









 生存分析是一种历史悠久的统计方法,用于研究随访研究中对象是否发生特定事件及其持续时间。文章介绍了生存数据、事件定义、时间处理、删失现象,以及关键的生存函数和风险函数。未来将探讨R语言在Kaplan-Meier分析、Cox回归等传统与前沿方法的应用。
生存分析是一种历史悠久的统计方法,用于研究随访研究中对象是否发生特定事件及其持续时间。文章介绍了生存数据、事件定义、时间处理、删失现象,以及关键的生存函数和风险函数。未来将探讨R语言在Kaplan-Meier分析、Cox回归等传统与前沿方法的应用。
生存分析
生存分析(survival analysis)是一个历史悠久的概念,最早在1662年就被提出,主要用来分析随访研究中研究对象是否发生我们关心的事件以及发生该事件之前的时长(生存时间)。生存分析也被称为时间事件分析(time-to-event analysis),因为该分析方法不仅只关注患者是否发生死亡,也可以用于分析其他事件,例如在肿瘤领域中:
-
从治疗开始到疾病发生进展的时间
-
从患者反应到复发的时间
-
患者肿瘤发生脑转移的时间等等
也可以应用于其他领域,如:
-
患者脑卒中复发的时间
-
从艾滋病毒感染到艾滋病发展的时间
-
机器发生故障的时间
1. 生存数据(Time to event)
事件(Event) 的具体定义取决于新药试验中事先指定的临床终点 (clinical endpoint) 。如果终点是总体生存期*(overall survival, OS)*,那么事件就是患者的死亡。如果终点是无进展生存期 *(progression-free survival, PFS)*,那么事件就是患者病情的进展 (例如固体瘤增大或者白血病的血液指标恶化) 或者死亡。生存分析能在生物医学以外的许多不同领域有用武之地,其关键就在于事件这个概念在定义上的灵活性。
时间(Time) 指从病人被随机分派进入临床试验的分组 (相对的时间零点) 直到事件发生所经历的时间跨度。时间可以为天、周、月和年。临床试验的病人招募通常是个持续的过程,不同病人的试验一般始于日历上不同的具体时间点,在数据分析时只有采用相对时间,才能有同样的时间轴及零点。对于临床试验的病人群体而言,个体病人的生存时间是一个随机变量,用大写的T表示。而生存曲线横坐标则对应各病人事件发生的时间点,它不是随机变量 (而用做函数的自变量),用小写的t表示,随机变量T一般不遵从正态分布。
