






初试基于ONNX Runtime的C++部署pytorch深度学习模型(典型图像分类模型ConvNeXt为例)
前言
最近开始接触深度学习模型部署相关的知识,主要是pytorch构建的模型如何部署在C++上使用这方面的。查询了目前主流的部署方案,其中下面这篇关于OpenCV DNN、ONNXRuntime、TensorRT以及OpenVINO四种方式比较的文章相对细致的对各方案进行了比较。
https://www.cnblogs.com/shaoxx333/articles/16630781.html
文中主要结论如下图:

由于已经安装了opencv,本着“配置环境尽量简单”的偷懒原则,我的第一选择是Opencv DNN😂,然而后面的尝试并不顺利,dnn在加载onnx权重文件出现异常中断,后来具我分析,这可能与Opencv DNN对一些较新的算子不兼容有关。ConvNext相对于之前的卷积神经网络添加了一些运算技巧。再在网上下载了Yolov5的onnx权重,能够加载成功,这也佐证了我的思考。
最终选择另一个兼具CPU/GPU推理能力的ONNX Runtime进行C++部署,以下记录整个onnx保存到部署推理成功的过程和主要代码,供各位参考。
前期工作包括:VS / C++ opencv / python / python opencv / Pyahram / pytorch / CUDA等必要环境需要配置好。毕竟本文的重点在部署,而不是构建模型。
ConvNeXt网络概述和onnx模型权重文件保存
ConvNeXt是于2022年初发布的一种性能极高的卷积图像分类神经网络。其性能甚至超越同时代的Transfromer。当然,本文不讨论网络的具体构成,有兴趣了解的同学可以参考以下链接,b站up主 霹雳吧啦Wz 对此有详细的讲解。我们可以理解为它是一个输入为(n,3,224,224)维张量,输出为(n,5)张量的黑盒。(因为源码默认是对五个品种花的图片进行分类)。如果各位手里已经有其他在用的模型了,也可以用自己的模型,不一定非要用ConvNeXt。
https://www.bilibili.com/video/BV1SS4y157fu/?spm_id_from=333.337.search-card.all.click&vd_source=d8ac0ff430c94b044512c4edabc63f35
源码下载地址:
https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/ConvNeXt
配置相关环境并下载对应的数据集之后即可进行训练。训练结束后即可在生成的weight文件夹下面得到best_model.pth权重文件。到此,模型的训练工作结束,接下来开始导出onnx格式的权重文件。
为方便操作,在predict.py文件中的约47行(model.eval()语句下方)添加以下代码:
# 保存onnx模型
# 定义输入张量和输出张量
input_tensor = torch.randn(1, 3, 224, 224)
output_tensor = torch.randn(1, 5)
# 将模型导出为ONNX格式
torch.onnx.export(model, input_tensor, "./model.onnx", verbose=False, opset_version=12)
如此,运行predict.py即可在生成model.onnx权重文件的同时检查训练模型的准确性(关于predict.py加载的图片等细节我就不赘述了,相信各位是有能力处理加图片、改路径之类细节操作的)。运行成功后,即可在根目录下找到一个model.onnx。
权重文件验证
谨慎考虑,可以先在pytorch环境下加载一次model.onnx,并进行推理实验,证明这个权重文件是可用的。首先确保自己的python环境已经配置onnx和onnxruntime。
pip install onnx
pip install onnxruntime-gpu
在根目录下新建一个loadonnx.py文件。将以下代码复制进去:
import os
import json
import cv2
from torchvision import transforms
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision.models as models
import torch.onnx
import onnx
import onnxruntime
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# 加载ONNX模型
model = onnx.load("./model.onnx")
onnx.checker.check_model(model)
# 创建会话
session = onnxruntime.InferenceSession("./model.onnx", providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
