






前情提要
torch_npu框架不支持多线程自动set_device
报错详情
直接使用transformers的TextIteratorStreamer进行流式推理,会报错
Exception in thread Thread-6:
Traceback (most recent call last):
File "/root/anaconda3/envs/AI/lib/python3.9/threading.py", line 954, in _bootstrap_inner
self.run()
File "/root/anaconda3/envs/AI/lib/python3.9/threading.py", line 892, in run
self._target(*self._args, **self._kwargs)
File "/root/anaconda3/envs/AI/lib/python3.9/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/root/anaconda3/envs/AI/lib/python3.9/site-packages/transformers/generation/utils.py", line 1403, in generate
and torch.sum(inputs_tensor[:, -1] == generation_config.pad_token_id) > 0
RuntimeError: getDevice:torch_npu/csrc/aten/common/CopyKernel.cpp:41 NPU error, error code is 107002
[Error]: The context is empty.
Check whether acl.rt.set_context or acl.rt.set_device is called.
EE1001: The argument is invalid.Reason: rtGetDevMsg execute failed, reason=[context pointer null]
Solution: 1.Check the input parameter range of the function. 2.Check the function invocation relationship.
TraceBack (most recent call last):
ctx is NULL![FUNC:GetDevErrMsg][FILE:api_impl.cc][LINE:4686]
The argument is invalid.Reason: rtGetDevMsg execute failed, reason=[context pointer null]
设置好generation_config后,报错变为
Exception in thread Thread-6:
Traceback (most recent call last):
File "/root/anaconda3/envs/sakura/lib/python3.9/threading.py", line 954, in _bootstrap_inner
self.run()
File "/root/anaconda3/envs/sakura/lib/python3.9/threading.py", line 892, in run
self._target(*self._args, **self._kwargs)
File "/root/anaconda3/envs/sakura/lib/python3.9/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/root/anaconda3/envs/sakura/lib/python3.9/site-packages/transformers/generation/utils.py", line 1411, in generate
streamer.put(input_ids.cpu())
RuntimeError: getDevice:torch_npu/csrc/aten/common/CopyKernel.cpp:41 NPU error, error code is 107002
[Error]: The context is empty.
Check whether acl.rt.set_context or acl.rt.set_device is called.
EE1001: The argument is invalid.Reason: rtGetDevMsg execute failed, reason=[context pointer null]
Solution: 1.Check the input parameter range of the function. 2.Check the function invocation relationship.
TraceBack (most recent call last):
ctx is NULL![FUNC:GetDevErrMsg][FILE:api_impl.cc][LINE:4686]
The argument is invalid.Reason: rtGetDevMsg execute failed, reason=[context pointer null]
为此咨询了transformers官方人员,issues-23042,但是他们无法处理

后来经过不断debug发现在threading.py的Thread函数中,执行run函数后self._kwargs中的参数均未传递成功
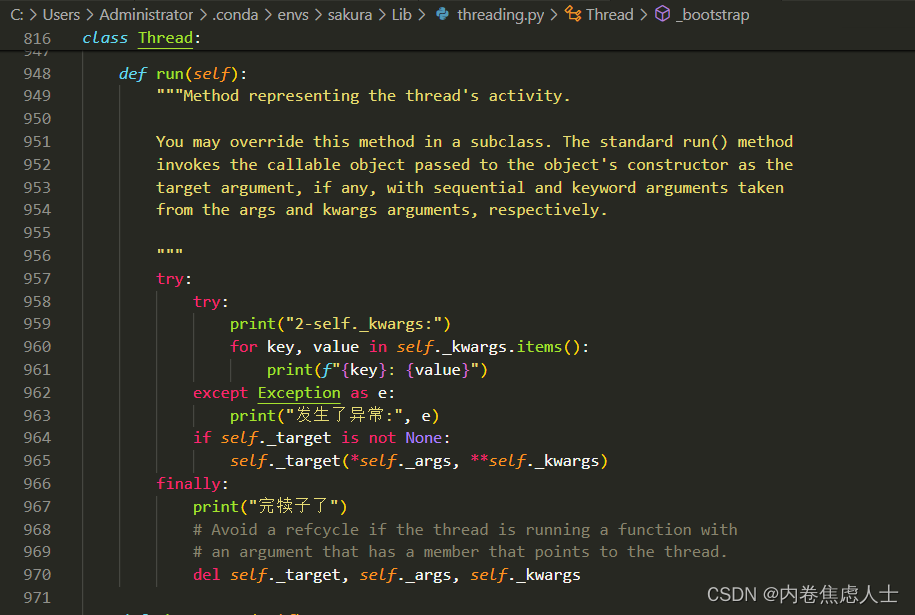
询问了torch_npu的官方人员
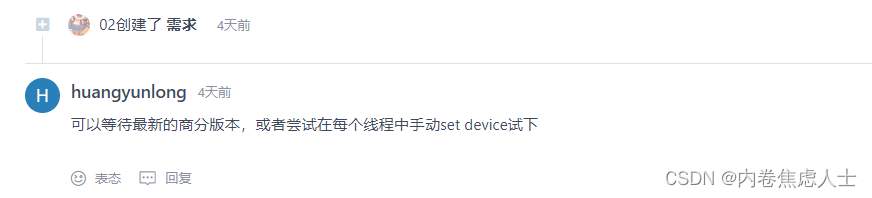
解决方案
在Thread函数中的target传入set_device
完整代码如下,以chatglm3-6b为例
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
torch_device = "npu:3"
torch.npu.set_device(torch.device(torch_device))
torch.npu.set_compile_mode(jit_compile=False)
option = {}
option["NPU_FUZZY_COMPILE_BLACKLIST"] = "Tril"
torch.npu.set_option(option)
import os
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer, AutoModel
from transformers import TextIteratorStreamer
from threading import Thread
model_path = "/root/.cache/modelscope/hub/ZhipuAI/chatglm3-6b"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True, device_map=torch_device)
model = model.eval()
def generate_with_npu_device(**generation_kwargs):
torch.npu.set_device(torch.device(torch_device))
model.generate(**generation_kwargs)
if __name__ == "__main__":
# TextIteratorStreamer实现
streamer = TextIteratorStreamer(tokenizer)
turn_count = 0
while True:
query = input("\n用户:")
if query.strip() == "stop":
break
inputs = tokenizer([query], return_tensors="pt")
input_ids = inputs["input_ids"].to(torch_device)
attention_mask = inputs["attention_mask"].to(torch_device)
generation_kwargs = dict(input_ids=input_ids,
attention_mask=attention_mask,
streamer=streamer,
max_new_tokens=512)
thread = Thread(target=generate_with_npu_device, kwargs=generation_kwargs)
thread.start()
generated_text = ""
position = 0
# 流式输出
for new_text in streamer:
generated_text += new_text
print(generated_text[position:], end='', flush=True)
position = len(generated_text)














 3455
3455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









