization(by localization-classification subnetwork)
Abstract
本文的目的是将细粒度认知的问题空间划分为一些特定区域。为了实现这一点,本文开发了一个基于混合特性的统一框架。由于细粒度识别问题的可用数据有限,使用数据划分策略学习不同expert是不可行的。为了解决这个问题,本文结合专家逐步增强的学习策略和基于Kullback-Leibler分歧的约束来促进专家之间的多样性。
这些方法驱动专家从不同方面学习任务,使他们能够处理不同的子空间问题。
Introduction
本文基于混合的神经网络专家(ME)提出了一个统一的框架。
ME通常遵循分而治之的策略。早期的ME策略往往对独一无二的子集训练一个专家,但是由于子集较小,往往会导致过拟合的问题出现。
为了克服从有限的数据中学习不同专家的困难,本文引入了一个逐渐增强的策略以及KL散度约束来鼓励专家之间的多样性。
逐步增强策略的主要思想是,一个新的专家通过从以前专家哪里获得的额外的信息知识或先前的信息来学习,所以更加专业。
因此,需要考虑的是如何将与任务相关的知识传递给后来者。
本文从卷积模型中选择attention map作为知识的载体。因为它表明了神经网络如何将图像的某些区域和目标任务联系起来。
另一个促进专家多样性的方法是惩罚概率分布的相似性。这可以简单地通过最大化专家之间的KL散度来实现。
Related Works
Mixture of experts 基于分而治之原则建立。目前在FGVC领域有初步应用。
Approach
本文的方法包含几个专家和一个门网络。门网络用来结合这些专家作出最终的决策。
本文依据两个原则设计专家。
其一是为了更好地执行细粒度的识别,需要学习一个好的表示,其中要包含详细的信息。为了更好地实现,本文需提取大局部特征和小局部特征,专家根据它们的组合做出决策。
其二是专家可以产生先验知识来建立另一个专家。
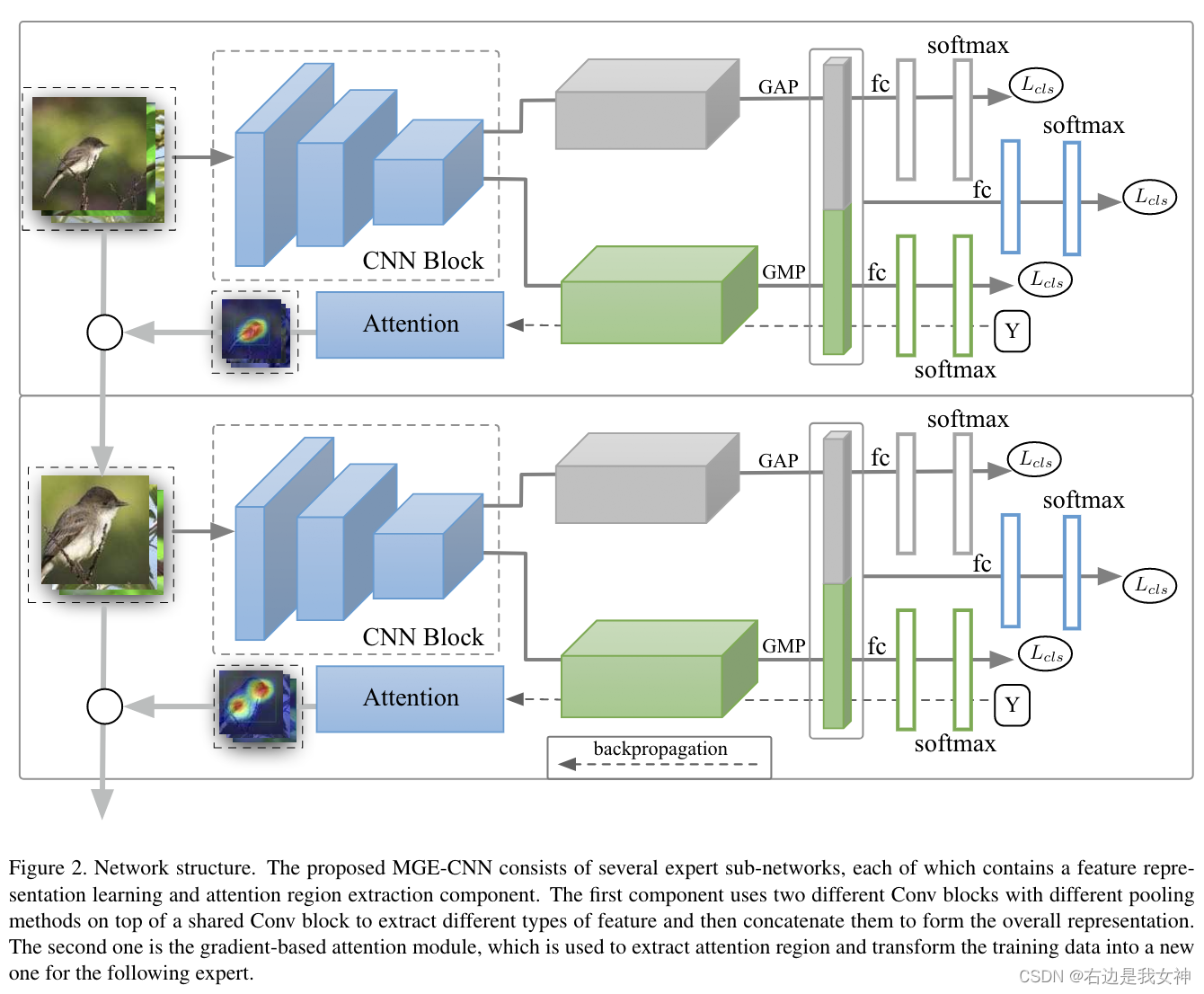
Experts for Fine-Grained Recognition
首先,我们需要建立一个强大的特征提取器。