删失 (Censoring)指由于事件没有被观测到或者无法观测到,而导致生存时间无法精确记录的情况。其中最为常见的情形称为右删失(right censoring,图1),对这样的病人我们只知道其生存时间要大于从试验开始到删失发生的时间。
library(tidyverse)
fkdt <- tibble(Subject = as.factor(1:10),
Years = sample(4:20, 10, replace = T),
censor = sample(c("Censor", rep("Event", 2)), 10,
replace = T))
ggplot(fkdt, aes(Subject, Years)) +
geom_bar(stat = "identity", width = 0.5) +
geom_point(data = fkdt,
aes(Subject, Years, color = censor, shape = censor),
size = 6) +
coord_flip() +
theme_minimal() +
theme(legend.title = element_blank(),
legend.position = "bottom")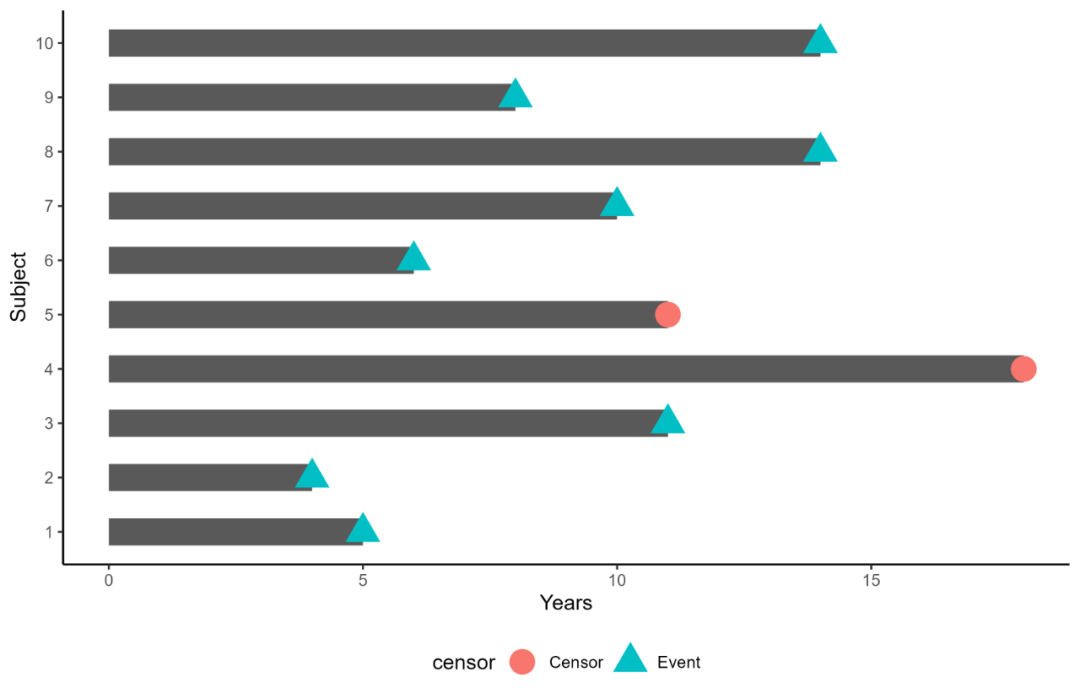
有多种原因可以导致右删失情况的出现,其中包括:(1)病人在某时间点上退出试验或失去随访信息;(2)病人在整个试验结束时事件还未发生;(3)病人由于毒性等原因停用被分派的药物或换用其它药物;(4)竞争风险事件的发生。
2. 生存函数和风险函数
生存函数(Survival Function)
生存函数为患者活过一定时间的概率
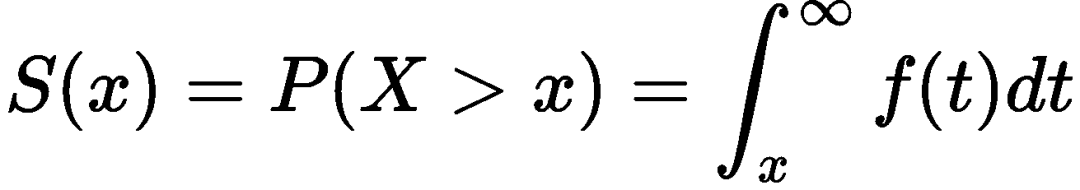
通过求导可以得出生存函数与概率密度函数的关系:
其累积生存概率函数(cumulative survival probability)为:
风险函数(Hazard Function)