num_classes = 5
img_size = 224
data_transform = transforms.Compose(
[transforms.Resize(int(img_size * 1.14)),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# img_path = "./5547758_eea9edfd54_n.jpg"
img_path = "./1686647709608.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
img = np.transpose(img, (2, 0, 1))
img = torch.from_numpy(img)
img = transforms.ToPILImage()(img)
img = data_transform(img)
img = torch.unsqueeze(img, dim=0)
img = img.numpy()
ort_input = {session.get_inputs()[0].name: img.astype(np.float32)}
output = session.run(None, ort_input)
output = torch.from_numpy(output[0]).cpu()
predict = torch.softmax(output, dim=1)
predicted_class = torch.argmax(output, dim=1)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[0,predict_cla].numpy())
print(print_res)
plt.title(print_res)
plt.show()
同理,一些路径等调整修改就交给各位了,连import带空格才60行代码,不复杂的。运行loadonnx.py,得展示出一张图片:
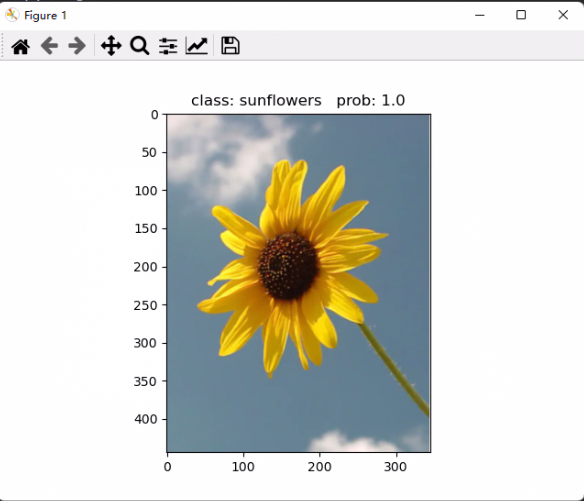
先不考虑是否存在过拟合、图片是否来源于训练集等情况,至少到这里证明我们保存的model.onnx是有效的!那么接下去的事情就是在C++上部署这个模型了。
VS配置ONNXRuntime
在VS上配置ONNXRuntime的方法有很多种,opencv学堂的 贾志刚 已经在B站上粗略讲解了一种方案:
https://www.bilibili.com/video/BV13g4y1K71Y/?spm_id_from=333.337.search-card.all.click&vd_source=d8ac0ff430c94b044512c4edabc63f35
当然,我认为贾志刚的配置方法稍显繁琐。同学们可以在其ONNXRuntime官网https://onnxruntime.ai/上按照自己系统、显卡情况选择下载对应的.nupkg文件。再参考以下第二个链接的方案进行配置:
https://onnxruntime.ai/
https://www.sohu.com/a/218061763_505923
而我自己的配置方案就更偷懒了,在VS中新建一个项目,配置好opencv环境。然后:项目右键》管理Nuget程序包。然后在浏览里输入onnxruntime进行搜索:
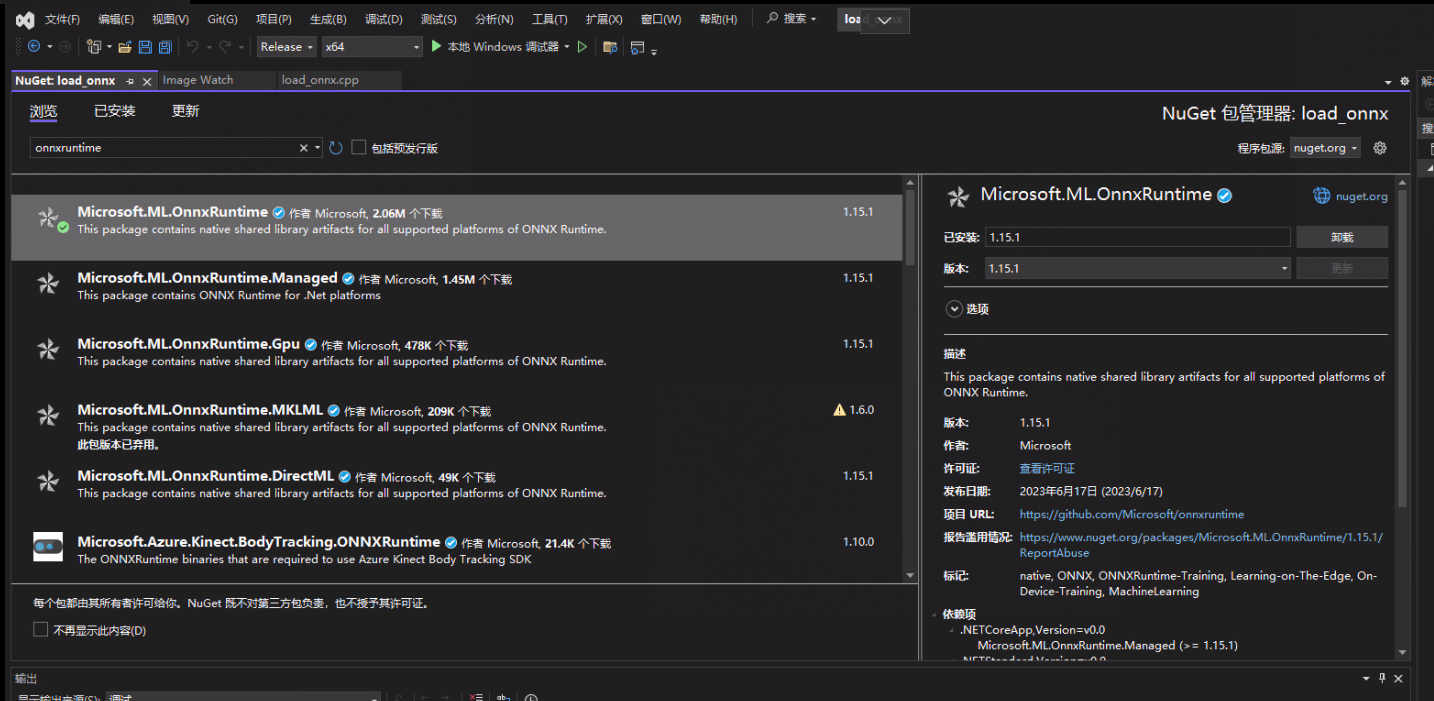
依据自己显卡等情况选择一个安装即可。配置成功!
牛刀小试,实现第一个部署!
直接上代码吧:
// load_onnx.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
#include <iostream>
#include<opencv2/opencv.hpp>
#include<opencv2/dnn.hpp>
#include<onnxruntime_cxx_api.h>
using namespace cv;
using namespace std;
using namespace cv::dnn;
int main()
{
/*String path = "D:/VS_zy/load_onnx/onnxweight/model.onnx";
//dnn::Net net = dnn::readNetFromONNX(path);
auto result = dnn::readNet("D:/VS_zy/load_onnx/onnxweight/model.onnx");*/
//vector<string> labelText = { "雏菊","蒲公英","玫瑰","向日葵","郁金香" };
vector<string> labelText = { "chu ju","pu gong yin","mei gui","xiang ri kui","yu jin xiang" };
//加载模型