对于专家 E t E_t Et,本文使用一个深度卷积模块以及全局平均池化来从large-part region f g t f_g^t fgt中提取特征。然后,本文用一个浅的卷积模块和一个全局最大池化来从small-part region KaTeX parse error: Double subscript at position 4: f_l_̲t中提取特征。
通过应用不同的全局池化方法,它们将会从相同的图像中学习到不同种类的特征。
最终的联合特征为 f t f^t ft,通过以下方式获得:
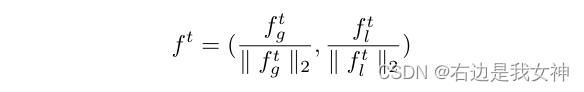
关于专家的分类损失主要包括两个辅助损失和一个决策损失:
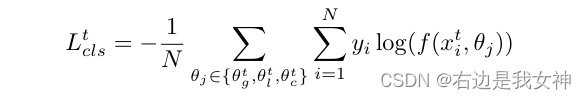
所有的损失都是交叉熵损失。每个样本对三种特征的输出结果算一个loss,最后除以样本数量。
后一个专家利用来自前一个专家的先验信息从数据中学习。先验知识通过基于梯度的注意力传递给后一个专家。本文构建注意力图的方式遵循Grad-CAM。该方法使用理想卷积层的梯度信息来理解每个神经元在决策中的重要性。
Grab CAM
Grad CAM可以画出网络的热力图(关注区域),用以研究网络的本质。
其整体流程如下所示:

得到classification vector之后,进行反向传播,得到A(feature map)中每个位置对结果的贡献。之后我们对每个通道进行全局平均池化,得到权重。接着,根据权重与feature map进行梯度map的一种压缩。最后进行一些relu、normalization的处理即可得到热力图。
我们回到本文。
对类别c、第k个通道的权重计算如下所示:
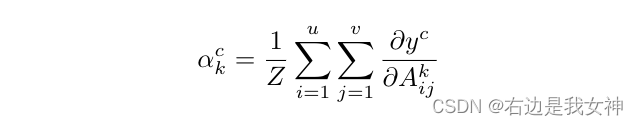
在全局池化之前,先进行ReLU操作:
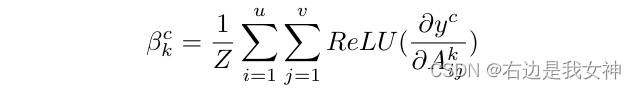
于是,专家
E
t
E_t
Et能够被表示为:
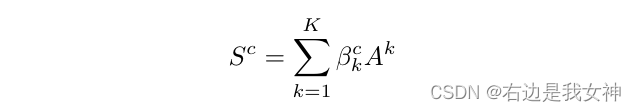