风险率函数为患者在时间时生存,但在极短的时间后死亡的概率。
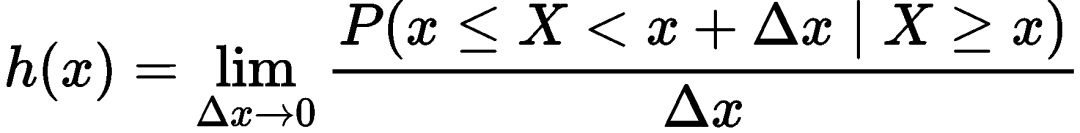
而h(t)在从零开始的一个时间段内的积分,H(t),则被称为累积风险函数 (cumulative hazard function):
各函数方程之间的关系
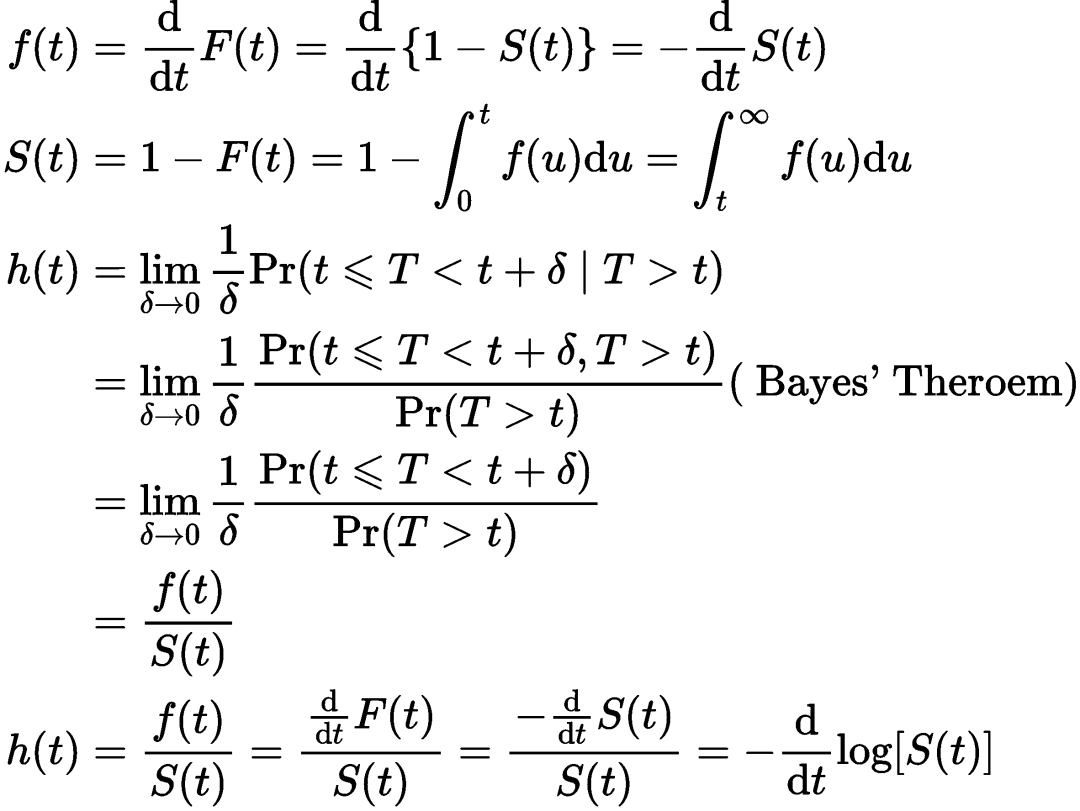
3. 未来更新计划
由于生存时间T的非正态分布以及删失情况的存在让传统的统计方法在分析这类数据时无用武之地,于是统计学家们殚精竭虑,直到1970年代才使生存分析这一方法体系趋于成熟。
Kaplan–Meier曲线(K-M曲线)和Cox Proportional Hazard Model(Cox回归)是现代生存分析方法的起源。两篇论文被引用次数很多,很大一部分原因在于临床试验(尤其癌症领域)应用广泛,不仅如此,它们在流行病学、社会科学、经济学、工业的可靠性测试等方面,都有着非常广泛的应用。
本系列未来会基于R语言更新传统的K-M分析、Cox回归以及现在一些前沿的方法,主要包括以下:
-
非参数法:Kaplan–Meier法及生存曲线绘制
-
半参数法:Cox回归及等比例风险检验
-
参数法:加速失效模型(AFT)
-
非参数法:限制平均生存时间(RMST)
-
如何从已发表K-M曲线中重构患者个体数据(IPD)
-
竞争风险模型(Competing Risks)
-
时依性变量(Time-Dependent Covariates)
-
游泳图(Swimmer Plots)
-
生存分析与因果推断:参数G方程(Parametric g-formula)
-
条件生存分析(Conditional survival)
-
界标分析(Landmark analysis)
-
脆弱模型(Frailty model)在生存分析中的应用
-
贝叶斯生存分析(Bayesian survival analysis)
-
LASSO回归在生存分析中的应用
-
机器学习在生存分析中的应用



















 5217
5217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