std::string onnxpath = "D:/VS_zy/load_onnx/onnxweight/model.onnx";
std::wstring modelPath = std::wstring(onnxpath.begin(), onnxpath.end());
Ort::SessionOptions session_options;
Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, "ConvNext-onnx");
session_options.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
//OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);
Ort::Session session_(env, modelPath.c_str(), session_options);
//加载图片
//cv::Mat frame = cv::imread("./img/5547758_eea9edfd54_n.jpg");
cv::Mat frame = cv::imread("./img/1686647709608.jpg");
//cv::Mat frame = cv::imread("./img/a.jpg");
cv::Mat ori = frame.clone();
/*
resize(frame, frame, Size(224, 224));
cv::Mat image = cv::Mat::zeros(cv::Size(224, 224), CV_8UC3);
cv::Rect roi(0, 0, 224, 224);
frame.copyTo(image(roi));
cvtColor(image, image, COLOR_BGR2RGB);
// 将图像扩大1.14倍
cv::Size newSize(1.14 * image.cols, 1.14 * image.rows);
cv::resize(image, image, newSize);
// 计算裁剪后的子图左上角坐标
int x = (image.cols - 224) / 2;
int y = (image.rows - 224) / 2;
// 截取中心的224*224的子图
cv::Rect roi_(x, y, 224, 224);
image = image(roi_);*/
cv::Size newSize(1.14 * 224, 1.14 * 224);
resize(frame, frame, newSize);
//cvtColor(frame, frame, COLOR_BGR2RGB);
cv::Mat image = frame.clone();
// 计算裁剪后的子图左上角坐标
int x = (image.cols - 224) / 2;
int y = (image.rows - 224) / 2;
// 截取中心的224*224的子图
cv::Rect roi_(x, y, 224, 224);
image = image(roi_);
cv::Scalar targetMean(0.485, 0.456, 0.406);
cv::Scalar targetStd(0.229, 0.224, 0.225);
// 分割RGB通道
std::vector<cv::Mat> channels;
std::vector<cv::Mat> or_channels;
image.convertTo(image, CV_32F);
frame.convertTo(frame, CV_32F);
cv::split(image, channels);
cv::split(frame, or_channels);
// 遍历每个通道,计算均值和标准差
for (int i = 0; i < 3; i++) {
cv::Scalar mean, stdDev;
//cv::meanStdDev(channels[i], mean, stdDev);
cv::meanStdDev(or_channels[i], mean, stdDev);
double scaleFactor = targetStd[i] / stdDev[0];
channels[i] -= mean[0];
channels[i] *= scaleFactor;
channels[i] += targetMean[i];
}
// 合并处理后的通道
cv::merge(channels, image);
//cv::Mat blob = image.clone();
cv::Mat blob = cv::dnn::blobFromImage(image, 1.0, cv::Size(224, 224), cv::Scalar(0, 0, 0), true, false);
auto allocator_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