得到attention map之后,通过在0和1之间缩放来进一步标昏花:
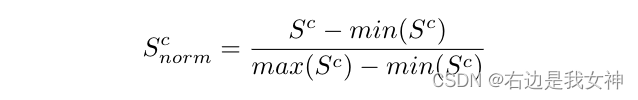
将attention map采样到输入图像大小。
在训练阶段,我们反向传播gt来计算注意力图,在测试阶段因为无法访问gt,于是采用预测的标签。
之后介绍如何将上一个专家的先验知识传递给下一个专家:
给定attention map(热力图),本文使用类似弱监督局部化技术为下一个专家构建输入,这样做是为了包含更多有效区域,而不是只检测部分区域:我们选择覆盖最大的连通区域得到bounding box,然后根据边界框的坐标进行裁剪。
这一部分的思路跟RA-CNN如出一辙。
KL-Divergence
为了促进专家之间的多样性,本文引入基于KL散度的约束来惩罚输入图像上产生相同概率分布的专家。
KL散度如下表示:
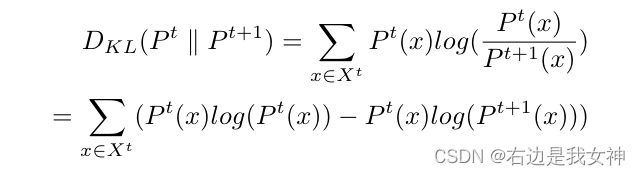
由于训练数据有限,每个专家都倾向于做出一个非常有把握的预测,产生一个one-hot向量。
这样的结果并不反映模型对数据固有结构的描述。因此,我们删除最大值,并将其归一化为新的分布。该分布更好地反映了模型对数据的描述。所以说,最大化这两种分布的KL散度相当于鼓励这两种模型对数据有不同的描述。
具体来说,模型做了如下的操作:
首先构建一个binary mask:
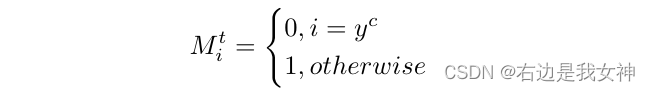
这也可以看做一个门控操作来选择分布进行优化。
于是,基于KL散度的约束如下所示:

然后,损失函数可以表示为:
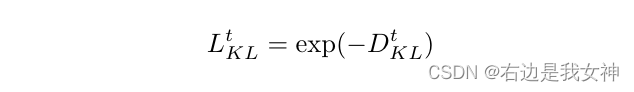
就是说,除了class element其他部分的差距都要尽可能得大。
Mixture of Experts
最终的优化目标如下所示:
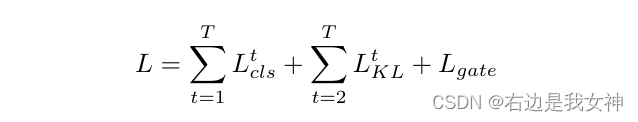
第三项是门控损失函数,用于学习门控网络:
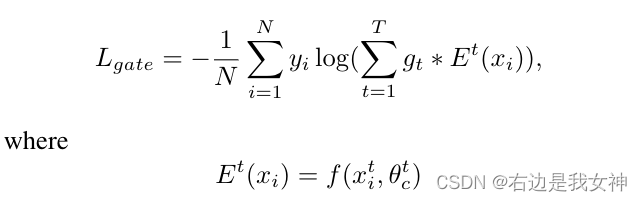
总结
