







文章目录
最近也是学习自动驾驶仿真相关知识,习惯去总结一下,方便自己回顾和总结,主要包括了自动驾驶框架和一些关于仿真方面的简单介绍,给想了解车企自动驾驶岗位的同学做一个初步普及,有写的不对的地方欢迎大佬前来指点orz
总的来说,仿真是自动驾驶方案的重点部分,无论是仿真开发还是仿真测试,都是为了实车相关部分的验证与落地。仿真开发的工作是为了去开发一套用于仿真测试的工具和算法。
QA仿真测试团队的使命是加速AD技术开发、测试验证与落地。在自动驾驶(AD)系统的开发流程中,仿真测试、模块测试与实车测试通过实施分层测试策略紧密协作,共同确保产品发布的质量和效率得以显著提升。为了实现这一目标,需要设计并构建了一套全面的仿真测试方案,包括丰富的测试场景集、科学的评价体系以及高效的自动化测试工具。
基础概念
自动驾驶级别
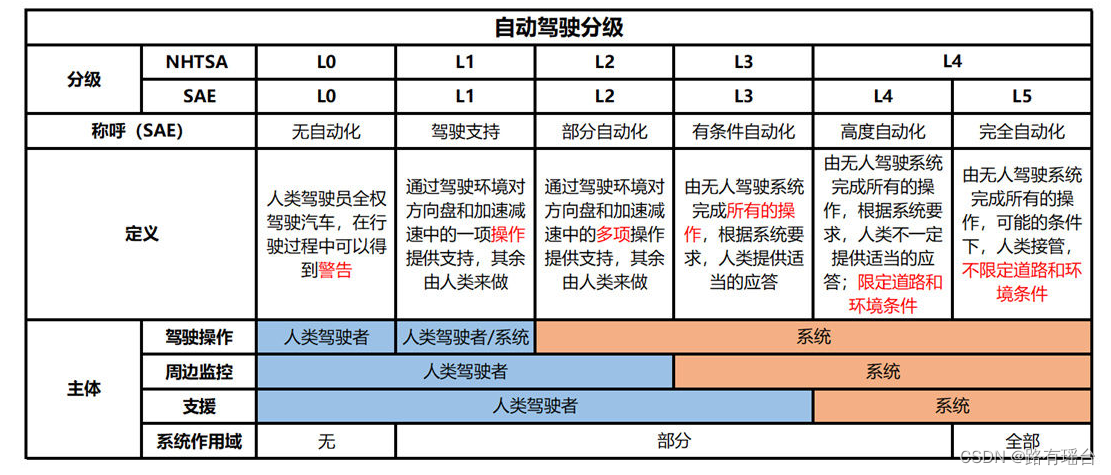
SAE是分为了L0~L5,根据不同程度,从零到完全自动化,共分为六个等级。
- L0级自动驾驶:
无自动,油门、刹车、方向盘全程皆由驾驶者掌控。 - L1级自动驾驶
主要还是由驾驶者操控车辆,但在特定的时候系统会介入,如ESP电子车身稳定系统或ABS防锁死刹车系统 - L2(部分自动驾驶)
部分自动化,驾驶者仍需专心于路况。第二级自动驾驶可说是目前各大车厂的主流,车辆的速度和转向可以在一定的条件下控制,但驾驶者仍需保持对路况的专注。 - L3(有条件自动驾驶)
相较于第二级,第三级自动驾驶可以在一定条件下驱动车辆,而不需要驾驶者专注于路况,双手甚至可以离开方向盘。但驾驶者仍需随时准备接管车辆。 - L4(高度自动驾驶)
高度自动化,车辆在启动自动驾驶后,计算机将在目的地设置后按自己的路线行驶,无需干预全面驾驶,但可能需要在特定区域(如高速公路或市区)进行干预。这一级别的自动驾驶技术仍处于研发阶段,市场上尚未有成熟的车型。 - L5(完全自动驾驶)
全自动化,第五级自动驾驶车辆将完全自动化,车上甚至不需要方向盘等驾驶机构,完全通过电脑感知与运算来驾驶车辆。不论任何环境、路况,都不需要人类驾驶介入操控。
如上述,自动驾驶一直有两条路线,一条是L2->L4的渐进式路线,典型公司是特斯拉和多数车企,一条是直接L4路线,典型公司是谷歌旗下的Waymo以及国内的百度、小马等公司。
渐进式路线的思路是,做事要一步步来,每一步都要实现商业价值,支撑着技术的演进,否则很容易路子太长,走不到最后。而直接L4路线的公司则认为,渐进式路线为了提前商业化,需要做太多的“无用功”,绕太多的弯路,他们认为自动驾驶的成败不在于前边谁抢占了乘用车市场,而在于谁先能真正做到完全不需要人来开车,如果做到了这一点,就可以通过运营无人驾驶出租车的方式,靠低人力成本先抢占出租车市场,再进一步的,无人出租便宜又方便之后,它甚至可以挤压掉私家车的市场份额。
再稍提一下ODD是什么?