size_t tpixels = 224 * 224 * 3;
std::array<int64_t, 4> input_shape_info{ 1, 3, 224, 224 };
Ort::Value input_tensor_ = Ort::Value::CreateTensor<float>(allocator_info, blob.ptr<float>(), tpixels, input_shape_info.data(), input_shape_info.size());
//推理
size_t numInputNodes = session_.GetInputCount();
size_t numOutputNodes = session_.GetOutputCount();
std::vector<std::string> input_node_names;
std::vector<std::string> output_node_names;
Ort::AllocatorWithDefaultOptions allocator;
for (int i = 0; i < numInputNodes; i++) {
auto input_name = session_.GetInputNameAllocated(i, allocator);
input_node_names.push_back(input_name.get());
}
for (int i = 0; i < numOutputNodes; i++) {
auto out_name = session_.GetOutputNameAllocated(i, allocator);
output_node_names.push_back(out_name.get());
}
const std::array<const char*, 1> inputNames = { input_node_names[0].c_str() };
const std::array<const char*, 1> outNames = { output_node_names[0].c_str() };
std::vector<Ort::Value> ort_outputs;
ort_outputs = session_.Run(Ort::RunOptions{ nullptr }, inputNames.data(), & input_tensor_, 1, outNames.data(), outNames.size());
// output data
const float* pdata = ort_outputs[0].GetTensorMutableData<float>();
cv::Mat dout(1, 5, CV_32F, (float*)pdata);
cv::Mat det_output = dout.t(); // 8400x84
//softmax
cv::exp(det_output, det_output);
double sum = cv::sum(det_output)[0];
det_output /= sum;
cv::Point maxLoc;
double maxValue;
int maxIndex;
cv::minMaxLoc(det_output, nullptr, &maxValue, nullptr, &maxLoc);
maxIndex = maxLoc.y;
string cls = labelText[maxIndex];
putText(ori, cls+" p="+ std::to_string(maxValue), Point(10, 30), FONT_HERSHEY_COMPLEX, 0.6, Scalar(0, 0, 255), 1);
cout << 223 << endl;
}
将以上代码复制到刚才配置好环境的项目中即可。又又又是老规矩,一些细节的调整就靠各位自己的了,其中:
OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);
的使用与否取决于你的显卡是否适配以及ONNXRuntime的配置版本。
运行后,可以在图片ori中显示结果:

至此,个人第一次图像分类卷积深度学习模型在C++上部署实现了!
其他
VS上看图像还是比较麻烦,这里推荐一个小工具:Image Watch,有了这个工具可以在调试代码的时候轻松观察过程中的所有Mat的图像、数组等信息。安装放下参考下面这个连接:
https://blog.csdn.net/Aliya_yy/article/details/128314438
如此,可以在上面代码的:
cout << 223 << endl;
这句打个断点,然后查看各个图片啦














 2906
2906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