整体框架其实和RA-CNN一致,只是attention采用了Grad-CAM提取的热力图来做。
本文的出发点应该是对ME类方法的一种推进,重点解决ME的过拟合问题。
Looking for the Devil in the Details:Learning Trilinear Attention Sampling Network for Fine-grained Image Recognition(TASN)(by localization-classification subnetwork)
Abstract
之前基于Attention的方法受限于局部数量多和计算复杂这两大问题,本文对此提出了新的模型TASN:
- 三线性注意力模块:通过对通道间关系进行建模来生成注意力图;定位细节
- 基于注意力的采样器:以高分辨率突出关注的部分;提取细节
- 特征提取器:通过权重共享和特征保存策略将部分特征提取为对象级特征。优化细节
Introduction
现有方法的大部分努力都集中在学习更好地表示这种细微而有区别的细节上。
现存的基于注意力的房啊或者基于局部的方法都尝试通过学习局部检测器、剪切并增强局部以及连接用于识别的局部特征来解决这一问题。
目前仍然有一些问题:
- attention的数量是限制的且预定义好的,这限制了模型的有效性和灵活度;
- 由于缺乏局部标注,很难学习多个一致的注意力映射(比如说每个样本的相同部分) ;
- 对每个局部学习CNN并不是高效的。
本文提出的TASN从数百个局部proposal中学习细节并且有效地将这些学习到的特征提取至一个集合中。
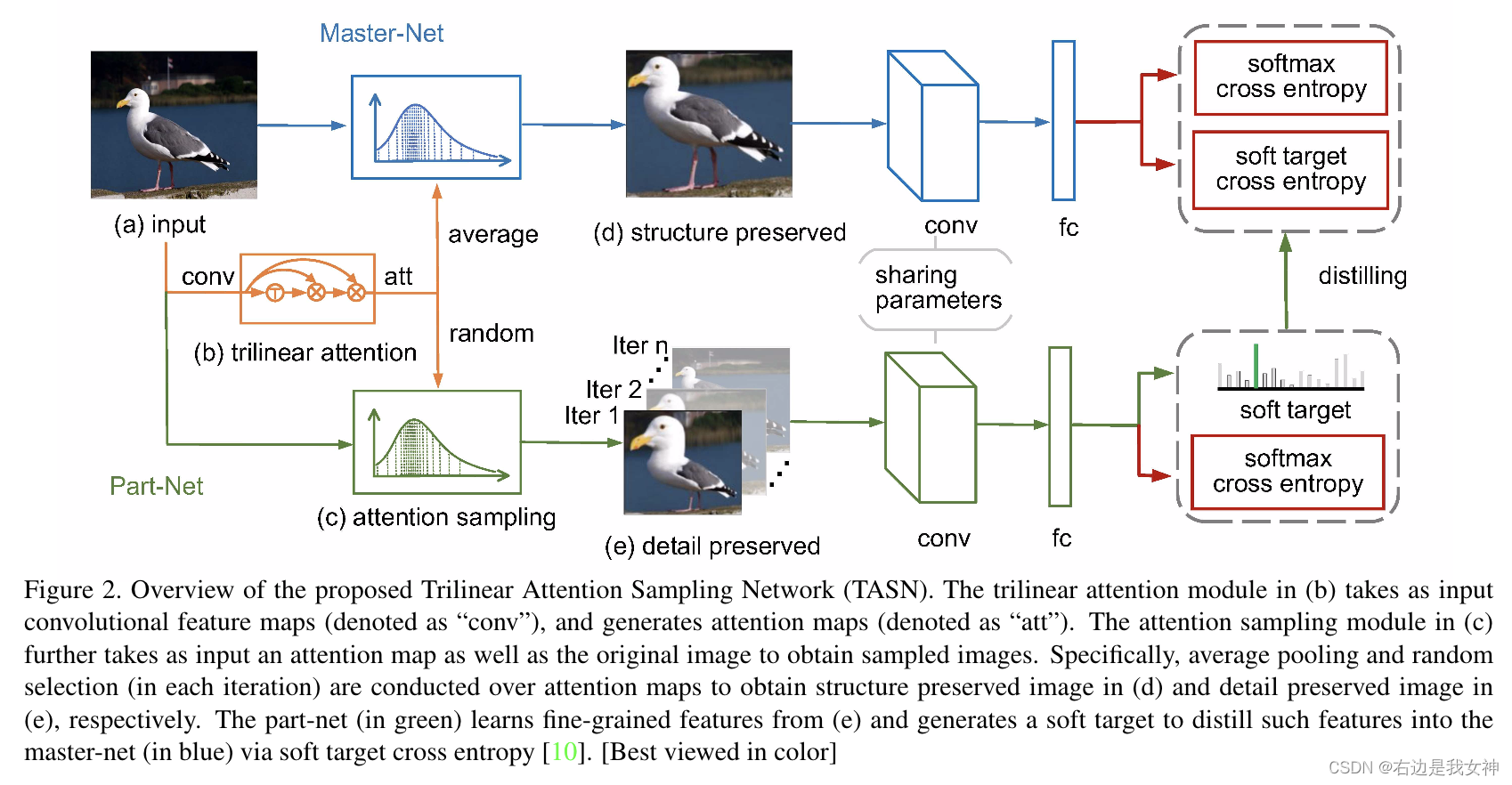
TASN由三个模块组成:线性注意力模块、基于注意力的采样器和特征提取器。
首先,三线性注意力模块以特征图为输入,通过self-trilinear product生成注意力图,这用它们的关系矩阵汇集了特征通道。由于feature map的每个通道都被转换为attention map,数以百计的局部proposals能够被提取。(什么是关系矩阵?为什么局部proposals就能被提取了?)