ODD的概念来自于SAE J3016中的定义,它将ODD定义为“特定驾驶自动化系统或其功能专门设计的运行条件。任何一台自动驾驶车辆,都必须有一定限定的工况。
ODD运行设计域(Operational Design Domain),代表了自动驾驶汽车的预期操作范围,包括交通状况、道路类型、天气等因素。定义涵盖了自动驾驶系统在设计时所确定的本车状态和外部环境,这些环境因素包括速度、道路、交通、天气、光照等。
简单来说,ODD就是要定义好在哪些工况下是能够自动驾驶的,脱离了这些工况,自动驾驶就不能保证工作。任何一台自动驾驶车辆,都必须有一定限定的工况。
ODD的范围越广,自动驾驶系统的适用性就越高,但在确定ODD时需要考虑各种复杂的因素,如不同的道路类型、交通情况、天气状况等,这些都会影响自动驾驶系统的表现。ODD是自动驾驶技术的重要组成部分,因为它决定了自动驾驶汽车在何种情况下可以安全地运行。在实际应用中,ODD的确定是非常困难的,因为自动驾驶系统需要在各种复杂环境中运行,确定ODD需要考虑各种可能情况。
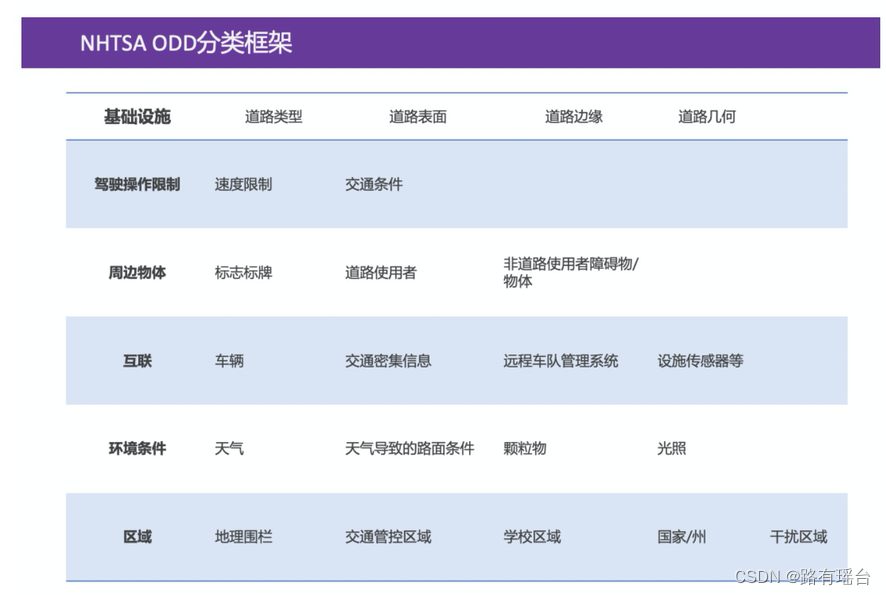
通过对于这六大要素的划分,可以较为清晰地定义出自动驾驶系统可以运行的工况及范围。
可以说,ODD的场景分类给予非L5级别的自动驾驶非常明确的场景定义以及测试标准,可以极大程度上保障驾驶员在使用这些自动驾驶功能时的安全性。根据不同场景的业务需求进行合理地ODD设计以及测试已经成为了所有自动驾驶企业们着重关注的目标。
ODD的划分标准与框架都有相关的标准可以清晰定义,那么在对ODD场景进行分类之后,如何去测试这些ODD的边界来判断现有的自动驾驶系统是否合格达标呢?
我们知道,自动驾驶汽车的开发满足V字开发模型,在V字开发模型中,涉及的测试方法主要包括软件在环(SIL,即software-in-loop)、硬件在环(HIL,即hardware-in-loop)、车辆在环(VIL,即vehicle-in-loop),再到最后的整车场地、道路测试等方法,涵盖了从零部件到系统再到整车的全链条验证。在测试内容方面,主要包括传感器、执行器、算法、人机界面测试以及整车功能等内容。
在环测试,借助虚拟现实数据生成、传输与交互技术,模拟自动驾驶汽车在真实道路环境行驶,并通过概率分布的危险场景强化模拟方法,进行的自适应加速测试。通过在环测试,可以在大幅节约测试时间和成本的同时,给虚拟测试提供了验证结果,并为实际道路测试提供了较为真实的参考数据。
传统来说自动驾驶几大核心团队
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2582
2582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