其次,基于注意力的采样器将attention map和图像作为输入,并以高分辨率“highlight”所关注的部分。对于每次迭代,基于注意力的采样器基于随机选择的attention map生成detail-preserved image,基于平均attention map生成structure- preserved image。前者学习特定部分的细粒度特征,后者捕捉全局结构并包含所有重要的细节。(什么是高分辨率?如何highlight?)
最后,局部网和主网可进一步表述为教师和学生的关系。局部网从detail-preserved image中学习细粒度特征并且将学习到的特征提取到主网中。
主网将structure-preserved image作为输入,在每次迭代中提炼特定的部分。这种提炼通过权重共享和特征保持策略来实现。(两种策略具体如何实现?)
值得注意的是,本文采用知识蒸馏的手段而不是简单地连接局部特征。这是因为局部数量多且并不是预定义的。
上述这些做法的优势在于:
- 可以实现随机细节优化,这使得从数百个proposals中学习细节变得实际可行;
- 实现有效推理,因为可以在测试阶段使用主网进行识别。
这项工作首次尝试从数百个局部proposals中学习细粒度特征。
Method
Details Localization by Trilinear Attention
卷积的每一个通道对应一个视觉模式,然而,由于缺乏一致性和鲁棒性,这样的特征图不能作为注意力图。
受到2017年的关于通道分组网络的影响,本文通过根据他们的空间结构汇集feature channels将feature map转变为attention map。
这一过程通过三线性公式实现,因此称为三线性注意力模块。
在得到attention map之前,本文首先用CNN进行特征提取。为了获得高分辨率的特征图,本文去除了resnet-18的两个下采样过程。此外,为了提高卷积响应的鲁棒性,本文添加了两组具有多个膨胀率的膨胀卷积层来增加感受野。
首先,本文对输入进行reshape: R c × h × w → R c × h w R^{c\times h\times w}\to R^{c\times hw} Rc×h×w→Rc×hw。
于是,三线性函数能够描述为如下:

其中 X X T XX^T XXT是一个双线性特征,表示了通道之间的空间关系。
为了使特征更加一致且鲁棒,本文进一步进行如上的点乘,于是我们可以获得三线性注意力图。
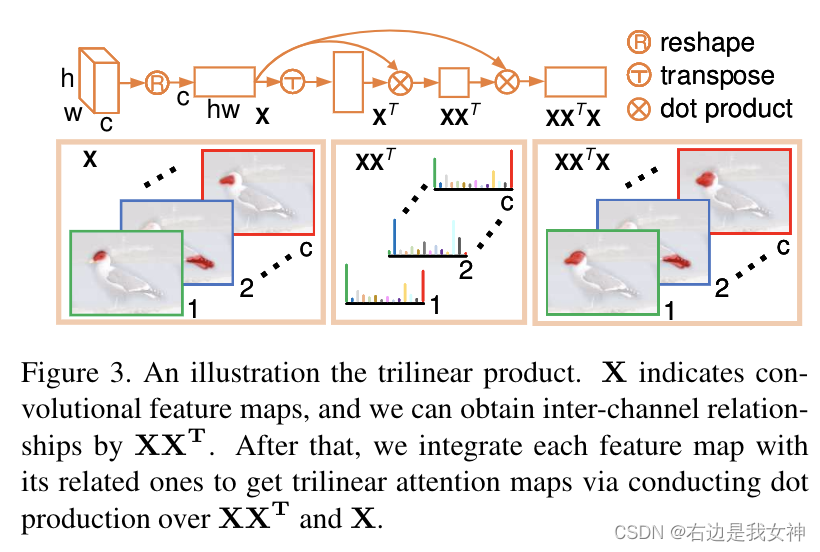
其实思想和通道分组网络差不多,不过通过三线性公式来实现这一功能。
本文进一步学习了不同的正则化方法来提升三线性注意力的有效性。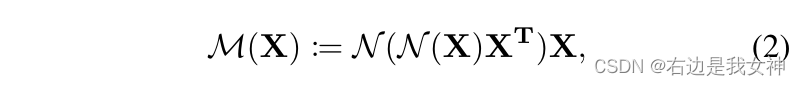
其中N表示softmax。第一个N保持每个通道有相同的规模。第二个则是关系正则化。
最后,我们将M reshape为原来的三维。
Details Extraction by Attention Sampling(Important)
通过对不同的attention map进行采样,可以得到不同类型的图:
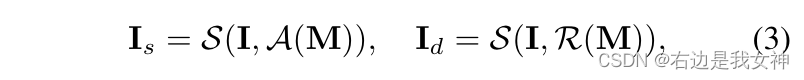
S指的是非均匀采样函数,A指的是通道之间的平均池化,R指的是从输入当中随机选择一个通道。
采样过程可以如下所描述:
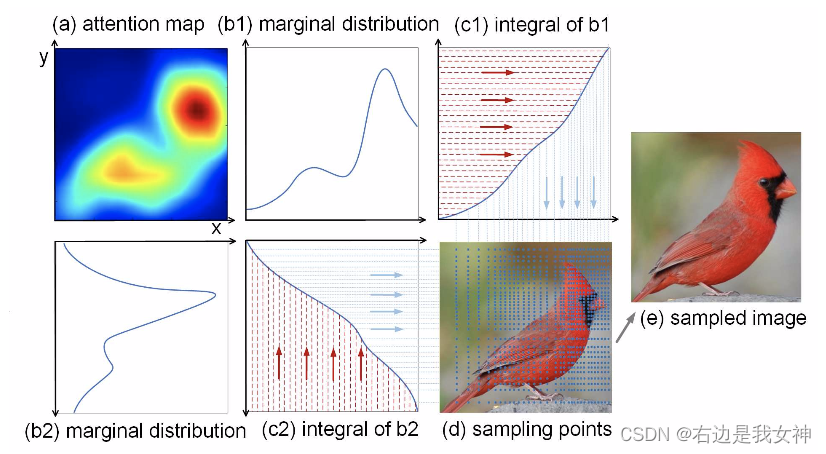
给定(a)中的注意力图,我们首先通过计算x轴(b1)和y轴(b2)上的最大值将地图分解成二维。然后获得(b1)和(b2)的积分,并分别显示在(c1)和(c2)中。我们进一步以数字方式计算(c1)和(c2)的反函数,即,我们在坐标轴上均匀采样点,并沿着红色箭头(如(c1)和(c2)所示)和蓝色箭头获得坐标轴上的值。
最终,我们对蓝色虚线的交点位置进行采样,得到(e),可以看到注意力矩阵所关注的位置得到了放大!
Details Optimization by Knowledge Distilling
该部分将detail-preserved image和structure-preserved image作为输入,并以蒸馏学习的方式将学习到的细节从局部网转移到主网中。
本文首先将两个图输入ResNet-50、fc以及softmax得到分类向量和概率向量
z
s
,
z
d
,
q
s
,
q
d
z_s,z_d,q_s,q_d
zs,zd,qs,qd,值得一提的是,softmax的步骤有些许特别:
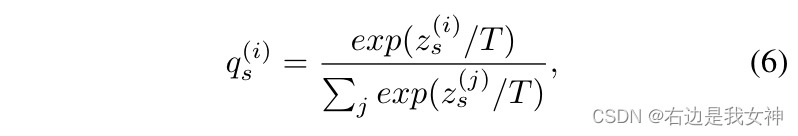
其中T是称为温度的参数,一般分类时,令其为1。一半会把T选得比较大,因为可以产生一个软的概率分布。
之后soft分类损失和hard分类损失作为损失函数:
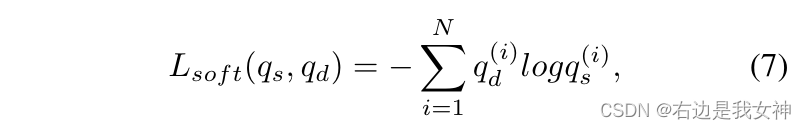
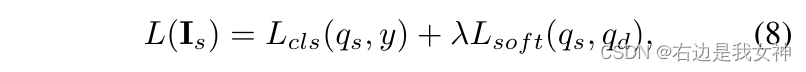
基于注意力的擦洋气在每次迭代中随机选择一个部分,所以所有的细粒度细节都可以在训练中被提取到主网络中。
总结
本文围绕CNN的图像模式出发,将传统的通道分组网络替换为三线性公式,以此得到紧凑的局部注意力map;
之后,本文最大的亮点在于其将这个attention map回头用于修改raw image以此放大一些关键部位;
最后,对修改后的图像进行特征提取以得到分类结果,其中更是融入了蒸馏学习的思想。
因为每次的detail-preserve image都只放大一个部位,所以主网每次都能学习一个部位,于是随着训练数量的增加,自然主网可以学到数以百计的局部特征。
Learning Deep Bilinear Transformation for Fine-grained Image Representation(by end-to-end)
Abstract
本文提出了深度双线性变换块,可以在卷积神经网络中深度堆叠以学习细粒度图像表示。DBT块可以将输入通道均匀地划分为几个组,由于双线性变换可以通过计算每组内的成对相互作用来表示,因此可以大大降低计算成本。
通过将组内双线性特征与来自整个输入特征的残差进行聚合,进一步获得每个块的输出。
Introduction
可以在多个层中学习成对的交互以增强特征识别能力;
通过学习语义组和计算组内双线性变换,模型仅在最具判别性的特征通道内获得成对的交互。
Selective Sparse Sampling for Fine-grained Image Recognition(by localization-classification subnetwork)
Abstract
本文提出了选择性稀疏采样模块(Selective Sparse Sampling)用以捕获多样的、细粒度的特征。
采用卷积神经网络实现,缩写为S3Ns。
在图像级的监督下,S3Ns从类响应映射中收集一些峰值(局部最大值)来估计信息感受野,然后学习一系列稀疏的注意力以捕捉细节的、视觉的证据以及保护上下文。
这样一种证据是是有选择地进行采样的,显著丰富了可学习的特征并且引导网络发现更多的微小的线索。
先前的文章对局部区域直接进行crop,破坏了相应的上下文信息,本文则提出将局部特征放大的同时保留周边环境信息。
Weakly Supervised Complementary Parts Models for Fine-Grained Image Classification from the Bottom Up(by localization-classification subnetwork)
Abstract
图像级标签训练的深度卷积网络往往只关注最具分辨力的部分,而忽略其他可以提供信息的对象部分。
本文以弱监督的方式建立互补局部模型,检索由卷积神经网络检测到的主要目标的局部所抑制的信息。
给定图像级的标签,首先提取粗糙的目标实例,采用Mask R-CNN和基于CRF的分割来执行弱监督目标检测与实例分割。
然后在尽可能保持多样性的原则下,对每个对象实例估计和搜索最佳部分模型。
最后构建双向LSTM,将这些互补部分的局orization(by localization-classification subnetwork)
Abstract
有区分度的区域的定位对于细粒度视觉分类是很关键的,这有两个问题:
- 哪些区域有区分度并且有足够的代表性与其他子类别进行区分;
- 要实现最佳分类性能,需要多少区域。
本文提出了多尺度和多粒度深度强化学习方法。该方法学习多粒度区分区域注意力和基于多尺度区域的特征表示。主要贡献如下所示:
- 提出了多粒度区分定位,通过两阶段深度强化学习方法来定位区分,该方法以分层方式发现具有多粒度的区分区域,并以自动和自适应的方式来确定区分区域的数量;
- 多尺度表示学习有助于定位不同尺度的区域,并对不同尺度的图像进行编码,从而提高细粒度视觉分类性能;
- 提出语义奖励功能,通过在奖励功能中联合考虑注意力和类别信息;
- 进一步探索无监督的有区分性定位。
















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











